Implementation
AI music teacher backend
FastAPI with llama.cpp
Project Structure Overview
Jamboxx-infinite-backend-llama
jamboxx_infinite_backends/
├── app/
│ ├── main.py # Entrypoint with FastAPI app
│ ├── services/ # Llama.cpp logic goes here
│ ├── config.py # Configuration (e.g., model path, llama-cli settings)
│ ├── models/ # Pydantic models for request/response
│ └── api/ # Route definitions
├── run.py # Development entry script
├── requirements.txt # Dependencies
└── README.md
FastAPI Endpoint /chat/
Key Features
- Pydantic Models: Used for request/response data validation and parsing.
- Llama.cpp Service Integration: Implements model inference using llama-cli.
- App Initialization: Configures the FastAPI app and related services.
Unity Frontend Integration
Key Functionalities
- Uses
UnityWebRequestto send POST requests to FastAPI athttp://127.0.0.1:8001/chat/. - Sends a prompt string in JSON format to the backend.
- Receives streamed responses via
DownloadHandlerRawText, updating the chat history in real time. - UI elements include:
- Mood/genre dropdowns
- A slider for song length
- A panel for lyrics
Data Flow Diagram
[Unity UI]
↓ (prompt)
[LlamaManager.cs]
↓ (POST request /chat/)
[FastAPI Endpoint]
↓
[Llama Service (llama-cli, mitral-7b)]
↓
[Model Output]
↓
[Unity UI Updated]
AI voice cloning backend
Jamboxx-infinite-Backend-AI-Voice-Clone
Key Feature: Audio Processing Pipeline
Overview
[Jamboxx-infinite-AI-voice-clone-backend]
The audio processing pipeline is a core feature of the project, enabling users to process audio files through multiple stages: separation, voice conversion, and merging. This feature is implemented using the FastAPI framework for building RESTful APIs, along with several specialized libraries for audio processing, such as NumPy, SoundFile, and PyTorch.
The pipeline is designed to handle complex audio processing tasks while maintaining modularity and scalability. Each stage of the pipeline is implemented as a separate service, ensuring clear separation of concerns and reusability.
Frameworks and Libraries Used
- FastAPI: Provides the API endpoints and request handling.
- NumPy: Used for numerical operations on audio data.
- SoundFile: Handles reading and writing audio files in various formats.
- PyTorch: Powers the machine learning models for voice conversion and audio separation.
- aiofiles: Enables asynchronous file operations for efficient I/O handling.
- UUID: Generates unique identifiers for temporary and output files.
- Logging: Logs debug and error information for monitoring and debugging.
Project Structure and Functional Analysis
The project is structured to implement a modular and scalable backend for audio processing tasks. Below is an analysis of the functionality implemented in each folder based on the provided file paths and code.
1. routers
Purpose: This folder contains the API route definitions for the FastAPI application. It acts as the entry point for client requests and orchestrates the interaction between services.
- Key File: router.py
- Implements endpoints for various audio processing tasks:
/voice/convert: Handles voice conversion using the DDSP-SVC model./audio/separate: Separates audio into vocals and instruments./audio/merge: Merges vocals and instruments into a single audio file./audio/process-all: A complete pipeline that combines separation, conversion, and merging./model/loadand/model/info: Manage and retrieve information about the loaded machine learning models.
- Frameworks Used:
- FastAPI: For defining RESTful API endpoints.
- Pydantic: For request parameter validation.
- aiofiles: For asynchronous file handling.
- Key Features:
- Modular endpoints for each audio processing task.
- Error handling and logging for debugging and monitoring.
- Temporary file management to ensure efficient resource usage.
- Implements endpoints for various audio processing tasks:
2. services
Purpose: This folder contains the core business logic for audio processing. Each service encapsulates a specific functionality, making the codebase modular and reusable.
- Key Files:
ddsp_service.py:- Implements the DDSP-SVC (Differentiable Digital Signal Processing - Singing Voice Conversion) model for voice conversion.
- Provides methods like
inferto process audio files with configurable parameters (e.g., speaker ID, pitch adjustment). - Frameworks Used:
- PyTorch: For running the DDSP-SVC model.
- NumPy: For numerical operations on audio data.
- Key Features:
- Supports dynamic model loading and inference.
- Handles pitch extraction and audio enhancement.
separator_service.py:- Implements audio source separation using a pre-trained Demucs model.
- Provides methods like
separate_tracksto split audio into vocals and instruments. - Frameworks Used:
- PyTorch: For running the Demucs model.
- SoundFile: For reading and writing audio files.
- Key Features:
- Processes multi-channel audio data.
- Normalizes and validates audio to ensure compatibility with downstream tasks.
- Also includes
merge_tracksfor combining separated audio tracks with configurable volume levels.
3. app/static/
Purpose: This folder serves as the storage location for processed audio files that are accessible via static URLs.
- Subdirectories:
convert/: Stores converted audio files from the/voice/convertendpoint.separator/: Stores separated audio files (vocals and instruments) from the/audio/separateendpoint.merge/: Stores merged audio files from the/audio/mergeendpoint.pipeline/: Stores the final output of the complete audio processing pipeline from/audio/process-all.
- Key Features:
- Organized storage for processed files.
- Enables clients to download files via static URLs.
4. app/models/
Purpose: This folder likely contains pre-trained machine learning models used for audio processing tasks.
- Key Features:
- Stores models for DDSP-SVC and Demucs.
- Supports dynamic model loading via the
/model/loadendpoint.
5. utils
Purpose: This folder likely contains utility functions for common tasks such as file handling, logging, and data validation.
- Key Features:
- Functions for saving and cleaning up temporary files.
- Helper methods for logging and error handling.
6. app/tests/
Purpose: This folder likely contains unit and integration tests for the application.
- Key Features:
- Tests for API endpoints to ensure correct functionality.
- Mocking of services to isolate and test individual components.
- Validation of edge cases and error handling.
7. app/main.py
Purpose: This file is likely the entry point for the FastAPI application.
- Key Features:
- Initializes the FastAPI app and includes the routers from routers.
- Configures middleware, logging, and static file serving.
Summary of Functional Design
The project is designed with a clear separation of concerns:
- Routers handle API requests and responses.
- Services encapsulate the core business logic for audio processing.
- Static Files provide a mechanism for serving processed audio files.
- Models and Utilities support the core functionality with reusable components.
Folder-Level Functional Analysis
The project is organized into several key folders, each serving a specific purpose in the audio processing pipeline. Below is an academic analysis of the functionality implemented in the enhancer, encoder, nsf_hifigan, and ddsp folders.
1. enhancer
Purpose: Implements audio enhancement functionality, focusing on improving the quality of audio signals after processing.
- Key File: enhancer.py
- Class:
Enhancer- Provides an interface for enhancing audio signals using different enhancement models.
- Supports adaptive key adjustments and silence padding for better audio quality.
- Uses NsfHifiGAN as the primary enhancement model.
- Class:
NsfHifiGAN- Implements a neural vocoder based on HiFi-GAN for high-quality audio synthesis.
- Includes methods for mel-spectrogram extraction and audio generation.
- Dependencies:
- PyTorch: For model inference.
- STFT: For mel-spectrogram computation.
- Resample: For resampling audio to match model requirements.
- Class:
Key Features:
- Adaptive resampling and pitch adjustment for enhanced audio fidelity.
- Modular design to support additional enhancement models in the future.
2. encoder
Purpose: Provides feature extraction and encoding capabilities for audio signals, enabling downstream tasks like pitch extraction and content vector generation.
-
Subfolder:
hubert/- File:
model.py- Implements the HuBERT model for extracting soft content vectors from audio.
- Uses Fairseq and Transformers libraries for model loading and inference.
- Supports multiple configurations for different feature extraction needs.
- File:
-
Subfolder:
rmvpe/- Files:
model.py: Implements the RMVPE model for robust pitch extraction.inference.py: Provides utilities for running inference with the RMVPE model.seq.py,spec.py: Handle sequence and spectrogram processing for pitch extraction.constants.py: Defines constants used across the RMVPE implementation.
- Key Features:
- High-accuracy pitch extraction using RMVPE.
- Modular design for integrating additional pitch extraction algorithms.
- Files:
Key Features:
- Encodes audio into feature representations (e.g., pitch, content vectors) for use in voice conversion and synthesis.
- Supports multiple feature extraction models, including HuBERT and RMVPE.
3. nsf_hifigan
Purpose: Implements the NsfHiFiGAN neural vocoder for high-quality audio synthesis.
- Key Files:
models.py: Defines the architecture of the NsfHiFiGAN model.nvSTFT.py: Implements the Short-Time Fourier Transform (STFT) for mel-spectrogram computation.env.py: Handles environment-specific configurations for the vocoder.utils.py: Provides utility functions for model loading and inference.
Key Features:
- High-quality audio synthesis using neural vocoding techniques.
- Efficient mel-spectrogram computation and audio generation.
- Modular utilities for model loading and configuration.
Dependencies:
- PyTorch: For model training and inference.
- STFT: For spectrogram-based audio processing.
4. ddsp
Purpose: Implements the Differentiable Digital Signal Processing (DDSP) framework for voice conversion and synthesis.
- Key Files:
- vocoder.py: Implements the F0_Extractor and other utilities for pitch extraction and audio synthesis.
- Class:
F0_Extractor- Extracts fundamental frequency (F0) from audio using algorithms like Parselmouth, PyWorld, and RMVPE.
- Supports adaptive resampling and silence trimming for accurate pitch extraction.
- Class:
core.py: Provides core utilities for frequency filtering, upsampling, and other DSP operations.unit2control.py: Maps unit features to control signals for synthesis.loss.py: Defines loss functions for training DDSP models.pcmer.py: Implements pitch contour modeling for enhanced synthesis.
- vocoder.py: Implements the F0_Extractor and other utilities for pitch extraction and audio synthesis.
Key Features:
- Modular design for pitch extraction, unit encoding, and audio synthesis.
- Integration with multiple pitch extraction algorithms (e.g., Parselmouth, RMVPE).
- Differentiable DSP operations for end-to-end training and inference.
Dependencies:
- PyTorch: For model training and inference.
- Parselmouth and PyWorld: For pitch extraction.
- Resampy: For audio resampling.
Summary of Folder-Level Contributions
enhancer/: Focuses on post-processing and enhancing audio quality using neural vocoders like NsfHiFiGAN.encoder/: Provides feature extraction capabilities, including pitch and content vector encoding, using models like HuBERT and RMVPE.nsf_hifigan/: Implements the NsfHiFiGAN vocoder for high-quality audio synthesis.ddsp/: Implements the DDSP framework for voice conversion and synthesis, including pitch extraction and differentiable DSP operations.
This modular structure ensures that each folder encapsulates a specific aspect of the audio processing pipeline, enabling scalability, maintainability, and ease of integration.
Implementation Details
1. Audio Separation
The first step in the pipeline is separating the input audio into vocals and instruments. This is achieved using the AudioSeparatorService class, which leverages a pre-trained Demucs model for source separation.
- Input: A single audio file uploaded by the user.
- Output: Two separate audio files (vocals and instruments) saved as temporary files.
Code Snippet:
vocals, instruments, sr = await separator_service.separate_tracks(input_path)
sf.write(vocals_path, vocals, sr)
sf.write(instruments_path, instruments, sr)
- Key Steps:
- The input audio is validated and converted to a compatible format.
- The
separate_tracksmethod processes the audio and returns the separated tracks. - The separated tracks are normalized and saved to temporary files.
2. Voice Conversion
The second step involves converting the vocals using a DDSP-SVC (Differentiable Digital Signal Processing - Singing Voice Conversion) model. This is handled by the DDSPService class.
- Input: The separated vocals file and user-specified parameters (e.g., speaker ID, pitch adjustment).
- Output: A converted vocals file.
Code Snippet:
result_path = ddsp_service.infer(
input_path=vocals_path,
output_path=converted_vocals_path,
spk_id=speaker_id,
key=key,
enhance=enhance,
pitch_extractor=pitch_extractor,
f0_min=f0_min,
f0_max=f0_max,
threhold=threhold,
enhancer_adaptive_key=enhancer_adaptive_key
)
- Key Steps:
- The
infermethod applies the DDSP-SVC model to the vocals file. - Parameters such as pitch adjustment and speaker ID are passed to customize the conversion.
- The converted vocals are saved to a temporary file.
- The
3. Audio Merging
The final step merges the converted vocals with the original instruments. This is performed using the merge_tracks method of the AudioSeparatorService.
- Input: The converted vocals file, the instruments file, and volume multipliers for each track.
- Output: A merged audio file.
Code Snippet:
merged_path = await separator_service.merge_tracks(
vocals_path=converted_vocals_path,
instruments_path=instruments_path,
output_path=output_path,
vocals_volume=vocals_volume,
instruments_volume=instruments_volume
)
- Key Steps:
- The
merge_tracksmethod adjusts the volume of each track and combines them into a single audio file. - The merged file is saved to a static directory for client access.
- The
Sequence Diagram
Below is a high-level sequence diagram illustrating the pipeline:
User -> FastAPI Endpoint (/audio/process-all)
-> AudioSeparatorService.separate_tracks()
-> Separate vocals and instruments
-> DDSPService.infer()
-> Convert vocals
-> AudioSeparatorService.merge_tracks()
-> Merge converted vocals with instruments
-> Return JSON response with file URLs
Error Handling and Cleanup
- Error Handling: Each stage of the pipeline is wrapped in a
try-exceptblock to catch and log errors. If an error occurs, an appropriate HTTP response is returned. - Temporary File Cleanup: Temporary files are deleted in the
finallyblock to prevent resource leaks.
Code Snippet:
finally:
for path in temp_files:
if path and os.path.exists(path):
os.unlink(path)
Conclusion
The audio processing pipeline is a robust and modular implementation that leverages state-of-the-art machine learning models and efficient file handling techniques. By combining FastAPI with specialized audio libraries, the project achieves high performance and scalability while maintaining code clarity and reusability.
Unity frontend
Virtual Instruments
Feature for playing virtual instruments with multiple input methods:
The script clickableButton.cs implements an interactive button system that handles multiple input methods (mouse clicks, keyboard presses, and hover interactions) with visual and audio feedback.
System works with a KeyMappingManager and PlayModeManager.
Attach script to every note of instrument.
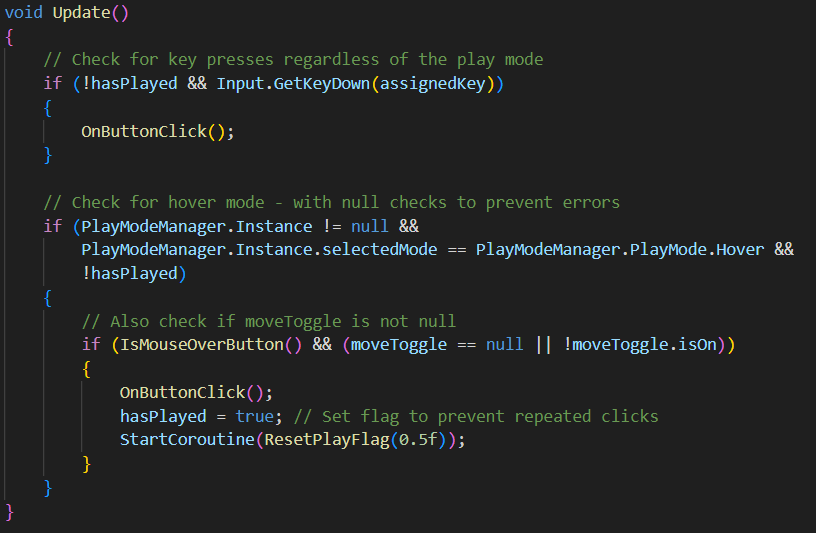
- Checks for assigned key presses to play note sound
- Handles hover mode interactions (IsMouseOverButton() checks position of mouse)
- Prevents rapid repeated triggers with hasPlayed flag (ResetPlayFlag method to reset hasPlayed flag to false after set duration in script)
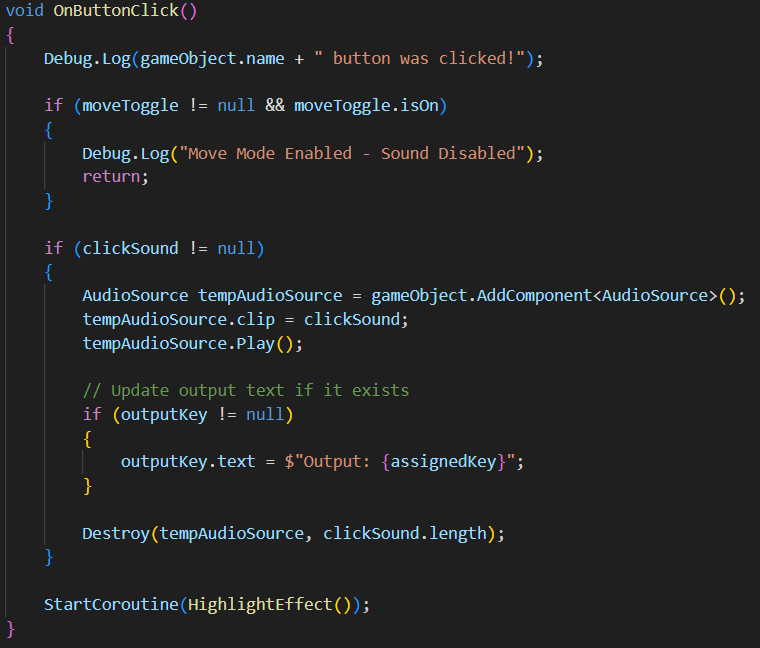
- Play sound effect with temporary AudioSource (assigned audio file to note in Unity Inspector)
- Updates output text display
- Triggers visual highlight effect (HightlightEffect method temporarily changes button color to gray to visualise click, returning to original color after specified duration)
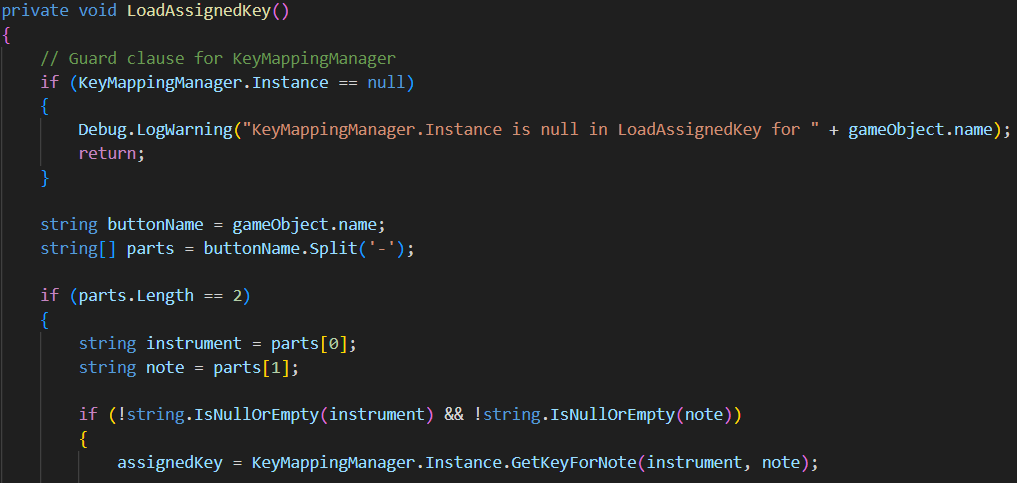
- Button loads its assigned key from KeyMappingManager based on its name (formatted as “instrument-note”)
- Explanation for GetKeyForNote method in KeyMappingManager.cs script
Feature for moving notes of virtual instruments:
The movableButton.cs script implements a draggable UI button system that allows users to reposition buttons on screen when in “move-mode”. Script utilises Unity’s Event System interfaces to handle pointer interactions.
Attach script to every note of instrument.
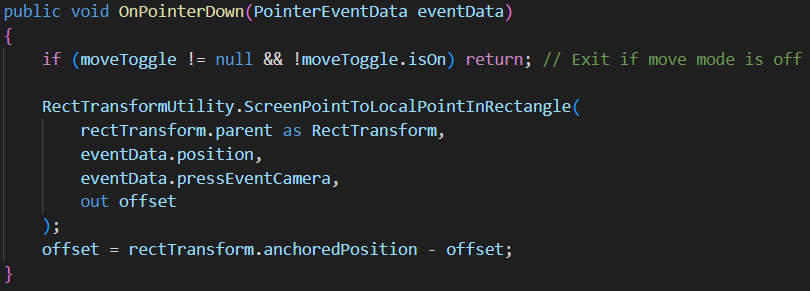
- Checks if move mode is enabled via the toggle
- Calculates the offset between:
- The click position (in local space of parent RectTransform)
- The button’s current position
- Stores this offset to use during dragging

- Checks if move mode is enabled
- Converts screen position to local position within parent
- Updates button position using initial offset to maintain relative positioning
Feature for recording playing instruments:
The InstrumentRecorder.cs script implements a complete audio recording system for Unity that captures microphone input and saves it as WAV files. The system provides a user interface with start/stop controls and status feedbacks
Script attached to RecordingManager (empty) object.
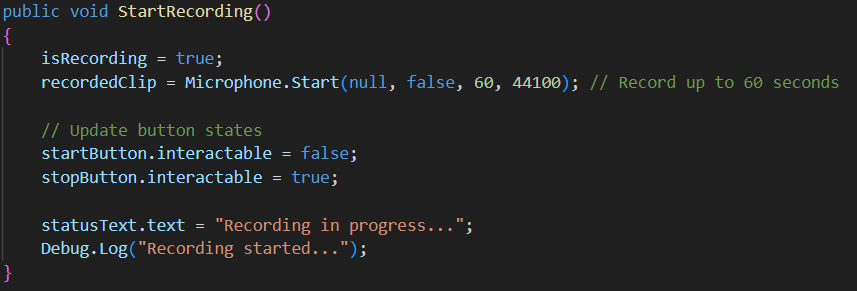
- Begins microphone capture for 60 seconds max at 44.1kHz (duration can be modified here)
- Updates button states and status text (start button cannot be clicked and stop button can be clicked)
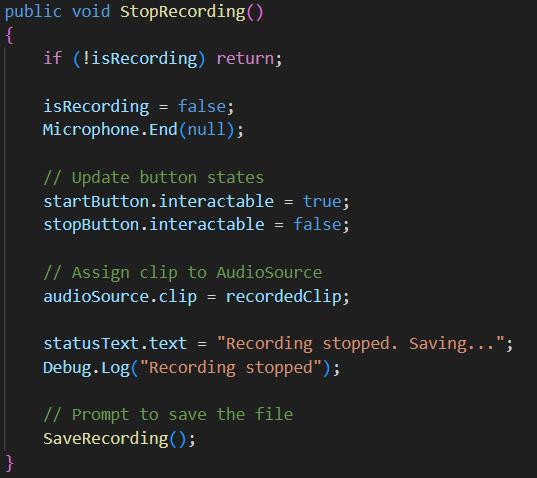
- Stops microphone capture
- Updates UI (start button can be clicked whereas stop button cannot be clicked)
- Prepares for file saving
- Configures file browser for WAV files
- Calls SaveAbsolutePath method in SavWav.cs script for saving file to any specified location
- Handles both successful save and cancel scenarios
- Provides user feedback through status text (HideStatusTextAfterDelay method used to clear status message after set delay of 3 seconds)
Settings
Feature: Selecting instrument from dropdown
The InstrumentSelector.cs script implements an instrument selection system that allows users to choose between different virtual instruments through a dropdown UI. This manages the visibility of instrument GameObjects based on user selection.
Script attached to InstrumentManager (empty) object.

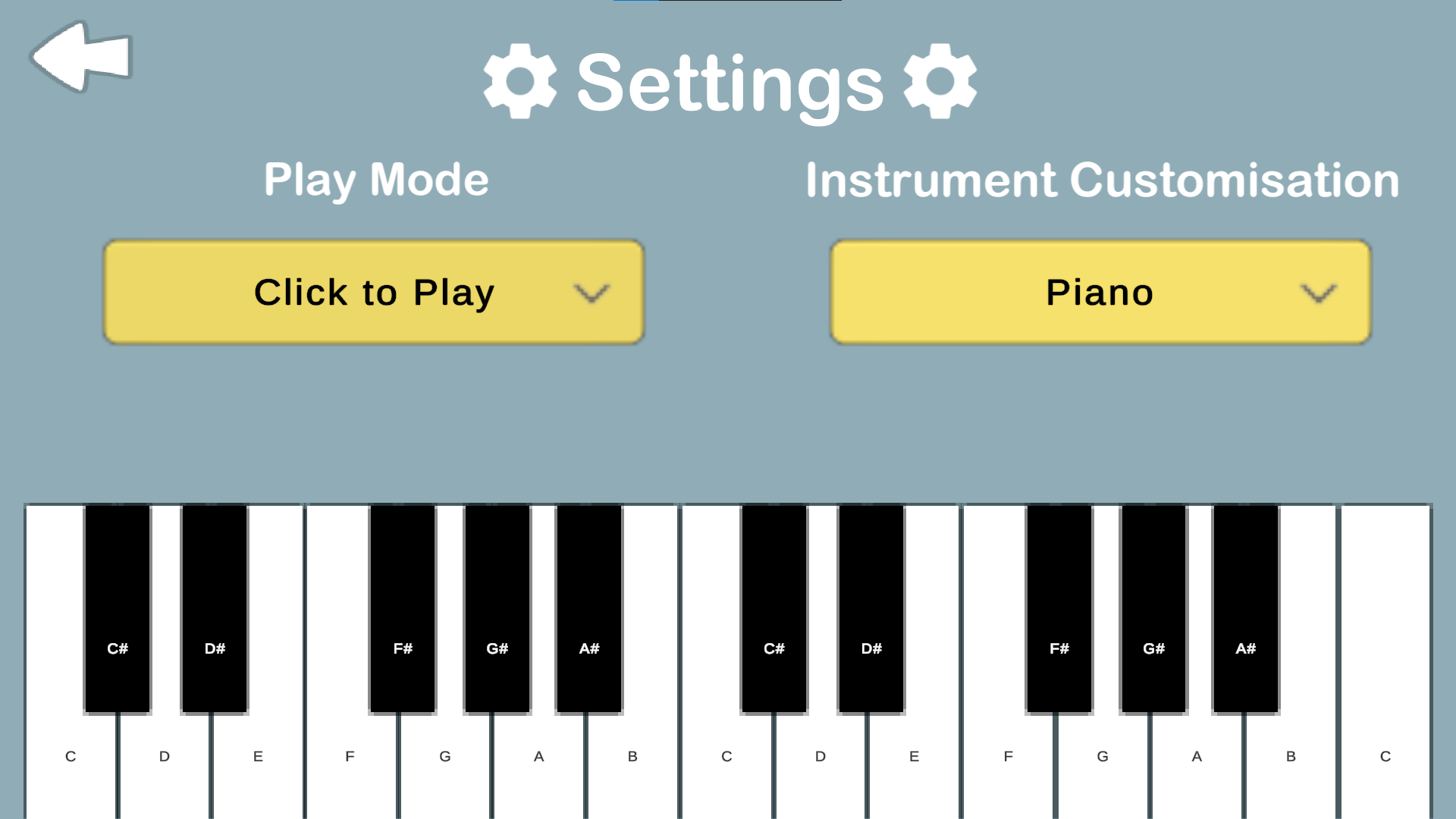
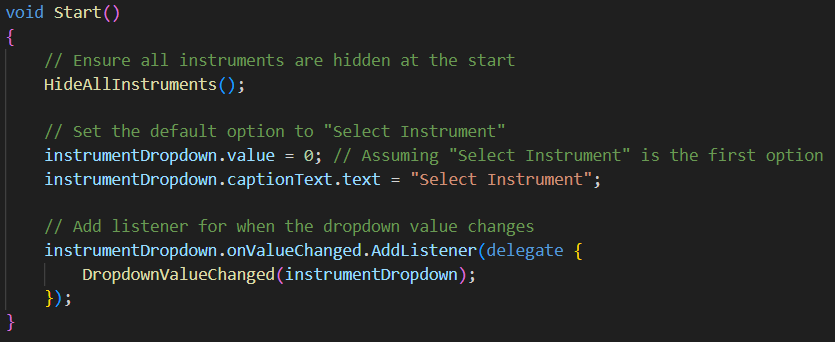
- Hides all instruments initially when load into Settings page (HideAllInstruments sets the instruments .SetActive to false to hide the instrument)
- Sets default dropdown selection to “Select Instrument”
- Adds listener for selection changes
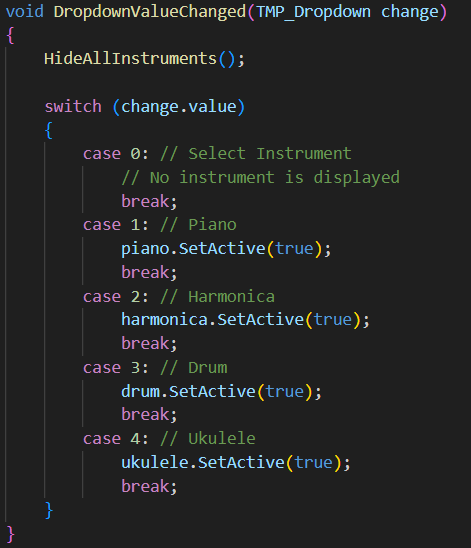
- Hides all instruments to ensure no instruments are active
- Uses switch-case to show selected instrument
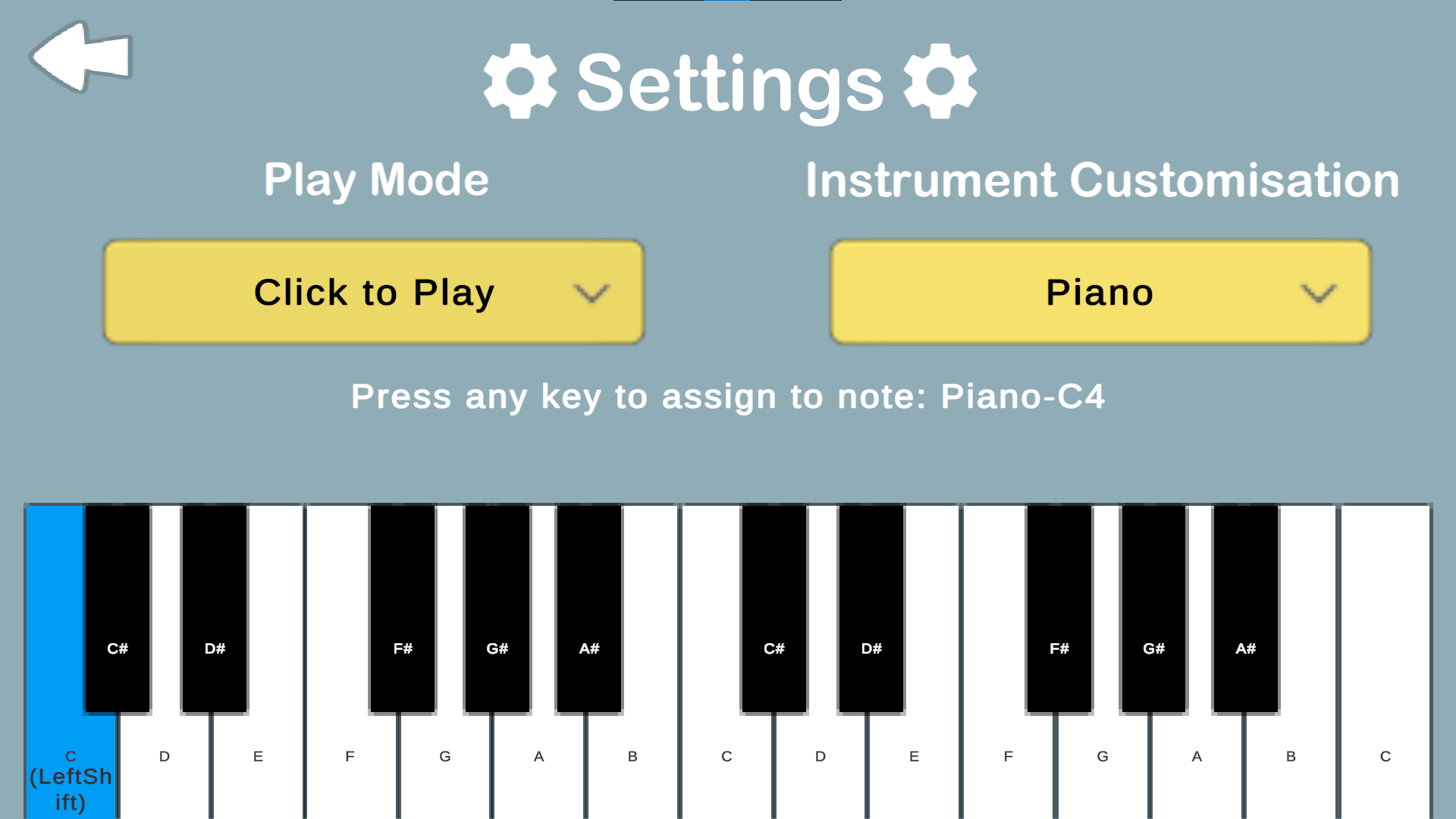
Feature for assigning keys to notes:
The KeyMappingManager.cs script implements a comprehensive key binding system that allows users to assign custom keyboard keys to different instrument notes. It serves as a persistent singleton that maintains key mapping across all scenes in the project and provides visual feedbacks when selecting notes in Settings page.
Script attached to KeyMappingManager (empty) object in Settings and Dashboard scenes.
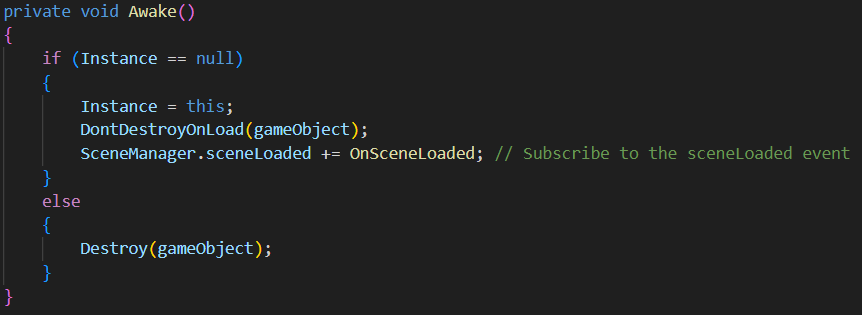
- Implements singleton pattern to remain persistent across scene loads
- Subscribes to scene change events
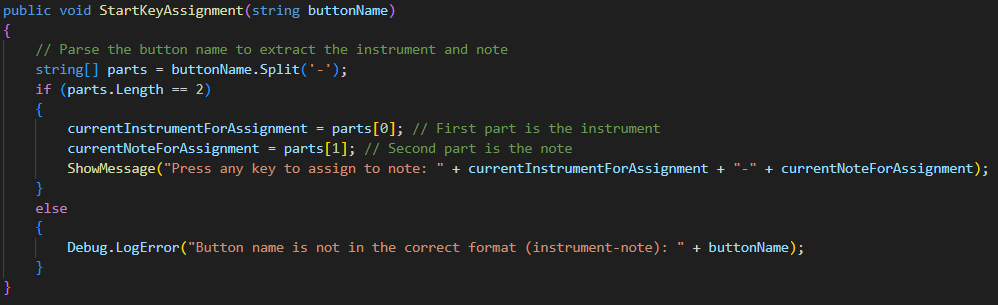
- Parses button names (following the format of “instrument-note”)
- Initiates key listening mode
- Provides user feedback (ShowMessage displays the message in script)
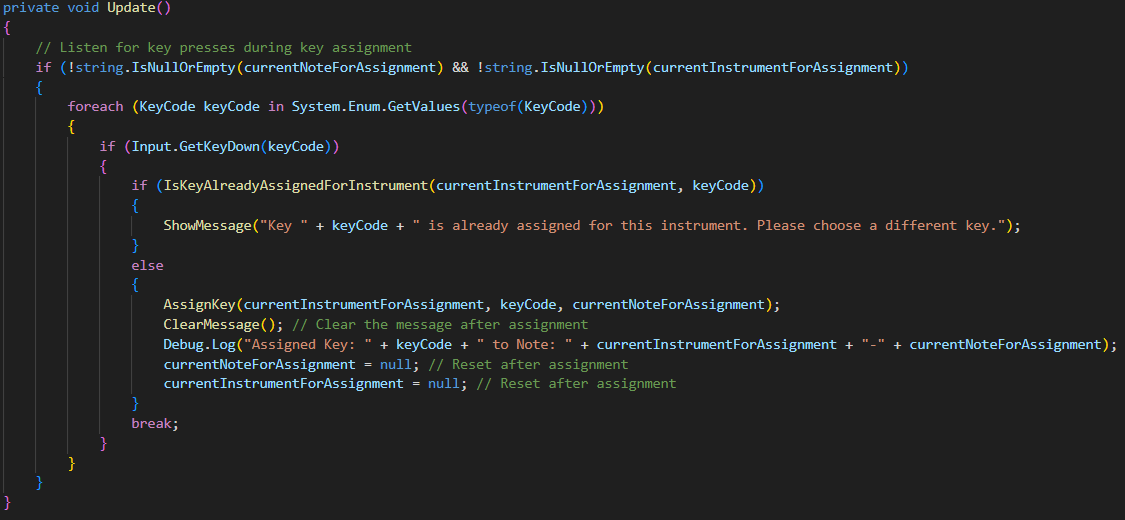
- Checks all possible keys each frame
- Prevents duplicate assignments (IsKeyAlreadyAssignedForInstrument checks the key mapping if a key is already assigned for the specific instrument)
- Handles successful assignments
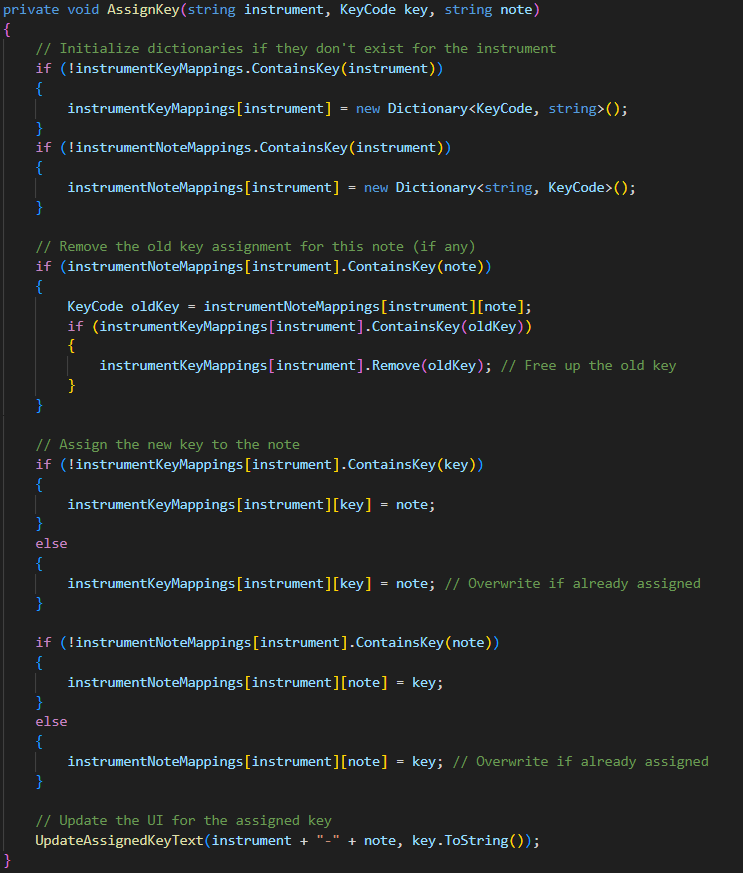
- Maintains two separate dictionaries for efficient lookup
- Handles overwriting existing mappings
- Organises by instrument
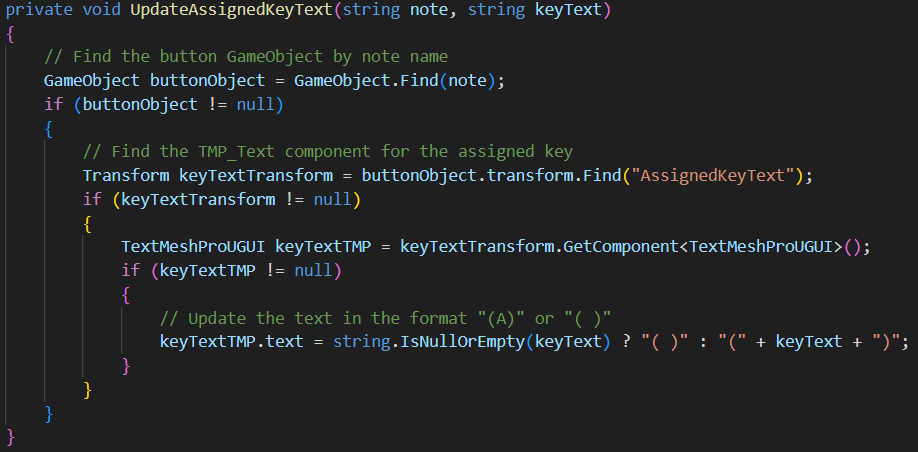
- Updates TMP_Text object called “AssignedKeyText” (attached as a child to each note) to display assigned key for that specific note
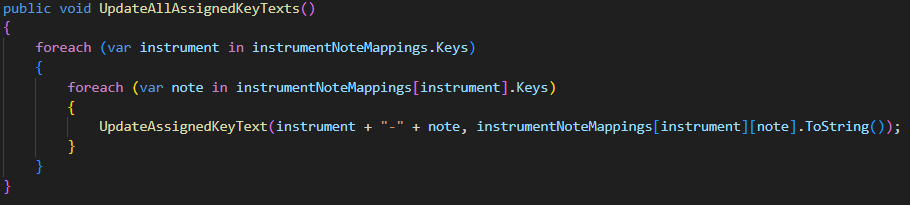
- Ensures that all assigned key texts are updated when scene is loaded
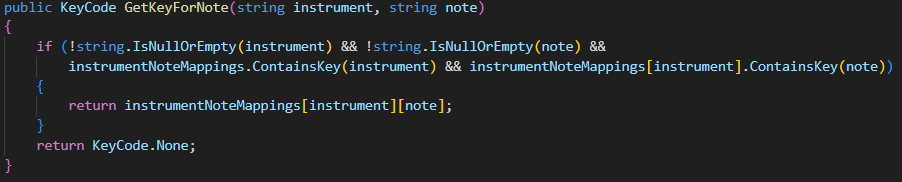
- Get the assigned key for a specific note and instrument
- Used in clickableButton.cs to load the assigned key for each note for virtual instruments
- GetNoteForKey method works the same as this method, but instead gets the note for a given key press and instrument
Feature for switching between different play modes for virtual instruments:
The PlayModeManager.cs script implements a persistent play mode selection system that allows users to switch between different interaction modes (Click to play and Hover to play) for the virtual instruments. It maintains the selected mode across different scenes.
Script attached to PlayModeManager (empty) object in Settings and Dashboard scenes.
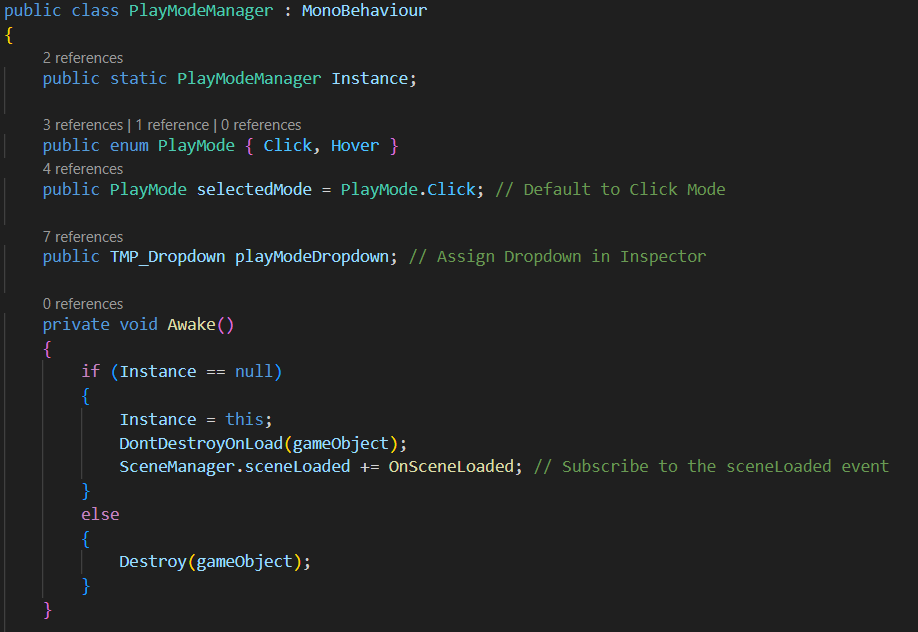
- Defines available play modes (click and hover)
- Default to set to click mode
- Implements singleton pattern and remains in different scenes
- Subscribes to scene load events
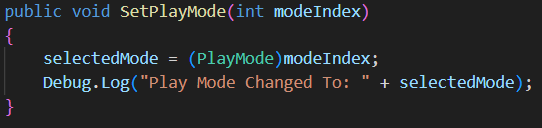
- Handles mode selection changes
- Updates current mode
Multiplayer
Overview
This project implements a basic multiplayer system using Unity Relay and Netcode for GameObjects (NGO). The networking is peer-hosted, where one player acts as the host and others join as clients via a Unity Relay Join Code.
Key Libraries Used
using Unity.Netcode;
using Unity.Services.Relay;
using Unity.Networking.Transport;
Server & Network Architecture
- Host: The player who starts the session acts as the game server.
- Unity Relay: Forwards data between host and clients.
- Clients: Connect through Relay using a Join Code.
- Network Management: The host manages all state synchronization, player interactions, and object spawning.
Port Information
| Component | Detail |
|---|---|
| Relay Port | Dynamically assigned by Unity |
| Client → Relay | Client sends data to Relay |
| Relay → Host | Relay forwards to host |
Networking Flow
1. Host Starts the Game
- Host creates a Relay session using Unity’s Relay SDK.
- A Join Code (e.g.,
FCQRWF) is generated. - Unity assigns a dynamic port for the session.
- Unity Transport connects through Relay.

2. Client Joins the Session
- The client enters the Join Code.
- A connection request is sent to Relay.
- Relay forwards the request to the host, establishing a connection.

3. Gameplay Events & RPC Communication
- When a player interacts (e.g., presses a button), a ServerRpc is sent to the host.
- The host processes the action and sends a ClientRpc to update all players.
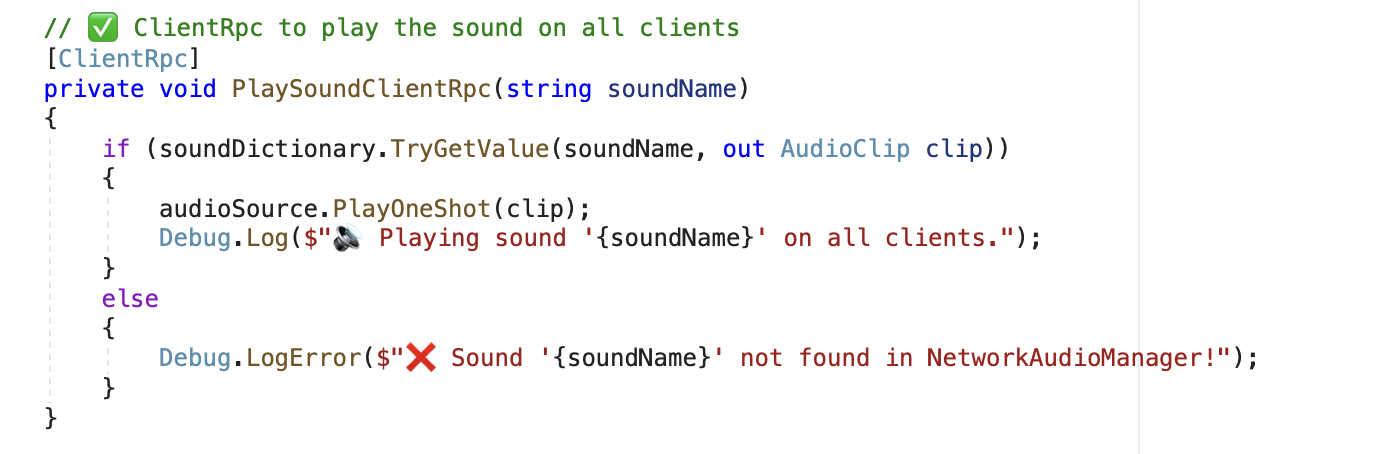
Sound Synchronization
Audio feedback is handled by the NetworkAudioManager. Here’s how sound events are synced across players:
- Client triggers a sound action.
- A ServerRpc is sent to the host:
PlaySoundServerRpc(). - The host sends a ClientRpc to all players:
PlaySoundClientRpc().

Handling Player Disconnects
- When a client disconnects, Unity Relay notifies the host.
- The host removes the player from the active session and updates any necessary game state.