Model Upload
High level overview
One of the core deliverables of our project is to support the upload of trained machine learning models, these models need to be dockerised server side, and be able to be downloaded so that users can run these images and test them with a provided frontend.
Currently our implementation supports uploading of trained machine learning models written in Python. We then build the docker image and provide a package to download. When run, the user is provided with a local frontend written with React which allows the user to call a predict function on that model. The predict function takes in any file as input and gives output from the trained model as JSON data.
To provide this to the end user, we need the following from an uploader:
- The source code to load the trained model into (zip)
- A trained model, which is uploaded as a pickle (Serialisation of a python object)
- A requirements file so we know what dependencies need to be installed on the docker image
- A config file, which is in JSON format. Since we support multi-file source code, we need to be able to dynamically import the model class from the source code to load the pickle into. To do this, we ask the user to provide the module name and class name of where the predict function is located, as well as the name of the predict function itself.
Calling the predict function:
To allow the end user to call the predict function from the provided frontend, we wrote an API with a ‘/model/predict’ endpoint.
When the API is run, its loads the pickle into the dynamically imported class from the source code, and the trained model now lives in memory.
Our /model/predict endpoint takes in a file as input and then calls the trained models predict function with this file, it then returns the output from the trained model as JSON.
Building the docker image:
In our main applications API, we have our ‘/models/upload’ endpoint. This takes in the following from the uploader:
-
Model data:
This is the meta data of the model which is stored in the database and displayed to the user when browsing models. This contains information such as name, description, version control, etc.
- The files needed for model upload as stated above: Source code, pickle, requirements, and config
Generating the docker image is handled in model_gen.py. Once uploaded, we verify the inputted data and create a temporary directory called ‘src/data/temp/[model name]-gen’. The following files are copied into the temporary directory:
- The Dockerfile for building the image
- The model API for calling the predict function
- The source code as a zip
- The requirements.txt file
- The source code as a zip
- The pickle
- A JSON dump of the model data so we can display the model’s name, description, etc. to the user when they run the model. This data is returned from the ‘model/data’ endpoint and is called when the frontend is ran.
The docker file and API are the same for every model, and are stored in ‘src/data/model_gen’.
The docker file builds the Python 3.8 base image, copies over the required files, installs the requirements, and when run, serves the API with uvicorn.
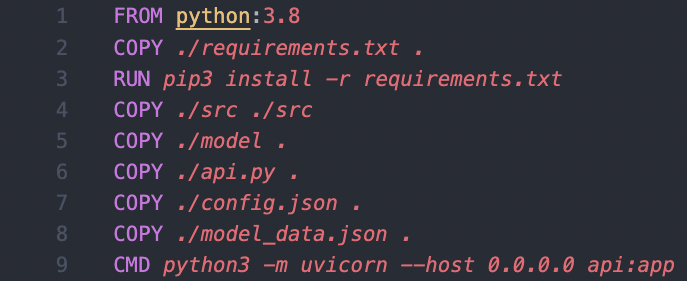
After the files have been copied into the temporary directory, we unzip the source code, build the docker image, save the image as a tar file with `docker save` to the directory ‘src/data/models’ with the file name being [model name].tar. Once the model has been saved as a file, we delete the image binary from the machine. The dockerised machine learning model is now ready to be downloaded.