Uncovering Lives of WW1
Team 1
Nour Obeid George Badea Junda He
Overview
• Experiences of the First World War could be thoroughly different, depending on the location, type of military unit, medical issues, social class and more. We aim to provide more context for the experiences of different military units in different locations of the war and seek to find the connections among them.
• We are collaborating with the British Library, text-mining and geo-referencing on a large collection of digitised books provided by the British Library.
• We need to apply machine learning, corpus linguistics and sentiment analysis techniques to identify and generate a gazetteer of the names of places within digitised publications from and about the First World War
Initial Data gathering
Client requirements:
A system that is trained to:
-identify place names mentioned in documents that aren't in gazetteers
-identify description of places
Data collection : From meeting and Interview with the client
User type:
Researchers - Historians - Literary scholars - Social scientists
Data collection: Researching and interviewing concurrent developers
Software type: Terminal program or Mobile App or Interactive website
We chose our system to be an Interactive website because :
-There is no download required making it faster and easier
-The data is easily updatable
Initial requirements
Functional requirements:
- The system SHOULD accept 1 input file
- The system SHOULD identify place names
- The system SHOULD identify the description of the place names
- The system SHOULD extract sentences surrounding each place name
Non-functional requirements :
- The input file MUST be in pdf or txt format
- The http connection time out SHOULD be 1 minute
- The waiting time SHOULD be visualised
- The language SHOULD be English
- The system SHOULD be developed by April 2018
User Consultation
As the Geo-parser is made mainly for researching and academic purposes, the users are most likely to be Professors, scholars or researchers in the field of human sciences or sociology. We had an interview with the Digital Curator of British Library’s Digital Scholar team, Dr. Mia Ridge to gather the initial requirements.
We emailed the developing team of the Edinburgh Geoparser and Dr. Beatrice Alex has provided us some information about the user and collaboration projects about this similar product:
- The default Edinburgh Geoparser (available in the download) was developed for newspaper text . It is used to work on research project where people adapt it to different domains.
- The geoparser is mainly rule-based apart from some of the candidate ranking steps in the geo-resolution component. The parser is found to work most reliable when applied to text in different domains as a machine learning based system would need annotated training data for each new domain and it’s costly to create.
- We looked at the projects that used the Edinburgh Geoparser and analysed each of them including the lit long project, the Survey of English Place Names, the GAP project
After the consultation, we decided to enable multiple files uploading to increase its efficiency .
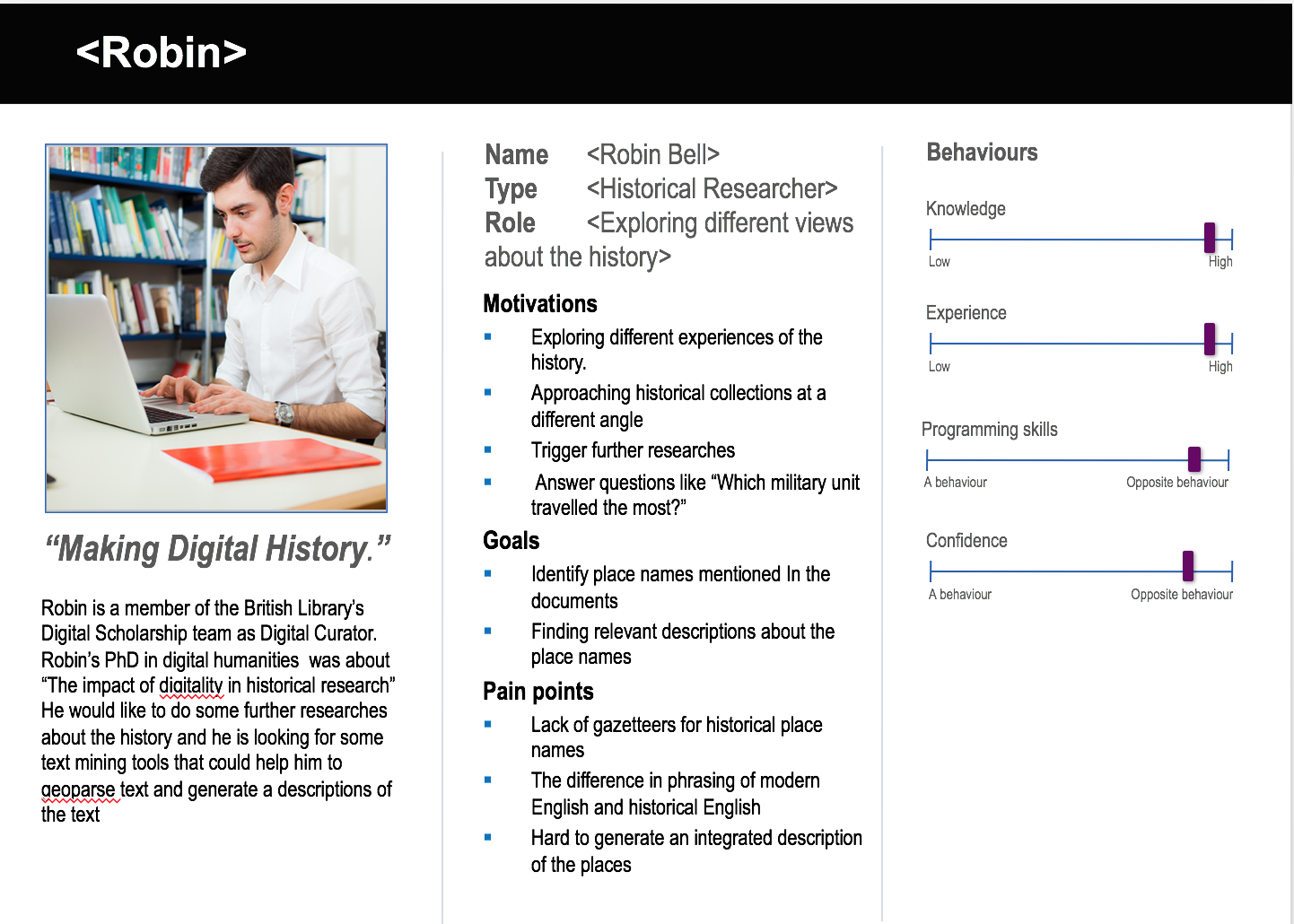
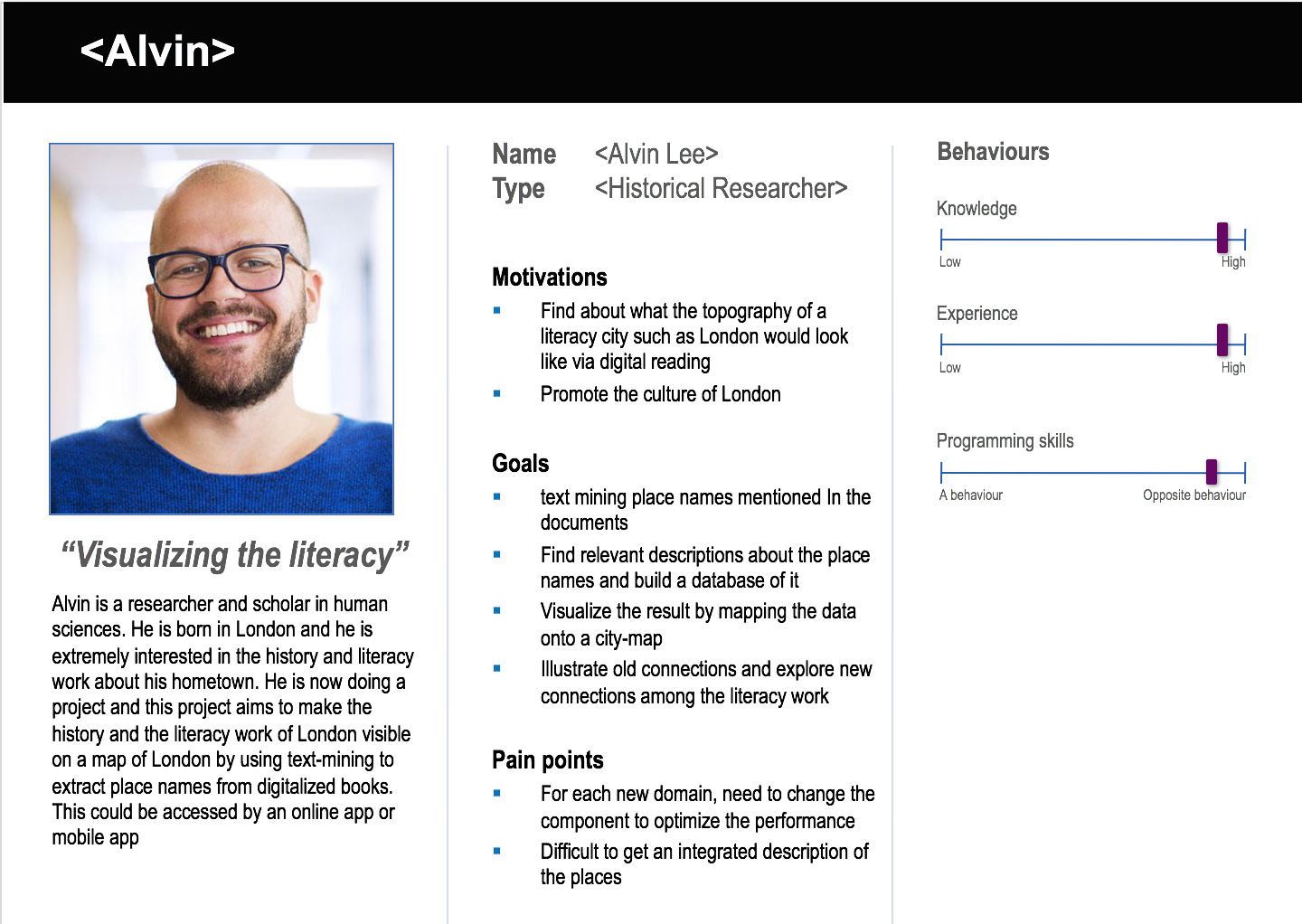
Personas
Sketches
Throughout the design process, we applied the Elaboration and Reduction method. Our ideas converged to the optimal one.
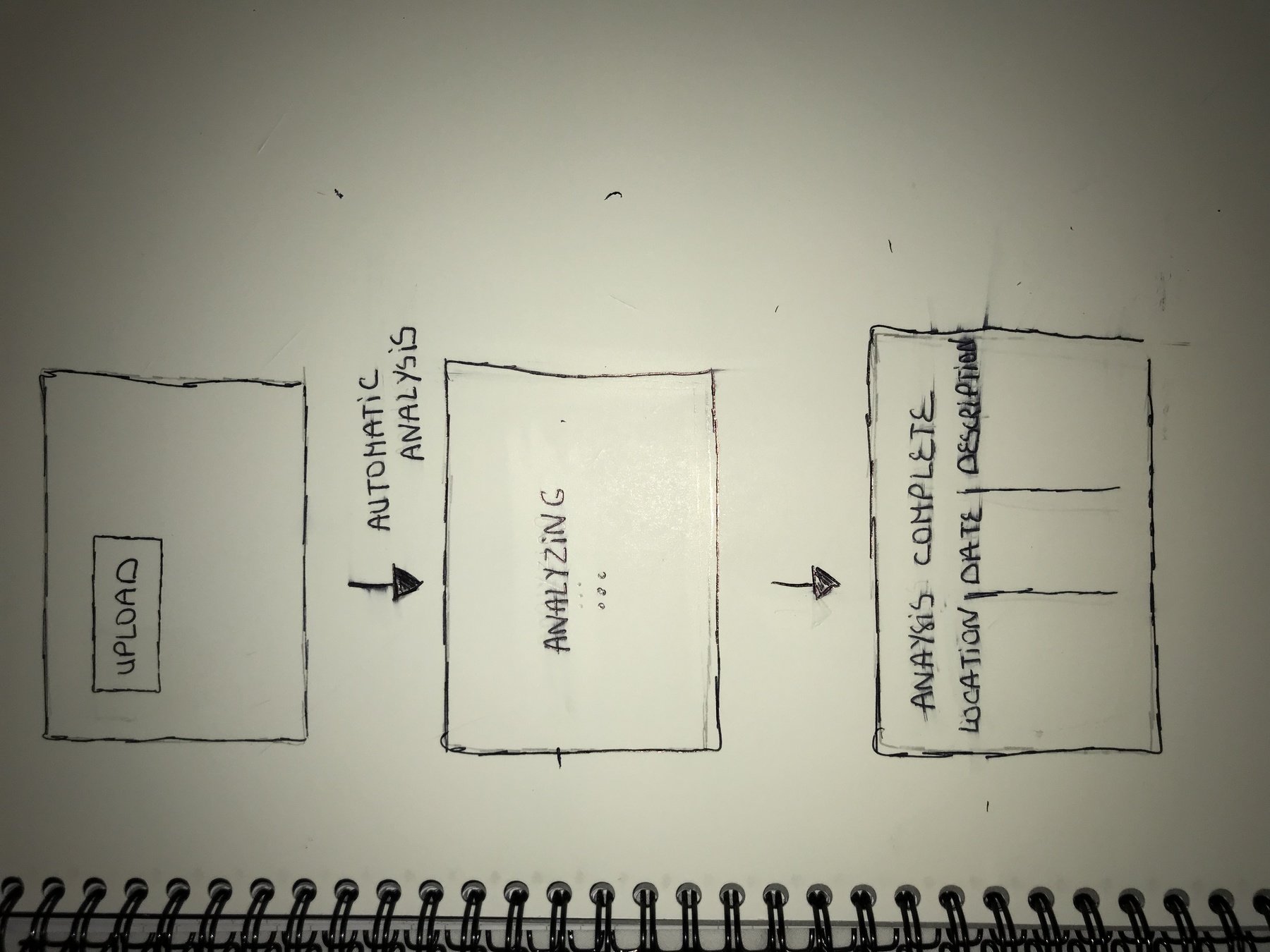
1st idea
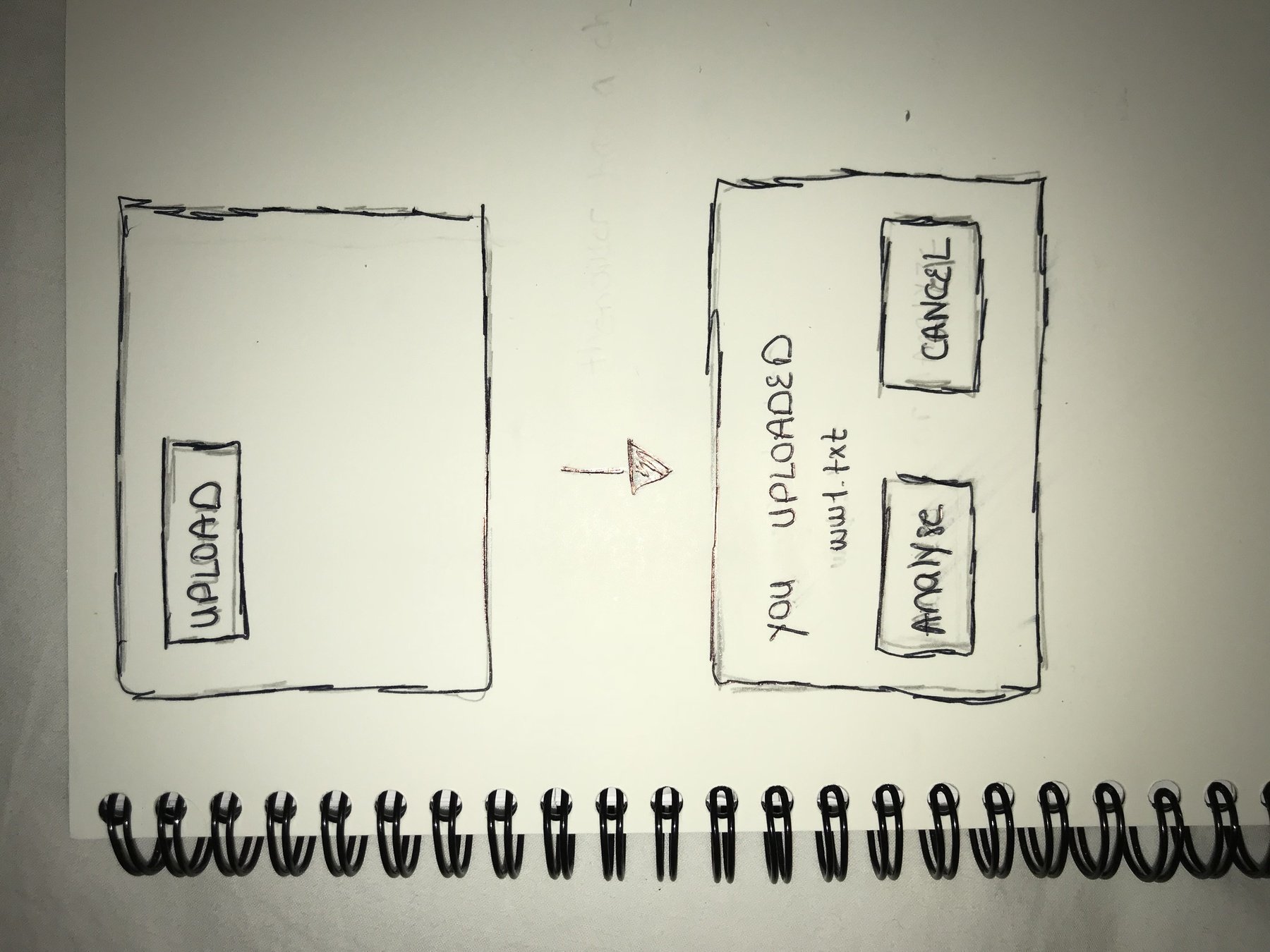
2nd idea : more usered- centered
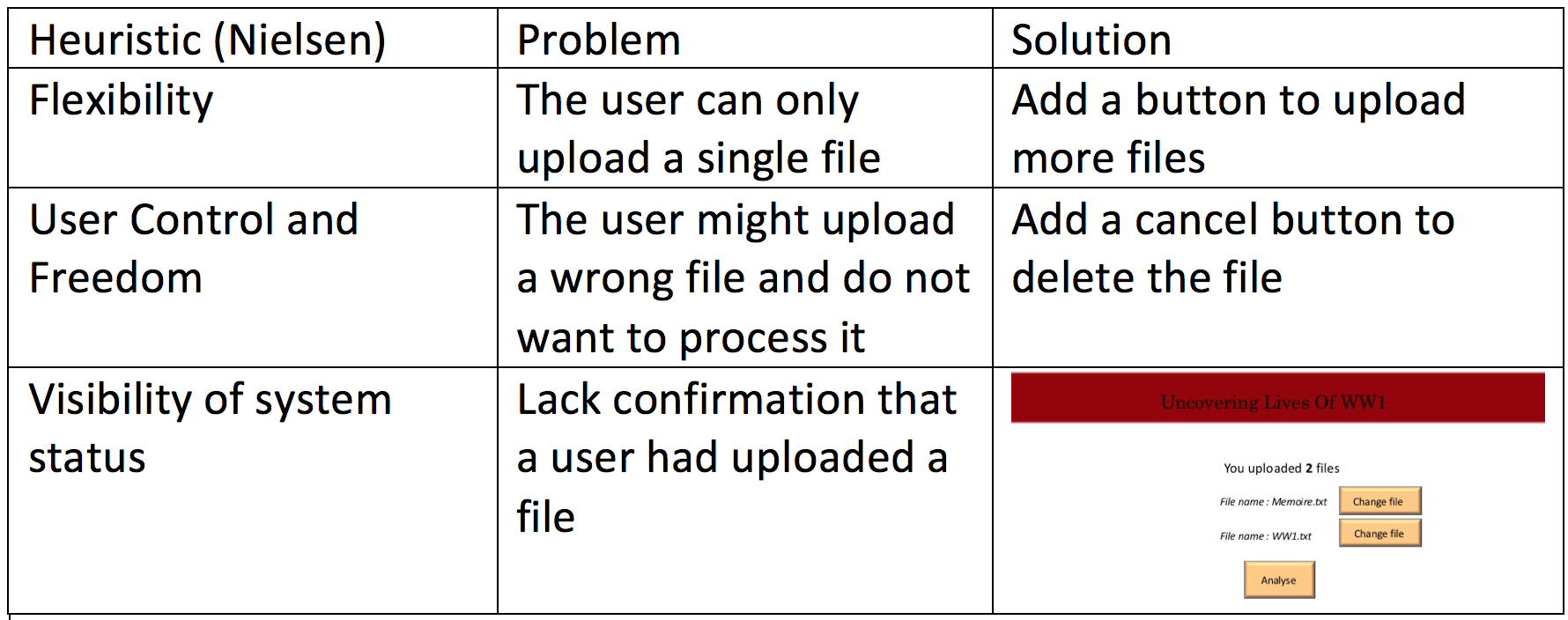
While sketching we aded to our requirements :
- A cancel button must be displayed
- The name of the uploaded file must be displayed
Automatic analysis
after uploading the file
The user can confirm
or cancel his upload
Scenario
Alvin has started his project. Initially Alvin needs to use text-mining and geo-referencing on a large set of collections of digitized books to build a database that contains the place-names and relevant descriptions. It would take a long time for humans to finish reading the books and precisely extracting the right sentences from the context.
So Alvin and his team used the Geo-parser to analyze the books, he selects many text files in one-go and lets the algorithms to extract place-names, relevant descriptions of the place and the title and author of the book. He types in the url of our website, uploads the text files and he clicks “submit”. After a while the algorithms finished reading and automatically build the database. Alvin then uses the output to continue doing his project
Storyboard

Prototype
We built 2 different prototypes to support our design
1. Digital prototype




I
II
III
IV
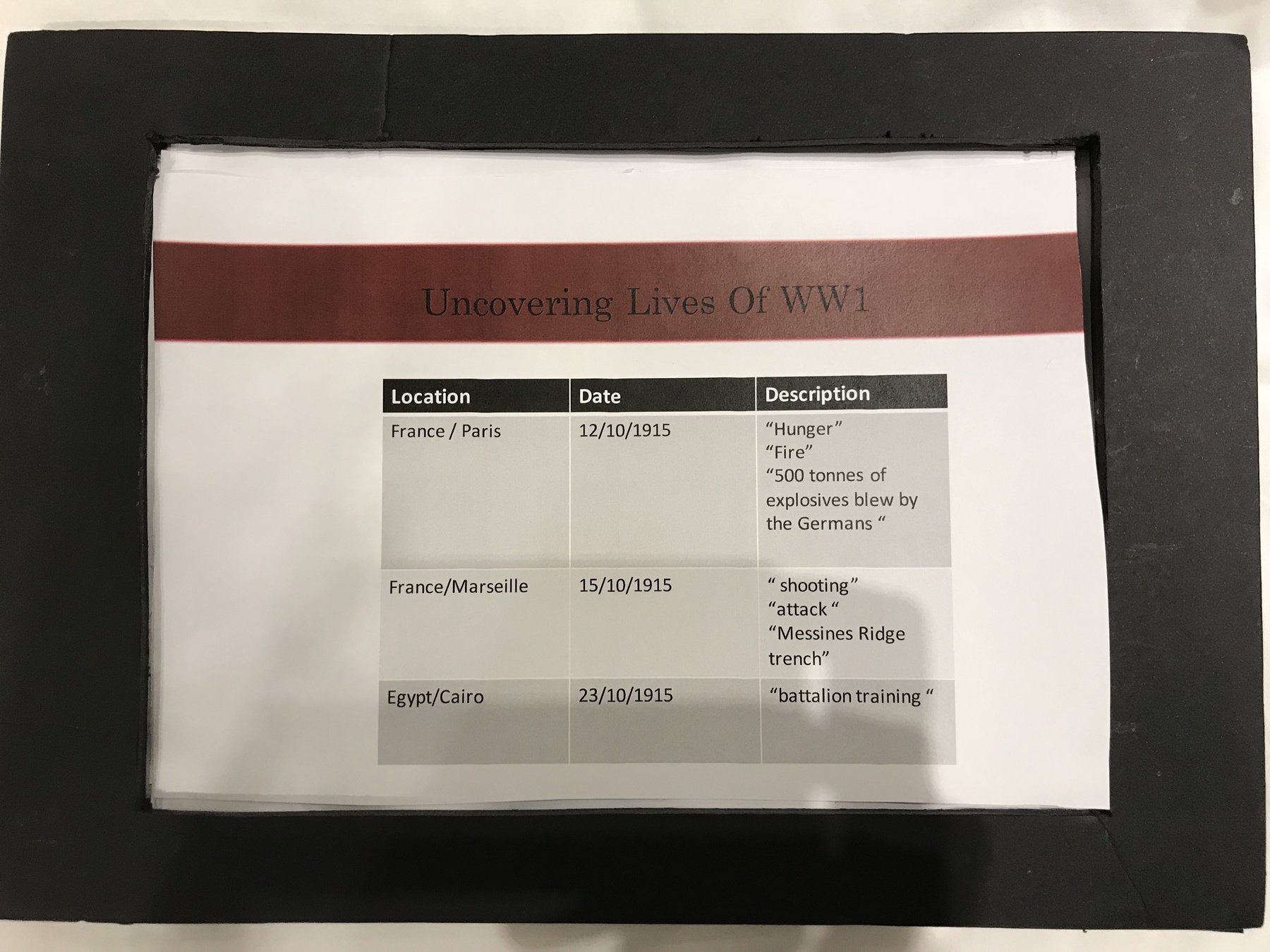
2. Made of cardboards:
- very quick to build
- very effective for identifying problems in the early stages of design
- quick to modify




I
II
III
IV
V
Evaluation
We used the prototype made of cardboards to evaluate our system
User testing method
- We can get unbiased feedback from real users in real time and
-Can ask users to complete specific tasks
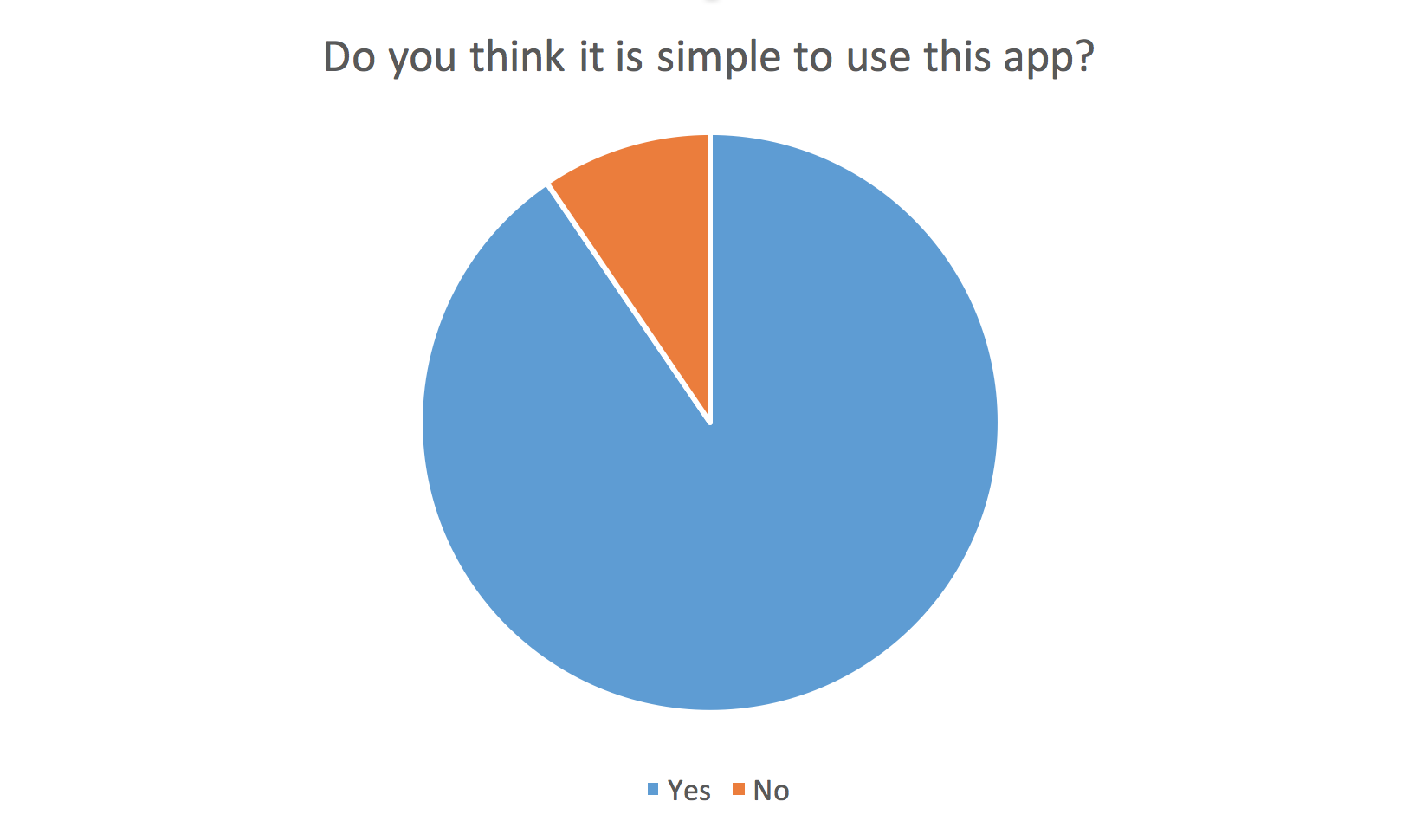
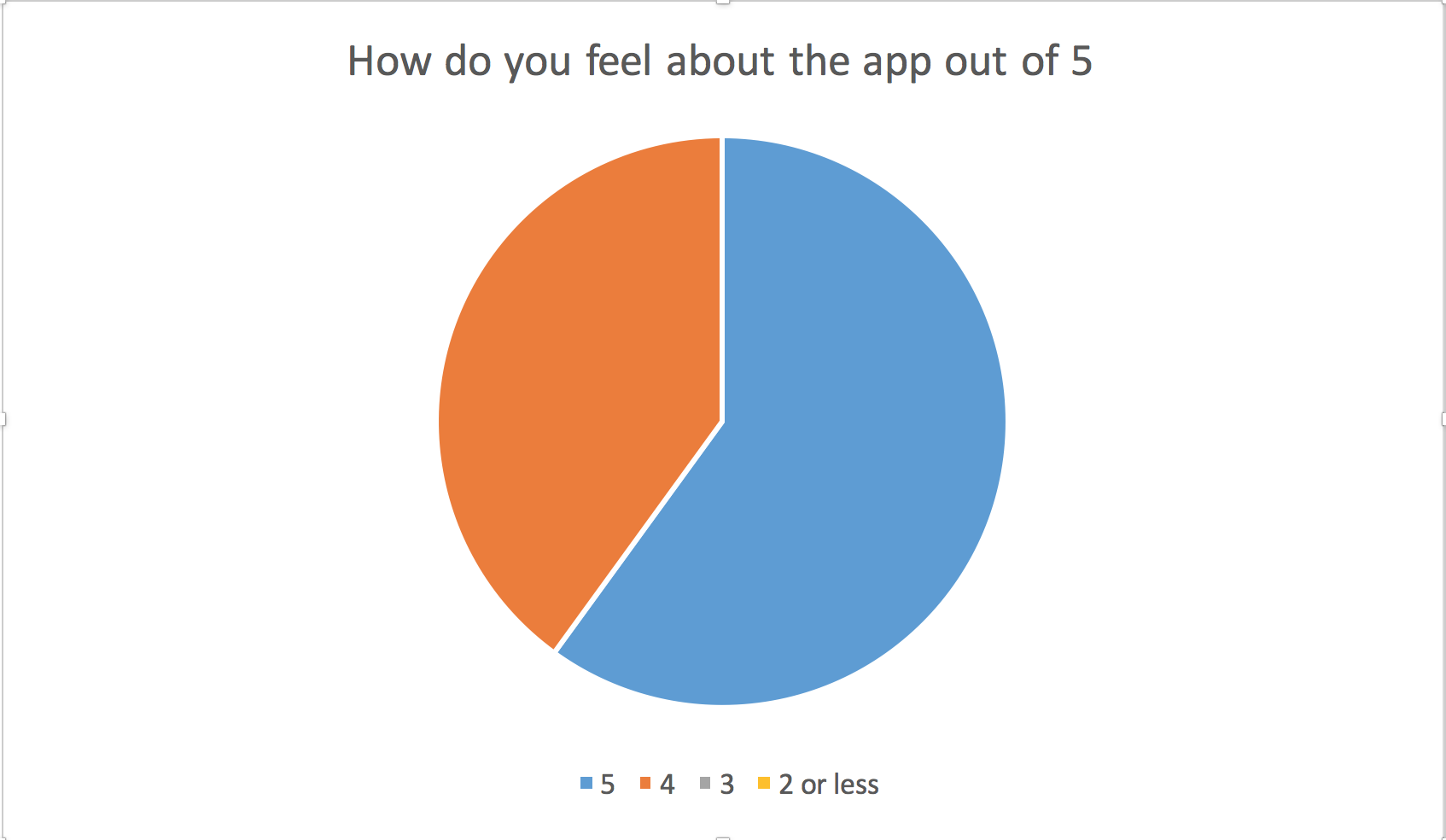
We consulted 5 users
We added to our requirements :
A "change file button "
The output should be visualised via google maps
The system should accept up to 2 files
Heuristic Method
Final Requirements
Functional Requirements : The system MUST accept an input file
The system MUST identify place names
The system MUST identify the description of the place names
The system MUST extract the sentences surrounding each place name
Non Functional Requirements :
The input files MUST be in txt or xml
The http connection time out MUST be one minute
The system MUST be developed by April 2018
The language MUST be in English
A cancel button SHOULD be displayed
The output SHOULD be visualised via google maps
The system SHOULD accept up to 2 input files
New Prototype







Text
I
II
III
Text
IV
V
VI
VII
Research
We have a range of gazetteers to choose; It is difficult to find a source that provides a perfect gazetteer for the domain of WW1 so it is necessary to experiment with different gazetteers before deciding which one to use. They are:
- Genomes: covers all countries and contains over eleven million place-names, the drawback is some historical place-names will not be identified
- Deep: historical place names in England
- Pleiades+: a community build gazetteer of ancient places
- Unlock: a general gazetteer mainly for the UK
The system should be able to identify people names as well. It is found that identifying place names and person names at the same time would increase the accuracy of differentiating some ambiguous places. For example, ‘Levis’ could be a first name or an island in Scotland. As well as “Mrs Chesterfield”, “Earl of Essex”.
Local gazetteers are important on improving the speed of processing large files. Comparing to use online gazetteer services, setting up a local database of storing the gazetteers is more desirable.
Process Pipeline
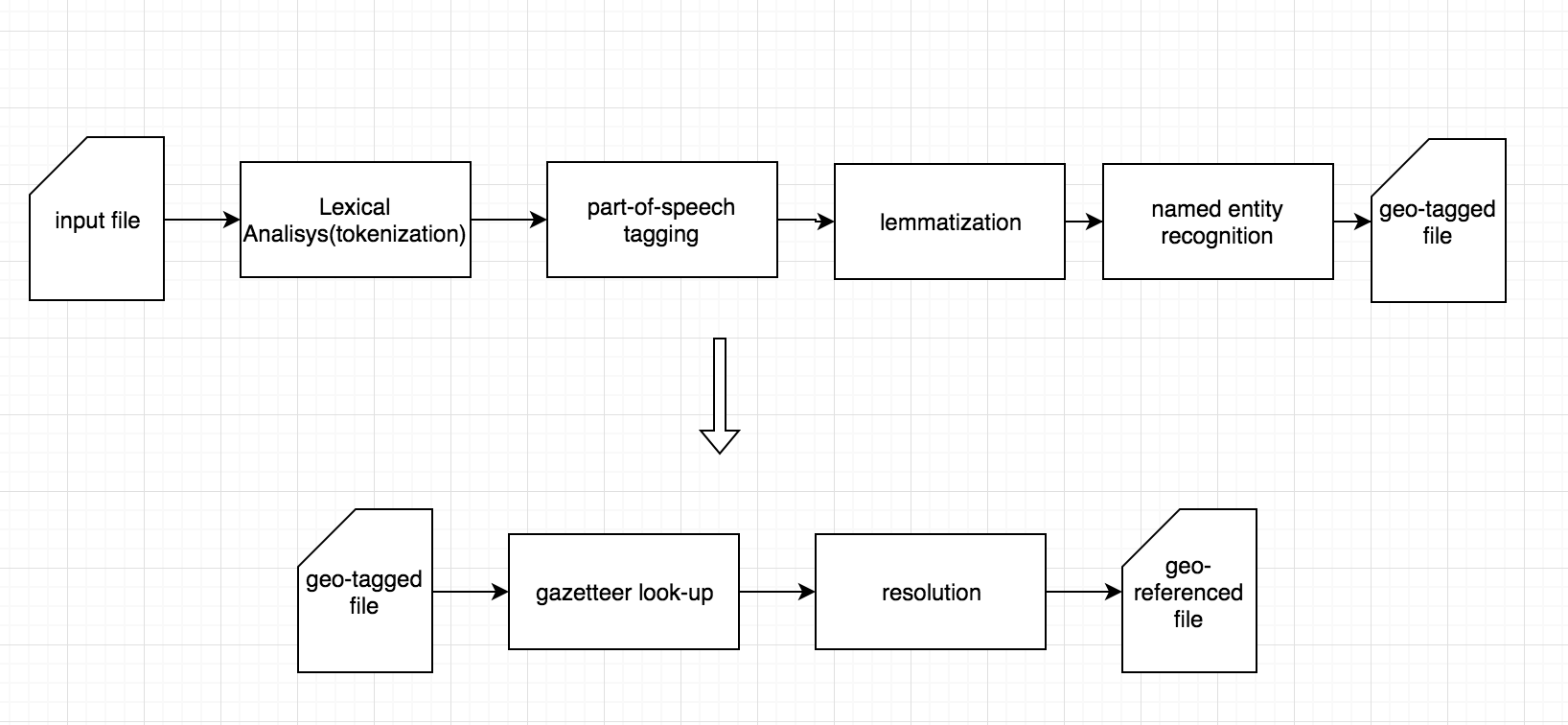
The specified text file is going through a series of processing steps which are combined into one pipeline. It is first tokenised, part-of-speech tagged and lemmatised. After these initial steps, named entity recognition is performed to identify location and person names as well as dates. Finally, visualisations are created to be able to inspect the file and the Geoparser output using a map interface in a browser.
1. Tokenization: It identifies word tokens and results in w elements being wrapped around the tokens and wraps s elements around the sentences
2. Part-of-speech tagging is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, based on both its definition and its context.
3. Lemmatization is the process of finding the stem form of inflected words.
The Edinburgh Geoparser
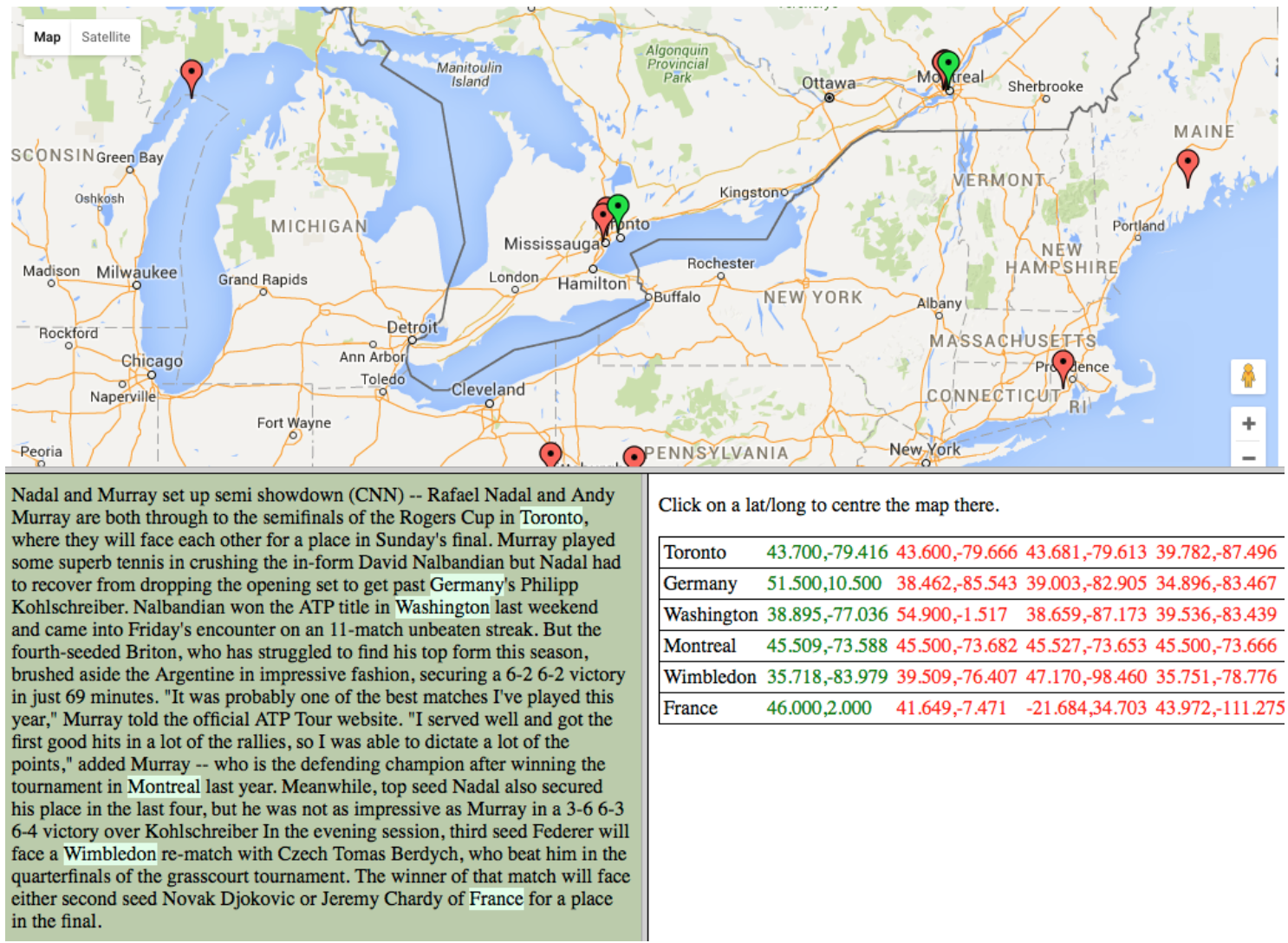
In December 2015, the Edinburgh Geoparser was released under the University of Edinburgh’s GPL license to be used by other researchers in the field of text mining as well as other scholars who are interested in geoparsing text.
The Geoparser allows you to process a piece of English-language text and extract and resolve the locations contained within it. Among other uses, geo-resolution of locations makes it possible to map the data.
Further Development
Specifying temporal expressions (dates and times) and people names
As we mentioned before, it has the best outcome when the identify of place names and person names are operating at the same time.
In the future, the system should be able recognize date and times and normalize them as well. By normalizing, we mean to compute the time to the exact calendar time. For example, it calculates the exact time of the expression “Yesterday” by processing other data.
Geo-parsing multiple text files
For researchers and scholars, being able to process a large single file is far away from their needs. You may would like to analyze a bunch of documents at once.
Architecture System
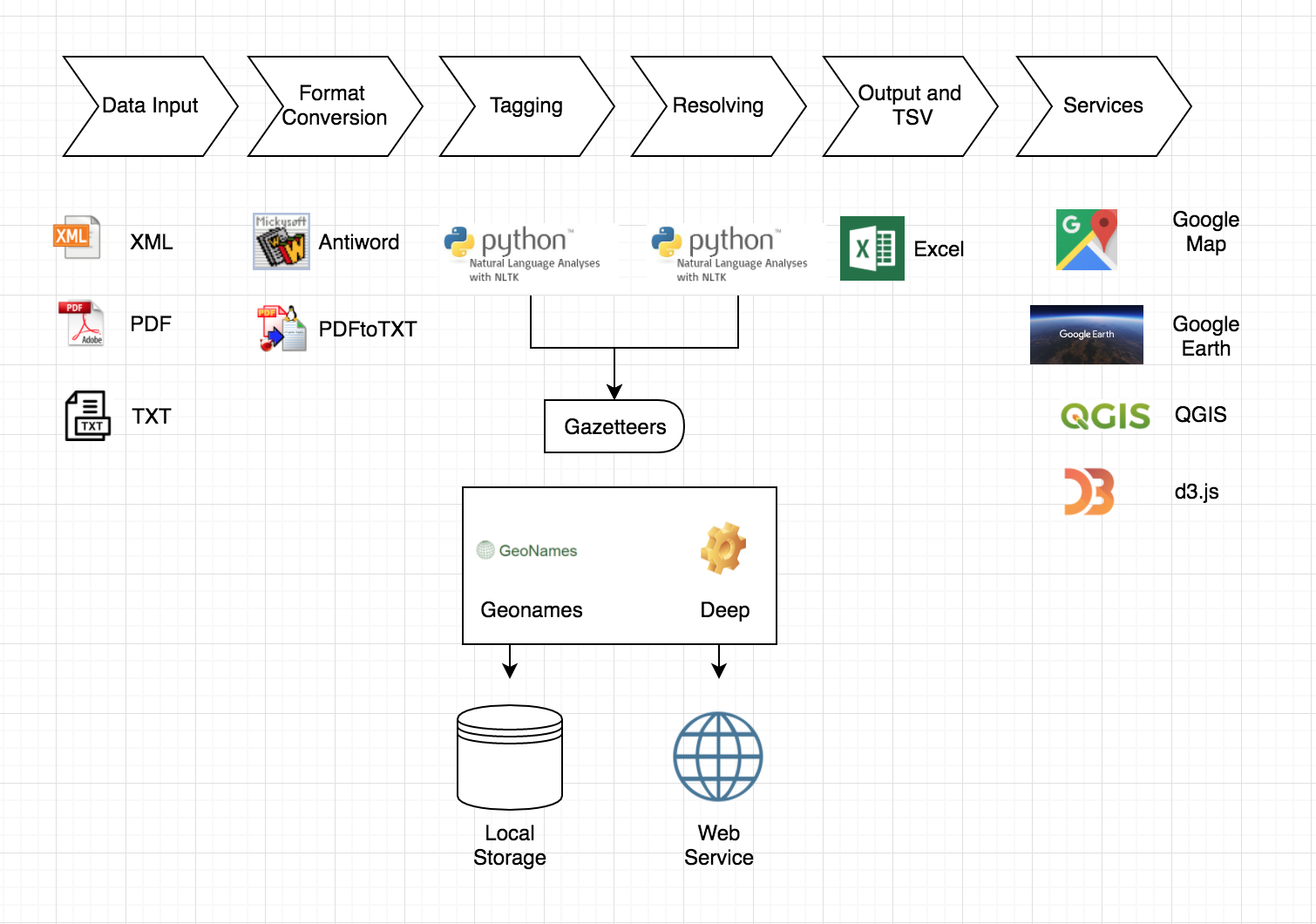
Future Plan
- Rebuild the HCI website
- Build website interface
- Researching about LT-TTT2 and NLTK
- Setting up the architecture system
References
•https://www.bl.uk/people/experts/mia-ridge
•https://www.ltg.ed.ac.uk/release-of-the-edinburgh-geoparser/
词干提取(stemming)和词形还原(lemmatization)
http://blog.csdn.net/march_on/article/details/8935462
Software Architecture Document, Natural Language Processing
https://www.i2b2.org/software/files/PDF/current/NLP_Architecture.pdf
Wei’s introduction to NLP architecture
http://blog.sciencenet.cn/blog-362400-1006290.html
The Edinburgh Geo-parser, Gazetteers
http://groups.inf.ed.ac.uk/geoparser/documentation/v1.1/html/gaz.html
•Image reference: https://www.usn.no/research/postgraduate-studies-phd/
•http://cdrin.org/next-generation-researcher-training/
https://en.wikipedia.org/wiki/Antiword#/media/File:Antiword-logo.png
https://gweb-earth.storage.googleapis.com/assets/google_earth_banner.jpg
https://www.gislounge.com/wp-content/uploads/2012/05/qgis-logo-new.png
https://lh3.ggpht.com/GkNfqm17WFuzaIR87_oz690ErF63hL08Ngj73QtDxyWlCOF80d2gWd2GHrPLJJ-YmHYS=w300
https://blog.sqlauthority.com/wp-content/uploads/2008/08/xmlicon.png
https://cdn.makeuseof.com/wp-content/uploads/2008/07/pdflogo.png
https://n6-img-fp.akamaized.net/free-icon/txt-file_318-119221.jpg?size=338&ext=jpg