

A Telecommunication Provider company receives thousands of calls per day and needs to improve its customer service by verifying the customers in recorded calls. Thus, the calls are recorded and saved for further evaluation by the Quality Control department of the company. A part of the evaluation process is the verification of the customer which is a difficult task in the case this is not done by the call operator during the call. The application being looked for will provide the staff of the Quality Control department with the opportunity to load recorded calls and automatically verify the customers. The application will help the company to decrease the time needed for the evaluation process and improve its services, increase customers and revenue.
We decided to use semi-structured interviews, which involves both
fixed and opened questions. Compared to questionnaires,
interviewing allows us to guide the interviewees to provide
more suitable information we need, especially the answers to
opened questions.

Our previous project topic was "Speaker verification: Find out if your
voice sounds the same as your favourite celebrities".
After we finished the HCI coursework, the project topic was changed to
"Speaker verification in phone calls". We didn't have enough time to
do personas for the current project. So, the personas below are off-topic.
The goal of this project is to develop an innovative speech recognition methods using machine learning algorithms. Before implementing the state-of-the-art algorithm to verify the voice, literature review on the current practices would be conducted. According to the comparisons between various type of algorithms, a deep learning model would be set up by utilising open source libraries and trained based on any voice dataset. The learning algorithm would be demonstrated as a speaker verification application via webpages.
| ID | Requirement | Priority |
|---|---|---|
| 1 | Testing for finding out the framework with the highest accuracy | Must have |
| 2 | A "Upload Data" page | Must have |
| 3 | A "Start Verifying" page | Must have |
| 4 | A "Home" page | Must have |
| 5 | A "Processing" page | Must have |
| 6 | A "User Verified" page | Must have |
| 7 | A "Submit" page | Must have |
| 8 | A "Consent" Page | Must have |
| 9 | Literature review | Must have |
| 10 | Comparisons between different feature extractions | Must have |
| 11 | Comparisons between dimensionality reduction | Must have |
| 12 | Comparisons between diufferent learning models | Must have |
| 13 | Database | Must have |
| 14 | File Uploader | Must have |
| 15 | Audio Recorder | Must have |
| 16 | Feature extraction: MFCC | Must have |
| 17 | Modeling: HMM | Must have |
| 18 | Modeling: GMM | Must have |
| 19 | Front-End: Modify with AJAX | Must have |
| 20 | Use Existing Code (libraries and APIs) | Must have |
| 21 | Comparisons between different frameworks | Should have |
| 22 | Speaker Recognition VS Biometric Feature Extractions | Should have |
| 23 | A "Recent verifications" page | Could have |
| 24 | Feature extraction: PLP | Could have |
| 25 | Feature extraction: LPC | Could have |
| 26 | Optimisation - Check 2 or 3 digits of the number to find the user faster | Could have |
| 27 | {To be added} | Won't have |
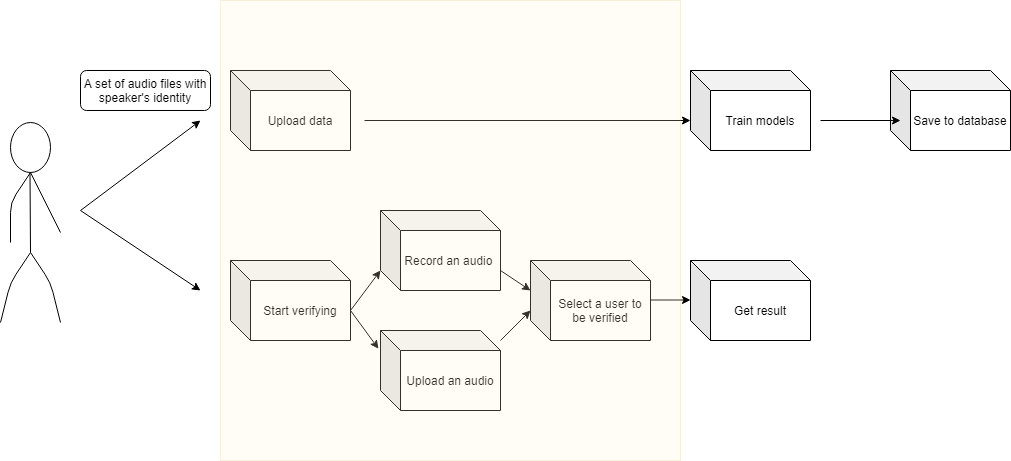
| ID | User Case For User |
|---|---|
| UCU1 | Uploading data and training models |
| UCU2 | Verifying |
| User Case | |
|---|---|
| ID | UCU1 |
| Actor | User |
| Description | Uploading data and training models |
| Main Flow | 1. Click "Upload Data" button 2. Upload audio files by file chooser or drag & drop and click "Upload" button 3. Select who is the speaker in the audio files 4. Check the checkbox about user terms and click "Start" button. |
| Result | Model of certain speaker stored |
| User Case | |
|---|---|
| ID | UCU2 |
| Actor | User |
| Description | Verifying |
| Main Flow | 1. Click "Start Verifying" button 2. Upload an audio file by file chooser or drag & drop and click "Upload" button 3. Select the speaker to be verified 4. Check the checkbox about user terms and click "Verify audio" button. |
| Result | Verification result shown |