Evaluation
Summary of Achievements
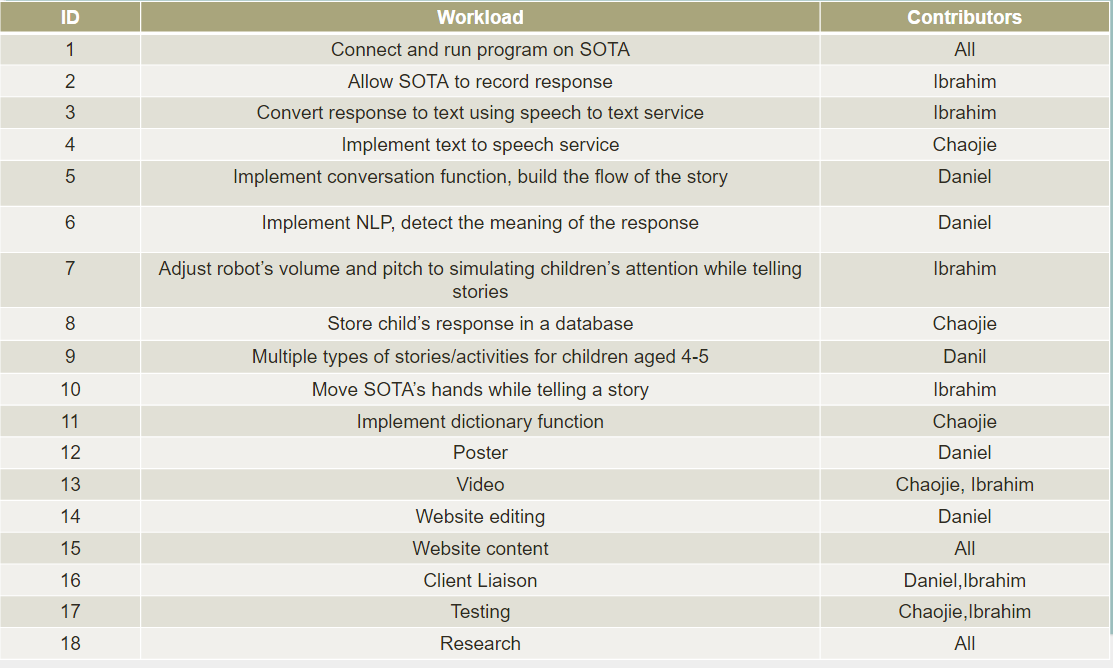
Achievement Table
Known Bugs
There are no known bugs in our project
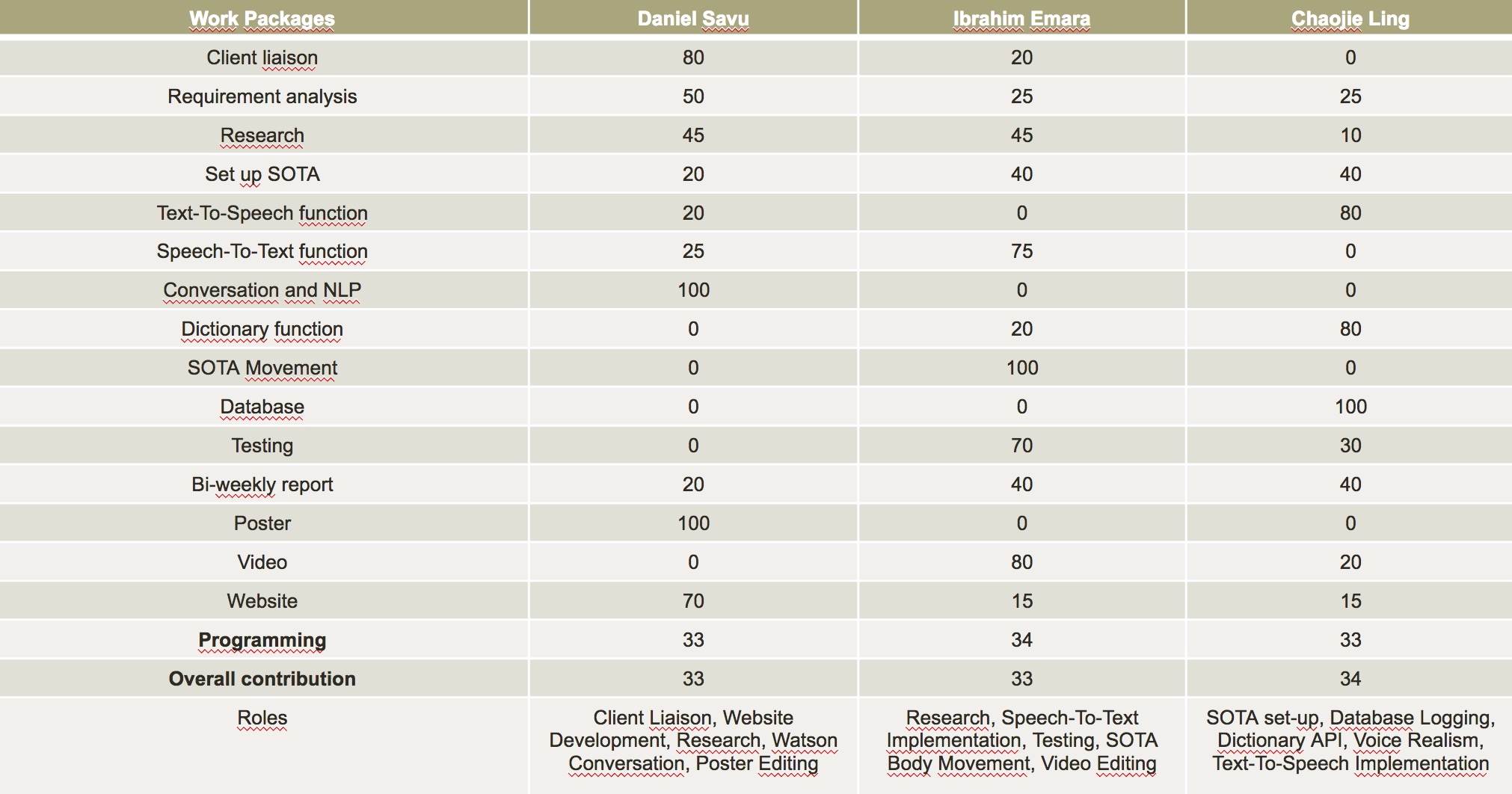
Individual Contribution Table
Critical Evaluation
User Interface / User Experience
When considering how we intended to create a desirable user interface for our system, which is shaped by how the conversation flows between the user and SOTA, we decided that it is important to consider the type of user for our application. Indeed, as our application is aimed at young children, we realised that a good user experience will involve a clear and expressive voice for SOTA, as it will be difficult for our users to understand certain types of artificial voices in their early development. Having compared a variety of different free and paid text to speech services, we identified IBM Watson’s Text To Speech service as the best candidate. This is because, apart from offering a wide variety of different voices, IBM Watson has an Expressive SSML facility, which allows the programmer to specify how different sentences should be expressed, either as ‘Good News’, or as an ‘Apology’ etc. This matches quite well with the purpose of our application, storytelling, and allows children to speak to SOTA in a way which very closely resembles a conversation with a human being.
Moreover, another consideration we made is the interaction the child has when recording their response. In order to clarify when SOTA is recording, SOTA’s eyes change to a green colour to indicate that it is ready to record. When recording is finished, SOTA’s eyes immediately change colour to signal that it is now processing the response.
However, it is important to note that a desirable feature would have been to allow SOTA to record continuously by sending a continuous stream of audio to the API services we are using. However, one of the requirements from our client was to store the responses of the children in a database in order to assess their improvement, which would mean that redundant data would be stored if recording was continuous. When considering the classroom environment where SOTA will typically be placed, we identified that it would be more convenient to enforce a one-to-one interaction with SOTA by allowing the child to click the button on the back of SOTA to record their response.
Functionality
Our project successfully implements and combines a wide range of functionalities which enable a smooth and enjoyable conversation flow. The Speech To Text service is largely accurate and is highly reliable as it is provided by Google Cloud. Indeed, any mistakes that do happen in speech recognition tend to be limited, and they have not affected the interpretation of the overall sentence. This is due to the sophisticated Natural Language Processing (NLP) used by the IBM Watson Conversation tool, which is able to identify intents without restricting the child to only responding in one certain way. Furthermore, our use of Watson Text To Speech has allowed an expressive and easy to understand voice to be heard.
We were also able to delivery a dictionary service to help children improve their language using the Oxford Dictionary API. However, it can occasionally provide definitions which could be difficult for a child to understand, as a children’s API was not available for our use.
Stability
We have tested the SOTA Storyteller under conditions where it could be difficult to operate. These include a weak Wi-Fi connection and noisy conditions which can make it difficult for the Speech To Text service to work effectively. The performance of Speech To Text was not affected by background noise which was filtered out automatically. However, a weak Wi-Fi connection meant that response times were very slow, although SOTA was still able to operate under this condition.
Efficiency
We have taken a number of different measures to both ensure and measure efficiency in our project. Firstly, we identified that the Watson Text To Speech service was causing delays in the overall time taken for SOTA to respond. Therefore, we adjusted our program such that Watson Text To Speech is only called upon when creating a sound file for the first time. As a result of this, SOTA’s response times are now significantly faster when playing stories and defining words which have occured before.
In order to measure efficiency, we were able to use Google Cloud’s dashboard, which displays the median time taken to convert speech to text in our applications. During use with a fast Wi-Fi connection, the time recorded was approximately 2.5 seconds. However, this increased dramatically to up to 15 seconds when connected to slow mobile hotspots. Therefore, a strong Wi-Fi connection forms an integral part of our application.
Compatibility
As our project is only made for use within SOTA, and makes use of SOTA’s specialised libraries, there is no consideration for compatibility with other platforms.
Maintainability
We have designed the classes in our project in order to ensure a high degree of maintainability. Indeed, we have created interfaces for the Speech To Text, Processing Engine, and Text To Speech services. This allows services to be replaced if future users have new requirements or if a service provider decides to take down the service. All that needs to be done is to create classes which provide those services and also implement the methods provided by the interface.
At the same time, the maintainability of hardware must be considered. As SOTA robots are currently shipped directly from Japan, it is difficult for repair and servicing to be sought in Europe. However, the warranty agreement of each SOTA product will specify the availability of international repairs for our users.
Project Management
We were able to manage our project effectively through a number of different considerations. Firstly, we created a GANTT chart, coordinating with our client, outlining our key requirements and specifying the deadlines we expect to complete them by. This helped us ensure that we are always on track with our project, particularly as we updated it every week with new progress. Moreover, we held weekly meeting online with our client, Mr Hiroki Inagaki from NTT Data, in order to communicate our progress and any difficulties we faced in our implementation of the task. These proved to be very useful as our client was able to connect us with different NTT Data teams from different countries that were able to share their expertise with us to deliver our project.
Future Work
If we were given more time to complete our project, for example, an extra three months, the main change we would have made would be to allow SOTA to continuously listen for a response from the child. Initially, we identified that the SOTA CRecordMic library only allows the microphone to be open for a fixed length of time, which prevents us from recording continuously. As a result, the child has to indicate that they are about to begin speaking by pressing the button on the back of SOTA. However, it would be possible for the child to be far away from the robot and speak at the same time if we were able to implement continuous speech recognition. For this to happen, SOTA will need to be attached with a specialised recorder that will overcome the limitations of the SOTA libraries and allow continuous recording of audio.