1 Our Implementations
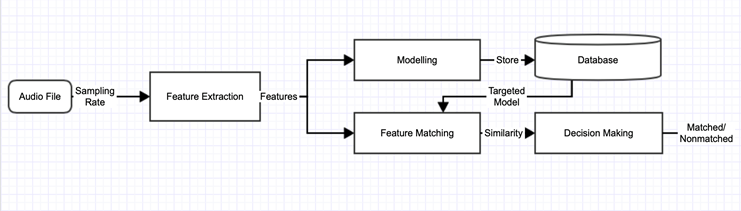
1.1 Feature Extraction Methods
Mel-Frequency Cepstral Coefficients (MFCC)
Mel-Frequency Cepstral Coefficients is an algorithm which focuses on accurately determine what sound comes out. “The shape of the vocal tract manifests itself in the envelope of the short time power spectrum, and the job of MFCCs is to accurately represent this envelope.” [1]
Linear Predictive Coding (LPC)
Linear Predictive Coding is an algorithm that is chosen mostly in audio signal processing for illustrating the spectral envelope of a digital signal of speech in compressed form, using the information of a linear predictive model.
Perceptual Linear Predictive (PLP)
Perceptual Linear Predictive approximates the auditory spectrum of speech by an all-pole model. This method has bark filter bank. Bark scale mainly reflects subjective loudness perception in auditory system. It is known that this method has lower computation speed than MFCC.
Linear Predictive Cepstral Coefficients (LPCC)
Gammatone Frequency Cepstral Coefficients (GFCC)
The Gammatone Frequency Cepstral Coefficients is based on gammatone filter bank, which models the basilar membrane as a series of overlapping band pass filters [4].
Cochlear Filter Cepstral Coefficients (CFCC)
Cochlear Filter Cepstral Coefficients is an auditory-based algorithm for extraction and measured regarding to a newly developed auditory-based time-frequency transform named Auditory Transform (AT) and a set of simulations from the processing functions in the cochlea.
Identity Vector (I-Vector)
I-vector is a front-end factors analysis which uses separate speakers and channel dependent subspaces. Its speech segment is expressed in a low-dimensional “identity vector”.
1.2 Comparisons of Feature Extraction Methods From Research
| Name | Type of Filter | Shape of Filter | What is modeled | Speed of Computation | Type of Coefficient | Noise Resistance | Sensitivity to quantization | Flowchart |
|---|---|---|---|---|---|---|---|---|
| Mel Frequency Cepstral Coefficient (MFCC) | Mel | Triangular | Human Auditory System | High | Cepstral | Medium | Medium | Pre-emphasis -> Framing& Windowing -> Mel-Scale Filter Bank -> Log -> DCT -> MFCC |
| Linear Prediction Coefficient (LPC) | Linear Prediction | Linear | Human Vocal Tract | High | Autocorrelation Coefficient | High | High | Frame Blocking -> Windowing -> Autocorrection Analysis -> LPC Analysis -> LPC |
| Linear Prediction Cepstral Coefficient (LPCC) | Linear Prediction | Linear | Human Vocal Tract | Medium | Cepstral | High | High | Frame Blocking -> Windowing -> Autocorrelation Analsis -> LPC Analysis -> LPC Parameter Conversion -> LPCC |
| Perceptual Linear Prediction (PLP) | Bark | Trapezoidal | Human Auditory System | Medium | Cepstral & Autocorrelation | Medium | Medium | Pre-processing -> FFT -> Bark-Scale Filter Bank -> Equal-Loudness Pre-emphasis -> Intensity-Loudness Power -> IDFT -> Linear Prediction Analysis -> Cepstral Analysis -> PLA |
| Discrete Wavelet Transform (DWT) | Lowpass & Highpass | - | - | High | Wavelets | Medium | Medium | - |
1.3 Modeling Methods
Gaussian Mixture Model (GMM)
Gaussian mixture model recognizes the speaker on the basis of log probability. It recalculates the log probability of voice vector and compares it to previously stored value. To attain a maximum likelihood estimate we utilize an iterative expectation-maximization (EM) algorithm.
Hidden Markov Model (HMM)
Hidden Markov Model is a statistical model that has unobservable states. In the Hidden Markov Model, the states are not directly visible, but the output is visible. Each state has a probability distribution over the possible outputs.
Vector Quantization (VQ)
Vector Quantization maps the vectors from a large set into groups. The Euclidian distance between the acoustic vectors of test speaker and the codewords in the codebook is computed. The speaker having the littlest Euclidian distance is chosen [5].
Dynamic Time Warping (DTW)
Dynamic Time Warping is a method for comparing two temporal sequences, its principle is basically dynamic programming. It can be used to eliminate the time difference caused by speaking speed between two speech patterns and compare the similarity [6].
2. Experiment Setup
We took a part of data from a public voice dataset called VoxCeleb as our dataset for testing. Our dataset has thousands of pieces of 3-6 seconds audio. In total, the audio is 5-hour-long. When we test, we make our system do speaker identification rather than speaker verification (we didn't specify the speaker to be verified and let the system identify the speaker who was talking). The accuracy was calculated and the duration was noted down.
3. Experiment Results
Hidden Markov Model (HMM)
| Framework | Accuracy | Duration | Description |
|---|---|---|---|
| MFCC + GMM | 95% | 4h30m | Success |
| MFCC + VQ | 45% | 7h on average | Partially Success |
| ### + HMM | - | - | Still Working |
| PLP + ### | - | - | Still Working |
| LPC + ### | - | - | Still Working |
4. Discussions and Conclusion
There are some open source libraries and APIs about
MFCC and GMM. We just used them to implement the two
algorithms. For the rest of the algorithms, there is
no libraries and APIs. We implemented them either by
reading papers or by studying other similar github
projects.
We tried our best when it comes to implementing the
algorithms and for some of them we succeeded.
We still need to do some work for some of them.
In terms of comparison
between frameworks, we expect PLP + VQ to have the
highest accuracy according to what we researched.