Similar Projects
As we had been researching, one of the projects we have taken inspiration from was podcast.ai. A tool where episodes of length 5-20 minutes are generated by Artificial Intelligence.
- Main Features:
- AI-generated short podcast episodes
- Simple and user-friendly interface
- Topic suggestions by users
- Learnings:
- Effective UI design for user engagement
- AI-powered content generation
- Integration of celebrity interviews for enhanced audience appeal
- Add episode descriptions
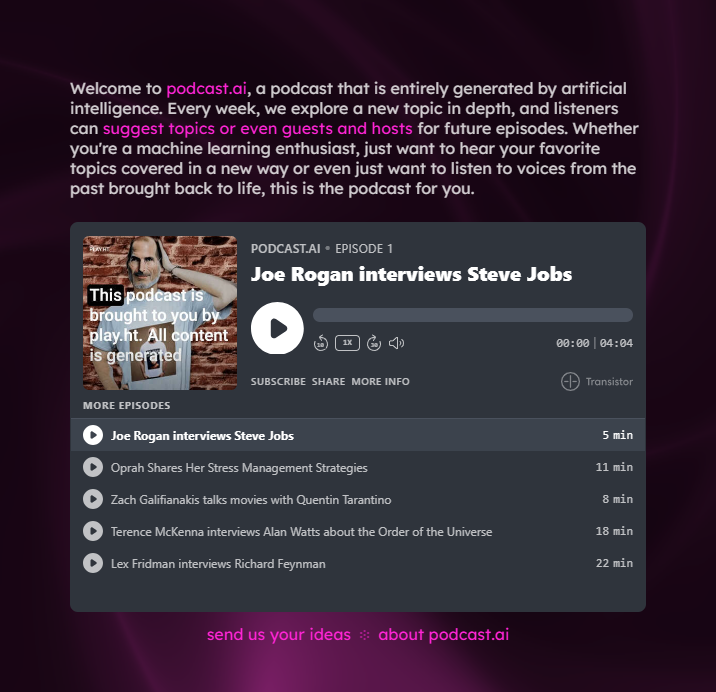
We were impressed by podcast.ai's innovative approach to generating short podcast episodes using Artificial Intelligence, particularly its UI design and adept integration of AI. Inspired by these successes, we aim to implement more automation in our project, leveraging AI tools and their APIs (Application programming interfaces used to communicate with other programmes) to convert AI generated scripts into audio episodes and provide a more automated topic suggestion scheme, where users can enter a topic with description or keywords and get a podcast episode in return. This automation will enhance efficiency and user experience, setting our project apart with a unique and advanced technological approach.
AI
Another project that we have taken inspiration from was a YouTube channel called The Joe Rogan AI Experience. The channel focuses on producing simulated interviews with famous figures, where the voices of these figures are also clones.
- Main Features:
- AI-generated scripts
- Realistic Conversations
- High quality cloned voices
- Generated pictures of the host and the guest
- Captions
- Learnings:
- Invest time in cloning voices
- Consider ethical part of cloning voices
- Add episode descriptions
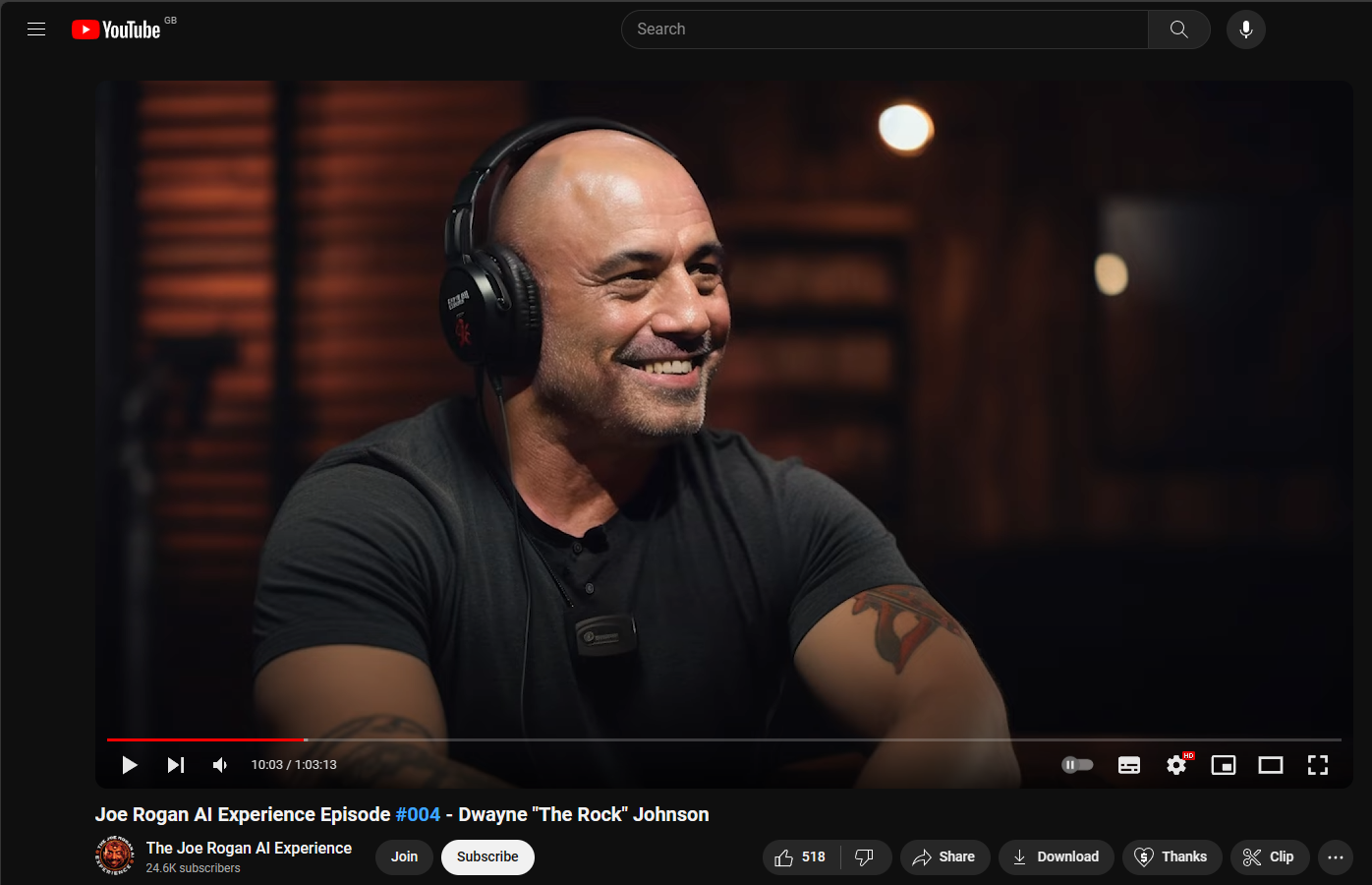
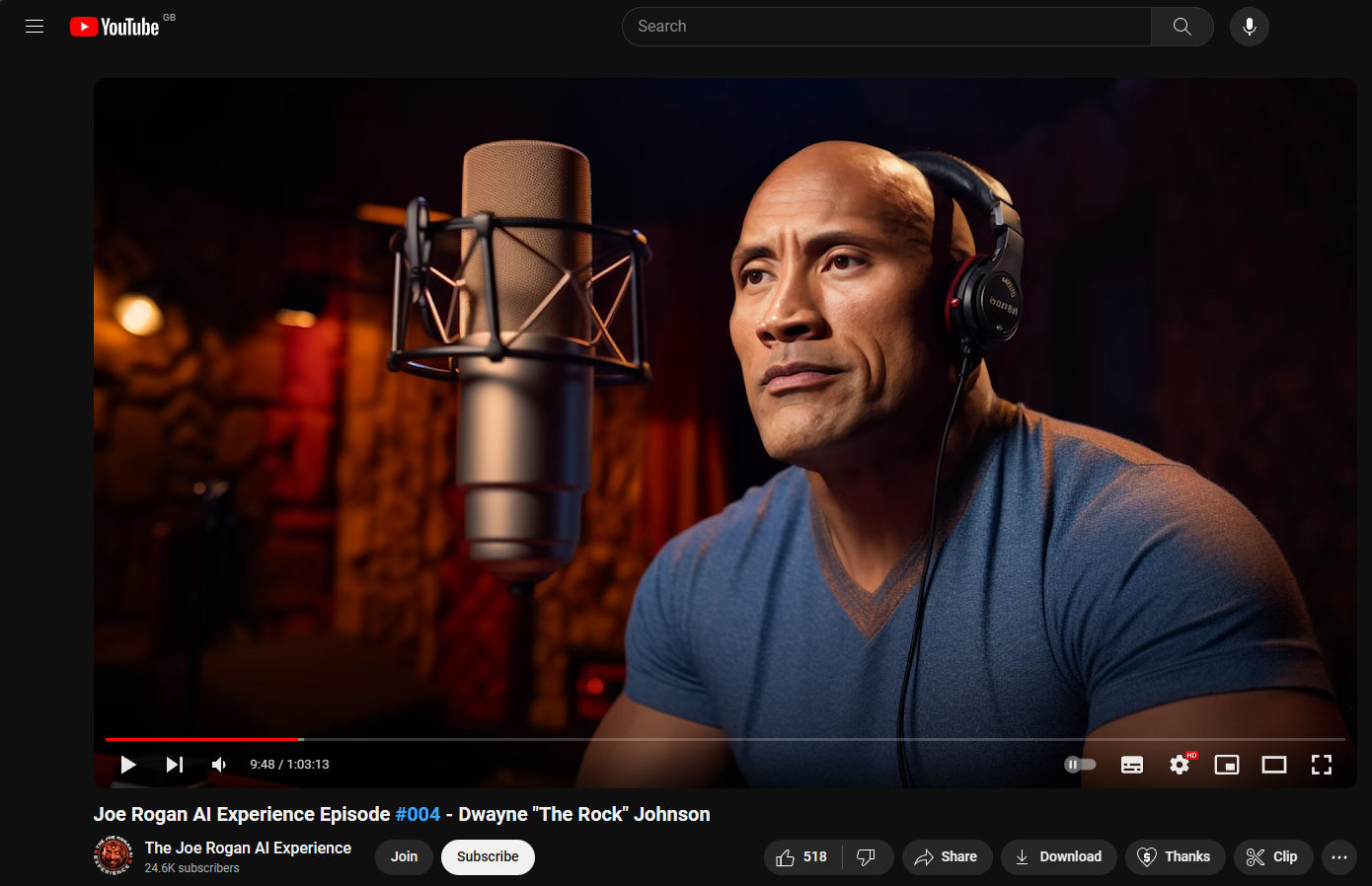

Having reviewed The Joe Rogan AI Experience podcast, we were pleasantly surprised by several key features such as cloned voices and the concept of having ai-generated pictures. We've opted to integrate both concepts, featuring images based on keywords or neutral themes for broader topics. Our primary emphasis would be put on perfecting voice cloning, as it is something that can distinguish our podcast. However, we would need to consider the ethical aspect of it and have a clear disclaimer, explaining the conversations and the voices are artificial, not real.
Technology Research
We had a lot of decisions to make when it came to the technologies that our podcast would use, hence we had done an in-depth research about as many technologies as we could.
-
Programming Language
We opted for Python as our programming language because it is one of the most common languages, thus it would be easier to get help with and all three team members were already comfortable and familiar with it prior to the project. Also, it has a lot of extensive third-party libraries and using APIs in our project was another key element, which python would help us with.
-
Script Generation
For script Generation, we have decide to tackle this in two different methods, Local and server LLM. For server LLM, we have opted to go with OpenAI due to past experience as a team have with the API. The user will need to put their OpenAI api into the website if they want to use the feature Moving on to local LLM, we have used LangChain and GPT4All to load our model. We have download and test multiple model from huggingface namely gpt4all-falcon and mistral-openorca which works decently with what we are trying to do
Retrieval Augmented Generation (RAG)
For RAG system, we decide to use model from huggingface community namely, "sentence-transformers/all-MiniLM-l6-v2" to transform our information which is usually in pdf or txt into vector based data. Then we can retrieve this information using LangChain and similarity search.
-
Audio Generation
We evaluated several technologies when it came to audio generation, each with its own strengths and weaknesses. Our goal was to select the ones tailored specifically to our project's objectives within audio generation, them being voice cloning, easy integration with python and accurate text to speech conversion.
Text To Speech
Initially, we needed to determine our Text-to-Speech tool. Some platforms provided pre-existing voices with various specifications (e.g., Male, American or Female, Australian), while others allowed voice cloning [1]. After considering the options, we opted for IBM Watson for its pre-made voices due to its high accuracy, quality voices, reliable algorithms (e.g., processing human speech), and future-ready features such as integration with Watson Assistant and multilingualism[2]. Regarding voice-cloning, ElevenLabs emerged as our choice for its instant voice cloning capabilities and cost-effectiveness compared to alternatives[3]. Although PlayHT was considered, given its usage by PodcastAI, a thorough comparison with ElevenLabs revealed its diminished functionality and quality, coupled with a higher cost.
Audio Processing
We then needed to figure out the audio processing part, including merging files together, adding music, cutting, etc. A crucial requirement for us was the tool's capability to import and export mp3 files, rather than solely playing the sound within Python. Considering that many Python libraries offer similar audio processing functionalities, we decided to choose pydub as it seemed to cover our needs, while also being easy to use[4]. We also used moviepy to concatenate audio clips together.
Sentiment Analysis
Also, we needed a tool or a library to analyse the mood of our script to then select the appropriate music. Similarly to audio processing, the sentiment analysis libraries offered similar features[5], at least for the functions we required (accurately analysing the text sentiment). Therefore, we selected textblob as it was a library we were already familiar with and hence knew how to use effectively.
Music
In the final phase, we required a selection of at least 3 different themed soundtracks with positive, negative or a neutral mood. The decision was made to use YouTube Audio library as the platform is copyright free, fairly rich, and it is easy to find the soundtracks needed by using the 'mood' filter tab.
-
Video Generation
Even though video generation was not a priority for us as we wanted to focus on the script and the audio of our podcust, we reviewed 2 different approaches when it came to video generating - generation of a dynamic video and generation of a static video.
First Potential Solution
Initially, we wanted to utilise a text-to-video tool such as synthesia[6] to generate video clips for our episodes. The idea would be: generate video based on what the host or the guest is saying and combine it with the audio from text-to-speech model. However, after researching deeper, we realised that the text-to-video tools, including synthesia and others are really expensive while providing us with something that we do not necessarily need as people usually listen to podcasts while doing something else (chores, drive, work out)[7] and hence will not focus on the video element of the podcast. Therefore, we made a decision to do something simpler and more cost-effective.
Second Potential Solution
As a result, we implemented the static video method. The approach included two different ways of choosing the image for the static video within itself.
The first method was to generate a number of neutral themed pictures, and once the audio part is ready, select a random neutral-themed picture from the folder with these images. Then, simply play this image throughout the episode, using it as a cover for the episode. The technology we wanted to use was MidJourney (text-to-image tool) as it generated very high quality pictures, following the prompt closely[8]. The only negative it had was the absence of the api for it, therefore we would have to do more manual work and the podcast would not be as automated.
The other method of selecting an image included using a different text-to-image tool, which had an api. After the final consideration of the three best tools tailored for our needs (DeepAI, Replicate and StabilityAI), we decided to choose StabilityAI for its ease of use, well-written documentation and decent quality of images, coupled with free accessibility[9]. The video generation process included analysing the text script to identify 5-10 keywords, which would then be used to generate an image displayed throughout the episode.
Video Processing
We did not require any advanced video processing technologies, hence decided to keep moviepy for videos too, as well as numpy for working with images that we would use for static videos.
Technical Decisions
This is a summary of the technologies that we have used throughout the process of building our project.
| Technology | Decision |
|---|---|
| Programming Language | Python |
| Method of Loading Local Model | Langchain & GPT4All |
| Local Model | mistral-7b-openorca.gguf2.Q4_0.gguf |
| Online LLM | OpenAI Chatgpt-3.5-turbo |
| RAG | transformers (sentence-transformers/all-MiniLM-l6-v2) |
| Text-to-Speech | IBM Watson & ElevenLabs |
| Audio Processing | pydub & moviepy |
| Sentiment Analysis | textblob |
| Music | YouTube Audio Library |
| Text-to-Image | MidJourney & StabilityAI |
| Video Processing | moviepy |
| Image Processing | numpy |
| Frontend (Website) | ReactJS |
| Backend (Website) | NodeJS & Express |
| Database (Website) | MongoDB (using Azure CosmosDB) |
| Storage (Website) | Azure blob storage |
References
- [1] Broadhurst, M. (2024). Best AI Text-to-Speech Tools: Top 5 Picks for Superior Audio Quality. Broadhurst Digital - Sales and Marketing Technology Consultancy. Available at: https://broadhurst.digital/blog/best-ai-text-to-speech-tools (Accessed: 20 March 2024).
- [2] Speechify (2023). The Ultimate Guide to IBM Watson Text to Speech. Available at: https://speechify.com/blog/the-ultimate-guide-to-ibm-watson-text-to-speech/ (Accessed: 20 March 2024).
- [3] Staniszewski, M. (2023). Best Text to Voice Software. ElevenLabs Blog. Available at: https://elevenlabs.io/blog/best-text-to-voice-software/ (Accessed: 20 March 2024).
- [4] Nordseele et al. (2023). Python Music, Audio Processing and Sound Manipulation. Lines. Available at: https://llllllll.co/t/python-music-audio-processing-and-sound-manipulation/64378 (Accessed: 20 March 2024).
- [5] BairesDev (2023). 8 Best Python Sentiment Analysis Libraries. Available at: https://www.bairesdev.com/blog/best-python-sentiment-analysis-libraries/ (Accessed: 20 March 2024).
- [6] Rebelo, M. (2023). The Best AI Video Generators. Zapier. Available at: https://zapier.com/blog/best-ai-video-generator/ (Accessed: 20 March 2024).
- [7] Gray, C. (2024). Podcast Statistics & Industry Trends 2024: Listens, Gear, & More. The Podcast Host. Available at: https://www.thepodcasthost.com/listening/podcast-industry-stats/ (Accessed: 20 March 2024).
- [8] Gwira, C. (2024). 12 Best AI Text-to-Image Tools in 2024 (Compared). Elegant Themes Blog. Available at: https://www.elegantthemes.com/blog/design/best-ai-text-to-image-tools#3-midjourney (Accessed: 20 March 2024).
- [9] Eden AI (No date). Top Free Image Generation Tools, APIs, and Open Source Models. Available at: https://www.edenai.co/post/top-free-image-generation-tools-apis-and-open-source-models (Accessed: 20 March 2024).

