Overview diagram
PDF extraction tool
Algorithm
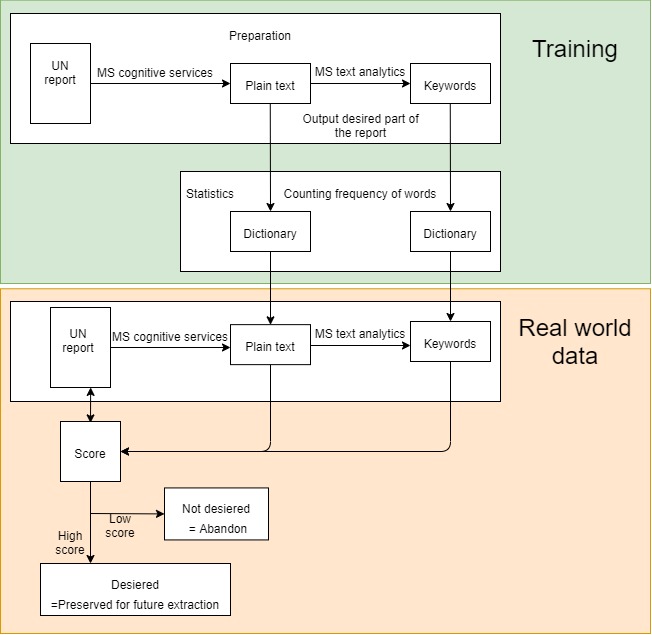
We input desired a particular part of the UN report as the training dataset. In this example, the training dataset consists purely of financial information. This is because financial information is fit for our purpose because the information is quantifiable, and so we can easily spot trends and patterns.
The Microsoft Cognitive Services Ink recognition API converts this pdf text into plain text. The Microsoft Cognitive Services Text Analytics API is then run on this plain text to extract the key words from the file. In order to build the dictionaries, two empty dictionaries are created initially. Each word in the plain text is checked to see if it exists in the dictionary. If it doesn’t, then it is added to the dictionary. If not, a counter is incremented to indicate a higher frequency for the corresponding word. The same process is applied to create a keyword dictionary.
The resulting dictionaries are exported as a search facility for another data set, which could be another UN report, for example. The same process is applied to this section, where Ink Recognition API is used to convert the pdf into plain text and the MS Text Analytics API is used to extract the keywords from the file. Afterwards, each word in the plain text and keywords are checked against the corresponding dictionaries (generated by the training dataset) and allocated a score. The score is higher for keyword match than a plain text word match.
At the end, both the plain text and keyword scores are accumulated. If the score is high enough, the input will be preserved for future extraction. If it’s too low, the input is not desired so this part will not be considered for future extraction. Essentially, the aim of this process is to check the relevancy of the information in each section of the report so that we only preserve the relevant sections for future analysis. The information in the relevant sections will be used to build the database.
This video, voiced by Rachel Mattoo, gives an overview of this algorithm:
Ink Recogniser
- An AI service that does OCR Recognition.
- Recognize digital information from pdf files. It can recognise 63 languages and locales.
- Makes inked content searchable.
- Digital ink data is presented in JSON format and it also includes REST APIs so that you can integrate into your applications across Windows, IOS, Android and the web.
Text Analytics
Detect sentiment, key phrases, named entities and language from your text