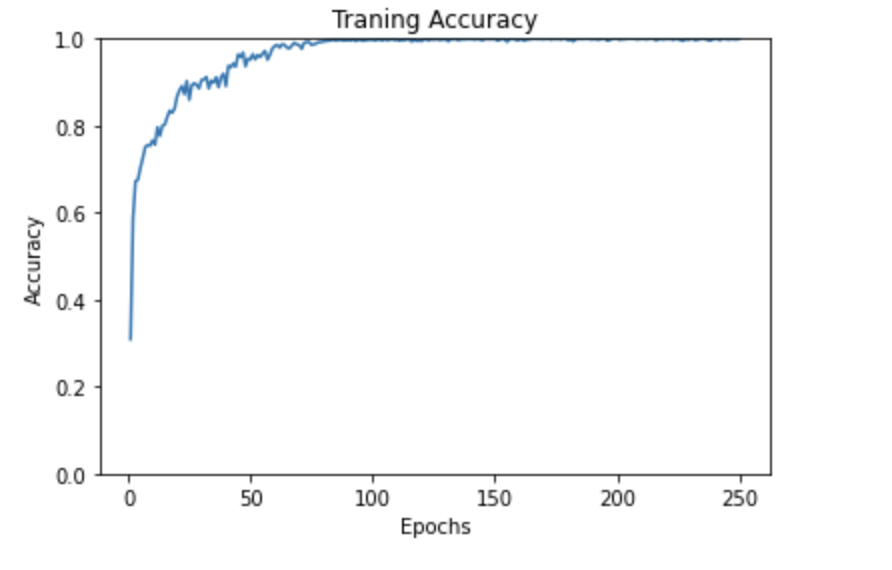
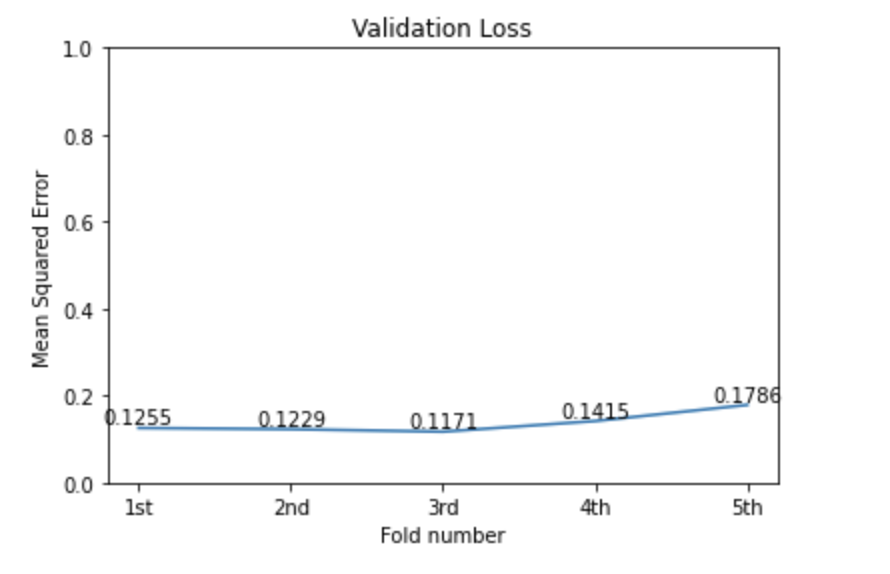
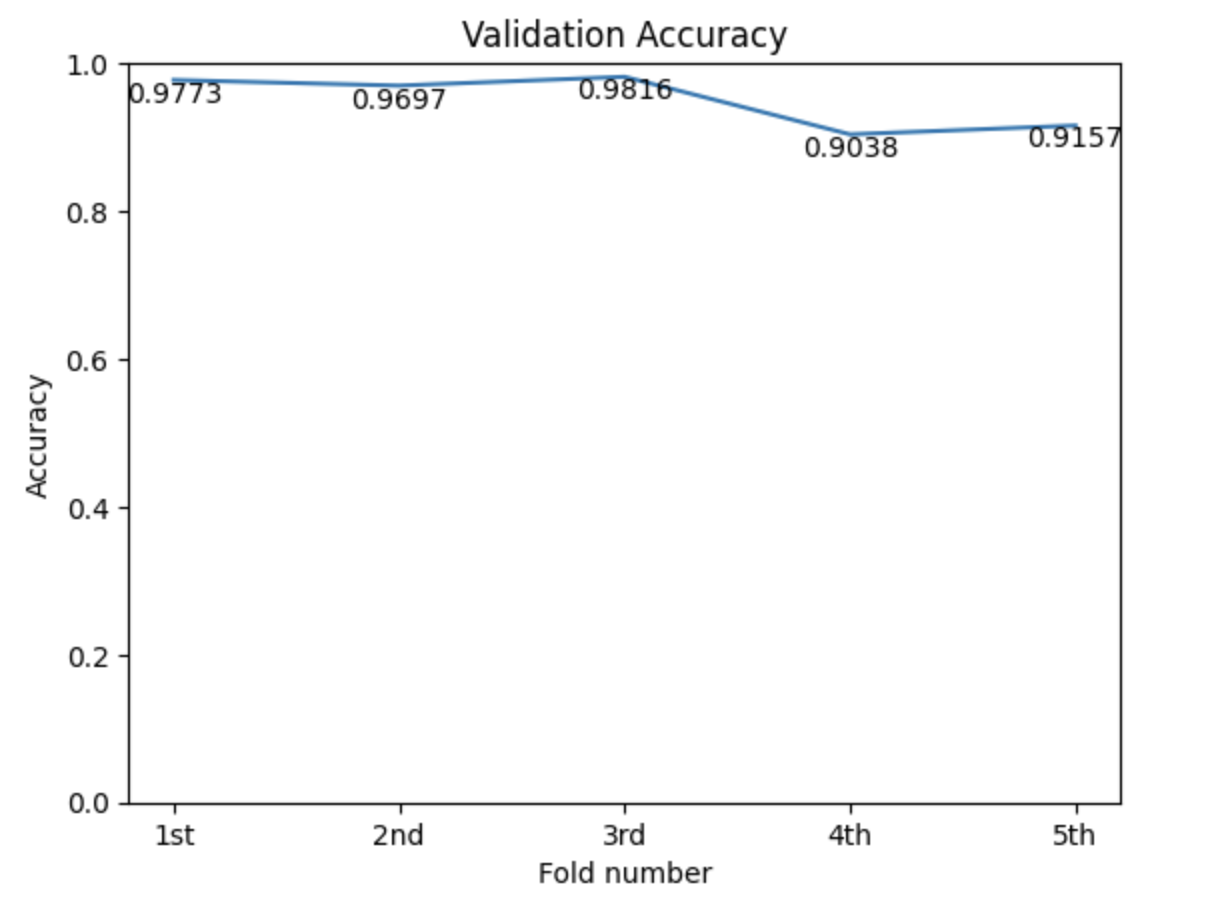
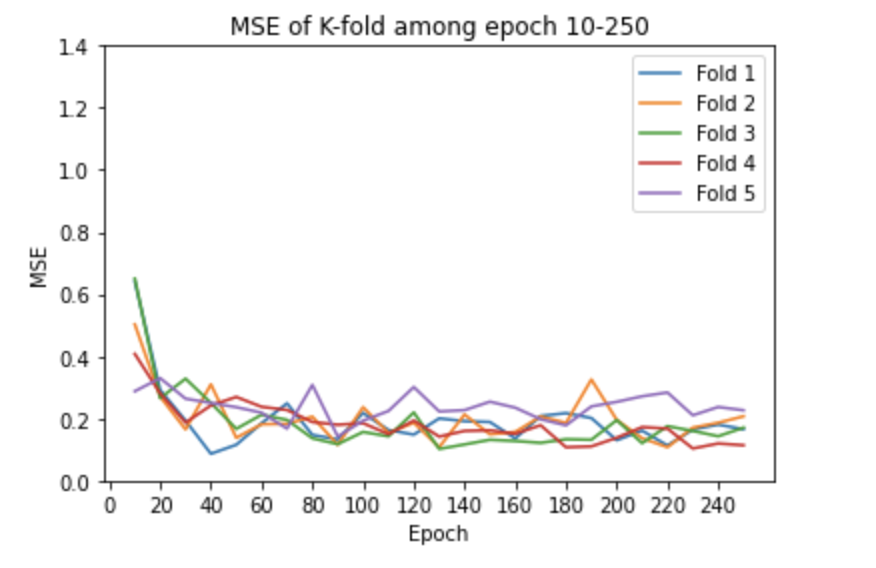
Dataset
Data Source
The data we used is from our client, the UCL Eastman Dental Institute. They provided us with 194 3D
teeth models (sextants). They also provided us with 14 real patient teeth models to be displayed in
the software.
Originally, we were supposed to train the deep learning model on real patient data. However, due to the
ethical issues, we did not recieve the dataset until March 2023. Therefore, we agreed to build a
proof-of-concept model using the sextant teeth models, where a sextant is 1/6th of all the
teeth (containing 4 to 6 teeth). Since teeth sextants are only a part of the whole teeth, it is easier
for dentists to scan and collect data. We recieved a dataset of 127 3D teeth models on the 13th of March
and 67 more on the 23rd of March. We began training and improving our model since then.
Data Description
The data we received is in the PLY file format, which is a format for storing 3D point cloud data. Each teeth model is labeled with a tooth wear grade from 1 to 4 on each tooth manually by experienced dentists. Hence, the label for a tooth model consists of 4 grades. According to the TWES2.0 standard, mentioned in the Research section, the overall tooth wear grade depends on the highest grade among the 4 teeth.
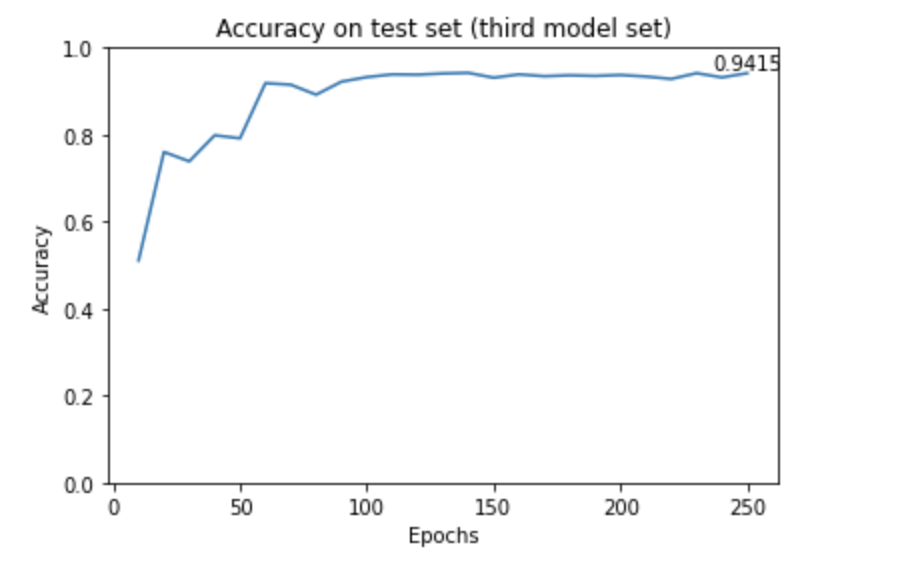
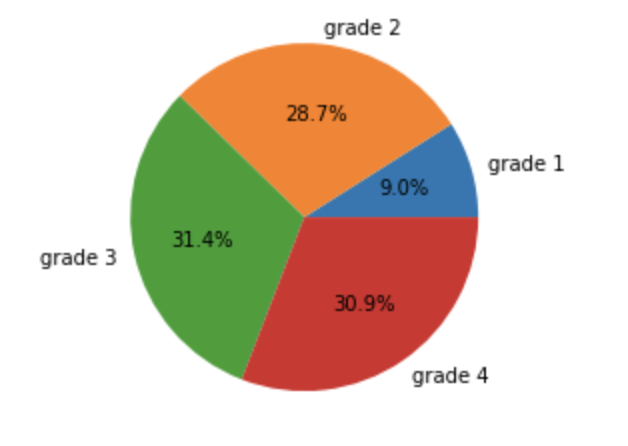
The distribution of the teeth model dataset is shown in the following pie chart.
Data Cleaning
After examining the dataset, we found that there are many teeth models that are not labeled correctly,
for example some 0's are labeled as "o", some tooth models have more than 4 grades but some have less.
Therefore, our first task was to clean the data and rectify the criteria of the labels.
After cleaning the data, we moved on to data augmentation to increase the volume of the dataset.
Data augmentation
As we only received 194 teeth models, which is insufficient to train a deep learning model, we decided to use data augmentation to increase the size of the dataset. Additionally, from the pie chart above, we can see that the dataset is imbalanced, which is not suitable for training a deep learning model. Therefore, we also need to increase the volume of data that has a grade of 1, which is obviously smaller than rest of the groups.
Method 1: Rotation
# random rotation
theta = np.random.uniform(0, np.pi * 2)
rotation_matrix = np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]])
point_set[:, [0, 2]] = point_set[:, [0, 2]].dot(rotation_matrix)
Method 2: Jitter
# random jitter
point_set += np.random.normal(0, 0.02, size=point_set.shape)
Method 3: Randomly selected
For each point cloud model, researchers usually select 1024 or 2048 points from a large number of
points.
The teeth models that we received usually contain 40k to 70k points, which is far more than we need.
Hence, we firstly randomly selected 2048 points from each tooth model and we repeated this process to
randomly select 2048 completely different points from the point set. As a result we can generate 20-30
different point cloud models from each teeth model.
# read in the ply file
with open(file, 'rb') as f:
plydata = PlyData.read(f)
pts = np.vstack([plydata['vertex']['x'], plydata['vertex']['y'], plydata['vertex']['z']]).T
# randomly choose 2048 points and delete these points from the set
num_points = np.array(len(pts))
choice = np.random.choice(num_points, self.npoints, replace=True)
num_points = np.delete(num_points, np.where(np.isin(num_points, choice)))
point_set = pts[choice, :]
# repeat the process according the how many points left
...
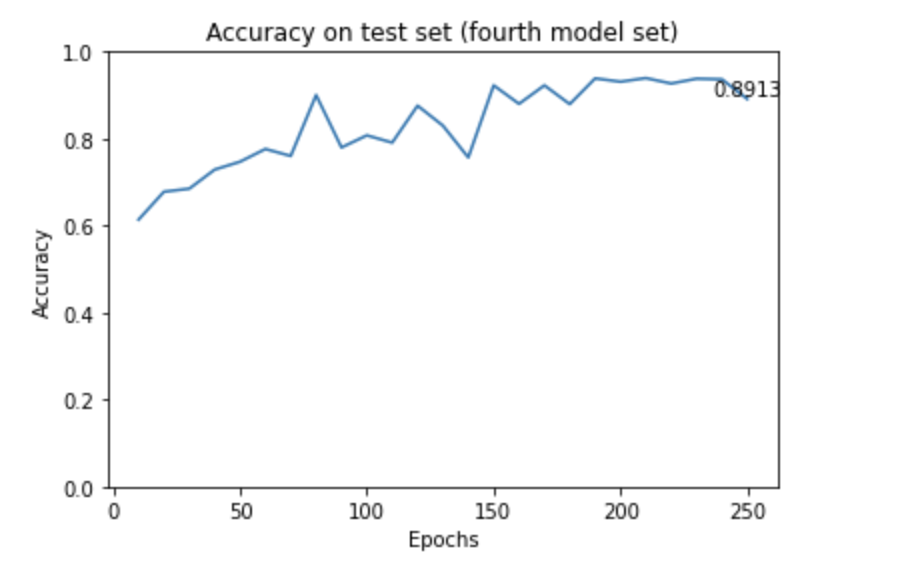
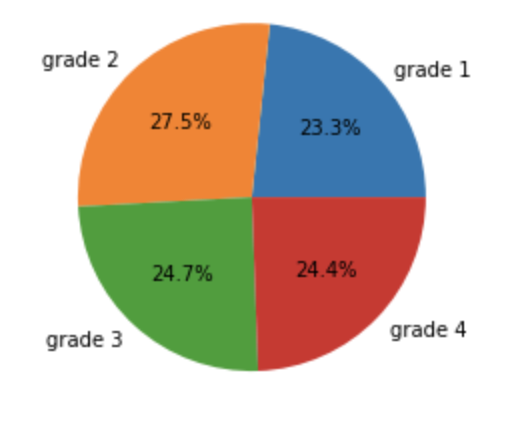
After augmenting the dataset, we increased the number of data that has a grade of 1. The new dataset distribution is much more balanced and is displayed below:
Training and Testing dataset
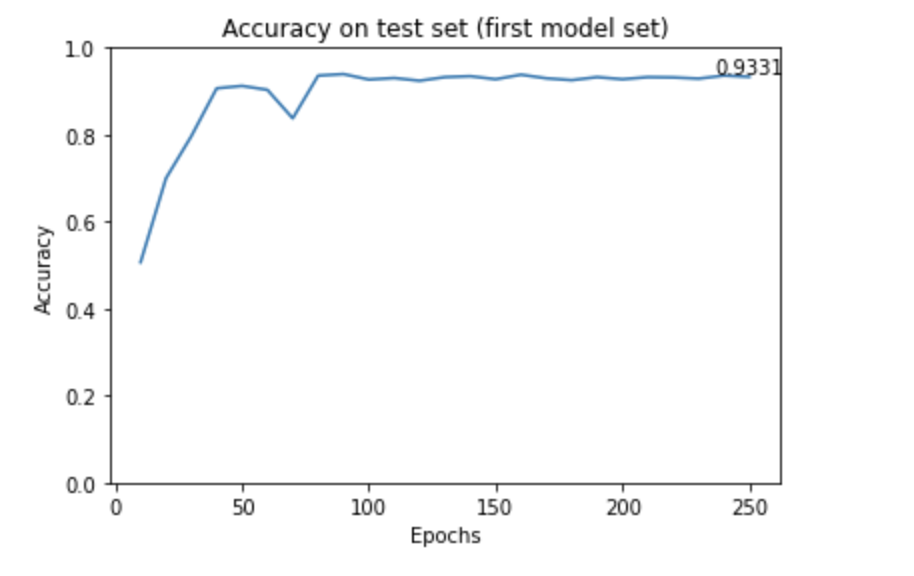
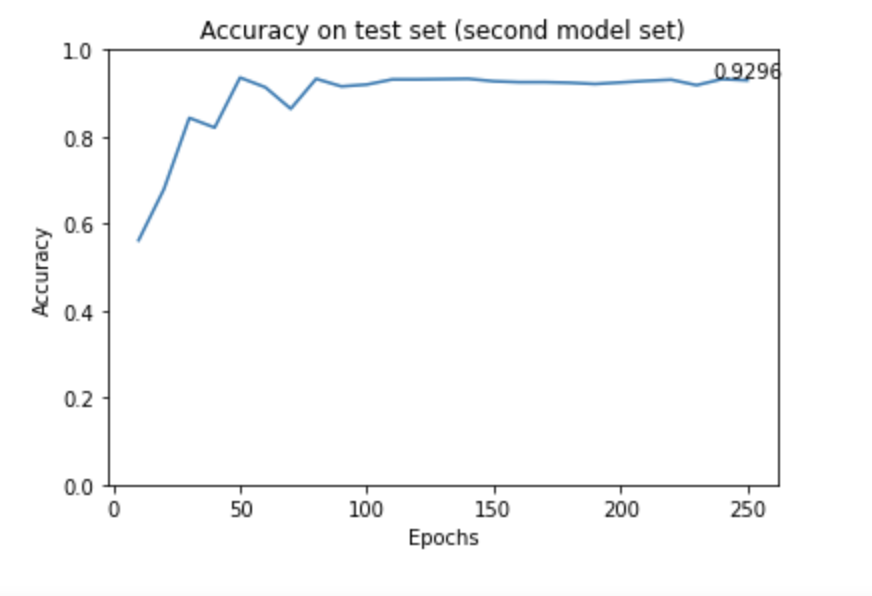
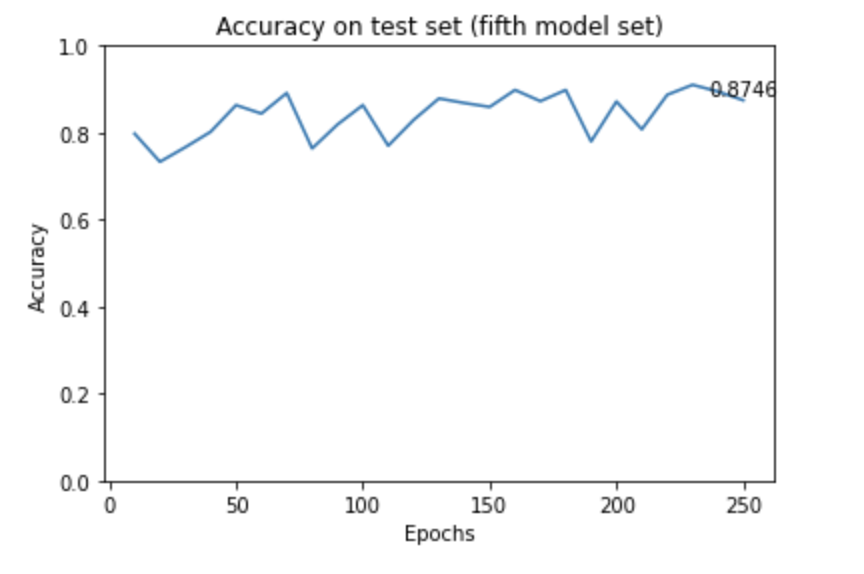
Ratio of training and testing datasets: 80% training, 20% testing
A commonly used ratio of splitting training and testing dataset is training:testing = 8:2 or 7:3. However, our dataset is relatively small and we want to have more data for training to achieve a good result. We decided to use 80% of the dataset for training and 20% for testing.
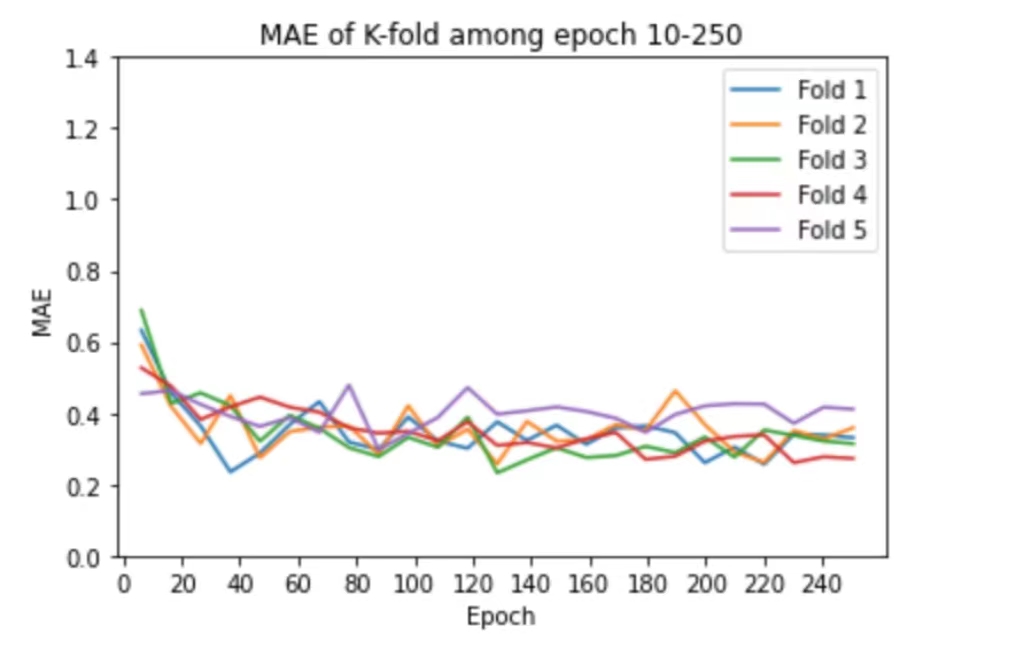
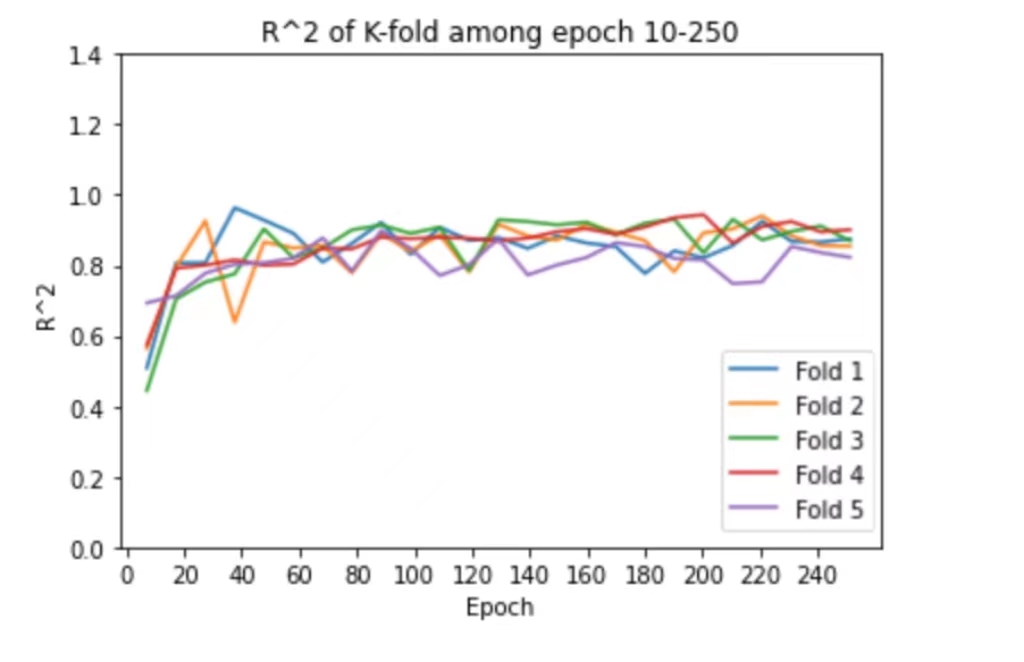
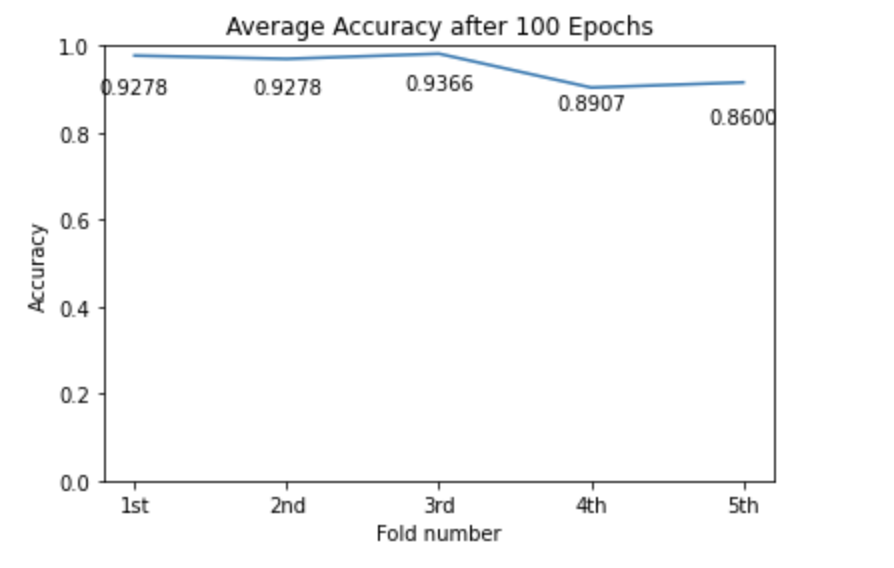
K-fold: In order to have a more accurate score, we used K-fold cross validation to train the model. We chose to use K = 5, which means we split the training dataset into 5 parts randomly, and each time we use 4 parts for training and 1 part for validating. We repeat this process 5 times and take the average score.