System Design
System Architecture design
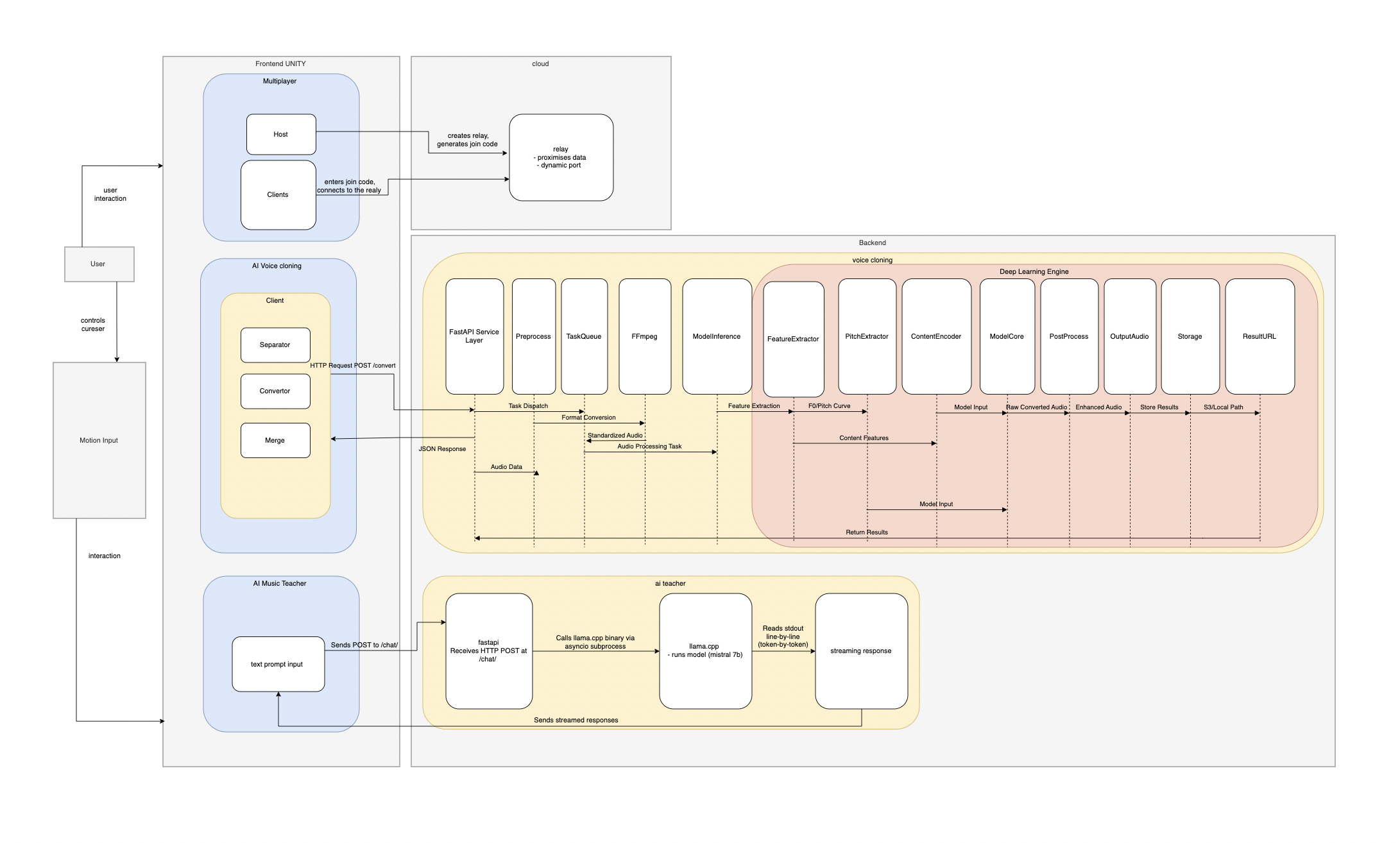
The system architecture presented in the diagram integrates multiple functional modules to enable a real-time AI-driven voice cloning and teaching platform within a Unity-based frontend. It begins with user interaction through motion input or direct control, which communicates with different modules such as AI Voice Cloning, Multiplayer, and AI Music Teacher. The Multiplayer module facilitates peer connectivity via a relay server in the cloud, which generates and manages dynamic data ports. The AI Voice Cloning client processes voice through three stages—Separation, Conversion, and Merging—by sending HTTP POST requests to a FastAPI backend service. The backend pipeline includes task dispatching, audio preprocessing, queue management, format conversion (via FFmpeg), and model inference. Audio then undergoes feature extraction and is processed by deep learning components like ModelCore, PostProcess, and OutputAudio, culminating in result storage and URL generation. Simultaneously, the AI Music Teacher module uses FastAPI to send text prompts to an AI teacher component, which leverages a local LLaMA model for real-time, token-by-token streamed responses. All backend operations are carefully orchestrated to ensure efficient audio processing and response generation, enabling seamless interaction between users, AI models, and system components.
Multiplayer network flow
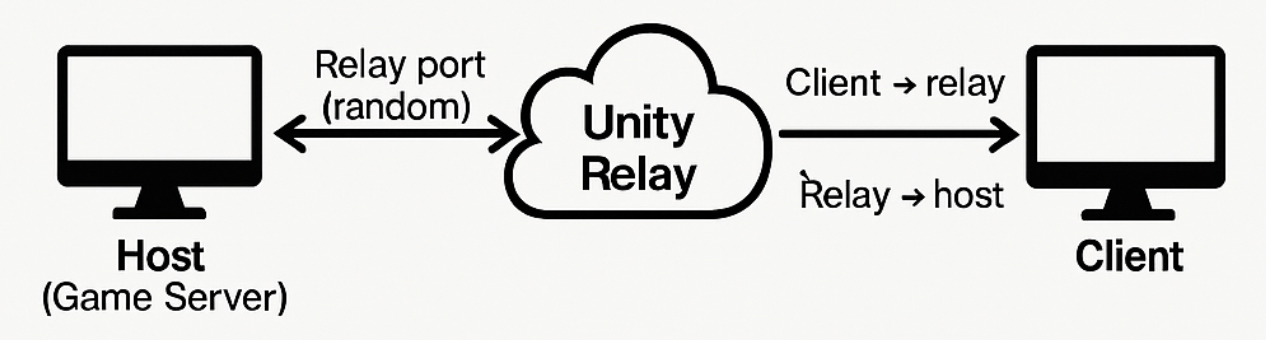 The multiplayer server architecture leverages Unity Relay to manage networked gameplay, using the host player as the authoritative server. When a game session begins, the host initiates a Relay session, during which Unity assigns a random dynamic port and generates a Join Code (e.g., FCQRWF). Clients join the session by entering this code, prompting Unity Transport to connect through the Relay instead of directly to a local port. The Relay acts purely as a proxy, forwarding all traffic between clients and the host.
During gameplay, the host handles all critical logic, including object spawning, interaction handling, and sound synchronization. For example, when a client performs an interaction like pressing a button, it sends a ServerRPC to the host. The host processes this and responds with a ClientRPC to synchronize the action across all clients. In sound events, the host ensures that audio is played at the same time for all users by validating the request and broadcasting a ClientRPC to trigger synchronized playback.
If a player disconnects, Unity Relay informs the host, which then updates the game session and removes the player from the scene. This architecture ensures a streamlined and synchronized multiplayer experience while reducing the burden on clients and maintaining host authority.
The multiplayer server architecture leverages Unity Relay to manage networked gameplay, using the host player as the authoritative server. When a game session begins, the host initiates a Relay session, during which Unity assigns a random dynamic port and generates a Join Code (e.g., FCQRWF). Clients join the session by entering this code, prompting Unity Transport to connect through the Relay instead of directly to a local port. The Relay acts purely as a proxy, forwarding all traffic between clients and the host.
During gameplay, the host handles all critical logic, including object spawning, interaction handling, and sound synchronization. For example, when a client performs an interaction like pressing a button, it sends a ServerRPC to the host. The host processes this and responds with a ClientRPC to synchronize the action across all clients. In sound events, the host ensures that audio is played at the same time for all users by validating the request and broadcasting a ClientRPC to trigger synchronized playback.
If a player disconnects, Unity Relay informs the host, which then updates the game session and removes the player from the scene. This architecture ensures a streamlined and synchronized multiplayer experience while reducing the burden on clients and maintaining host authority.
AI voice conversion frontend and backend flow
Frontend design
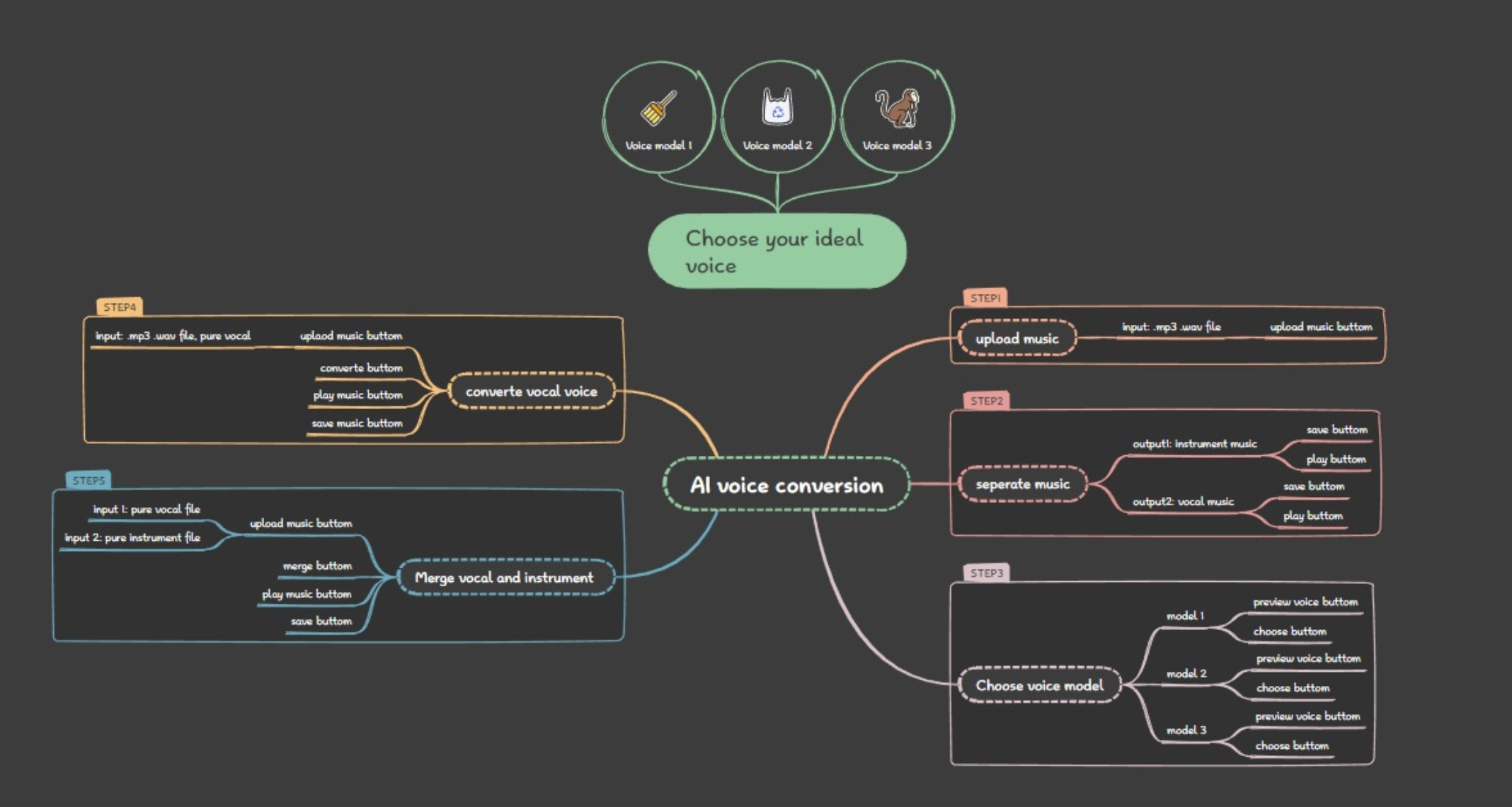
The frontend flow of the AI voice conversion system is structured into a clear, user-guided sequence of five interactive steps. It begins with Step 1, where users upload a music file (MP3 or WAV format) through an “upload music button.” In Step 2, the system separates the uploaded track into two components: instrument music and vocal music. Each output is available with “save” and “play” buttons for user convenience. Step 3 enables users to choose their preferred voice model from three available options. Each model can be previewed using a “preview voice button” and selected via a “choose button.” Once the user has selected a voice, Step 4 allows them to upload a pure vocal file and apply the chosen model to convert the vocal voice. This step provides options to play, save, or process the converted output. Finally, in Step 5, users can upload two files—one vocal and one instrumental—to merge them into a complete music track using the “merge button.” This merged output can then be played or saved. Overall, the flow offers an intuitive interface that guides users step-by-step through uploading, separating, converting, and merging audio content, making the AI voice conversion process seamless and user-friendly.
Backend design

The backend flow begins when the client sends an HTTP POST request to the /convert endpoint of the FastAPI service layer. The FastAPI API receives the audio data and initiates two parallel operations: it forwards the raw audio to the Preprocessing Module and also dispatches a task to the Celery-based Task Queue. The Preprocessing Module performs initial audio cleanup and normalization, then passes the data to the FFmpeg toolchain for format conversion. The standardized audio is then returned to the Task Queue, which manages the asynchronous processing of the audio task. Once the audio is queued, it flows into the Model Inference Layer, where it enters the Deep Learning Engine. Here, the audio undergoes feature extraction, generating pitch information through the RMVPE Pitch Extractor and extracting speech content using the Hubert Content Encoder. These features are then combined and fed into the DDSP-SVC Core Model, which performs the core voice conversion. The model outputs raw converted audio that is further refined by the Audio Enhancer in the PostProcess module. The final enhanced audio is passed to the OutputAudio module, which hands it off to the Storage Service. The Storage Service saves the result either to S3 or a local path and generates a corresponding Result URL. This URL is sent back to the FastAPI layer, which wraps it in a JSON response and returns it to the client, completing the entire voice cloning backend pipeline.
AI llama backend flow
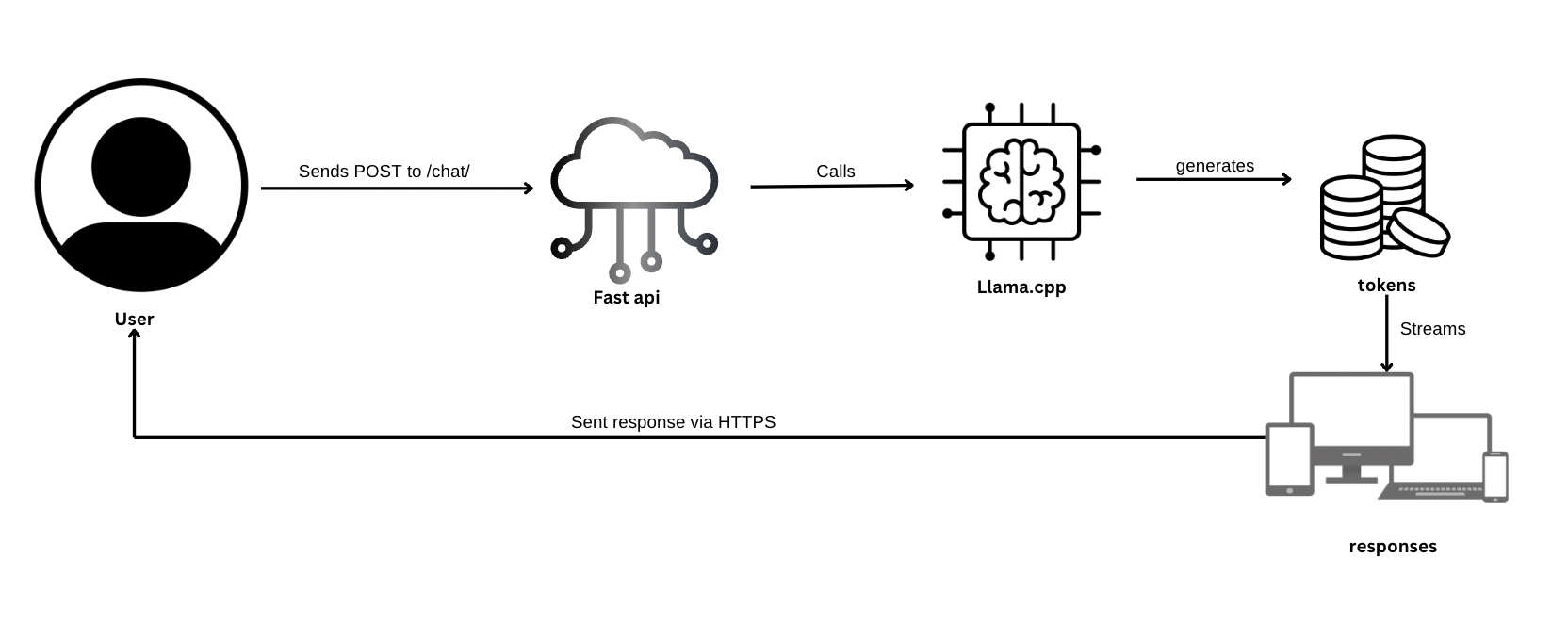 The AI chat backend begins when the user sends a POST request to the /chat/ endpoint exposed via a FastAPI server. This request includes the user prompt intended for the AI assistant. FastAPI, acting as the interface layer, asynchronously calls the llama-cli binary from the llama.cpp project, which runs locally or in a server environment. Under the hood, llama-cli loads the quantized mistral-7b-instruct-v0.2.Q4_K_M.gguf model—a 7-billion parameter instruction-tuned model optimized for inference—and starts generating tokens token-by-token in a streaming manner.
As llama.cpp generates tokens (i.e., pieces of the AI’s response), they are streamed back line-by-line to the FastAPI layer. FastAPI collects these tokens and streams the response back to the client via HTTPS, enabling near real-time AI interaction. This design is lightweight and fast, especially due to the quantized GGUF model, which allows for reduced memory footprint and faster inference without a significant drop in quality.
The AI chat backend begins when the user sends a POST request to the /chat/ endpoint exposed via a FastAPI server. This request includes the user prompt intended for the AI assistant. FastAPI, acting as the interface layer, asynchronously calls the llama-cli binary from the llama.cpp project, which runs locally or in a server environment. Under the hood, llama-cli loads the quantized mistral-7b-instruct-v0.2.Q4_K_M.gguf model—a 7-billion parameter instruction-tuned model optimized for inference—and starts generating tokens token-by-token in a streaming manner.
As llama.cpp generates tokens (i.e., pieces of the AI’s response), they are streamed back line-by-line to the FastAPI layer. FastAPI collects these tokens and streams the response back to the client via HTTPS, enabling near real-time AI interaction. This design is lightweight and fast, especially due to the quantized GGUF model, which allows for reduced memory footprint and faster inference without a significant drop in quality.
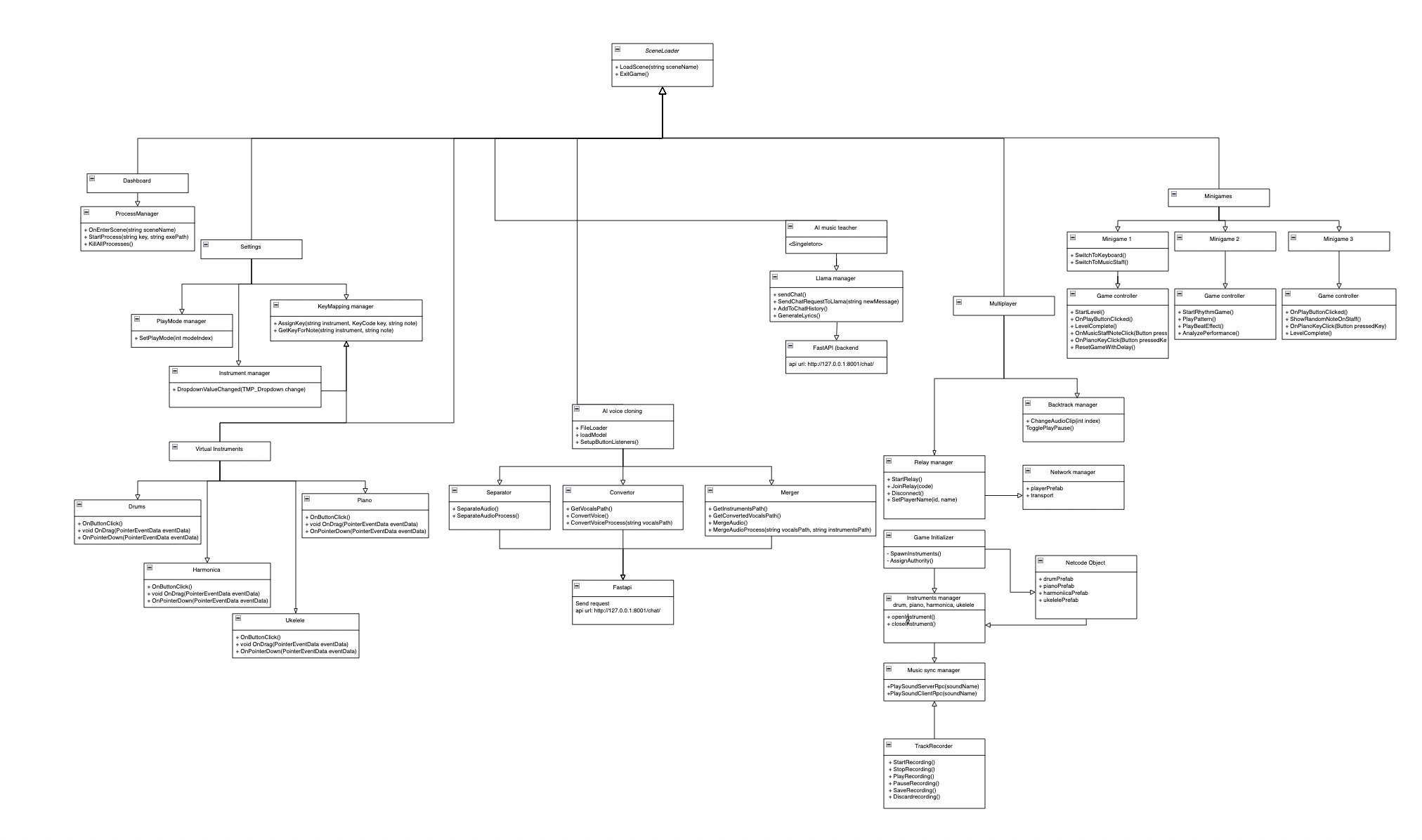
Simplified UML diagram
Packages
Frontend – unity
- Basic unity 2D core packages
- 2D Aseprite Importer
- 2D SpriteShape
- Entities & Entities Graphics
- Input System.
- TextMeshPro
- Timeline
- Shader Graph
- Universal RP (URP)
- Visual Scripting
- Netcode for GameObjects
Backend
Web Framework
- FastAPI or Flask (for RESTful API handling)
- Uvicorn (if using FastAPI, as ASGI server)
Audio Processing & Machine Learning
- NumPy / SciPy – numerical and signal processing
- librosa – audio feature extraction (e.g. pitch, spectrogram)
- PyDub / ffmpeg-python – audio conversion and manipulation
- soundfile or wave – reading/writing .wav files
- Torch / PyTorch – deep learning model execution (DDSP-SVC, pitch extraction models)
- DDSP / DDSP-SVC – model library for differentiable digital signal processing
- openunmix / Demucs – for vocal/instrument separation
- RMVPE – Robust Multi-resolution Voice Pitch Estimation (used for pitch extraction)
File Handling & Storage
- UUID – for generating unique filenames
- os / shutil – file path and management
- Celery + Redis (optional) – for background processing
Llama chatbot
- cmake – for building llama.cpp llama.cpp – LLM backend (compiled binary)
Compilation
- nuitka – Python-to-binary compiler
API
Voice Conversion
- POST /voice/convert – Converts a voice to another speaker using DDSP-SVC
- Params: file, speaker_id, key, enhance, etc.
Speaker Management
- GET /speakers – Returns available speakers
- POST /model/load – Load a different voice model
- GET /model/info – Info about current model
Audio Processing
- POST /audio/separate – Separate vocals/instruments
- POST /audio/merge – Merge separate tracks (by path)
- POST /audio/merge-uploads – Merge uploaded files directly
Full Pipeline
- POST /audio/process-all – Full pipeline: separate → convert → merge
Utilities
- GET /ping – Health check
Llama Chatbot
- POST /chat/ - sends prompt
- GET /chat/ - process prompt
Site map