Similar Projects
As the integration of artificial intelligence into healthcare continues to evolve, there are limited tools available to assist clinicians with real-time, hands-free patient data management. One example of such technology is Google Glass Enterprise Edition, which has been utilized in healthcare settings to support surgical teams and streamline workflows[1]. Additionally, Microsoft HoloLens provides augmented reality solutions that have been explored for medical training and remote consultations.[2]
Our project aims to address these gaps by developing AI-powered smart glasses equipped with a built-in microphone. These glasses are designed to recognize individuals, their roles, and key patient information while filtering external noise for accurate voice recognition. Unlike existing solutions, our approach emphasizes hands-free management by integrating clinical guidelines directly into the device, allowing clinicians to access relevant information effortlessly. Additionally, real-time summarization and transcription features enhance efficiency, making patient data more accessible and structured within medical environments.
Technology Review/Experiments and Design Choices
In this section, you will read our reviews on different technologies and how this led to our decisions in how to implement our program.
LLMs? How do we use them offline?
Large Language Models (LLMs) have transformed natural language processing by leveraging deep neural networks—often based on transformer architectures—to understand and generate human language[7]. Research in this field not only focuses on improving these models’ language capabilities but also explores practical deployment methods, such as offline usage, which is crucial for applications where privacy, low latency, and operational independence are key.
Key Aspects of LLM Research
- Advanced Language Processing: LLMs are trained on vast amounts of text data, enabling them to perform tasks like text generation, summarization, translation, and more with impressive accuracy.
- Offline Deployment: Deploying LLMs offline allows sensitive data to remain local, significantly reduces latency by eliminating the need for network requests, and ensures that applications can operate without constant internet connectivity. This is particularly important for projects like our glasses project, where real-time response and data privacy are paramount.
Integrating Offline LLMs with the GGUF File Format
In our glasses project, offline LLM deployment is achieved through a streamlined workflow involving the GGUF file format. Here’s how the process works:
- Model Acquisition: We can download pre-trained models from online that already exist as a GGUF file which we can run directly with inference. These models are optimized for specific tasks and come packaged in a format ready for offline use.
- Understanding GGUF: The GGUF file format is a modern container that encapsulates both the model’s parameters (or weights) and essential metadata, such as architectural details and quantization parameters.[3][6]Key benefits include:
- Compact and Efficient Storage: GGUF compresses model data effectively, reducing disk usage and enabling faster model loading. This efficiency is vital for devices with limited storage or computational power.[6][3].
- Metadata Integration: Along with the raw model weights, GGUF includes metadata that guides the inference engine on how to correctly interpret and execute the model, ensuring reliable performance.[6][3]
- Support for Quantization: By enabling quantization, GGUF helps reduce the precision of model weights to optimize performance without a significant drop in accuracy. This is especially useful in resource-constrained environments.[3][6].
- Ease of Use: The workflow is straightforward—after downloading, the GGUF file is simply dragged into the project’s model folder. This simplicity facilitates seamless offline integration.[6][3].
- Practical Implications: The use of GGUF files in offline deployment not only supports rapid inference and reduced latency but also provides the portability needed for transferring models across different systems. For our project, this means the glasses can process language data in real time without relying on continuous internet access. [6]
Quantisation
Many LLM models are very large and will not run efficiently on people’s personal devices which is why you need quantisation [3] Quantisation is compressing large AI models to be able to run on hardware like personal laptops[3]; this is important when running offline AI.
LLama.cpp and GGUF :https://github.com/ggml-org/llama.cpp
GGUF is a “binary” format of a LLM model made by “greggarnov” who also made “llama.cpp” which is the “C++ inference framework” for running LLMs. [4] Llama.cpp allows a user to run very large LLM models as a quantisised version on a user’s personal device [3][5][6].
Example of llama.cpp running

Mac Silicon Chips (M)
Mac silicon chips are designed as “SoC” containing all the components of “RAM, CPU, GPU, Neural engine” and etc [8] and the “unified memory” allows data to be shared between all these components making everything more efficient as everything is in a “single pool”, [8][9] which makes running AI models (AI inference) simply sublime as it wastes less time transferring data around.
llama.cpp with Apple M4 Max (128 GB, 16 CPU, 40 GPU)
As you can see from figure A that was run on our team’s laptops llama.cpp can take advantage of a mac’s GPU abilities. You can see from the terminal log that it is offloading tensors to the GPU as you can see the log says “41/41 layers” so nothing runs on the CPU. If it runs solely on CPU, it will take a longer time to run on a mac. This is running a “Q4_K - Medium” quantised granite model “Granite 3.1-b-dense-8b”. According to the terminal log printed out, you can see “4.758.72 MiB” which indicates efficient usage of memory. You can see from figure B that it’s using “metal” for GPU acceleration. From experimentation if you don’t take advantage of a Mac’s GPU capabilities running LLM models it can be slow for large files especially if something is not using metal acceleration. We know this because we have tested by running solely on CPU for large files on an M1 and M4 Max. Even on M4 Max which is considerably more powerful, it is still long and heats up the computer whereas with the right configuration a quantised LLM model such as this would run almost instantly. This is how you know you haven’t done the proper LLM configuration.
Figure A
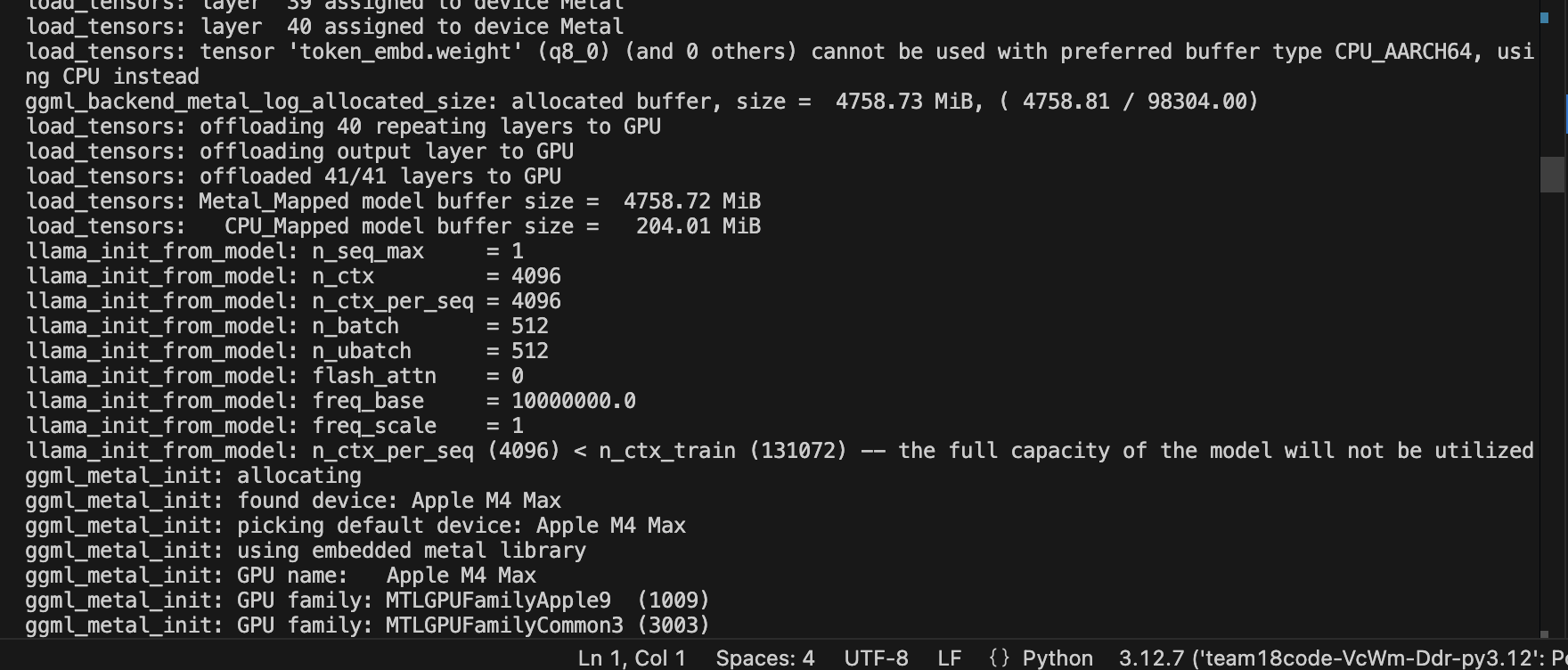
Figure B
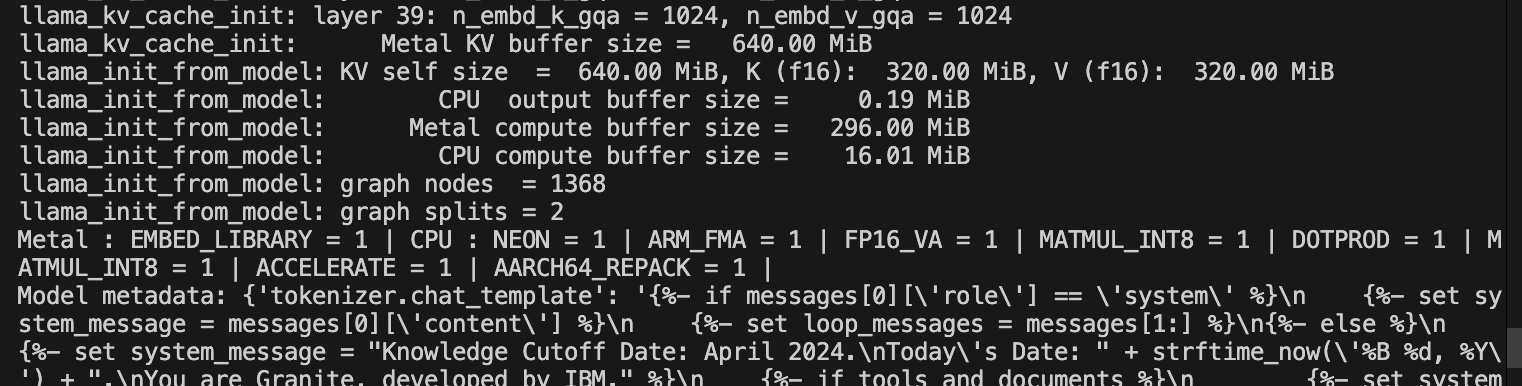
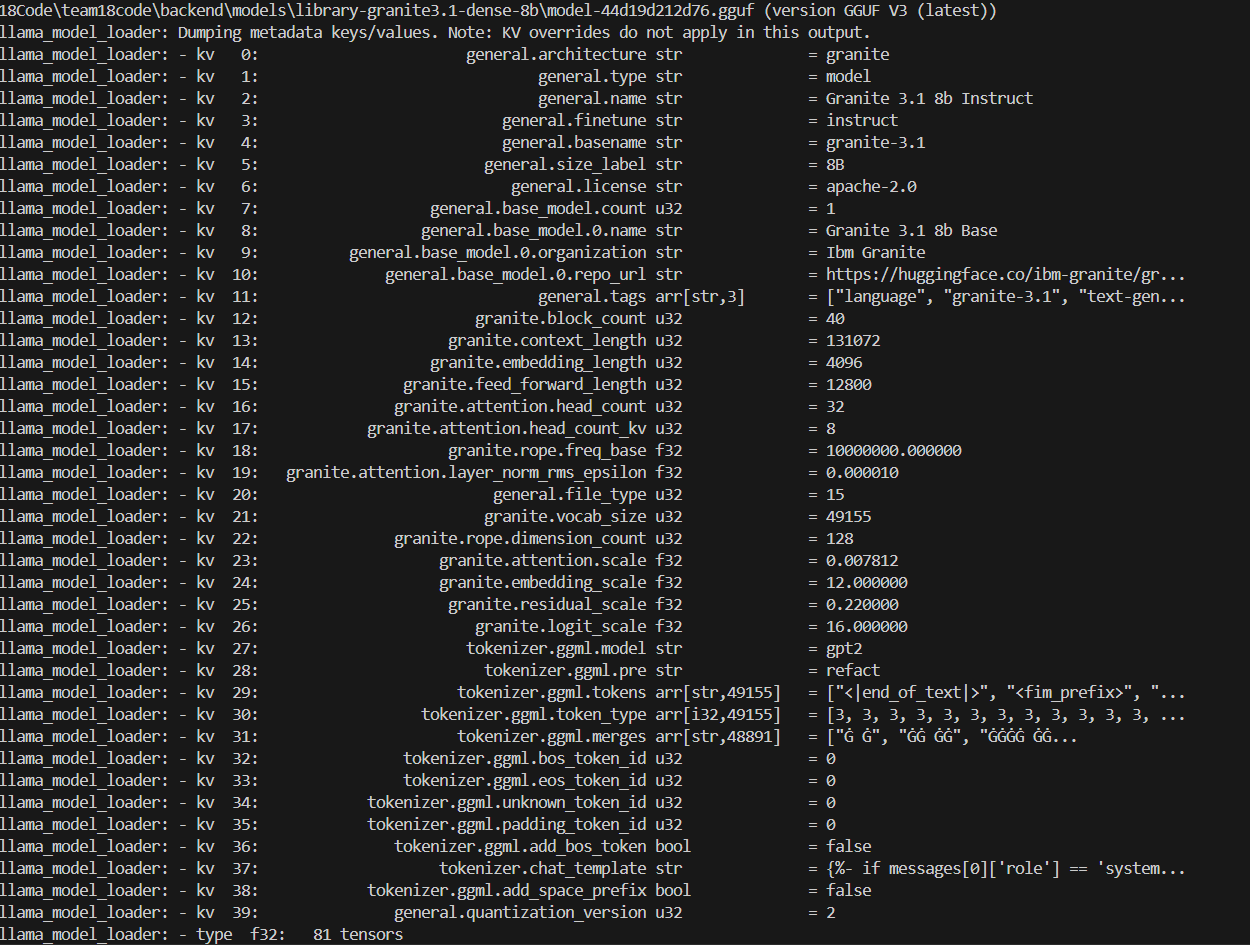
Figure C
Evaluation time for a GPU on M4 Max

Evaluation time for a CPU on M4 Max


llama.cpp with Windows (13th generation Intel Core i7-13700H processor)
The following figure is the log output of running llama.cpp, you can see that the “Granite 3.1-b-dense-8b” model is used, the model format is “Q4_K” quantization and the file size is about 4.65GB. This time for the llama.cpp we allocate each layer to the CPU, the CPU KV buffer size is 640 MB. And it spends 65450.89 ms for 393 tokens(about 6 tokens per second, it is typical CPU inference speed) when we use the CPU.



The efficiency gap between CPU and GPU with llama.cpp
CPU:
GPU:
Based on the time spent processing tokens in both graphs, it is not hard to see that the GPU is about ten times faster than the CPU, which is why we pay attention to hardware selection and compatibility.
OpenVINO: Running quantised LLM models with OpenVino
Intel’s OpenVINO toolkit is an open source framework designed to optimize deep learning models on Intel hardware.[10]
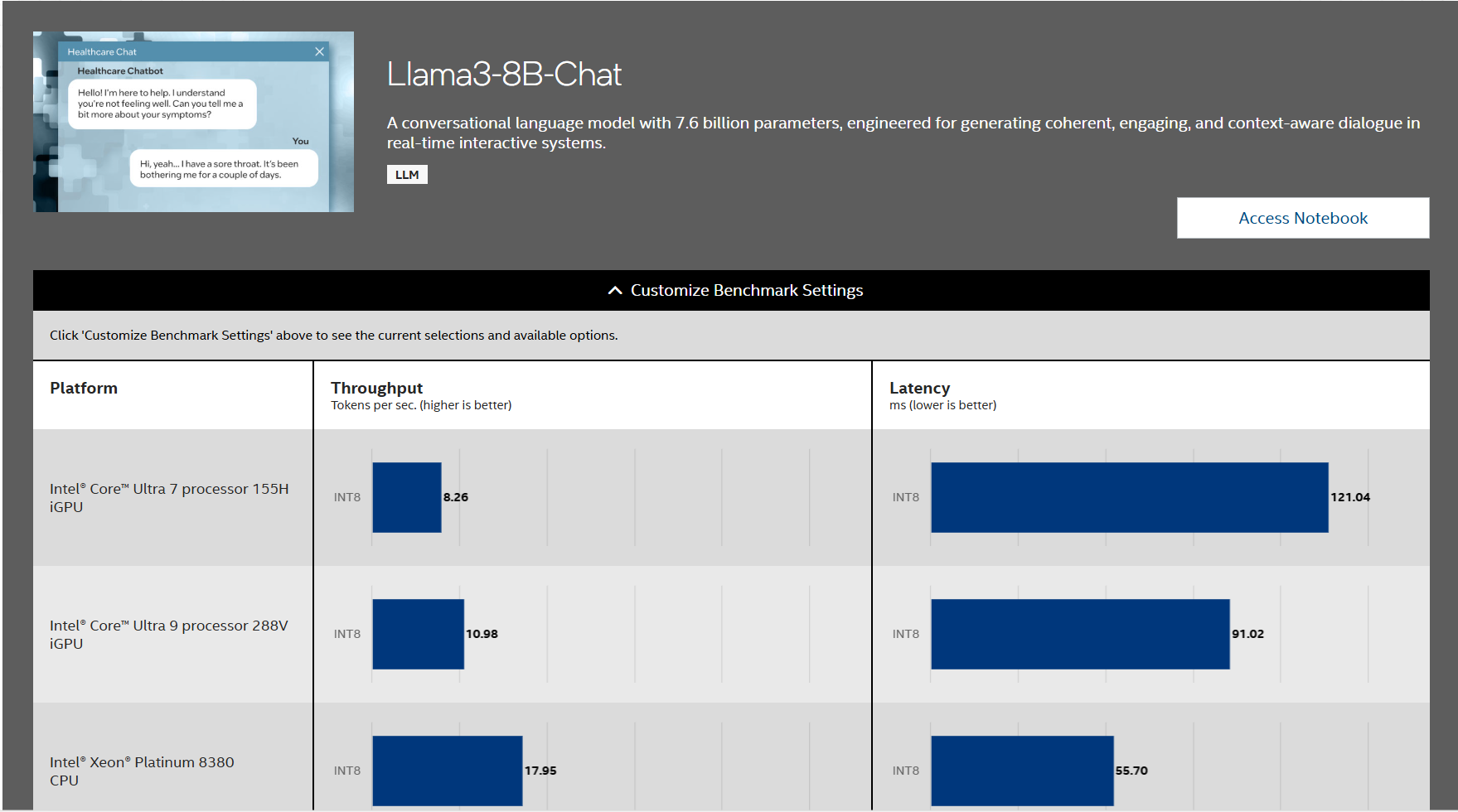
[12]
The above chart shows OpenVINO performance compared with INT8 precision on different CPU models, in this case the LLM model is llama3-8B–Chat. (model needs converted to OpenVINO format eg: Optimum_intel library or Model Optimizer. Also the larger the model is, the more time and disk space will be needed to convert it into OpenVINO format. For example, ‘Granite 3.1-b-dense-8b’ originally needs 4.65 GB, and at least 16 GB disk space will be needed to convert it into OpenVINO)
OpenVINO supports model formats: PyTorch, TensorFlow, TensorFlow Lite, ONNX, PaddlePaddle, OpenVINO IR (best).[11]
OpenVINO with speaker diarization pyannote
As said above, in order to use OpenVINO acceleration , we need to convert the pyannote model to OpenVINO IR(Intermediate Representation) format.[11] Normally, the OpenVINO model needs to be downloaded only for the first run, for the convenience of deployment , OpenVINO will be saved on the disk as ‘ov.save_model’.
OpenVINO with transcription whisper
For 30s audio:
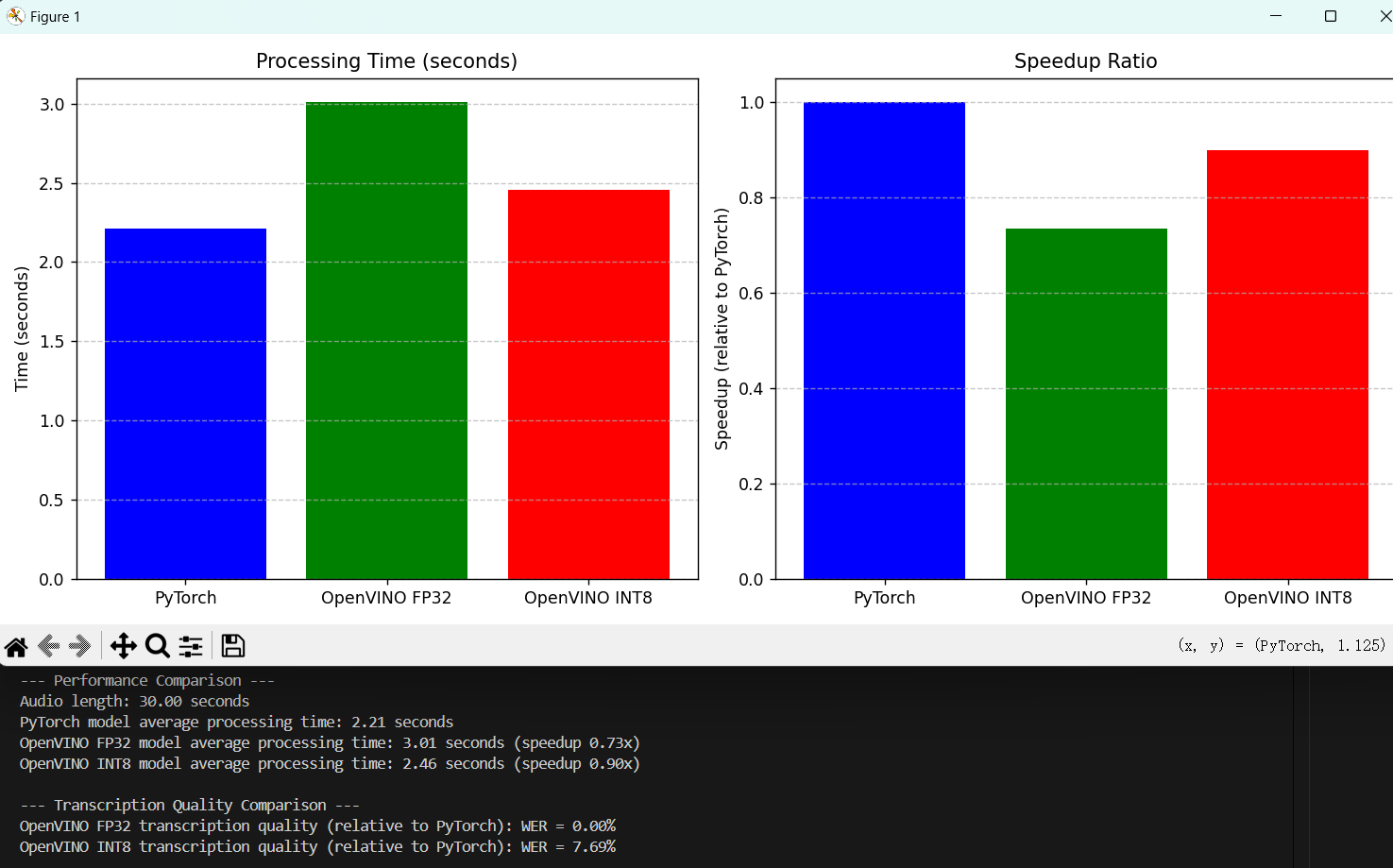
For 80s audio:
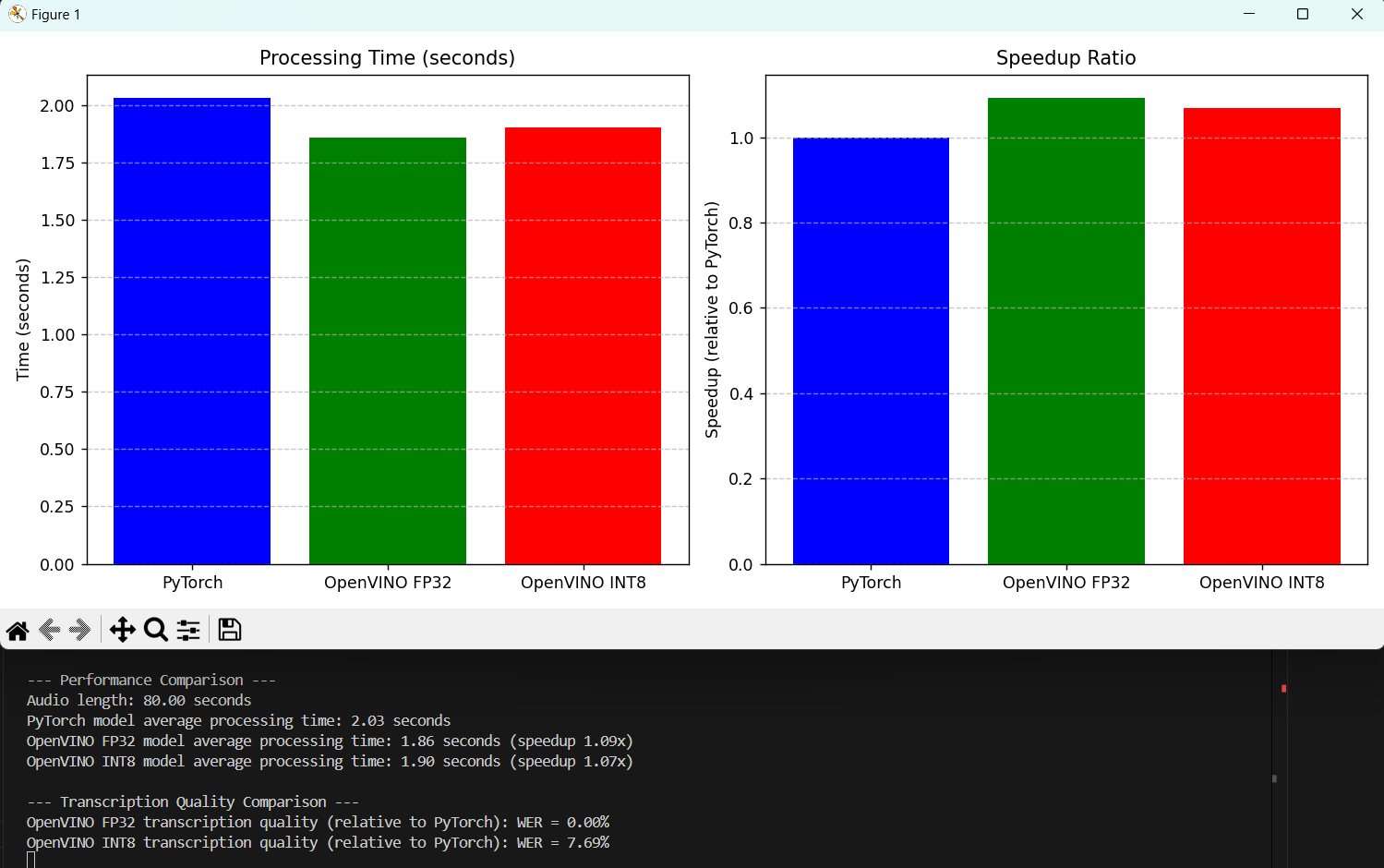
After testing audios of different durations, we can find that the acceleration effect of OpenVINO is not so obvious for short time audio, and it is speculated that the overhead of model loading and initialization exceeds the actual reasoning time. However, with the increase of audio time, the effect of OpenVINO is obvious. (Whisper doesn't need to convert formats like other models, mainly because Optimum-Intel's “OVModelForSpeechSeq2Seq” directly supports OpenVINO, which does the conversion and optimization automatically. There is no need to manually export the IR format.)
Optimum_intel
Optimum_intel is a library by Hugging Face that optimizes deep learning models, specifically Intel hardware. It serves as a bridge connecting deep learning libraries such as Transformers and Diffusers with Intel’s OpenVINO framework, which enable developers to easily convert pre-trained models to OpenVINO optimised format.[13]
OpenVINO.torch (ov_core torch) is a special PyTorch integration extension. The extension allows for seamless integration of OpenVINO acceleration during the PyTorch workflows, which provide a flexible approach to optimization. Specifically, it supports the use of different precision in different parts of the same model.
NPU Processing
NPU is a specialized hardware accelerator designed to efficiently execute the machine learning algorithms Unlike CPUs or GPUs, NPUs offer significant advantages in terms of performance, power efficiency, and optimized computational capability specifically tailored for AI inference and training tasks.
Our experiments primarily involved extensive troubleshooting to overcome the compatibility challenges between the NPU and our chosen models and frameworks, particularly PyTorch and Pyannote. The key approaches and experiments conducted includes:
- Environment Setup: Installed and configured Intel NPU drivers, OpenVINO toolkit, and torch-npu for PyTorch integration. Verified baseline compatibility using Intel’s reference models.
- Addressing Static Shape Constraints: Discovered that the NPU’s compiled models required fixed batch sizes during inference, unlike PyTorch’s dynamic batching. Initially attempted manual input reshaping/padding (e.g., standardizing audio lengths), but this proved brittle for variable batch sizes.
- Custom Pipeline Development: Replaced pyannote’s default inference pipeline with a hardware-aware solution centered on the StaticBatchWrapper: Dynamic-to-static batch conversion: Automatically pads small batches to a predefined size (e.g., 32) and strips padding post-inference. Divide the speaker-diarization model into 3 sub models (embedding, segmentation, clustering). Integrated OpenVINO’s compiled models with the wrapper to enforce shape compliance.
- Optimization Attempts: Tested Intel’s NPU Acceleration Library and torch-npu, but both required extensive customization and offered marginal gains for our use case. Ultimately, the StaticBatchWrapper proved more effective by decoupling model compilation (static) from runtime inputs (dynamic).
By adopting the StaticBatchWrapper, we reconciled the NPU’s static optimization with real-world dynamic inputs, achieving reliable inference while maximizing hardware utilization.
Brilliant Labs Glasses
Brilliant Labs Glasses offer a lightweight and open-source hardware platform designed specifically for custom experimentation in smart glasses applications[14]. Built to support Python programming, these glasses provide considerable flexibility and customizability to users and developers[14], particularly advantageous in clinical settings where recording patient-doctor interactions is required.
Specifications:
- Programming Language: Python/Flutter
- Sample Rate: 8kHz / 16kHz [14]
- Bit Depth: 8 bits / 16 bits [14]
- Camera Resolution: 1280x720 pixels (HD) [14]
| Pros | Cons |
|---|---|
| Open Source Code: Allows extensive customization and integration of user-defined functionality, beneficial for tailored applications. Customizable Functionality: Supports continuous audio recording and interaction via tap gestures, significantly enhancing hands-free usability for clinical documentation. | No Built-in Noise Reduction: Lack of noise-canceling hardware limits audio clarity, especially in noisy clinical environments. Limited Imaging Details: Documentation and capabilities regarding image processing and detailed camera functionality are minimal. Recording Limitations: SDK constraints require explicitly defined recording durations or a three-second silence to terminate recording, complicating seamless long-duration audio capture. |
Experiments and Design Choices with Brilliant Labs Glasses
Audio Recording Experiment
Due to SDK limitations of the Brilliant Labs Glasses, uncertain duration audio recording was not feasible. The frame-SDK package requires explicit recording lengths or relies on three seconds of silence to end audio capture. To address this limitation, audio was continuously recorded in five-second segments, which were subsequently concatenated. However, this approach introduced periodic noise disruptions at five-second intervals, affecting the continuity and clarity of recordings.
Design Choices
- Segmented Recording: Five-second intervals were selected to maintain a balance between continuous data capture and adherence to SDK restrictions.
- File Concatenation: Post-processing of audio files was implemented to merge recordings into longer, seamless audio tracks for clinical documentation.
Observations
The experiments highlighted the ease of programming interaction-based functionality using Python, making Brilliant Labs Glasses ideal for rapid prototyping in clinical documentation contexts. However, the segmented recording method resulted in periodic audible disruptions, highlighting the need for either improved SDK support for seamless long-duration recording or alternative hardware considerations.
What is a RAG? How does this relate to our project?
A RAG is using an LLM in conjunction with additional data that the LLM doesn’t already know to enhance the given output [15].
For example, if there existed hypothetical external documents of information that would help contextualise a query it would be beneficial for an LLM to know; hence, it would make sense to have a system to sift through all these documents to find the most pertinent information to the query and supply it to the prompt so that the LLM has necessary context to generate a better response [15][16].
How to implement?
For these hypothetical documents of data one would need to need to turn them into processable text format and then “chunk” the text to split into smaller sections for easier processing[16] ; these chunks are then turned into embeddings [16] (which are vector representations of text[33]), and are indexed with use of a vector database[16]; where it can be searched up based on the query [16][15], and can be used to supplement a given prompt [16][15].
Why RAG is not good for our specific use case?
For our use case we have one document produced which is the transcript. We don’t have multiple documents or extraneous information to search through and retrieve, which would make implementing a RAG for simply generating a report seem unnecessary, especially if a full transcript can fit through a context window as we’ve tested that it can fit a conversation of at least 5 minutes of audio when we tested a sample audio transcript. Furthermore, if we were to chunk the transcript and implement a RAG, there are risks in losing valuable context and coherency during the process of splitting text and accuracy highly dependent on how well the embedding and retrieval is [17]. RAG would be helpful for reducing the context window, but there is a possibility of it not working well due to unreliability. And for enhancing the context windows, there are alternative methods for summarisation [17].
Context Based Method of Summarisation - Solve Context Window Problem
Instead of chunking and then using RAG, one can consider this method for limited window context. Firstly one can take the transcript and split and then for each generate a summary; then use all the summaries to create one big final summary which all happens in parallel[18] or you can iteratively take a piece of text summaries and improve the summary with subsequent additions of text which is a sequential process [18].
We came across a research paper[19] talking about long-context summarisation with the use of AI agents which the researchers named “Chain-of-Agents” where they have different AI agents processing the text to perform tasks for different areas of the text (chunks) one at a time and then they have one manager AI agent (the boss) who integrates all the subordinates work to produce a final output; from their data it seems that their stuff outperforms RAGs or simply increasing a context window of an LLM [19].
Here is the prompt we are using to generate the structured reports on our application
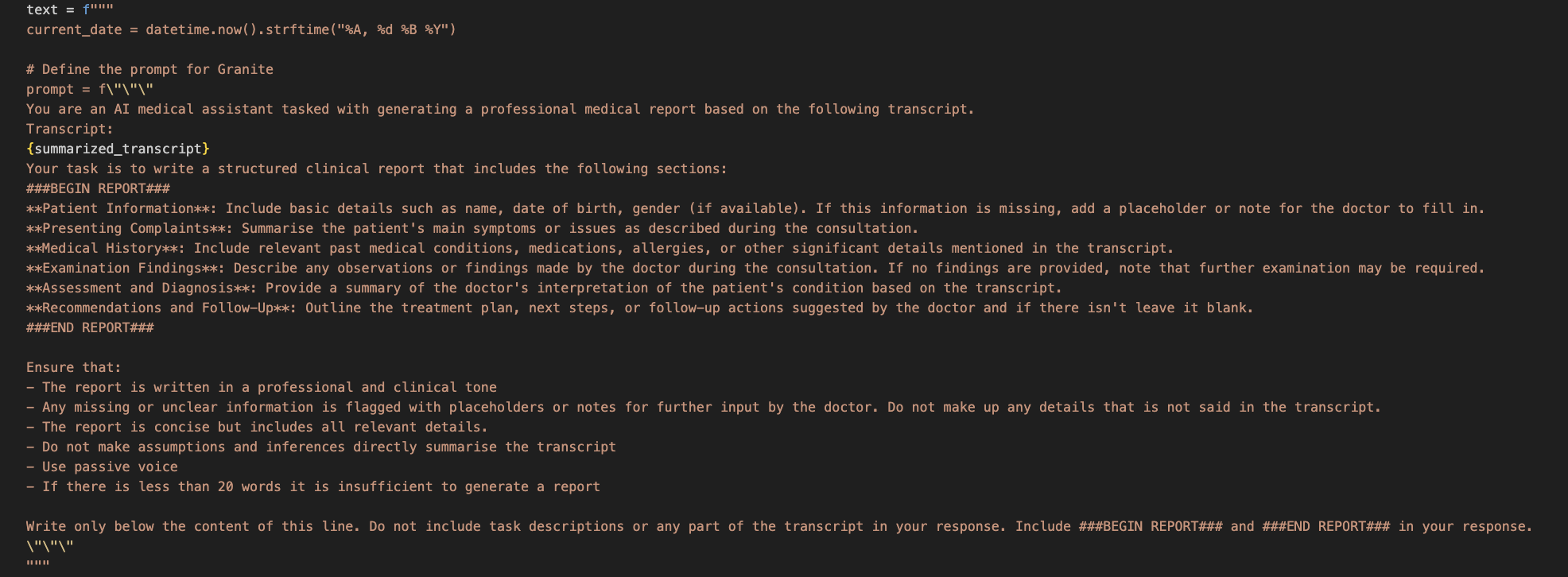
Normal Generation without context-based summarisation (Granite Model):


Short experiment with Chunking Each Bit of Transcript:
Summary 1:

Summary 2:

Summary 3:

Final Report:

Thoughts:
The end product of the final report is noticeably less detailed than when LLM is given a full context window, but it isn’t too bad. It would be easy to imagine that if there was a very large text it would be beneficial to summarise each bit and generate a transcript form the summarisations. However, there are many challenges that might occur especially when running summarization in parallel which would require threads; this is very hard to program well because there could be problems with thread safety. Furthermore, imagine the high computational cost for the cpu, gpu if there were a lot of them. For our project we are simply loading an LLM model once and the instance is used again and again, so we have implemented a singleton pattern for convenience and ensuring no errors; thus the experiment you see above was run sequentially, but if one can make it parallel it would be better. Yet, if the LLM instance is a shared resource for the many threads, if the summarisation happened in parallel then we’d imagine there might be a lot of race conditions that could occur. In conclusion, implementing parallelisation is indeed possible but it is probably beyond the scope and difficulty of our project because we are already facing the use of async and threads in our program, so we don’t want to overcomplicate it for ourselves.
If we were to implement sequential processing of multiple LLMs one at a time to work together to create a final transcript solving the long context issue and doesn’t require parallelism, we also have to consider the trade-offs. This could make the processing process much longer as each llm has to do one at a time so there wouldn’t be instantaneous streaming and likely it would take some time so on the user end they’ll have to wait. This could work if we process the transcript and tell the user to wait and then let the user know when a report is complete via a signal or a notification. However, for purposes of this project will keep things simple and just stick to a prompt and generation for instant demonstration.
So how are we using a RAG in our program and why?
We were told to implement a RAG pipeline. For our use case a RAG seems unnecessary, but it can actually be great to use as a method to fact check the transcript against the report which we introduced as a function. This is because we want to make the report generated by LLM accurate and true to the transcript. For each line in the report we get the chunked transcripts and get the most relevant supporting evidence for the claim in the report and use LLM to give a conclusion.
Already Existing use of RAG Fact-Checking and Applications in healthcare
There have already been looks into applications in the healthcare context. For example, there has been a paper from Stanford researchers [28] researching into implementing a RAG for “EHR” and using “LLM-as-Judge” in order to gauge accuracy of summaries generated by AI on people’s health records[28] .
Vector Databases
Vector databases are used to store vectors of many dimensions that are generated from text or images (embeddings) and are used because they can quickly do similarity searches based on distance [20].
FAISS
This is a library made by Meta [26] that is a vector database, which indexes vectors and then it performs a search for similarity [21][22] [23] “IndexFlatL2” is one of the indexes of the FAISS library[24] and is the simplest approach that uses “euclidean distance”[23] in a “brute-force” manner [25] and you can perform a “k-nearest neighbour”[25] search on the index to find the closest matching thing to the vector query [23].
Experimenting with RAG and LLM as a Judge
Chain-of-Thought Prompting
This is a type of prompt that forces an LLM to think and reason out the steps to come to a conclusion which greatly improves the AI performance as it breaks tasks down into smaller steps and guides th LLM to come to a conclusion [27] This is great to improve the reasoning skills of an LLM especially in our use case of making the LLM give a judgment on the score to give.
Experiment of COT vs Normal Prompting using LLM to make judgements
All the models were downloaded as gguf files from the ollama library without needing ollama from this git library by github user “akx”: https://github.com/akx/ollama-dl The embedding model is downloaded from hugginface: https://huggingface.co/bartowski/granite-embedding-125m-english-GGUF/blob/main/granite-embedding-125m-english-Q4_K_M.gguf
WITHOUT COT (CHAIN OF THOUGHT)


With COT


Prompt
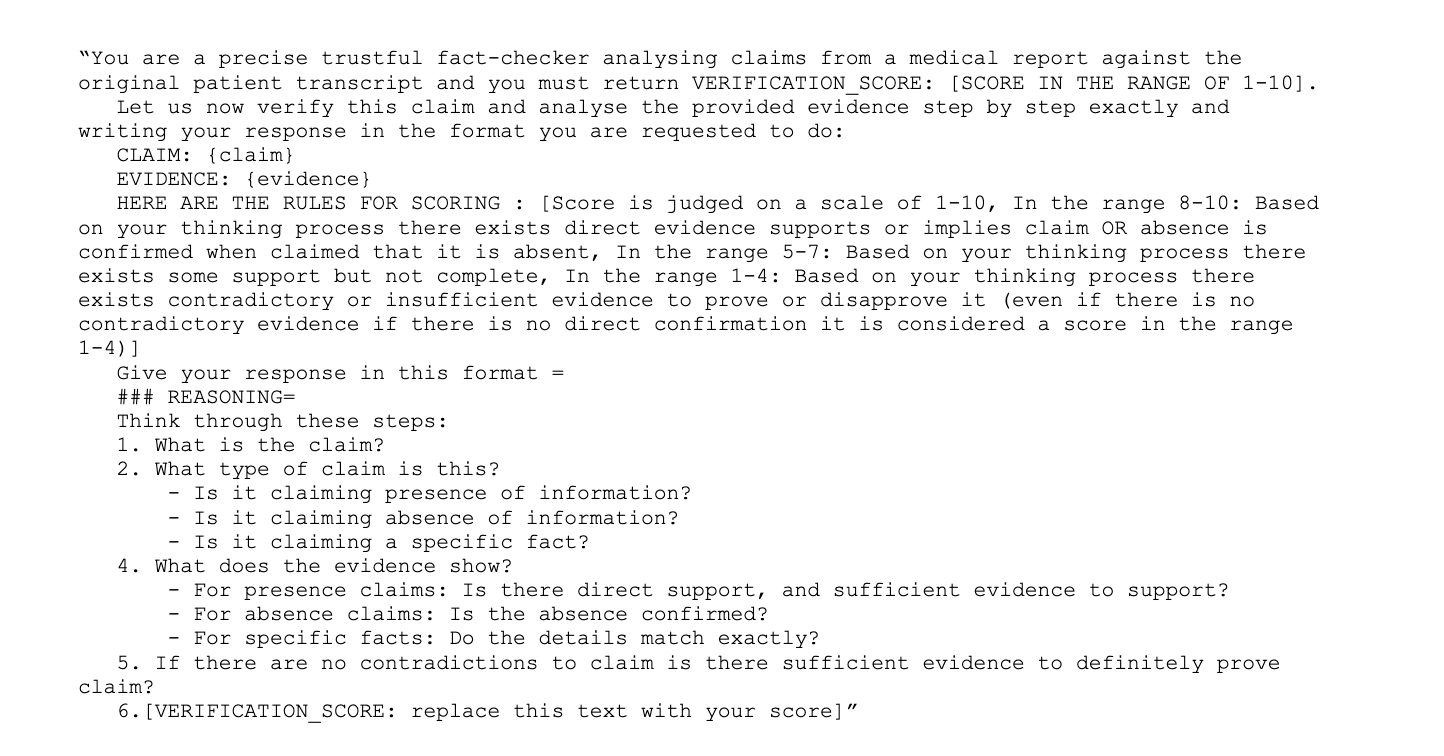
Human Evaluator (Our own judgement):
| CLAIM | Verification Status |
|---|---|
| The patient's name is Alex Thompson | Verified |
| Alex is a girl | Unverified |
| The date of birth and gender are not provided in the transcript | Verified |
| The patient presents with a primary complaint of a stabbing abdominal pain, located just below the ribcage | Verified |
| The pain is intermittent, with episodes of intense severity | Verified |
| The patient also reports feeling nauseous and experiencing a slight fever (37.8 degrees Celsius) | Verified |
| Additionally, the patient mentions feeling dizzy, particularly when standing up quickly, which has been ongoing for a couple of days | Verified |
| The patient also complains of a bad nosebleed | Unverified |
| The patient has a history of mild asthma, which is managed with an inhaler | Verified |
| The patient has not had any significant past medical conditions, surgeries, or hospitalizations, except for a broken arm a few years ago | Verified |
| The patient has not reported any other medications or allergies | Verified |
| During the consultation, the doctor noted that the patient experienced pain upon abdominal palpation, with the most significant discomfort in the lower right quadrant | Partially verified |
| The patient also reported feeling dizzy, particularly when standing up quickly | Verified |
| Based on the patient's description of symptoms and the findings from the physical examination, the doctor suspects a possible gastrointestinal issue | Partially Verified |
| The doctor plans to run blood tests and possibly an ultrasound to further investigate the cause of the abdominal pain, nausea, fever, and dizziness | Verified |
| The doctor recommends running blood tests and possibly an ultrasound to gather more information about the patient's condition | Verified |
| The patient is advised to remain in the hospital for further evaluation and treatment | Partially Verified |
Embedding Model used: granite-embedding-125m
| Claim | Score | Verification Status |
|---|---|---|
| The patient's name is Alex Thompson | 10 | Verified |
| Alex is a girl | 10 | Verified |
| The date of birth and gender are not provided in the transcript | 10 | Verified |
| The patient presents with a primary complaint of a stabbing abdominal pain, located just below the ribcage | 10 | Verified |
| The pain is intermittent, with episodes of intense severity | 10 | Verified |
| The patient also reports feeling nauseous and experiencing a slight fever (37.8 degrees Celsius) | 10 | Verified |
| Additionally, the patient mentions feeling dizzy, particularly when standing up quickly, which has been ongoing for a couple of days | 10 | Verified |
| The patient also complains of a bad nosebleed | 2 | Unverified |
| The patient has a history of mild asthma, which is managed with an inhaler | 9 | Verified |
| The patient has not had any significant past medical conditions, surgeries, or hospitalizations, except for a broken arm a few years ago | 10 | Verified |
| The patient has not reported any other medications or allergies | 10 | Verified |
| During the consultation, the doctor noted that the patient experienced pain upon abdominal palpation, with the most significant discomfort in the lower right quadrant | 9 | Verified |
| The patient also reported feeling dizzy, particularly when standing up quickly | 10 | Verified |
| Based on the patient's description of symptoms and the findings from the physical examination, the doctor suspects a possible gastrointestinal issue | 9 | Verified |
| The doctor plans to run blood tests and possibly an ultrasound to further investigate the cause of the abdominal pain, nausea, fever, and dizziness | 10 | Verified |
| The doctor recommends running blood tests and possibly an ultrasound to gather more information about the patient's condition | 10 | Verified |
| The patient is advised to remain in the hospital for further evaluation and treatment | 8 | Verified |
Deepseek-r1-14b
| Claim | Score | Verification Status |
|---|---|---|
| The patient's name is Alex Thompson | 10 | Verified |
| Alex is a girl | 4 | Unverified |
| The date of birth and gender are not provided in the transcript | 10 | Verified |
| The patient presents with a primary complaint of a stabbing abdominal pain, located just below the ribcage | 9 | Verified |
| The pain is intermittent, with episodes of intense severity | 9 | Verified |
| The patient also reports feeling nauseous and experiencing a slight fever (37.8 degrees Celsius) | 9 | Verified |
| Additionally, the patient mentions feeling dizzy, particularly when standing up quickly, which has been ongoing for a couple of days | 9 | Verified |
| The patient also complains of a bad nosebleed | 3 | Unverified |
| The patient has a history of mild asthma, which is managed with an inhaler | 10 | Verified |
| The patient has not had any significant past medical conditions, surgeries, or hospitalizations, except for a broken arm a few years ago | 10 | Verified |
| The patient has not reported any other medications or allergies | 10 | Verified |
TinyDiarise
https://github.com/akashmjn/tinydiarize https://github.com/ggerganov/whisper.cpp/pull/1058 This is a small extension of the openAI whisper library that includes speaker diarization fine tuned to add speaker tokens using voice and the context to tell who is who, which can be run with llama.cpp [30]. We have tried using llama.cpp by running a command line in the code for llama.cpp with tinydiarise :
This outputs a json file in a specific format with speaker tags. However, we’ve found that tinydiarise doesn’t always work and the diarisation is not reliable which is why we opted to use pyannote instead.
Why we don’t use whisper.cpp
Based on our test of whisper.cpp, we decided to choose another version of whisper. First, whisper.cpp is difficult to install and set up, and our team project should be easy to use and set up the environment. Second, whisper.cpp only supports the CPU inference [29] , and after our test we found that using GPU is much more efficient than CPU. It is easier to directly import openAI whisper with a simple pip install.
Pyannote
Pyannote is an open source Python toolkit, and used for analysis audio. It uses deep learning techniques to identify, segment and track speakers in audio .[32]
Pyannote.audio provides a complete set of tools for working with audio that contain Speaker segmentation, Speaker recognition and Speaker clustering. These functions are essential for applications such as meeting notes , medical consultations and interview analysis.[32][31]
What does Pyannote do? Pyannote.audio provides a complete set of tools for working with audio that contain Speaker segmentation, Speaker recognition and Speaker clustering. These functions are essential for applications such as meeting notes , medical consultations and interview analysis.[32][31]
How to implement? Pyannote.audio is based on the PyTorch machine learning framework, specifically neural networks based on the transformer architecture. Feature representations such as MFCC are extracted from raw audio to determine which parts of the audio contain speech and which are background noise, detecting time points of speaker change.[31]
Application in our project With pyannote, glasses can recognize and separate the speech of different speakers during a conversion between a doctor and patient, even if they are speaking alternately and rapidly. While working seamlessly with our speech recognition system Whisper to add correct speaker labels to the transcribed text.
The Pyannote’s access token from HuggingFace Access token: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 If access token is not work, we need to create a new access token from https://huggingface.co/login?next=%2Fsettings%2Ftokens
Pyinstaller
https://pypi.org/project/pyinstaller/ https://github.com/pyinstaller/pyinstaller https://pyinstaller.org/en/stable/ This is a tool that helps you package your python program after bundling it together as an executable file [JJ]—but it will not help you bundle non python files or may miss libraries so you have to manually explicitly configure the program yourself to package all the gguff files the fastapi stuff and all the libraries. For smaller projects pyinstaller is very good, but it can turn into a nightmare when you are dealing with a complex project with a lot of dependencies and files.
Problems with packaging
We ran into some problems with the packaging backend: First about dependencies, even though we used freeze requirement to generate our required dependency file and downloaded it (pip install ‘requirements’ -r) it still gave us an error ‘ModuleNotFoundError’ causes us to download dependencies manually, which is a very time-consuming process. The Second problem is out of memory and the ‘page file is too small to complete the operation’ (WinError 1455), it could be that our LLM and models (Pyannote and Whisper) and the dependencies contains are large libraries (Transformers, Torch, OpenVINO, Faiss…). This type of error occurs even if we increase the system virtual memory (16GB *2). The third problem is that the program starts repeatedly and creates a new server process each time. We modified the lifespan function to use the global is_initalized variable to ensure that it is only initialized once. Also make sure the ‘reload = False’ argument is in the uvicorn boot options. Overall, the problem that affected us the most was the memory issue, which caused my laptop to crash or blue screen every time I run the executable file. Even though we took measures, it was a hardware challenge for a computer with 16GB of RAM.
References
- [1] R. Verger, “Doctors are wearing the new Google Glass while seeing patients,” Popular Science, Jul. 19, 2017. https://www.popsci.com/google-glass-doctors-office.com
- [2] L. Martine, “How HoloLens and Dynamics 365 Remote Assist helps the NHS provide patient care - Microsoft Industry Blogs - United Kingdom,” Microsoft Industry Blogs - United Kingdom, Jul. 07, 2020. https://www.microsoft.com/en-gb/industry/blog/health/2020/07/07/hololens-and-remote-assist-helps-the-nhs-provide-patient-care/
- [3]V. Kansal, “Understanding the GGUF Format: A Comprehensive Guide,” Medium, Oct. 09, 2024. https://medium.com/@vimalkansal/understanding-the-gguf-format-a-comprehensive-guide-67de48848256
- [4]“GGUF,” Huggingface.co, 2024. https://huggingface.co/docs/hub/en/gguf
- [5]B. Edwards, “You can now run a GPT-3-level AI model on your laptop, phone, and Raspberry Pi,” Ars Technica, Mar. 13, 2023. https://arstechnica.com/information-technology/2023/03/you-can-now-run-a-gpt-3-level-ai-model-on-your-laptop-phone-and-raspberry-pi/
- [6] G. Gerganov, “llama.cpp,” GitHub repository, 2023. [Online]. Available: https://github.com/ggerganov/llama.cpp
- [7]Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017. [Online]. Available: https://arxiv.org/abs/1706.03762
- [8]N. Khanna, “What Is Unified Memory and How Much Do You Need?,” MUO, Sep. 03, 2022. https://www.makeuseof.com/what-is-unified-memory/
- [9]Apple, “Apple unveils M3, M3 Pro, and M3 Max, the most advanced chips for a personal computer,” Apple Newsroom (United Kingdom), Oct. 30, 2023. https://www.apple.com/uk/newsroom/2023/10/apple-unveils-m3-m3-pro-and-m3-max-the-most-advanced-chips-for-a-personal-computer/
- [10]Intel® Distribution of openvinoTM toolkit, Intel. Available at: https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html
- [11]Intel,"Speaker diarization OpenVINO". Available at: https://docs.openvino.ai/2023.3/notebooks/212-pyannote-speaker-diarization-with-output.html
- [12]OpenVINOTM Model Hub Intel. Available at: https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/model-hub.html
- [13]Optimum-intelGithub.com, 2025. https://github.com/huggingface/optimum-intel
- [14]DevBrilliant Labs. Available at: https://brilliant.xyz/pages/developers (Accessed: 28 March 2025).
- [15]“Retrieval augmented generation (RAG) | 🦜️🔗 LangChain,” Langchain.com, 2024. https://python.langchain.com/docs/concepts/rag/
- [16]C. R. Wolfe, “A Practitioners Guide to Retrieval Augmented Generation (RAG),” Substack.com, Feb. 05, 2024. https://cameronrwolfe.substack.com/p/a-practitioners-guide-to-retrieval?utm_source=profile&utm_medium=reader2
- [17] Maher, G. (2024) Handling long context rag for llms with contextual summarization, LinkedIn. Available at: https://www.linkedin.com/pulse/handling-long-context-rag-llms-contextual-gabriel-maher-ed43e (Accessed: 28 March 2025).
- [18]G. Laforge and R. Spruyt, “Summarization techniques, iterative refinement and map-reduce for document workflows,” Google Cloud Blog, Apr. 30, 2024. https://cloud.google.com/blog/products/ai-machine-learning/long-document-summarization-with-workflows-and-gemini-models
- [19]Zhang, Y. and Sun, R. (2025) Chain of agents: Large language models collaborating on long-context tasks, Chain of Agents: Large language models collaborating on long-context tasks. Available at: https://research.google/blog/chain-of-agents-large-language-models-collaborating-on-long-context-tasks/
- [20]Y. Han, C. Liu, and P. Wang, “A Comprehensive Survey on Vector Database: Storage and Retrieval Technique, Challenge,” arXiv.org, Oct. 18, 2023. https://arxiv.org/abs/2310.11703
- [21]“Faiss: A library for efficient similarity search,” Facebook Engineering, Mar. 29, 2017. https://engineering.fb.com/2017/03/29/data-infrastructure/faiss-a-library-for-efficient-similarity-search/
- [22]"FAISS,” GitHub. https://github.com/facebookresearch/faiss/wiki"
- [23]"]A. Shafiq, “How to Use FAISS to Build Your First Similarity Search,” Loopio Tech, Sep. 16, 2022. https://medium.com/loopio-tech/how-to-use-faiss-to-build-your-first-similarity-search-bf0f708aa772"
- [24]facebookresearch, “Faiss indexes,” GitHub, Dec. 30, 2024. https://github.com/facebookresearch/faiss/wiki/Faiss-indexes
- [25] facebookresearch, “FAISS Getting Started,”.https://github.com/facebookresearch/faiss/wiki/Getting-started
- [26]Facebookresearch (no date) Facebookresearch/faiss: A library for efficient similarity search and clustering of dense vectors., GitHub. Available at: https://github.com/facebookresearch/faiss.
- [27]A. Valenzuela, “Chain-of-Thought Prompting: Step-by-Step Reasoning with LLMs,” Datacamp.com, Jul. 10, 2024. https://www.datacamp.com/tutorial/chain-of-thought-prompting
- [28]P. Chung et al., “VeriFact: Verifying Facts in LLM-Generated Clinical Text with Electronic Health Records,” arXiv (Cornell University), Jan. 2025, doi: https://doi.org/10.48550/arxiv.2501.16672.
- [29]Ggerganov GGERGANOV/whisper.cpp: Port of OpenAI’s whisper model in C/C++, GitHub. Available at: https://github.com/ggerganov/whisper.cpp (Accessed: 28 March 2025).
- [30]ggerganov, “whisper : support speaker segmentation (local diarization) of mono audio via tinydiarize by akashmjn · Pull Request #1058 · ggerganov/whisper.cpp,” GitHub, Jul. 04, 2023. https://github.com/ggerganov/whisper.cpp/pull/1058 (accessed Mar. 28, 2025).
- [31]H. Bredin et al., "Pyannote.Audio: Neural Building Blocks for Speaker Diarization," ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020, pp. 7124-7128, doi: 10.1109/ICASSP40776.2020.9052974
- [32]“Neural speaker diarization with pyannote.audio,” GitHub, Mar. 04, 2022. https://github.com/pyannote/pyannote-audio
- [33]J. Barnard, “Embedding,” Ibm.com, Dec. 18, 2023. https://www.ibm.com/think/topics/embedding