This project is built using Python and ElasticSearch 7.11.2. To complement this paper, we created a python package1 which allows to implement these algorithms and test them. In this paper, we build and compare the following algo-rithms: BM25, Language Model, and LambdaMart. We also implemented stemming to the search algorithms.
The classic search algorithms we decided to implement are Okapi BM25* [12] and a Language model** with Dirichlet Smoothing [15]. These two algorithms are natively built-in in ElasticSearch.
We used the following parameters for the algorithms:
- K1 = 0.9, b=0.4 for BM25
- μ = 1000 for Dirichlet Smoothing
These parameters are the same as in the paper “100,000 Podcasts: A Spoken English Document Corpus” [6] in order to make results as comparable as possible.
We then trained two LambdaMart models with the default RankLib parameters: one with, and one without stemming in the BM25_Score feature. The model trained with stemming will be used as a comparison and with stemming on top, as using stemming on a model trained without it could decrease performance. We then incorporated both models into Elasticsearch. More details on this are included in the PDF report.
*Okapi BM25 : BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document, regardless of their proximity within the document. It is a family of scoring functions with slightly different components and parameters.[12]
**Language model : Bayesian smoothing using Dirichlet priors. From Chengxiang Zhai and John Lafferty. 2001. A study of smoothing methods for language models applied to Ad Hoc information retrieval. [18]
For this projects, we used 2 datasets:
- The X5GON Dataset: A TSV file containing Data for all of the learning material in the X5GON Database
- The Spotify Podcast Dataset: A sample of 105,360 podcasts episodes from the platform Spotify, coupled with relevant metadata. These episodes are transcribed using Google’s cloud Text to Speech API [1]. The dataset includes 2 judgement lists*: one called training, which included 8 queries, and one for testing. We decided to save the training judgement list for creating the LTR models.
We compiled the dataset into one CSV file with all relevant information. Due to performance and time constraints, we decided to only use a random subset of the dataset which includes the documents included in the training and testing judgement lists. The size of this subset is around 166,000, out of the total ~3M documents. A document, in our case, is a two-minute extract of a transcript with one minute overlap taken from the original JSON transcript files.
Judgement list: A judgement list is a list of (document, query) pairs coupled with a ground-truth relevence value (usually between 0 and 4). It is often created manually, or using user data.
In order to test the efficiency of these algorithms, we used the judgement list given in the dataset. We chose to use nDCG@10 and nDCG@5 as metrics for accuracy, which is given by:
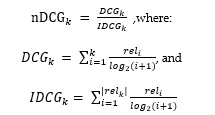
Where k= 5 or 10, reli is the relevance score of document I on the judgement list, and relk represents the list of relevant documents (ordered by their relevance) in the corpus up to position k.
To perform the testing, we used Elasticsearch’s ranking evaluation module [16], which allows getting the nDCG@k scores for a set of queries given a list of (query, document, score) triples. We used that method to get nDCG@10 and nDCG@5 scores for all of the mentioned algorithms with and without stemming, for all of the queries in the judgement list.
Using the methodology described above, we ran the tests and compiled the results for all queries in the testing judgement list.
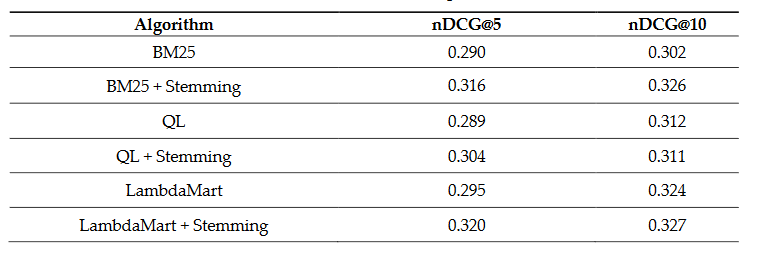
As we can see, algorithms with stemming consistently perform better than their counterparts. It also seems like the best performing retrieval algorithm is LambdaMart with stemming. However, using Wilcoxon rank-signed tests [14], we found that the algorithms are not distinguishable, as none of the results is statistically significant. This lack of difference could be due to the limitations of the bag-of-words strategy [6]. We cannot reject the hypothesis that they all follow the same distribution.
Some queries suffer a lot from the noise created by automatic speech transcription. For example, the query Fauci interview consistently gets an nDCG score of 0 for all of the algorithms.
Using a larger sample of the dataset could make the results more precise.
Unfortunately, our test results are not significant and cannot help us to draw any definite conclusion. Thus, after read-ing more literature on search for information retrieval [5], we decided to implement LM with Dirichlet Smoothing to the X5Learn web application. We also considered the fact that using LambdaMart on a different dataset would significantly decrease its performance.
To improve the performance, future work could include improving the LambdaMart models. Indeed, some terms are often wrongly transcribed (usu-ally names and complicated words), and adding the BM25 score with fuzziness to the list of features could help tackle that. Furthermore, using a larger dataset like the TREC datasets [5] would help gather significant knowledge about which retrieval technique is more accurate. If we were to decide to implement LambdaMart to the web application, we could make use of user data collection to build a judgement list for that dataset.
if you want more information on how we created and tested the algorithms, you can check this report
Link to the report[1] “Google Cloud Speech-to-T.” [Online]. Available: https://cloud.google.com/speech-to-text.
[2] “x5learn.org.” [Online]. Available: https://x5learn.org/.
[3] “stemming @ www.elastic.co.” [Online]. Available: https://www.elastic.co/guide/en/elasticsearch/reference/current/stemming.html.
[4] Apache, “Lucene.” [Online]. Available: http://lucene.apache.org/.
[5] G. Bennett, F. Scholer, and A. Uitdenbogerd, A Comparative Study of Probabalistic and Language Models for Infor-mation Retrieval. 2008.
[6] A. Clifton, M. Eskevich, G. J. F. Jones, B. Carterette, and R. Jones, “100 , 000 Podcasts : A Spoken English Document Corpus,” pp. 5903–5917, 2020.
[7] A. Clifton et al., “The Spotify Podcast Dataset,” 2020, [Online]. Available: http://arxiv.org/abs/2004.04270.
[8] D. Davies, “How Search Engine Algorithms Work: Everything You Need to Know,” Search Engine J., 2020, [Online]. Available: https://www.searchenginejournal.com/search-engines/algorithms/#whysearc.
[9] X. Han and S. Lei, “Feature Selection and Model Comparison on Microsoft Learning-to-Rank Data Sets,” vol. 231, no. Fall, 2018, [Online]. Available: http://arxiv.org/abs/1803.05127.
[10] lintool, “PySerini @ pypi.org.” https://pypi.org/project/pyserini/.
[11] J. B. Lovins, “Development of a stemming algorithm,” Mech. Transl. Comput. Linguist., vol. 11, pp. 22–31, 1968.
[12] S. E. Robertson and K. Sparck Jones, “Relevance Weighting of Search Terms,” in Document Retrieval Systems, GBR: Taylor Graham Publishing, 1988, pp. 143–160.
[13] D. Turnbull, E. Berhardson, D. Causse, and D. Worley, “Elasticsearch Learning to Rank Documentation,” 2019. [Online]. Available: https://media.readthedocs.org/pdf/elasticsearch-learning-to-rank/latest/elasticsearch-learning-to-rank.pdf.
[14] W. J. Conover, “Practical Nonparametric Statistics, 3rd Edition.”
[15] C. Zhai and J. Lafferty, “A Study of Smoothing Methods for Language Models Applied to Ad Hoc Information Retrieval,” SIGIR Forum, vol. 51, no. 2, pp. 268–276, 2017, doi: 10.1145/3130348.3130377.
[16] “Google Cloud Speech-to-T.” [Online]. Available: https://cloud.google.com/speech-to-text.
[17] Stephen Walther, ASP.NET MVC Framework Unleashed, Sams Publishing - 2009, (ISBN 9780768689785)
[18] C. Zhai and J. Lafferty, “A Study of Smoothing Methods for Language Models Applied to Ad Hoc Information Retrieval,” 2001, pp. 334–342.