Research
Summary of Technical Decisions
This page contains all the research we have done in terms of related projects, programming languages, libraries, algorithms and models. A summary of the technical decisions we have made are as follows:
1. We will be developing a custom tool for this as there is no existing application that would meet all the requirements.
2. We will be developing a stand-alone tool that can be run independently and will not be an extension of an already existing tool/framework.
3. We will use Python as our primary programming language.
4. We will use TKinter to build our GUI.
5. We will use a pre-trained extractive Question Answer model to extract certain pieces of text from the uploaded document/documents.
6. We will use the fuzzywuzzy library to perform fuzzy string matching (this is done to meet certain requirements, a further description is available down below).
7. We will use spaCy to extract Admin 1 and Admin 2 location names from a given document.
8. We will use Named Entity Recognition to extract location names.
9. We will use PostgreSQL to create and manage the database.
Main Programming Language
What is Named Entity Recognition?
Our client expressed interest in having a tool that could be run locally on any Windows device as a stand-alone application (as the IFRC is a Windows based company).
As our client did not have a preference for programming language, it became clear to us that the choice of programming language would depend on our comfortability and which language would come with the most tools that would help us perform Natural Language Processing (NLP) related tasks. Our 2 main choices were Java and Python.
While Java is robust and object-oriented which would allow for more efficient coding, it is not as flexible as Python and does not come with as many NLP related libraries. Python, on the other hand, has an easy-to-understand syntax and is highly versatile. Additionally, it comes with a lot of packages that allow for a very high degree of code re-usability and a relatively less complicated implementation of NLP related tasks like Named Entity Recognition (NER), text summarization etc., which are all concepts we would need to implement t for this project.
As such, it became evident to us that the main programming language our project would incorporate would be Python due to our prior experience with it, its vast and diverse collection of NLP libraries such as PyTorch, spaCy, as well as Pandas. In addition, Python is a platform-indepependant language which aligned with our client’s needs. Python has also surpassed Java in terms of popularity, and a whopping 51% users used it for Data Analysis and 36% users used it for Machine Learning [1]. All 4 of us had prior experience in Python, this combined with the vast amount of easily accessible documentation and online resources meant that we could not only effectively support one another but also reduce the steepness of the learning curve for ourselves.
Named Entity Recognition (NER)
The highest priority requirement of this project, as expressed by our client, was the extraction of Admin 1 and Admin 2 location names of affected locations from the PDF text as well as matching their names to their respective ISO codes (which are stored in an Excel spreadsheet). In order to do this, we decided to use Named Entity Recognition, which is a field of NLP that aims at identification, extraction and classification of information in unstructured text into named entities such as people, organization, location etc. Upon further reading we found that the 3 types of NER are dictionary based, rule based and machine learning based NER.
1. Dictionary-based has a dictionary containing vocabulary which is used. Basic string-matching algorithms check whether the entity is present in the given text against the items in the vocabulary. We decided not to employ this method because the dictionary that is used is required to be updated and maintained consistently.
2. Rule-based has a predefined set of rules for information extraction is used which are pattern-based and context-based. Pattern-based rule uses the morphological pattern of the words while context-based uses the context of the word given in the text document. While rule-based systems can perform relatively alright when it comes to texts like newspaper articles, they are often very poor at capturing nuance or diversity of text and they can also be very complex to construct due to the manual effort and amount of training data required.
3. Machine learning based solves a lot of limitations of the above two methods. It is a statistical-based model that tries to make a feature-based representation of the observed data. It can recognise an existing entity name even with small spelling variations. The machine learning-based approach involves two phases for doing NER. The first phase trains the ML model on annotated documents. In the next phase, the trained model is used to annotate the raw documents. The process is similar to a normal ML model pipeline.
Choice of Python Library for NER
These are the top Python libraries that were considered for our project:
1. Natural language Toolkit is a set of libraries used for NLP. It is widely used in research and for educational purposes. Written in Python, it has access to more than 50 text corpora across 7 languages. One of the primary principles of NLTK, besides simplicity, consistency, and extensibility, is modularity. Modularity provides components that can be used independently. This might be especially useful for tuning only specific parts of the pipeline or even using third parties in conjunction with this toolkit. NLTK does NER in two steps. The first step is POS (parts-of-speech) tagging or grammatical tagging, which is followed by chunking to extract the named entities. The library is quite powerful and versatile but can be a little difficult to leverage for natural language processing. It is a little slow and does not match the requirements of the fast-paced production processes. The learning curve is also steep.
2. SpaCy is a powerful Natural Language processing tool used to process large amounts of data. With support for over 64 languages and 63 trained pipelines for 19 languages, it is a handy tool in NLP. SpaCy offers the fastest parsing in the market. Since it is written in Cython, it is efficient and is among the fastest libraries. Although SpaCy supports a small number of languages, the growing popularity of machine learning, artificial intelligence, and natural language processing enables it to act as a key library.
3. Flair is a simple framework developed for NLP. Flair is built on top of PyTorch which is a powerful deep learning framework. Claimed to support over 250 languages, it is very useful in training small models. It is pre-trained on an extremely large unlabelled text corpora. Whereas SpaCy adds a feature engineering step to encode the context of neighboring words into its NER model at the word embedding layer, Flair uses a deep learning model to do such feature engineering implicitly.
4. Polyglot’s NER doesn’t use human-annotated training datasets like other NER models. Rather, it uses huge unlabeled datasets (like Wikipedia) with automatically inferred entity labels (via features such as hyperlinks). By cleverly addressing the supervised learning labeling limitation, Polyglot has been able to leverage a massive multilingual corpus to train even a simple classifier (e.g. a feedforward neural network) to become a very robust, competitive NER model.
Out of these 4 options, we have decided to go with SpaCy for the following reasons:
1. SpaCy has clear and organised documentation with detailed explanations, valuable tips and tricks, helpful code modules and illustrations, and video tutorials to get started. As none of us had previous experience with NLP, documentation was an important factor to consider.
2. NLTK supports various languages whereas SpaCy supports 17 languages for statistical modelling and 64+ languages for "Alpha tokenisation". Although NLTK supports more languages, it does not extend support to all modules and algorithms. Since our client has already confirmed that all documents to be parsed are in English, SpaCy is the better option for this project.
3. SpaCy v3 has an incredible error handling and validation support giving SpaCy an upper hand. It has type hints support from Python 3 and static or compile-time type checker like Mypy for validating and giving friendly error messages for the same.
4. Although NLTK performs better when it comes to sentence tokenisation, SpaCy performs better in word tokenisation and POS-tagging. This makes SpaCy the better option as our client has prioritised extraction of location names and related geographical data over other details.
Evaluating SpaCy Models
Testing Location Detection
SpaCy has 3 main NLP models: small, medium, and large, which you can choose from to perform a task. The team decided that the large model would be best for our task of extracting all Geopolitical Entities (GPE) from the document.
We carried out a test on all three models, using the same extract of text, taken from the first two paragraph of the Wikipedia page on the United States. The extracted GPEs were then put into a list as shown below:
Small model - ['The United States of America', 'U.S.A.', 'USA', 'the United States', 'U.S.', 'US', 'America', 'The United States', 'the Federated States', 'the Marshall Islands', 'the Republic of Palau', 'Canada', 'Mexico', 'Bahamas', 'Cuba', 'Russia', 'Washington', 'D.C.', 'New York City']
Medium model - ['The United States of America', 'USA', 'the United States', 'U.S.', 'US', 'America', 'The United States', 'the Marshall Islands', 'the Republic of Palau', 'Canada', 'Mexico', 'Bahamas', 'Cuba', 'Russia', 'Washington', 'D.C.', 'New York City']
Large model - ['The United States of America', 'U.S.A.', 'USA', 'the United States', 'U.S.', 'US', 'America', 'The United States', 'the Federated States of Micronesia', 'the Marshall Islands', 'the Republic of Palau', 'Canada', 'Mexico', 'Bahamas', 'Cuba', 'Russia', 'Washington', 'D.C.', 'New York City']
Comments on Results
Although all three models do a great job of identifying the locations in the text, the large model in one instance was able to recognise “the Federal states of Micronesia” as a GPE, as opposed to the small model that recognised only part of the GPE “the Federal States”, and the medium model not identifying it at all.
This may not seem like much of an important factor, it would be very important to our clients. Their main requirement was for us to extract precise locations from the DREF documents, for them to correctly identify disasters and issue funds accordingly. As seen in the table above, the large model is significantly larger than the small and medium. However, for reasons stated previously, we prioritised accuracy over any other factor.
Model Statistics
Other metrics we considered when choosing our model, include storage size, F-score, and word vector size. A comparison of the three models using these metrics is shown below[2]:
1. Small Model: Size - 12 MB, Word Vector Size: 0 keys, 0 unique vectors (0 dimensions), F-Score - 0.85.
2. Medium Model: Size - 40 MB, Word Vector Size: 514k keys, 20k unique vectors (300 dimensions), F-Score - 0.85.
3. Medium Model: Size - 560 MB, Word Vector Size: 514k keys, 514k unique vectors (300 dimensions), F-Score - 0.85.
Although all three models have the same F-score, the large model has a much larger vector size compared to the small and large model, making it more accurate.
Question Answering(QA) Models
QA Systems primarily deal with the NLP related task of answering questions posed by humans in natural language by combining the fields of NLP and information retrieval. The 3 variants of QA based on input and output are as follows:
1. Extractive QA: In this type of QA, a passage is provided along with the question to serve as a context and the model is expected to predict where in the passage the answer is located.
2. Generative QA: In this case, the model generates free text based on the context provided. However, this is only in Open cases. In Closed cases, no context is provided and the answer is generated without a context.
Since our tool required us to extract specific pieces of information from uploaded document/documents, it was evident we had to make use of an Extractive QA Model.
Evaluating QA Models
Metrics Used to Evaluate QA Models
There are two dominant metrics used by many question answering datasets, including SQuAD: exact match (EM) and F1 score. These scores are computed on individual question+answer pairs. When multiple correct answers are possible for a given question, the maximum score over all possible correct answers is computed. Overall EM and F1 scores are computed for a model by averaging over the individual example scores.
EM: For each question+answer pair, if the characters of the model's prediction exactly match the characters of (one of) the True Answer(s), EM = 1, otherwise EM = 0. This is a strict all-or-nothing metric; being off by a single character results in a score of 0. When assessing against a negative example, if the model predicts any text at all, it automatically receives a 0 for that example.
F1: F1 score is a common metric for classification problems, and widely used in QA. It is appropriate when we care equally about precision and recall. In this case, it's computed over the individual words in the prediction against those in the True Answer. The number of shared words between the prediction and the truth is the basis of the F1 score: precision is the ratio of the number of shared words to the total number of words in the prediction, and recall is the ratio of the number of shared words to the total number of words in the ground truth.
Dataset Used
The Stanford Question Answering Dataset (SQuAD) is a set of question and answer pairs that present a strong challenge for NLP models. Due to its size (100,000+ questions), its difficulty due to the model only has access to a single passage and the fact that its answers are more complex and thus require more-intensive reasoning, SQuAD is an excellent dataset to train NLP models on. SQuAD 1.1, the previous version of the SQuAD dataset, contains 100,000+ question-answer pairs on 500+ articles. SQuAD2.0 combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.We have decided to choose a model that has been pre-trained on SQuAD2.0 for improved performance.
Our Evaluation
We shortlisted 5 well performing pre-trained QA models from Hugging Face and analysed them using their f1 and EM values on the SQuAD2.0 dataset, which are as follows:
| Model Name | F1 | EM |
|---|---|---|
| distilbert-base-cased-distilled-squad | 86.996 | 79.600 |
| deepset/roberta-base-squad2 | 82.950 | 79.931 |
| deepset/minilm-uncased-squad2 | 79.548 | 76.192 |
| bert-large-uncased-whole-word-masking-finetuned-squad | 83.876 | 80.885 |
| deepset/bert-base-cased-squad2 | 74.671 | 71.152 |
We also ran all models on a sample document provided by our client, asked the models questions related to our requirements, tabulated the results and asked 15 of our peers to rate the sensibility of the answers from 1-5 for each of the answers. The names of the abovementioned models were replaced by A,B,C,D,E and they were run on the same document, the extracted answers were provided in the questionnaire. The number of people who voted for each of the ratings is as follows:
| Rating | Model A | Model B | Model C | Model D | Model E |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 4 | 0 | 2 | 2 | 3 |
| 3 | 3 | 1 | 4 | 3 | 6 |
| 4 | 4 | 3 | 7 | 8 | 6 |
| 5 | 2 | 11 | 2 | 2 | 0 |
The Roberta model performed the best and therefore was chosen.
String Matching
What is Named Entity Recognition?
Fuzzy Matching (also called Approximate String Matching) is a technique that helps identify two elements of text, strings, or entries that are approximately similar but are not exactly the same.
For our project, the client’s primary requirement was to extract Admin 0, 1 and 2 locations and match them to their appropriate ISO codes. However, there were a number of factors to consider with these requirements.
1. The SpaCy NER pipeline only recognizes entities as geopolitical entities and would not help us classify the extracted location names into 1 of 3 categories.
2. We did not have a collection of the location names with their corresponding ISO codes. This was something that would have to be prepared by ourselves.
3. There are certain locations, especially within Admin 2, whose classification is not clear both in terms of whether they belong to Admin 2 or 3, and which country they belong to.
4. Location names have varied spellings/names especially within Admin 2 as they tend to be localized. Therefore, a mechanism that makes use of exact word matching would not work. This was the main reason, along with the fact that we wanted to take typos into account, that we decided to make use of fuzzy matching.
The first step was to prepare collections of the Admin 0, 1 and 2 codes. This was done largely by making use of online collections and expanding upon them. Our client was also able to provide us some data for the same, and we were able to combine the 2 to prepare 3 Excel spreadsheets for the same.
Next, there was an issue regarding time taken for execution. Our Admin 1 spreadsheet has 2001 entries and our Admin 2 spreadsheet has 39,246 entries. Manually iterating through them would be highly inefficient and so, we decided to filter the entries. The Admin 1 and Admin 2 spreadsheets contain a column of the ISO Country Code. Thus, we decided to use our already implemented QA model to extract the country of disaster, find the corresponding ISO Country Code by fuzzy matching against the Admin 0 Spreadsheet (which is far less time intense as it has only 287 entries) and then use the obtained ISO Country Code to perform filtering on the Admin 1 and Admin 2 spreadsheets.
After this, there was the issue of choosing which method of fuzzy matching to perform. We did research, looked at the existing code that our client had provided us, spoke to our client and decided to choose between the following 3 methods:
1. Cosine Similarity, which measures the similarity between 2 vectors using the cosine of the angle between them.
2. Edit Distance, which quantifies the similarity between 2 strings by calculating how many operations (insertions, removals or deletions) it takes to convert one string into another.
3. Python’s Fuzzywuzzy module, which uses either difflib or the Python-Levenshtein module to calculate dissimilarity between 2 strings using the concept of ‘fuzz ratio’. However, making use of Python-Levenshtein was recommended for production purposes by the developers and so, that was what was considered.
Evaluating String Matching Methods
To decide which method of string matching was best, we decided to compare the Fuzzywuzzy module, Edit distance and Cosine Matching by using 40 random Admin 1 and Admin 2 locations extracted from 15 random documents. We decided to test 2 different cases:
1. We filter the dataframe obtained from reading the Admin 1 Code and Admin 2 Code spreadsheets using the Country Code.
2. We filter the dataframe obtained from reading the Admin 1 Code and Admin 2 Code spreadsheets using the Country Code as well as matching the first letter of the Admin 1/Admin 2 locations with the first letter of the location whose code we are trying to obtain (this was done to see whether time of execution could be reduced further).
We decided to compare the 3 types of string matching on the basis of time taken to execute the program, the number of ‘Not Found’ values returned as well as the accuracy which was calculated by (number of correct answers / total number of answers) * 100. The results obtained are as follows:
| Type of String Matching | Time | No. of 'Not Found' Values | Accuracy |
|---|---|---|---|
| Fuzzy Matching without first letter filter | 11.3 minutes | 0 | 95% |
| Fuzzy Matching with first letter filter | 17 minutes | 1 | 90% |
| Cosine Matching without first letter filter | 49.6 minutes | 0 | 85% |
| Cosine Matching with first letter filter | 16.29 minutes | 1 | 85% |
| Edit Distance without first letter filter | 10.3 minutes | 0 | 90% |
| Edit Distance with first letter filter | 10.42 minutes | 1 | 87.5% |
It was observed that adding the first letter filter did not reduce time of execution significantly except in the case of Cosine Matching. However, the additional filter reduced accuracy in all cases except with Cosine Matching as well as increased the number of ‘Not Found’ values returned from 0 to 1 in all cases. This is because locations have been entered with different names in the spreadsheets and these entries were filtered out and therefore not considered when string matching was performed(For e.g.: Johannesburg has been entered as City of Johannesburg).
Text Summarizers
One feature of the tool we decided to work on was summarizing the Operational Strategy section of reports. However, this proved to be difficult as documents did not have a fixed format. While some of them had only tables in the Operational Strategy, others had several pages or text, or a mix of both. As it would be inefficient to stores paragraphs worth of text in our database, we decided to make use of a text summarizer model.
Evaluation Metrics Used
ROUGE-1 compares the degree of similarity of unigrams in the automatically generated and hand-written summaries. Unigrams, in this case, are words. Thus, the precision and recall can be calculated by evaluating how many individual words are captured from the source material to the final automatically generated summary.
ROUGE-2 compares the degree of similarity of bigrams in the automatically generated and hand-written summaries. Bigrams, in this case, are two consecutive words. Thus, the precision and recall can be calculated by evaluating how many bigrams are captured from the source material to the final automatically generated summary.
ROUGE-L measures the longest common subsequence (LCS). This refers to the words that happen to be in sequence, not taking into account any different words that are in the way of the matching sequence (when comparing the candidate and reference sentences).
The following text summarizer models were evaluated:
1. Luhn's Heuristic Method
2. TextRank
3. Latent Semantic Analysis (LSA)
4. Kullback-Leibler Sum (KL-Sum)
5. T5 Transformer Model
In order to be able to choose between these models, we calculated the ROUGE values which are as follows:
| Evaluation Metric | LSA | TextRank | T5 | KL-Sum | Luhn's |
|---|---|---|---|---|---|
| ROUGE-1 Precision | 0.6527 | 0.4637 | 0.4615 | 0.4776 | 0.1829 |
| ROUGE-1 Recall | 0.6438 | 0.4383 | 0.4109 | 0.4383 | 0.2054 |
| ROUGE-1 F-Score | 0.6482 | 0.4507 | 0.4347 | 0.4571 | 0.1935 |
| ROUGE-2 Precision | 0.4772 | 0.2967 | 0.3086 | 0.2873 | 0.0086 |
| ROUGE-2 Recall | 0.4719 | 0.3033 | 0.2808 | 0.2808 | 0.0112 |
| ROUGE-2 F-Score | 0.4745 | 0.2999 | 0.2941 | 0.2840 | 0.0097 |
| ROUGE-L Precision | 0.6388 | 0.4492 | 0.4615 | 0.4626 | 0.1585 |
| ROUGE-L Recall | 0.6301 | 0.4246 | 0.4109 | 0.4246 | 0.1780 |
| ROUGE-L F-Score | 0.6344 | 0.4366 | 0.4347 | 0.4428 | 0.1677 |
Transformer model produced the best summary, as it most closely resembles a human-made summary. Luhn's Heuristic Method, however, scored significantly worse, owing to the fact that it is one of the earliest Text Summarization models to come into the picture.
Upon demonstrating the code to our clients and explaining the mechanism of the text summarizer model, they were a bit concerned with the loss of information that comes with a summarizer and hence, requested that we also explore PDF slicing using images so that the appropriate sections of the PDF could be extracted and stored.
Thus, we made use of the module PyMuPDF, which allows for PDF slicing in the form of images. We have successfully implemented this code and it is able to extract the Operational Strategy portion of reports. However, our client has decided to not include this feature in the tool as they would like to focus on the other enrichments and extractions since they have a higher priority.
Tkinter
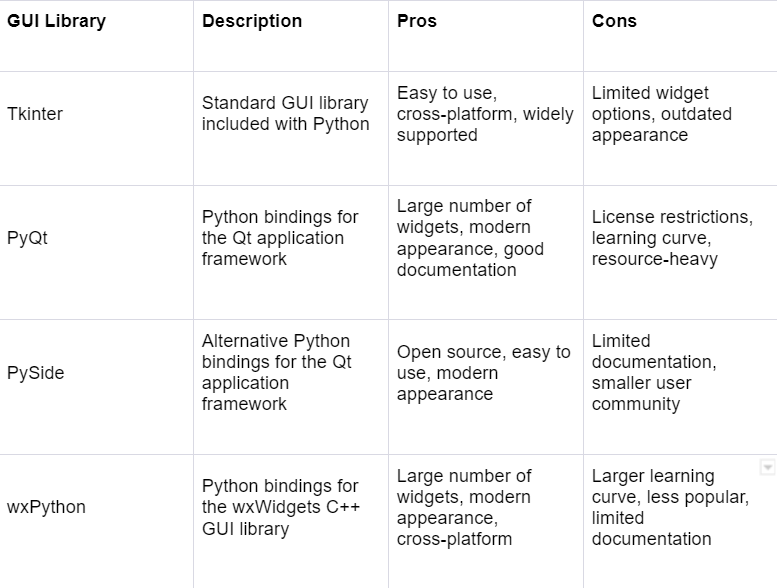
I chose Tkinter as the GUI library to compare with other Python GUIs because it is the standard GUI library included with Python and has been widely used and supported for many years. It is also relatively easy to use and cross-platform compatible.
PyQt and PySide are also popular GUI libraries that use the Qt application framework. They offer a modern appearance and a large number of widgets, but they have a learning curve and can be resource-heavy. Additionally, PyQt has license restrictions that may be a concern for some users.
wxPython is another option that provides a large number of widgets and a modern appearance, but it has a steeper learning curve and less popularity than other libraries.
Ultimately, the choice of GUI library depends on the specific needs and preferences of the developer. Tkinter may be the best choice for those who value simplicity and cross-platform compatibility, while other libraries may be more suitable for those who require more advanced features or a more modern appearance.
PostgreSQL
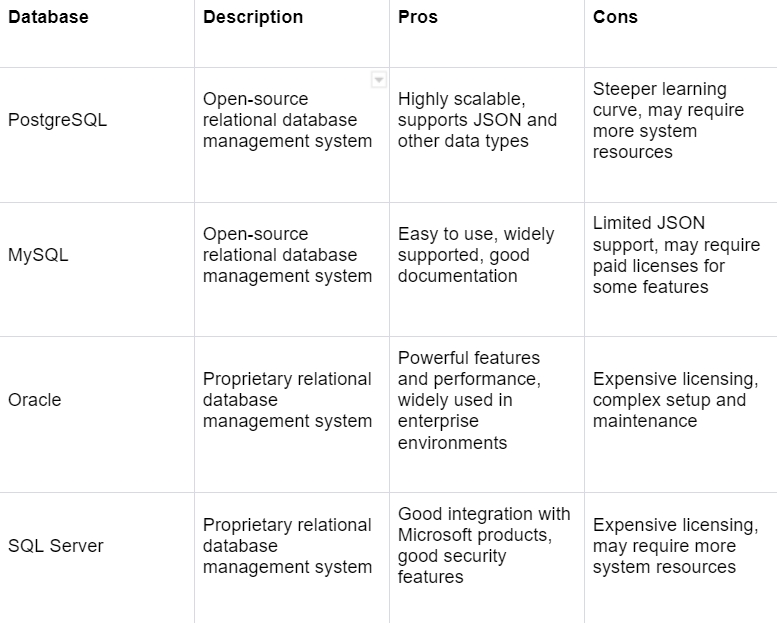
I chose PostgreSQL as the SQL database to compare with other databases because it is a popular open-source relational database management system with a strong reputation for scalability and support for JSON and other data types.
MySQL is another popular open-source database that is easy to use and widely supported, but it has limited JSON support and may require paid licenses for certain features.
Oracle and SQL Server are proprietary databases that offer powerful features and performance, but they require expensive licensing and may be more complex to set up and maintain.
Overall, the choice of database depends on the specific needs and requirements of the project. PostgreSQL may be the best choice for those who require scalability and support for JSON and other data types, while other databases may be more suitable for those who prioritize ease of use, integration with specific technologies, or other features.
Resources
[1] “Python Developers Survey 2021 Results,” JetBrains: Developer Tools for Professionals and Teams. https://lp.jetbrains.com/python-developers-survey-2021/#DevelopmentTools (accessed Mar. 23, 2023).
[2] “English · spaCy Models Documentation,” English. https://spacy.io/models/en
[3] Reading Comprehension [Online]:https://www.k12reader.com/what-is-reading-comprehension/
[4] Hugging Face Documentation [Online]:https://huggingface.co/docs/hub/index
[5] Hugging Face wants to become your artificial BFF [Online]:https://social.techcrunch.com/2017/03/09/hugging-face-wants-to-become-your-artificial-bff/
[6] PyPDF2 Documentation [Online]:https://pypi.org/project/PyPDF2/
[7] Applications of String Matching [Online]:https://www.geeksforgeeks.org/applications-of-string-matching-algorithms/
[8] What is fuzzy matching? [Online]:https://www.techopedia.com/definition/24183/fuzzy-matching#:~:text=Fuzzy%20matching%20is%20a%20method,fuzzy%20matching%20can%20be%20applied.
[9] Fuzzy matching with cosine similarity [Online]:https://engineering.continuity.net/cosine-similarity/#:~:text=Cosine%20matching%20is%20a%20way,grid%20%2D%20i.e.%2C%20as%20a%20vector
[10] Natural Language Processing with SpaCy in Python [Online]:https://realpython.com/natural-language-processing-spacy-python/#:~:text=spaCy%20is%20a%20free%2C%20open,general%2Dpurpose%20natural%20language%20processing.
[11] Camelot Python Documentation [Online]: https://pypi.org/project/camelot-py/
[12] Tkinter - Wikipedia [Online]: https://en.wikipedia.org/wiki/Tkinter#:~:text=Tkinter%20is%20a%20Python%20binding,License
[13] An Introduction to Tkinter [Online]: https://www.cs.mcgill.ca/~hv/classes/MS/TkinterPres/
[14] PostgreSQL: a closer look at the object-relational database management system [Online]: https://www.ionos.co.uk/digitalguide/server/know-how/postgresql/