We have used a large amount of software and frameworks to complete the project. This is shown in the image below.
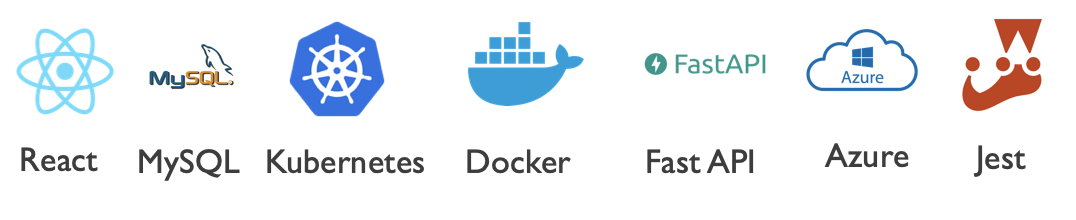
The image below demonstrates our systems architecture diagram. There are two main sections to it. Firstly, there is a kubernetes cluster that hosts our React front end, and FastAPI back end. The cluster is being hosted on Azure Kubernetes Service, which allows the project to be easily scaled up or down. The second part is the MySQL database we have hosted on an Ubuntu VM on Azure. The database has been populated with data that we have gathered from two different sources, a web scraper we have written that obtains data from UCL’s website, as well as a student resource called UCL API.
We have used a large amount of software and frameworks to complete the project. This is shown in the image below.
We created our (containerized) front end pod using React, and used the create-react-app toolchain to start up the project. We chose to use react for a number of different reasons. Firstly, it is a well-established front end backed by Facebook, so we knew there would be a lot of support and good documentation, which we could refer to if we got stuck. Furthermore, it seemed easier to learn than some other options such as Angular, and is quite efficient due to its virtual DOM. Moreover, using the ‘create-react-app’ meant that we could easily test our app using ‘Jest’, without needing to install any other dependencies. However, the biggest reason we chose react was because some of our team already had experience with it, so we thought it would be best to play to our strengths. The site diagram below shows how we laid out our React web page:

Our project structure is quite simple. The user first sees a render of our question page, which presents the user with 5 questions and a drop-down selector for each question from a file called data.js.
Once the user presses submit, they are directed to the results page, where we use an axios request to communicate with our back end. The resultant courses obtained are then mapped into a separate layout component called table results which formats the courses in a visually appealing way. We also have a separate UI component called ‘Single course card’ that displays more of the course data if the user presses a check box.
We decided to use Fast API to construct our back end. None of us had any experience in developing a back end, so when we were researching different frameworks, we were attracted by Fast API’s concurrency and efficiency, making it one of the fastest frameworks available. We were also attracted by the fact that they had automatic documentation creation, which we thought would be quite useful for our project. The front end and the back end communicate with each other via get and post requests to their exposed ports.
As I mentioned in our research and experiment section, we initially had an Azure MySQL database resource to host our database. However, when this was no longer available, we decided to use an Azure Ubuntu VM to store the database instead. This was useful as it allowed the back end to use SSH to query the back end to obtain all of the course data it needed. The database has been populated with data that we have gathered from two different sources, a Python web scraper we have written that obtains data from UCL’s website, as well as a student resource called UCL API. We chose to use Python as the web scraper due to its request library, as well as the beautiful soup library. This was extremely helpful, as it made obtaining and indexing the HTML pages much easier, which helped speed up the development of our prototype. We go into more depth with code snippets in our technical video which can be viewed here
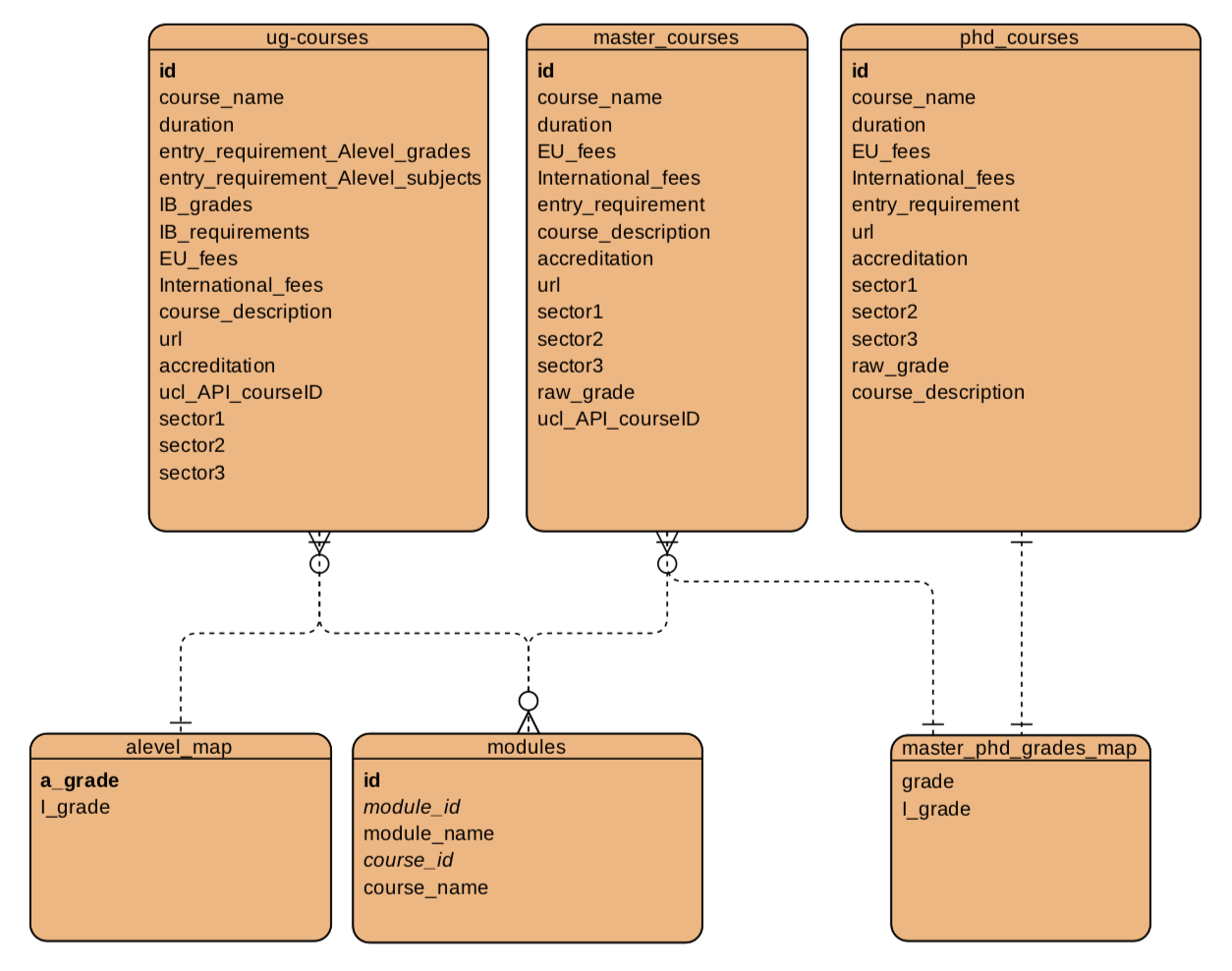
The picture below shows our entity relationship diagram for our MySQL database.
As we created our project, we always tried to maintain best practices and good design patterns both at a low code level, and at a higher system level.
We paid a lot of attention to design principles when coding our React front end. For example, we ensured that we always obeyed the principle of ‘lifting state up’. This states that the developers should always try to keep the main information and data storage (state) in the parent components, and pass down the information as props to child components, bringing the state to higher levels in the project tree and thus creating a sort of ‘root of truth’. Obeying this principle came in handy, as it made the creation of a back button very simple. This is because the previously stored data was not lost when changing back to a previous page, as it was stored in a parent component, ensuring its survival.
Another example in React is that we applied the ‘separation of concerns’ principle, giving each component its own job. For example, rather than embedding our questions and options into the questionnaire component, we created a separate data file called data.js. This was beneficial, as it acted as a nice container for all our data, which made modifying it much simpler than trying to find lots of random strings scattered across a component.
Separation of concerns was also very useful on a broad systems level as well. The fact that we built our web scraper separately from our database meant that we had to use the web scraper to create a CSV file that was then used to populate the database. This is beneficial, as other developers can replace our web scraper with their own, allowing the tool to be used for other purposes as well (e.g. a different university that wants to use the tool on their own courses). On a side note, we also tried to make the web scraper as extensible as possible, which is described in our technical video which is linked above.
Please refer to our technical video which is linked here. We go into a lot of detail analysing the code, and walk you through our MoSCoW requirements.
Our systems architecture has changed multiple times while we were developing our projects. This is because we developed our project with an agile approach, which involved creating multiple prototypes with increasing functionality. This was beneficial, as it allowed us to show our prototypes to our client and fellow classmates (acting as pseudo users), which would influence the design of the next prototype, ensuring that we were designing software that actually matched what our client desired.
For our first prototype, we just made the front end of the website using React. The front end would operate on dummy data and would simply filter courses that we hard coded based on what the user inputted. At this point, we were not considering making a back end, as we were under the impression that we would obtain a CSV file from UCL ISD that contained all of the course information. Therefore, we were simply going to extract the required data and place it into our front end.
However, when we got to the next iteration, we realised that we needed a back end. This is because it became clear that we probably would not be getting the CSV file, which meant that we would need to gather our own data. We also reasoned that collecting our own data may be more beneficial for our project, as we could later automate the data collection process. This means that our tool could reflect real life changing data, rather than becoming obsolete after a few years due to being dependent on an outdated CSV file. As a result, we built our second prototype with a back end, and the diagram below represents its system architecture:
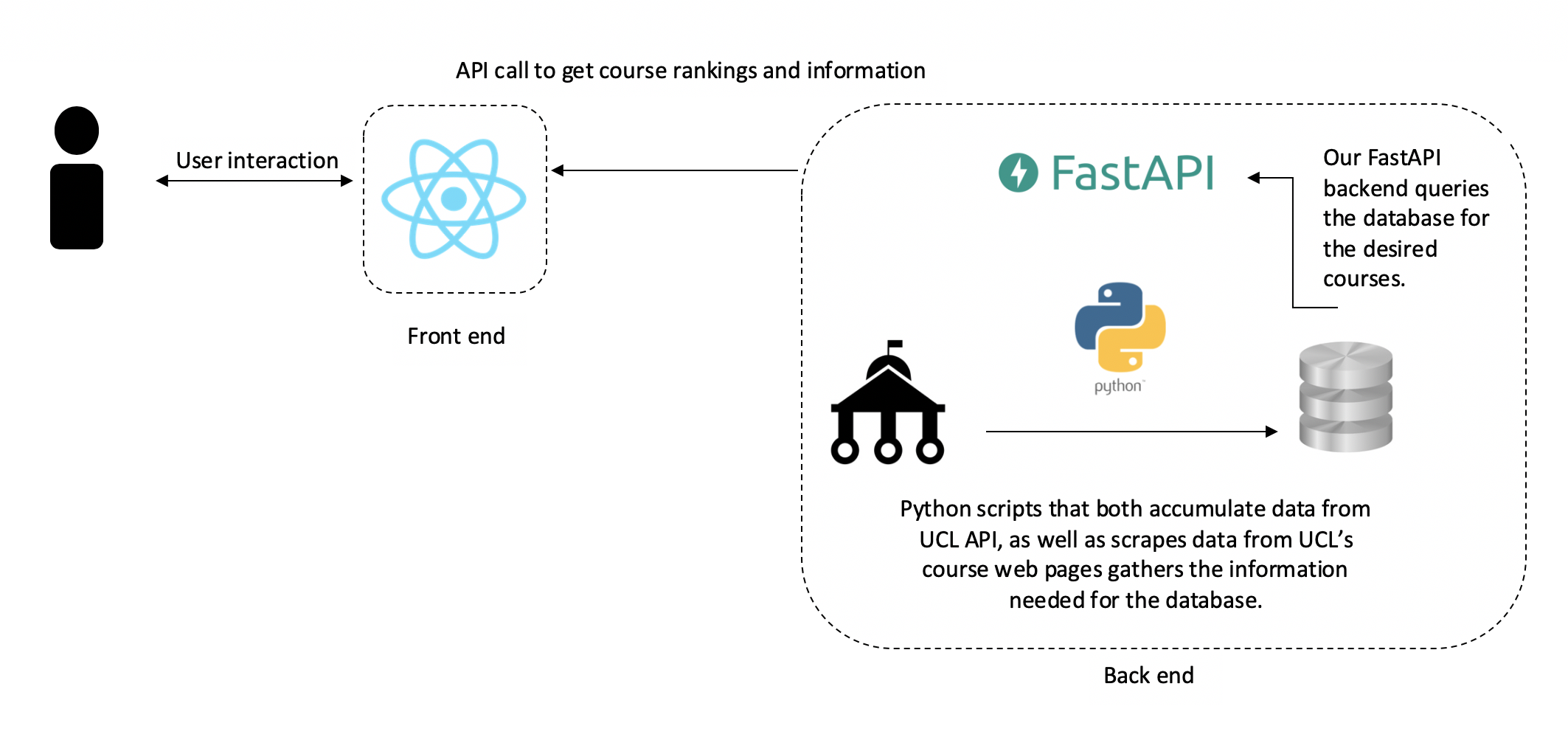
As you can see, this diagram is very close in structure with our final prototype’s diagram. The difference is that this is lacking our deployment. We then chose to use Azure’s kubernetes service to host the front and back end. This is because we wanted to produce a stable deployment that could easily be scaled up or down. We increased the stability of the project by adding a second back end in the YAML file to ensure that if the back end went down, we would have a back up ready to help users.