The repository containing our code can be found here
Overview
We have made huge progress in the "first phase" of development, which focuses on creating a set of relevant keywords we can use to search documents.
It is important to automate this process to create a set of keywords most representative of the dataset we have, as our algorithm can analyse all of the documents much faster than we ever could.
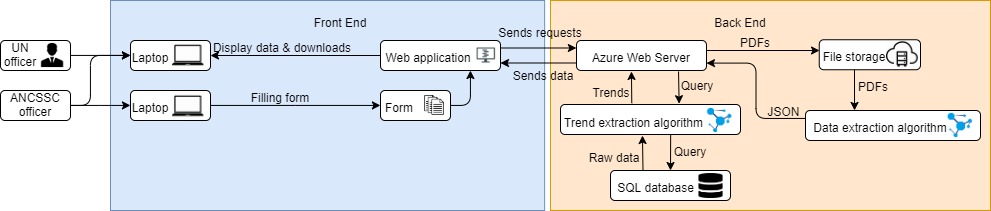
System architecture diagram
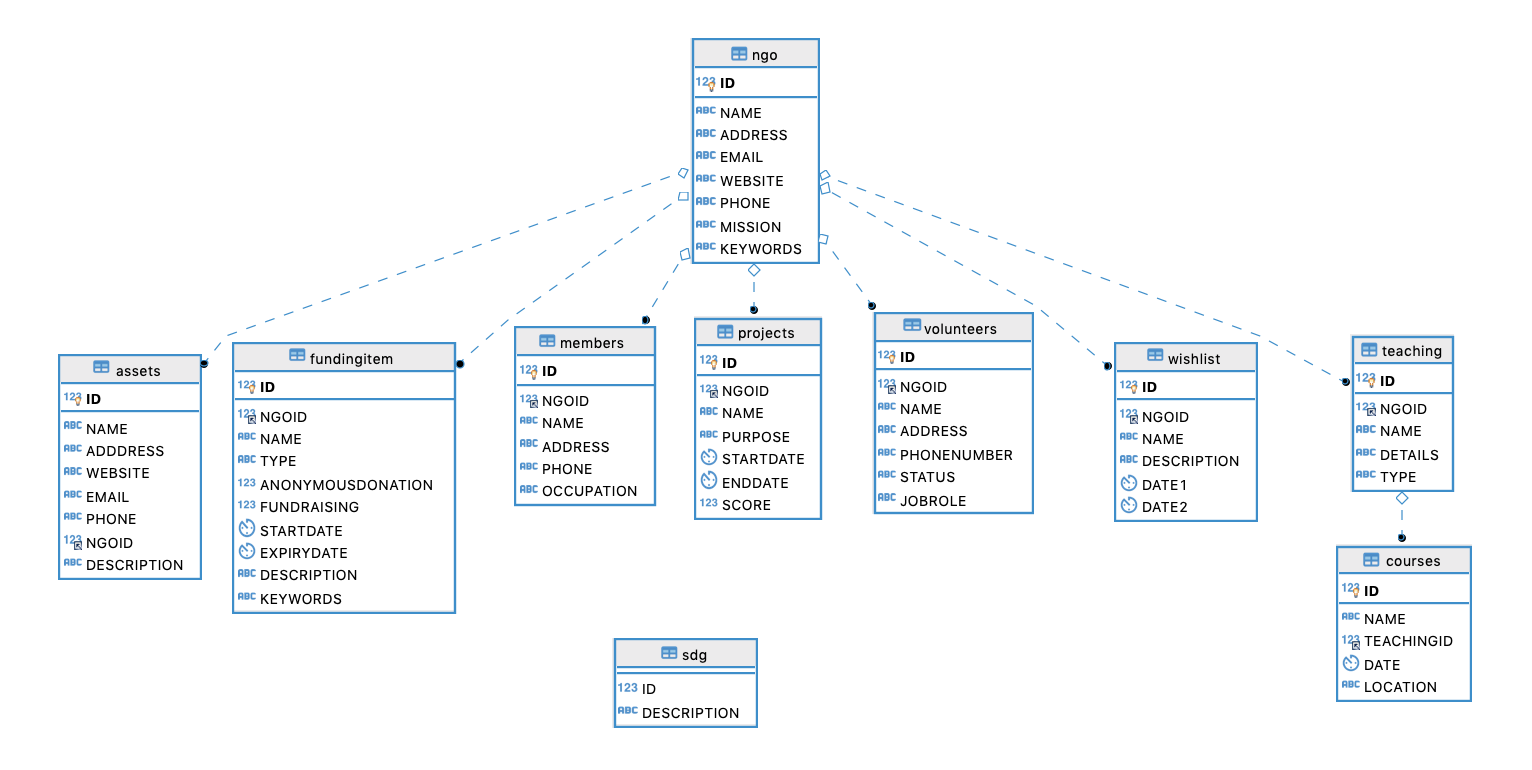
ER diagram for Database 1
Implementation of finished functionalities
A detailed write up of our current algorithm for the PDF extraction tool can be found in the Algorithms section.
This video, voiced by Rachel Mattoo, gives a concise demonstration of this algorithm: