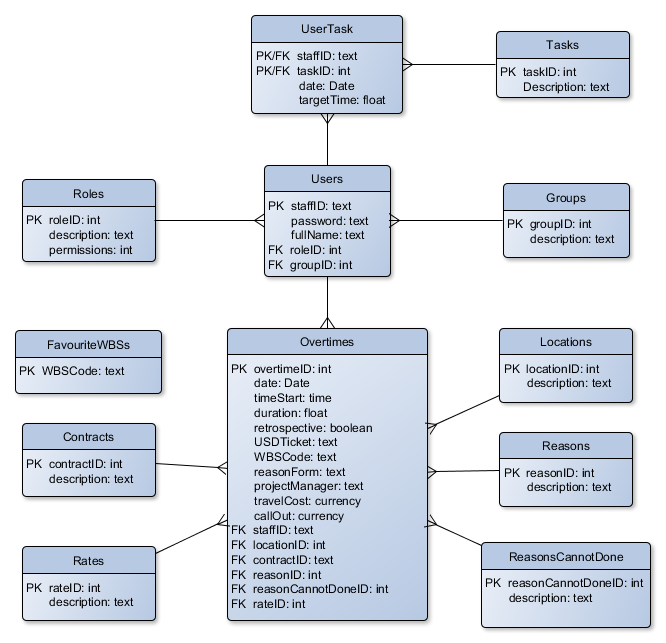
Database
Experiments
Experiment 1 - Find the most appropriate DBMS
We narrowed down a list of DBMSs to the most common ones (SQL Server, Oracle SQL, SQLite and MySQL) and we performed some tests to decided which one do adopt for this project.
| Experiment No. | Experiment Title | Experiment Details | Experiment Results |
|---|---|---|---|
| 1.1 | Dealing with different platforms | We have tried to install and perform small tasks (e.g. create a simple table) for every of the proposed DBMS in the following Operative Systems: Windows; UNIX-based systems. | As SQL Server is only available on Windows platform, we decided to discard it. |
| 1.2 | Dealing with proprietary software | To avoid intellectual property issues, we decided to research whether or not the proposed DBMS use a proprietary license | As Oracle SQL use a proprietary license, we decided to discard it |
| 1.3 | Data types variety | To facilitate further database improvements and extensions, we opted for a DBMS that allows as many data types as possible. Using each integrated environment, we had access to a list of all the available data types for each DBMS and we could therefore compare them | As SQLite offers way less data types than MySQL does, we decided to discard it. We eventually chose to use MySQL as DBMS to use for this project |
Experiment 2 - Find the most appropriate MySQL Engine
Once decided which DBMS to go for, we had to decide whether to adopt MyISAM or Innodb as table engine.
| Experiment No. | Experiment Title | Experiment Details | Experiment Results |
|---|---|---|---|
| 2.1 | Following ACID properties | Given the potential frequency of use of the system, we decided that ACID transactions had to be used to maintain data integrity. We therefore researched which engine made use of ACID properties | Consequently to our research, we found out that MyISAM does not offer ACID proprieties whilst Innodb does |
| 2.2 | Speed | Given the potential size of the system, we decided that speed was also to prioritise. We therefore researched which engine performed faster operations | Consequently to our research, we found out that MyISAM is slightly faster as it does not offer ACID proprieties |
| 2.3 | Finding a compromise | After performing some speed tests on our database, we found out the difference of speed between the two systems is not sensibly big, even performing multiple complicated calculations at the same time | We decided to value the ACID properties more than speed as data integrity is much more important for this particular project. Therefore we chose Innodb as engine to use for this project |
Experiment 3 - Data Normalisation and Standardisation
We went through the process of Data Normalisation and Standardisation for our Database and changed it accordingly
| Experiment No. | Experiment Title | Experiment Details | Experiment Results |
|---|---|---|---|
| 3.1 | Data Normalisation and Standardisation | Performed usual checks to see whether the created database respect the 1 st , 2 nd and 3 rd Normal Form and researched about the most used data standards | Performed usual checks to see whether the created database respect the 1 st , 2 nd and 3 rd Normal Form and researched about the most used data standards |
Experiment 4 - Dealing with fields’ data types
We needed to check the previous system and perform some tests on the new system’s fields to optimally satisfy the user requirements.
| Experiment No. | Experiment Title | Experiment Details | Experiment Results |
|---|---|---|---|
| 4.1 | Checking the data behaviour of the existing solution | Checked the behaviour of inserting any type of data in any field of the existing solution | Came up with a list of behaviours for each fields |
| 4.2 | Perform complicated overtime calculations | We performed some calculations on huge salaries and compared the outcome results with the ones of the existing system | Switched travelCost and callout fields from FLOAT to to CONCURRENCY type |
| 4.3 | Trying to put NULL values | We checked the errors thrown in case we omit any value | To not overcomplicate the system, we set every field’s boundary to NOT NULL |
| 4.4 | Fetch the example IDs into our Database | As we were undecided whether to use INT or TEXT type for IDs, we performed some research on the standard and the requirements of the system | We used TEXT for staffID as required from the client, but we used INT for the other keys for a performance and standardisation matter |