Implementation
Frameworks & Overview
Frameworks

Pandas - Pandas is a tool that aids data analysis in python application, providing many auxiliary functions for data conversion, manipulation, and display.

Nltk(Natural Language Toolkit) - Nltk is a framework that helps convert user input into a form, useful for the developer. It employs features such as tokenization, synonym generation, POS-tagging, etc. Nltk allows the developer to analyze and assign meaning to lists of tokens or other streams of strings.
FuzzyWuzzy - A Python library that is used for string manipulation. It utilizes the Levenshtein Distance formula, in order to calculate differences between various word sequences and can be used by the programmer to create efficient algorithms that involve string matching.

Flask - A lightweight Python framework used for the creation of web applications that does not require third party libraries for the use of its functionalities.
An Overview Of The System
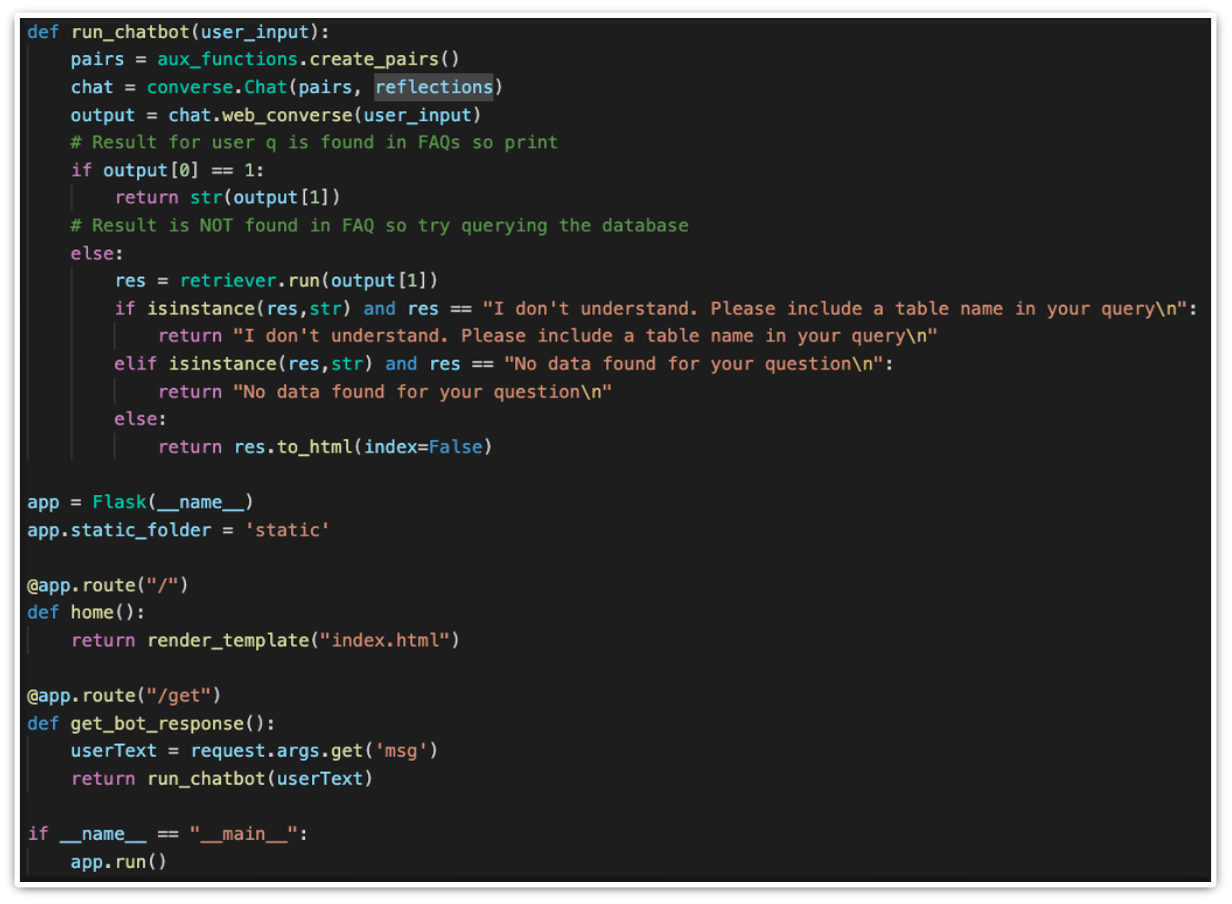
Our algorithm allows users to interact with a web-based interface to send queries in the form of HTTP requests to the back end of the application. The back end consists of a multi-layered processing system that recognizes the user's input as either a general conversation type of question, FAQ, or a Data Retrieval request. For general questions and FAQs, string input is split into a list of tokens by natural language processing. Common stop words in the English language are then removed from the list of tokens so that a vector can be formed from the word sequences using the cosine formula. Afterwards, a similarity percentage is calculated between the input being examined (which is now in vector form) and the list of questions in the database. If a match is found, then the relevant answer is returned, and if there are no matches, the chatbot proceeds with checks for data-retrieval questions. These types of questions are also split into tokens and pre-processed in the way FAQs are. For them, however, HeartBot uses string matching, synonym checks, and other utilities for categorisation. Keywords are extracted and then grouped into n-grams to check if any additional matches occur. Once the keywords are collected, they are assembled in a query, which is used to filter out a data frame, made with pandas. Results are displayed to the user in tabular form as a response is sent back to the web app.
FAQ Implementation
Our algorithm for FAQ categorisation initializes an internal storage, reading off a .txt file containing a list of given FAQs. Once the initialization stage is passed, different scripts are ran to calculate a confidence percentage between the user input and the list of FAQs.
aux_functions.py
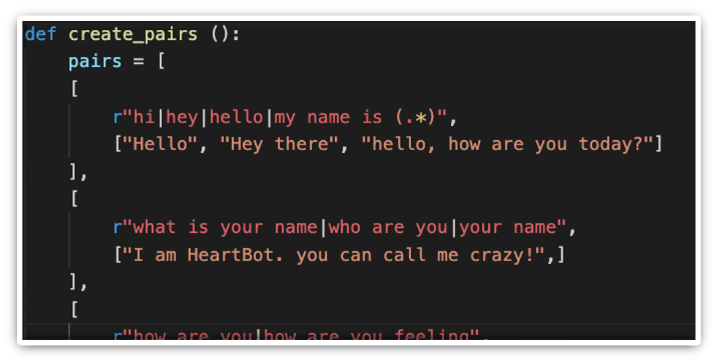
This python file contains two functions. One is for creating a list of the pairs used for the general conversations and greetings that the chatbot can recognize.
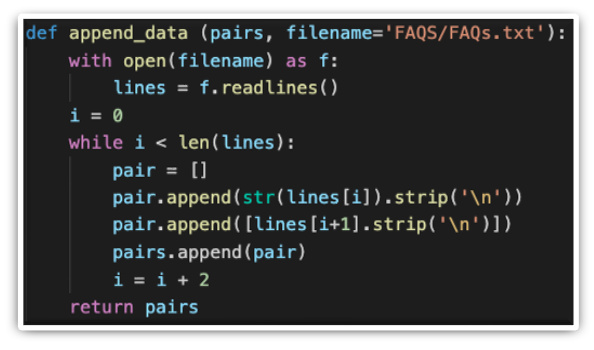
The other is for automatically reading and appending pre-stored FAQs and answers to the initial list of pairs that need to be recognized by the chatbot algorithm for FAQ matching.
best_match.py
This python file contains contains the BestMatch class, which includes multiple methods for comparing user's input to our database of FAQs. BestMatch calculates a similarity percentage based on the amount of overlapping tokens between two string sequences. It forms a vector to make use of the cosine formula and establish a list of similarity values that are used later on, and compared against a minimum confidence threshold.
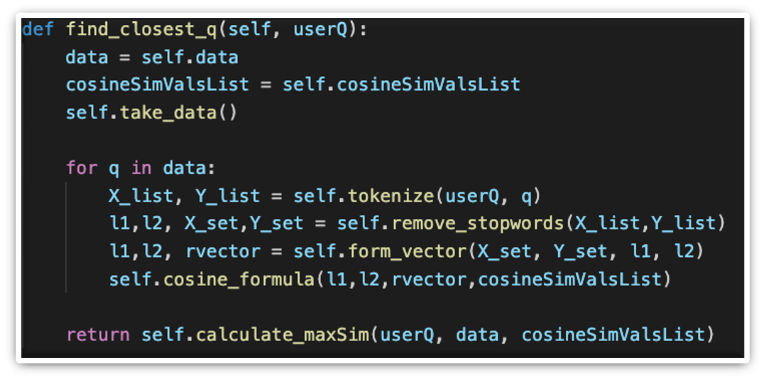
Data Retrieval Implementation
The process for data retrieval begins if the tokenized string input fails the FAQ categorisation, and thus an alternative solution needs to be provided to the user of the chatbot.
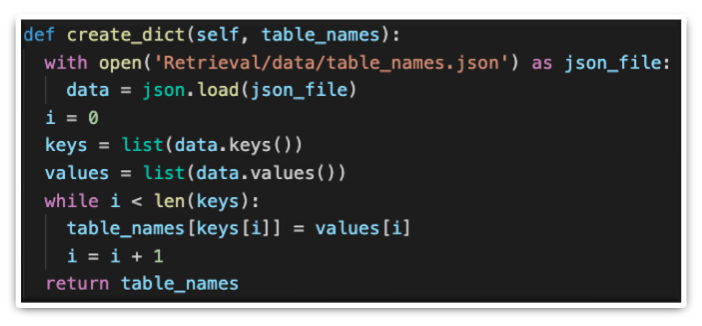
classifier_tab.py is used to classify the table from the BHF compendium, from which data needs to be extracted. The process begins with the creation of a dictionary that holds the actual names of tables from the compendium along with commonly used abbreviations/synonyms for them.
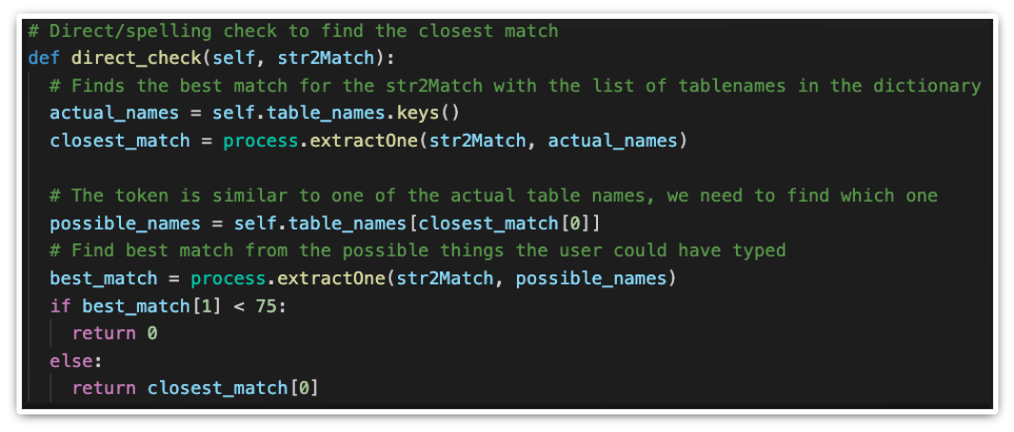
Afterward, with the help of fuzzywuzzy, a string match is attempted, utilizing the Levenshtein formula to calculate the distance between two strings and make out whether they are similar enough. This process in useful for matching both correctly typed and mispelled words in sentences.
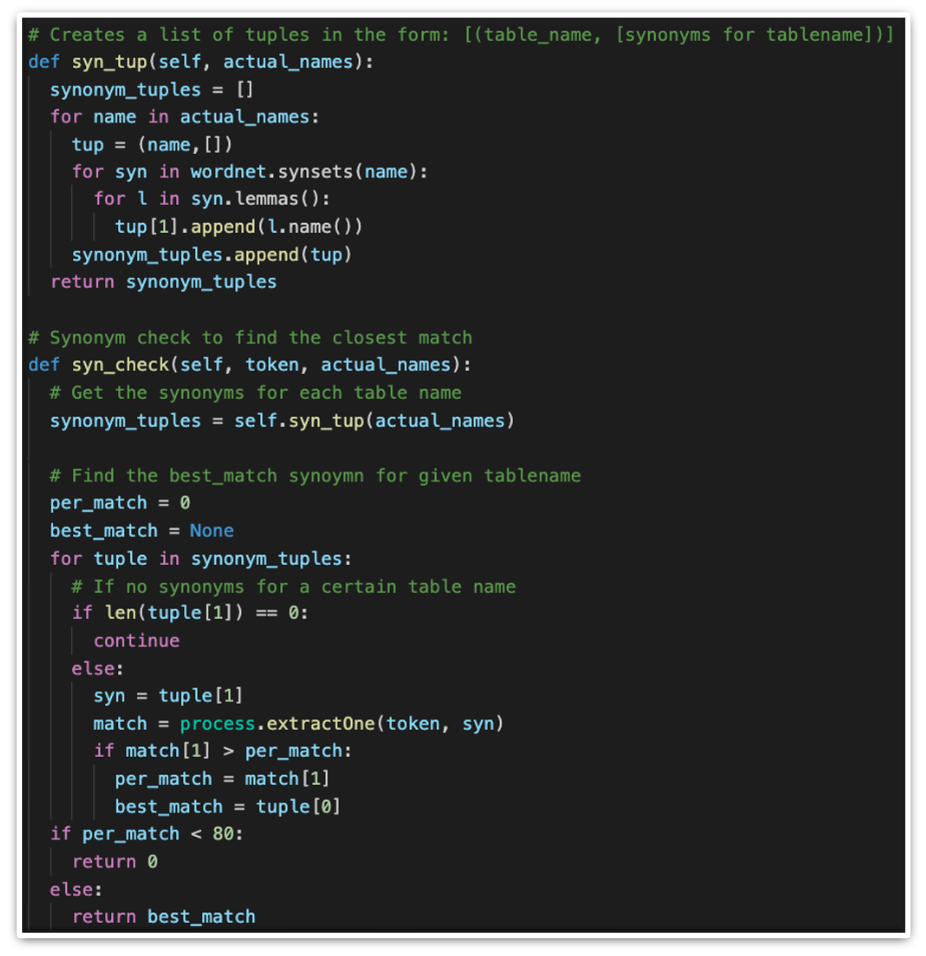
If a direct check fails, another categorisation technique is to match table names with synonyms from nltk's wordnet which is used to generate commonly used synonyms for various strings. In addition to this, pre-stored custom synonyms are also available to HeartBot to aid the matching process. This is crucial because wordnet does not contain all required synonyms.
After an appropriate table name is extracted, relevant column names need to be found and used as keywords to create a meaningful query, which can later be used to fetch data. To extract column names, the same checks are used as for the table names with the addition of an n-gram check, which groups the words into different sequences (combinations) to try and aid text classification. An n-gram is simply an array of strings or numbers in our case, since punctuation and symbols are removed in question pre-processing.
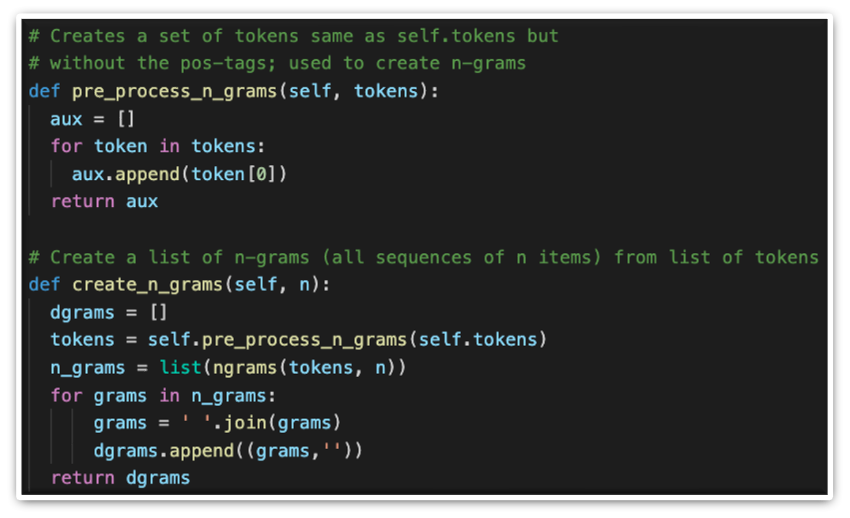
Both 2-grams and 3-grams are used for higher accuracy and better results. Here is how all checks are put together to extract column names.

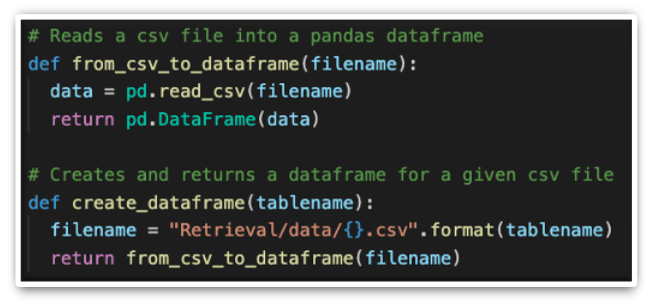
Finally, when as many keywords as possible are extracted, they are put to establish a pandas query, which is then sent to form and filter a pandas dataframe to display.
Forming the pandas dataframe, knowing the table name:
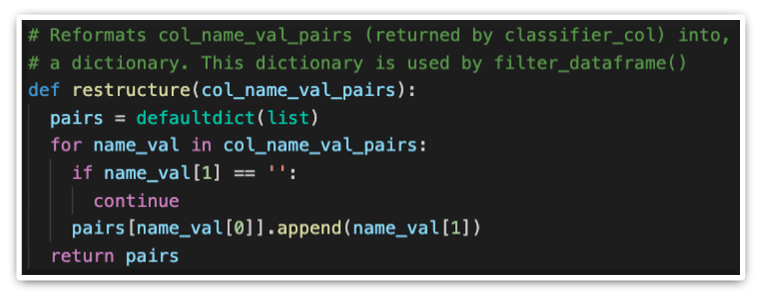
Restructuring keywords, in a format that can be used for the creation of a query:
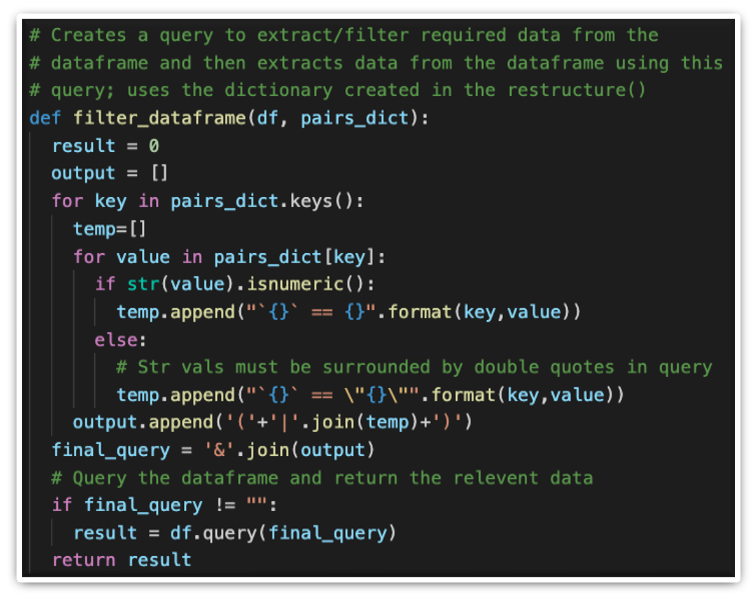
Forming the query and using it to filter the dataframe that is going to be sent to the WebApp for display:
Chatbot WebApp Implementation
The web application is very straightforward, as it sends HTTP GET requests to fetch data and returns an appropriate result from independently running the chatbot logic (if the result is a data frame, it converts it to html).