Algorithms
Overview
Our Quantum Proximity Gateway system incorporates multiple algorithms to ensure the highest level of security and usability. This page provides an in-depth explanation of each algorithm used within the system. The following sections cover our facial recognition algorithm, post-quantum cryptography, our AI chatbot assistant model, and natural-language-processing.
Facial Recognition Algorithm
Models
The facial recognition algorithm that we implemented in our system is based on the face_recognition library, an open-source Python library that uses deep learning models to detect and recognise faces from images or videos. The model converts human facial features into high-dimensional numerical vectors, known as face encodings, which uniquely represent each face. These encodings are created via a convolutional neural network (CNN), a deep learning network architecture that analyses visual information through pattern and feature detection [1]. To do this, the CNN uses convolution and pooling, where it applies a small filter to the image to identify specific patterns, before simplifying the the data by aggregating information.
When a new face is detected via the Raspberry Pi's camera module, its encoding is compared with a database of known encodings using Euclidean distance. A threshold-based decision mechanism then determines whether or not the match is valid: deep metric learning ensures that faces of the same person have minimal distance in the feature space, while faces of different people have the maximum distances between each other.
Data
The dataset we used for facial recognition consists of high-resolution images captured by the Raspberry Pi camera module. Each image undergoes preprocessing to extract meaningful facial features while ensuring real-time recognition performance.
- Captured faces: Images of authorised personnel stored in an encoded format.
- Real-time Frames: Continuous video feed used for live recognition.
- Environmental Variations: Data collected under different lighting conditions, angles, and facial obstructions.
- Resolution Adjustment: We resized images to strike a balance between the retention of detail and computational efficiency.
- Encoding Generation: Each detected face is converted into a 128-dimensional vector using deep metric learning.
- Color Conversion: Frames were converted to RGB format, as required by the face_recognition library.
- Noise Reduction: We discarded blurry or low-confidence frames to prevent incorrect identifications.
Since this is a real-time face recognition system, it does not have a traditional training phase. Instead, it operates by storing known face encodings and comparing incoming video frames against this dataset.
Experiments
We tested the facial recognition system using a controlled environment and real-world scenarios to measure its accuracy and performance under different conditions.
The system processes video frames from the Raspberry Pi camera in real-time. A user enters the frame, and the system attempts to detect and match their face against stored encodings. If a match is found, their profile is activated. We conducted experiments to assess the algorithm's performance using the following design:
- 1. Baseline Test: Users were asked to stand at a fixed distance and face the camera directly.
- 2. Variable Conditions: Users moved around the frame, wore accessories (glasses/masks), or appeared in different lighting.
- 3. Real-Time Scenario: The system was deployed in a dynamic environment with multiple people moving in and out of the frame.
The metrics we used to evaluate and measure the algorithm's performance are:
- Recognition Accuracy (%): Number of correct identifications vs total attempted identifications.
- False Positive Rate (FPR): Incorrect matches where an unauthorised face is recognised.
- Frame Rate (FPS) Number of frames processed per second.
- Latency (ms): Time taken for face detection and verification.
In our QPG's facial recognition system, optimising hyperparameters is necessary for balancing accuracy, speed and resource efficiency. Hyperparameters are tunable values that affect the model's image processing, face detection, and comparison with stored encodings. We explored several key hyperparameters to observe and determine their impact on system performance.
HOG vs. CNN for Face Detection
The face_recognition library supports two methods for face detection: Histogram of Oriented Gradients (HOG) and Convolutional Neural Networks (CNN). HOG is a traditional feature descriptor that detects edges and gradients in an image to identify faces. While HOG is computationally efficient, it is typically less accurate in complex environments like low light. CNN on the other hand, is a deep learning-based approach that detects faces with higher accuracy, especially in more difficult situations, but it does require more computational power. We compared each of these approaches' performance based on accuracy and processing time, and evaluated their trade-offs.
We found that CNN provides higher accuracy but is less suitable for real-time applications on low-power hardware like the Raspberry Pi. Therefore, we selected HOG for real-time face detection, while CNN could be considered for periodic re-validation of identities.
cv_scaler - Balancing Speed and Accuracy
The cv_scaler parameter controls how much an image is resized before face detection. A higher value results in a smaller image, which speeds up processing but reduces the level of detail available for recognition. We conducted experiments to test different values of cv_scaler, to measure its effect on frame rate (FPS) and recognition accuracy.
We selected cv_scaler = 8 was selected as the optimal setting, as it provides real-time performance (30 FPS) while maintaining acceptable accuracy.
Face Encoding Model - Small vs Large Model
The face_recognition library offers two pre-trained face encoding models: the Small model (model='small') uses a lightweight neural network, which offers faster encoding but lower accuracy, while the Large model (model='large') uses a deeper neural network, which generates more precise encodings but requires a longer processing time. We analysed which option would be most suitable for our system through experiments:
Given our system's focus on security, we opted for the large model, as we felt that the additional processing time was justified by the increase in accuracy.
Discussions
Unfortunately, our facial recognition algorithm did fail for some test examples. Recognition accuracy and performance degraded under these circumstances:
- Occlusions — If a user wears glasses or a mask, recognition accuracy drops.
- Lighting Conditions — Poor lighting can degrade performance.
- Low Resolution Input — If the camera resolution is too low, facial features are less distinguishable.
In order to improve performance, the stored dataset could be expanded to include variations in lighting, angles and occlusions to maintain high levels of accuracy. Addditonally, our algorithm could also incorporate a hybrid model - we could use CNN for initial face recognition, to ensure accurate face encoding, then switch to HOG for real-time tracking. This method would strike a balance between accuracy and efficiency, enabling reliable identification without excessive resource usage.
Post-Quantum Cryptography
Models
Please refer to the Research page, Post-Quantum Cryptography (PQC) Algorithm section.
Data
Our cryptographic algorithm does not require a conventional dataset in the same way that other algorithms do, as it relies on mathematical operations rather than training data. However, the process involves several key components:
- 1. Public and Private Keys: These keys are used in the KEM stage to securely establish a shared secret (key).
- 2. Shared Secret: This is the symmetric key derived from the key encapsulation process, which is then used for AES-GCM encryption.
- 3. Ciphertext and Nonce: The data encrypted using AES-GCM requires a unique nonce for each operation to prevent replay attacks. The nonce is used as an initialization vector for the counter mode of the AES encryption.
Furthermore, since PQC is a mathematical system, and is not driven by data, no data preprocessing was necessary. The keys are simply generated during execution, and the shared secret is encapsulated using the Kyber algorithm and then used in AES-GCM.
Experiments
While we already knew that CRYSTALS-Kyber provides long-term quantum resistance [2], we wanted to evaluate its performance in real-world scenarios. In order to assess the performance of the PQC system and algorithms, we conducted multiple iterations of KEM and AES-GCM to measure execution time. We then compared the results to other traditional encryption methods to analyse the efficiency and viability of our PQC in real-world environments.
To evaluate the performance of the PQC system, we measured the following factors:
- KEM Performance: The time taken for public/private key generation; time required for encapsulation of a shared secret; time required for decapsulation and retrieval of the shared secret.
- AES-GCM Encryption Performance: The time taken to encrypt data using shared secret; time taken to decrypt and verify integrity of data; key size overhead compared to traditional cryptographic algorithms including RSA-2048.
We conducted experiments as part of our testing, results explaining the overhead caused by ML-KEM-512 can be found on our Testing section under the Performance Testing subheading.
Discussions
While the combination of CRYSTALS-Kyber and AES-CGM provides quantum-resistant security, the algorithm does face challenges in certain test examples:
- Security Implications — Since AES-GCM requires a unique nonce for every encryption operation, improper handling of the nonces can lead to security vulnerabilities, such as key reuse attacks.
- Computational Overhead — While key encapsulation is efficient, the added step of using PQC introduces slight latency compared to traditional symmetric key exchanges like Diffie-Hellman.
- Larger Key Sizes —Kyber-512 public keys (800 bytes) and ciphertexts (768 bytes) are much bigger than standard RSA-2048 keys (~256 bytes), and this could introduce additional bandwidth and storage requirements.
To improve performance, we could consider the following modifications:
- Improved Key Storage — We could efficiently manage key pairs to minimise memory overhead.
- Optimised Nonce Generation for AES-GCM — Use a cryptographically secure pseudo-random number generator (CSPRNG) for nonce generation. Implement a nonce-reuse prevention mechanism to mitigate security risks.
AI Inferencing
Models
As part of the Offline AI Working Group, we were tasked with experimenting different ways of inferencing, these types of LLMs, whilst making sure they were efficient and embeddable as executables. There were two options that our team really considered, native compilation using llama.cpp or Ollama-based inferencing.
The AI chatbot in our QPG system is powered by a Large Language Model (LLM), using IBM's Granite 3.2-8B-Instruct model. The model is specifically trained for creating human-like text responses and operates through an instruction-based system, in which it is guided to reply in structured JSON format.
Data
When interacting with the chatbot, user input is tokenised and decoded into a format that the model can utilise. Tokenisation breaks down the input text into small pieces (tokens), which are then mapped to embeddings. These embeddings allow the model to process and generate text efficiently. That is the high-level overview of how these LLM inferencing programs work.
Our specific chatbot needs to operate in a JSON format, which means that all responses are structured acccordingly. The model is explicitly instructed to return responses in JSON in a "message" field, so that the output's formatting is consistent in order to be processed in later parts of the system.
Experiments
We assessed the inferencing performance through varied test cases, where the same prompts were given to the model, and we evaluated the inferencing performance. These test cases simulate real world examples, specifically the customisation of user preferences, which was the intended function of the chatbot.
We measured the performance of this algorithm using the following criteria:
- Tokens per Second: The number of tokens generated every second by each implementation.
- Response Latency: The time taken to generate a response, measured in milliseconds.
We conducted a performance comparison between the Ollama framework and the llama.cpp implementation. The results, as illustrated in the performance graph below, show that while Ollama maintains a more stable token generation rate over multiple message exchanges, the llama.cpp implementation exhibits a gradual decline in performance. This highlights potential inefficiencies in memory management, or computational overhead in llama.cpp for prolonged interactions.
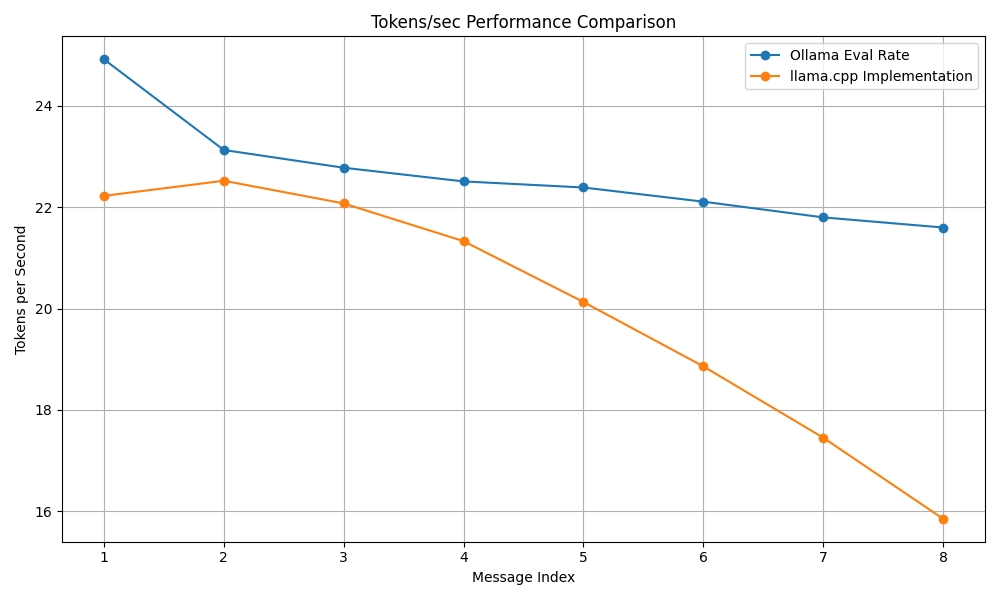 Figure 1: Performance comparison of token generation rates between Ollama and llama.cpp
Figure 1: Performance comparison of token generation rates between Ollama and llama.cppThe above graph shows the rate of token generation per second as the chatbot processes multiple messages. Further optimisations in thread allocation and caching mechanisms could help bridge the performance gap.
Discussions
We could easily conclude that utilising ollama as our choice of LLM inferencing was the best option, due to the backend optimization that the Ollama team could perform that we could not. This was further confirmed by Bill Higgins (IBM VP Watson X), after a presentation for IBM OIC where he encouraged our team to keep exploring Ollama.
However, we are still very proud of the work we completed as it also empowered other teams in our year to clone our repository and try out the llama.cpp inferencing on their own projects.
Natural Language Processing
Models
A natural language processing (NLP) algorithm is a complex mathematical formula used to train computers to understand, interpret and generate human language. The primary objective of our NLP algorithm is to ensure that the AI model used in the chatbot only retrieves relevant commands from a JSON dataset based on a user’s query, minimising hallucinations. To achieve this, we explored multiple text similarity algorithms:
- Jaro-Winkler Similarity — This algorithm is a string metric used to measure the similarity between two sequences of characters [3]. We initially tested this algorithm due to its efficiency in handling short strings, however it struggled with longer phrases.
- Cosine Similarity — This measures the similarity between two vectors by calculating the cosine of the angle between them, ranging from -1 to 1, with values closer to 1 indicating higher similarity. We selected cosine similarity as the final approach due to its ability to handle multi-word phrases and capture contextual meaning through vector representations.
Data
The dataset consists of JSON-formatted command configurations for different operating systems. Each command contains a setting name (e.g. "zoom", "cursor-size") and a specific terminal or API command for Windows, macOS and Linux.
Before running similarity comparisons, we preprocessed the JSON to extract only the necessary information. This involved:
- Identifying the current operating system to filter OS-specific commands
- Extracting setting names and their corresponding commands
- Removing unnecessary metadata from the JSON
Since this is a retrieval-based system rather than a traditional machine-learning model, no explicit training set is required. Instead, we used a validation set
Experiments
We tested the NLP algorithm by evaluating its ability to correctly match user queries to the most relevant command from the JSON dataset. The experiment consisted of:
- 1. Manually curated test cases with different phrasings of the same command request
- 2. User-based testing to analyse real world performance.
- 3. Comparative testing between Jaro-Winkler and Cosine Similarity
We measured performance using:
- Accuracy (%): Percentage of test cases where the correct command was retrieved.
- Precision & Recall: To evaluate false positives and false negatives.
- Response Time: Average time taken to match a query.
- Latency (ms): Time taken for face detection and verification.
Cosine Similarity significantly outperformed Jaro-Winkler, particularly in handling longer queries. Although Jaro-Winkler was faster, its lower accuracy made it unsuitable for practical use.
Discussions
Unfortunately, some queries still failed to retrieve the correct command, for reasons including:
- Low Similarity Scores: — Some user inputs contained terminology that differed from the dataset’s key phrases (e.g., “font enlargement” instead of “zoom”).
- Ambiguous Queries — If a query matched multiple commands equally, incorrect retrieval occurred.
In order to improve performance, we could implement query expansion, using NLP techniques like synonym detection to expand user queries and match them to similar terms in the dataset. We could also combine Cosine Similarity with rule-based filtering to improve accuracy for ambiguous queries.
Conclusion
In conclusion, our Quantum Proximity Gateway solution integrates several highly advanced algorithms to drive security, efficiency, and usability. We've optimised facial recognition, post-quantum cryptography, AI inferencing, and natural language processing through extensive testing and analysis to deliver consistent real-time performance.
For face recognition, we optimised our approach with deep metric learning, balancing computational efficiency and accuracy by fine-tuning hyperparameters. Our system remains robust to variations in environment, like lighting and occlusions, and can be improved further using hybrid detection models and increasing the dataset.
Our integration of post-quantum cryptography with CRYSTALS-Kyber and AES-GCM is quantum-attack secure with strong security. Having low computational overhead and larger key sizes compared to RSA, our experiments confirm its long-term viability for secure key exchanges. Efficiency can be improved with optimizations in nonce management and key storage.
AI inferencing was also compared with different deployment models, where Ollama proved to be more stable and with a greater token generation rate compared to llama.cpp. This option, as confirmed by industry testing, ensures maximum chatbot responsiveness while maintaining formatted JSON output.
For natural language processing, Cosine Similarity was preferred over Jaro-Winkler due to its superior long query support and contextual appropriateness. The algorithm is strong at linking user commands to JSON-based settings, but further enhancement in synonym detection and rule-based filtering can help improve disambiguation in ambiguous cases.
Overall, our research and experimentation have yielded a highly efficient and secure system. Future iterations will focus on making the real-time processing even more robust, less susceptible to environmental factors, and increasingly secure from future threats.
References
- [1]GeeksforGeeks, "Introduction to Convolution Neural Network", Oct. 10, 2024. [Online]. Available: https://www.geeksforgeeks.org/introduction-convolution-neural-network/. [Accessed March 28, 2025].
- [2]P. Schwabe, "Kyber", Dec. 23, 2020. [Online]. Available: https://pq-crystals.org/kyber/. [Accessed March 28, 2025].
- [3]J. Wellington, "Implementing the Fastest (Pseudo) Jaro-Winkler Algorithm in Rust", June 24, 2022. [Online]. Available: https://tech.popdata.org/speeding-up-Jaro-Winkler-with-rust-and-bitwise-operations/. [Accessed March 28, 2025].