System Architecture Diagram
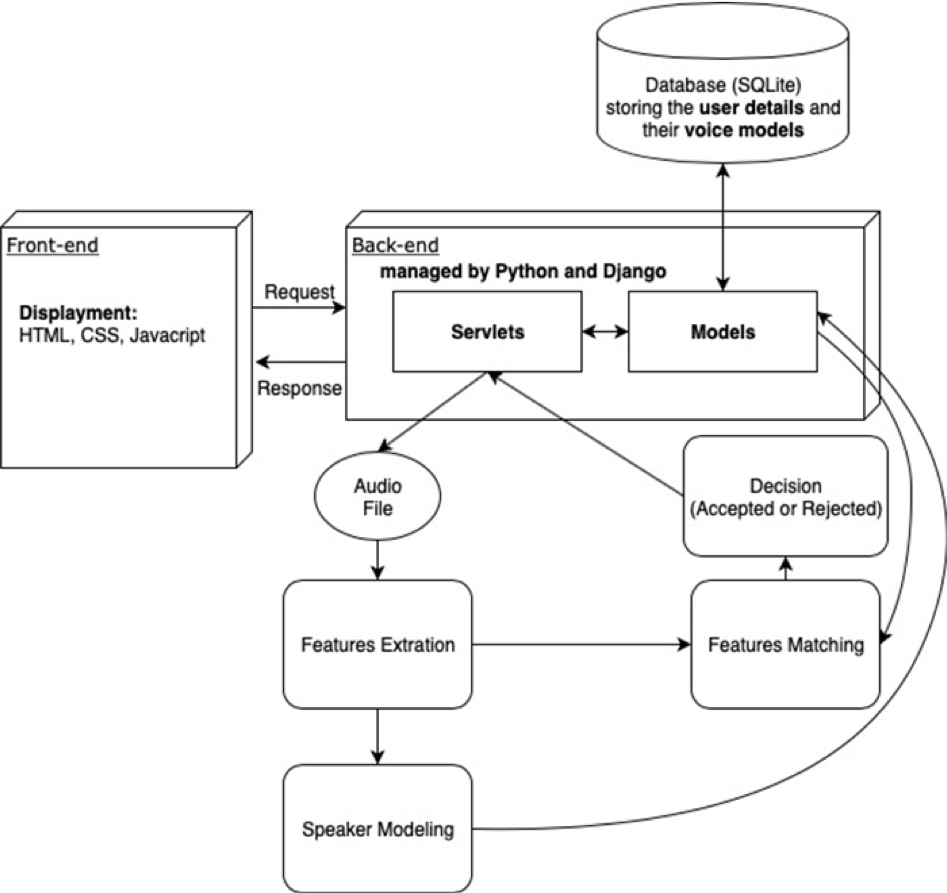
The Front-End is implemented by HTML, CSS and javaScript.
Django is in charge of handling the requests and
communicating with the database. Machine learning
techniques are used to conduct the speaker verification.
There are three main components of the algorithms,
feature extraction, speaker modeling and feature matching.
Feature extraction is used both in entering and matching
processes, where entering is to train a voice model using
as much audio as possible from one single person, whose
features are identified and extracted by some machine
learning algorithms like MFCC.
Those extracted features are represented in high-dimensional
vectors, which would be simplified in terms of dimension and
modeled using statistical model such as HMM. The result is
stored in database. Feature matching process requires specific
algorithms as well, which produces similarity between the
uploaded audio and the voice model in the database. Decision
of accepted or rejected is made according to the similarity
number generated. In the database, user details and paths to
models files are stored.
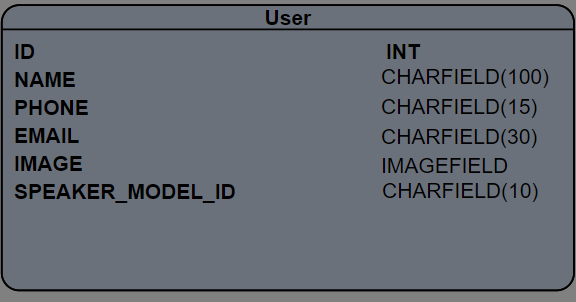
ER Diagram (Only one entity)
Implementation of Key Functionalities
1. File uploader with Drag-and-Drop support
2. Auto type convertor for any type of audio file
3. Audio Recorder (recording, replay, download and upload)
4. Data uploading for training models
5. Speaker verification using MFCC and GMM algorithms