System Architecture
Our project has 3 main components: frontend, backend and the function app. Each of these uses different technologies and models:
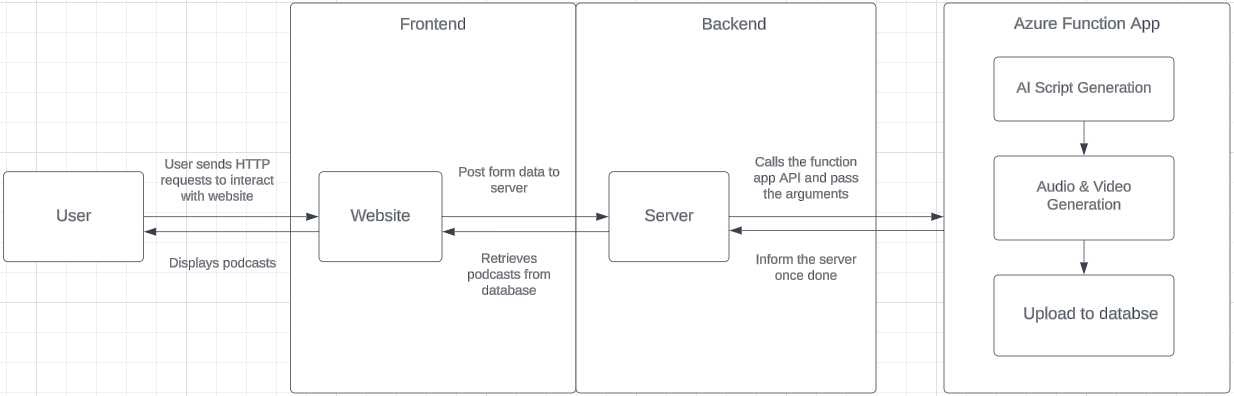
Frontend: The website is developed using ReactJS, along with Material-UI React component library to fasten the development process. Users can play the generated episodes as well as sending arguments to generate a new episode via the frontend.
Backend: The server is developed using NodeJS and ExpressJS. When a request is sent to generate an episode, the server calls the function app API and pass in the necessary arguments to run the generation process. The server itself along with the build files from frontend is deployed using Azure web app service.
Function App: The function app is developed using Python and includes all the automated python scripts for generating the podcast. It gets triggered when a HTTP request is received. The python scripts then generate the podcast and upload it to the database so that the users can play it from the frontend. The function app is deployed using Azure function app.
Function App Architecture
Our function app has 3 main components: script generation, audio & video generation, and file management. Each of these uses different technologies and models:
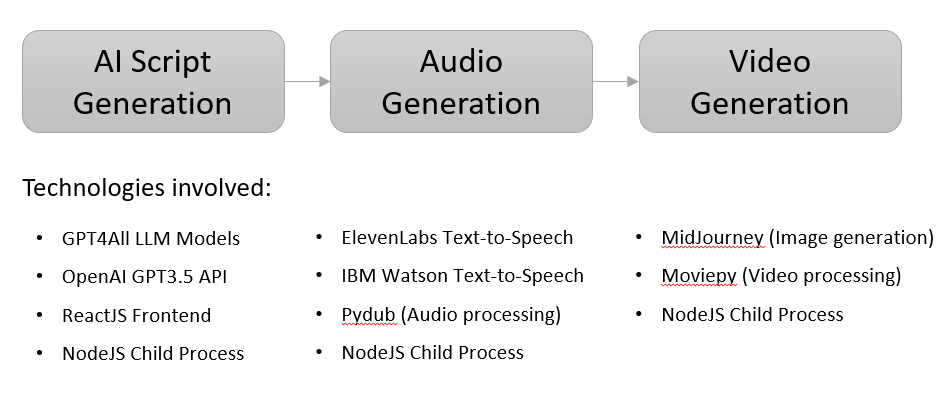
1. Script Generation: Firstly, the website prompt user to input podcast name, podcast description, podcast topics. Then the user need to select whether the podcast is single or duo and to use local or server LLM, based on this response the script will use different classes. When the user finished selecting the options, OpenAI or Local LLM will brainstorm the podcast with relavent information with RAG and output the script.
2.1. Audio Generation: Uses IBM Watson and ElevenLabs Text-To-Speech tools to generate audio files based on the script. It receives a variable with the script and turns it into audio mp3 file using either a pre-made voice (IBM Watson) or a cloned voice (ElevenLabs), as well as different audio processing python libraries to add music and concatenate individuaal speech files.
2.2. Video Generation: Uses MidJourney and StabilityAI Text-To-Image tools in order to generate images that are used as covers for the video part. It receives an mp3 file and turns it into an mp4 file by inserting the image and adding the audio file to it, using moviepy Python library for audio and video processing.
3. File Management: Uses Blob Storage API and MongoDB API from Cosmos DB to upload the generated episode. It firstly uploads the video file to the blob storage, then creates a document containing episode title, description and the video link to upload to the Cosmos DB. It also cleans up all the generated file after the episode is fully uploaded to save server space.
Data Storage
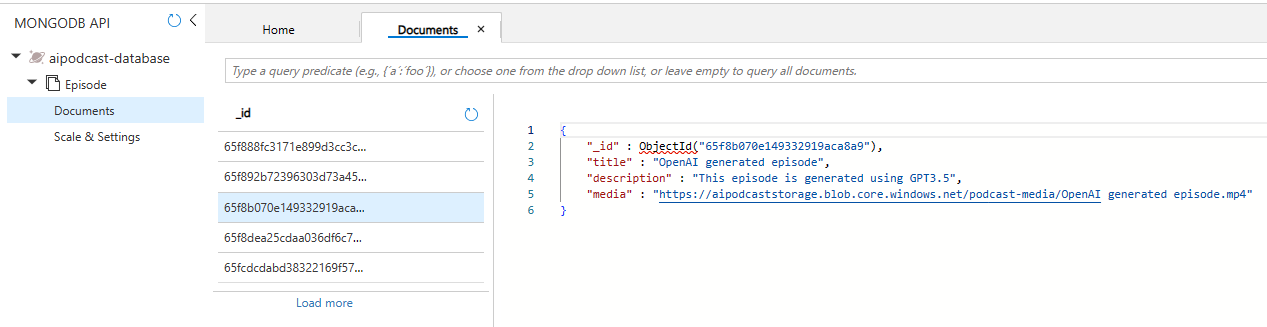
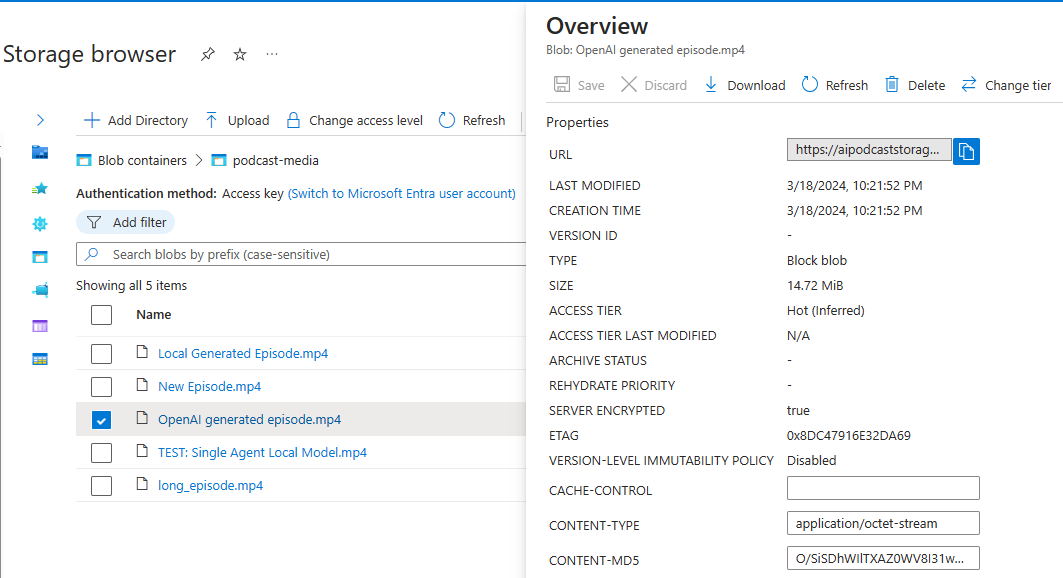
For data storage, we've chosen to use Azure Cosmos Database with MongoDB API to store the records of each episode once it's generated. Considering the file size of the podcast video, we store all the multimedia data in Azure Blob Storage, which is specifically designed for storing large files for distributed access.
When a new episode is generated, the python function app runs a script to upload a mongoDB document to the Azure Cosmos DB, which includes the title, description, and a link to the podcast video. In the meantime, the python function app uploads the actual podcast video onto the Azure Blob Storage.
APIs
Throughout the project, we have used different APIs (application programming interfaces that connect components to communicate with each other). They enabled us to automate most of the tasks that had to be done for our podcast including script, audio and video generation.
-
OpenAI API
-Used for generating the script.
Primarily used for generating the script of the episodes by sending prompts to OpenAI.
-
ElevenLabs API
-Used for converting Text to Speech and cloning voices (e.g., cloning Joe Rogan voice).
For instance, to clone the voice of Joe Rogan, we followed a straightforward process. We first uploaded sections of his speech from his podcast "Joe Rogan Experience". Then, we used the Voice ID generated and incorporated it as a voice option within our Text-To-Speech component of the code, called AudioGeneration. From there, it is very easy to generate audio chunks, using his or someone else's voice by selecting the preferred voice option.
-
IBM Watson API
-Also used for converting Text to Speech.
Just like with ElevenLabs API, IBM Watson API helps us turn text into speech. However, using IBM watson we chose to work with pre-recorded voices, making things a bit easier, though sacrificing a bit of naturalness in the voice quality.
-
StabilityAI API
-Tool used for converting Text to Image.
We used StabilityAI API to automate the process of generating images that are used for video generation. A function within video generation uses the text script to identify its keywords and then these keywords are used in a prompt in order to generate an image using StabilityAI.

