
Tingmao Wang
Researcher, Programmer, Tester


Kaloyan Rusev
Researcher, Programmer
Victoria Xiao
Client liaison, Report Editor, UI designer
For this project, we worked with NTT DATA to build an improved version of last year's team 24 project, a lab virtual assistant. It is a set of components which together allows a user to talk to an animated avatar backed by Alexa. The existing implementation requires a large amount of setup and also looks quite plain. There is also a lack of features the assistant can do.
We build upon their code to make the assistant more engaging to interact with, more configurable, as well as improving the existing installation process and adding extra features tailored for company usage.
We hope with our changes, the project will be more accessible to companies and encourage the use of virtual assistants in a working environment.
Note: We also have a third year student—Brandon Tan—working on this project at the same time. Our team and the third year student will focus on different tasks, and we will list requirements that are not ours separately.
Researcher, Programmer, Tester
Researcher, Programmer
Client liaison, Report Editor, UI designer
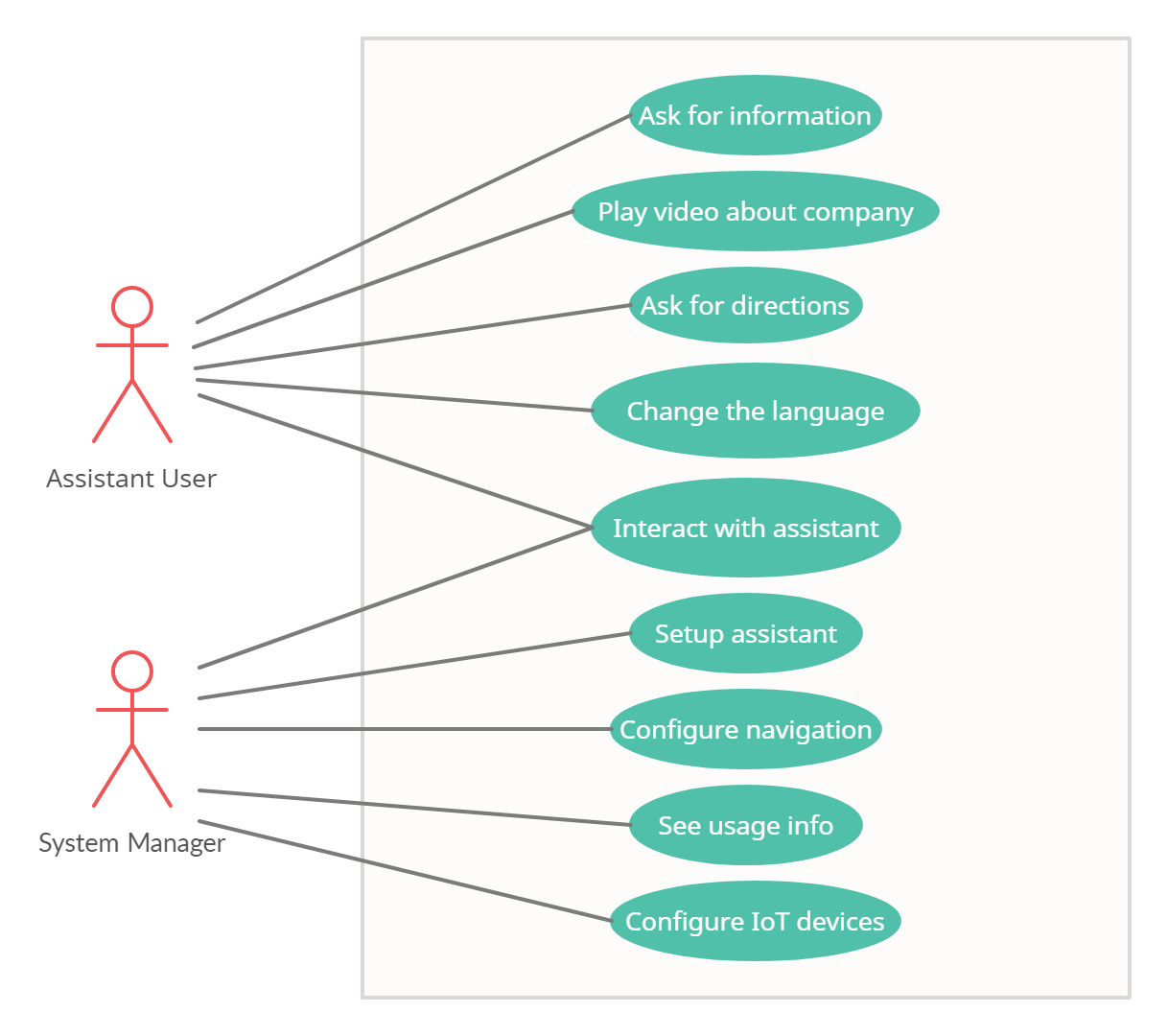
The project is about building a digital avatar that is to be displayed on a lab TV/screen. Visitors and employees in the lab can interact with the assistant via voice commands. The assistant should be able to give the user an introduction to the lab and the company, and be able to handle different queries about the lab or the company.
For example, if the company organizes a VR workshop in the lab, after being led to the lab by reception, visitors should be able to ask the assistant about what happens next, where to go, etc. and possibly also have the assistant help demonstrate some of the VR features in the lab through videos.
NTT DATA is a global IT Innovator who deliver technology enabled services to clients. They have labs which often hold workshops and demos which many people attend. Our project aims to upgrade a virtual assistant which will be deployed in their labs.
Overall our goal is to improve the existing solution. After talking to the client, we established the 3 main goals for our project. Firstly, to make the assistant easier to install by creating scripts to automatically install some components and reducing the number of components needing to be installed. Secondly, make the assistant more professional and engaging. Lastly, give the assistant the ability to perform more tasks.
In our first meeting with the client, we asked about the requirements and were given some ideas of what we could achieve throughout this project. In the following meetings, we clarified and agreed on the requirements. The client occasionally added requirements throughout the project timeline.

Peter Jensen is a technology enthusiast who is attending a workshop at NTTDATA. He uses the assistant to find out what room his workshop is in and receive directions to get there. He is happy he is able to talk with the assistant naturally.

Joseph Richardson is an employee who manages the assistant. He is not familiar with complex programming so he wants a system that is easy to set up, configure and maintain. He found the lab assistant's set up to be very straightforward.
Given the nature of our project, all requirements are functional
Currently the avatar shows an empty background. We plan to implement a feature to match the background to the current weather.
Visitors to the lab should be able to ask the assistant where to go for a certain place or event, and the assistant should be able to show a map, along with voice directions.
Currently, setting up the assistant involves the deployment of multiple components. Ideally this should be improved to a one-click install and run.
Currently the assistant only has one 3D form. We aim to be able to support using multiple models, so that the company or the user can select the 3D avatar they like the most.
Currently the assistant only supports landscape mode. The assistant must be able to adjust accordingly to both landscape and portrait monitors/TV screens.
If the user has never used the assistant before, they may be confused what they can say. The assistant should prompt the user with things to ask.
The client suggested a monitoring interface to show usage of the assistant.
This would involve making the assistant able to control building lights, etc.
One of Brandon's major requirement, to make the mouth show the correct shape when Alexa is speaking.
Also one of Brandon's area, to make the avatar able to convey appropiate emotions to the user via facial features.
This could involve the use of some loading animation
We originally attempted to make the project runnable with just one installer which automatically supports both the Unity client and the Alexa client. We researched about how to make that possible.
For example, since we use Python, we wanted to "package" our python code such that user doesn't need to have Python installed or install any pip dependencies themselves. We found PyInstaller [1] which seemed like a viable option. It packages the application along with its dependencies and Python into a standalone executable, which is easy to install and run.
However, not all dependencies will work, especially if the Python package relies on native code that needs to be compiled. There is a list of supported packages, but it doesn't include pyaudio, for example. We did not attempt to build it since we decided to go with another approach later on.
Our first idea for how the navigation feature of the assistant should work was to prompt the user, setting up the assistant, to draw the maps to each room in a GUI. However, that seemed too time consuming and annoying for them, so we decided to automate this task, so the user should only upload an image of the floor plan. We researched about any existing libraries or algorithms that can help with this task.
After thorough research we did manage to find some existing solutions. However, none of these solutions were quite suitable for our case.
The ones we found about detecting rooms in an architectural floor plan were too complex to implement in the given time slot (see [2][3]).
The other option, we came up with, was to detect just the lines and their intersections and from the results, to calculate where the rooms are. However, in this case the solutions we found (like this one and this one) were either not quite accurate (detected a line twice or not detect it at all) or required too much processing power. [4]
As a final solution, we decided to develop our own algorithm for this problem.
[1] PyInstaller. [Online]. Available: https://www.pyinstaller.org/index.html [Accessed Mar. 14, 2021]
[2] H. Locteau, S. Macé, E. Valveny and S. Tabbone, "A System to Detect Rooms in Architectural Floor Plan Images", ACM International Conference Proceeding Series, 167-174, 10.1145/1815330.1815352, 2010. [Online]. Available: https://www.researchgate.net/publication/220933144_A_System_to_Detect_Rooms_in_Architectural_Floor_Plan_Images [Accessed Feb. 2, 2021]
[3] Z. Zeng, X. Li, Y. K. Yu and C. Fu, "Deep Floor Plan Recognition Using a Multi-Task Network With Room-Boundary-Guided Attention," 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 2019, pp. 9095-9103, doi: 10.1109/ICCV.2019.00919. Available: https://openaccess.thecvf.com/content_ICCV_2019/papers/Zeng_Deep_Floor_Plan_Recognition_Using_a_Multi-Task_Network_With_Room-Boundary-Guided_ICCV_2019_paper.pdf. [Accesssed Feb. 3, 2021]
[4] OpenCV. [Online]. Available: https://opencv.org/ [Accessed Feb. 5, 2021]
The assistant has no interactable buttons to press as it is fully voice controlled. The system will register if a user has been detected but not said a voice command and will suggest commands the user can say through speech bubbles coming out of the avatar. The configuration page is simple and clear, specifying exactly where everything should be inputted.
The assistant will be able to smoothly rotate its head/body to follow the user if they move within its camera range to show the system is aware of the user's presence. When the system is processing a user's voice command, the assistant will show a thinking pose to show the user that it has heard what they said and is processing.
The only interaction possible with the assistant is through voice, the speech bubbles that appear indicates to users that they must talk to the assistant to use it.
The way the commands are triggered all require the user to start with the hot word 'Alexa'. This is consistent for all commands. The commands also generally follow the same structure, for example for navigation, the user can ask "how do I get to x place" and replace the x with whichever room their destination is.
After gathering our requirements, we created hand-drawn sketches to explore the ways we could design the interface to integrate the design principles (visibility, feedback, affordance, consistency). Originally, we had 2 sets of sketches. After some user feedback, we decided to use these as our final sketches.
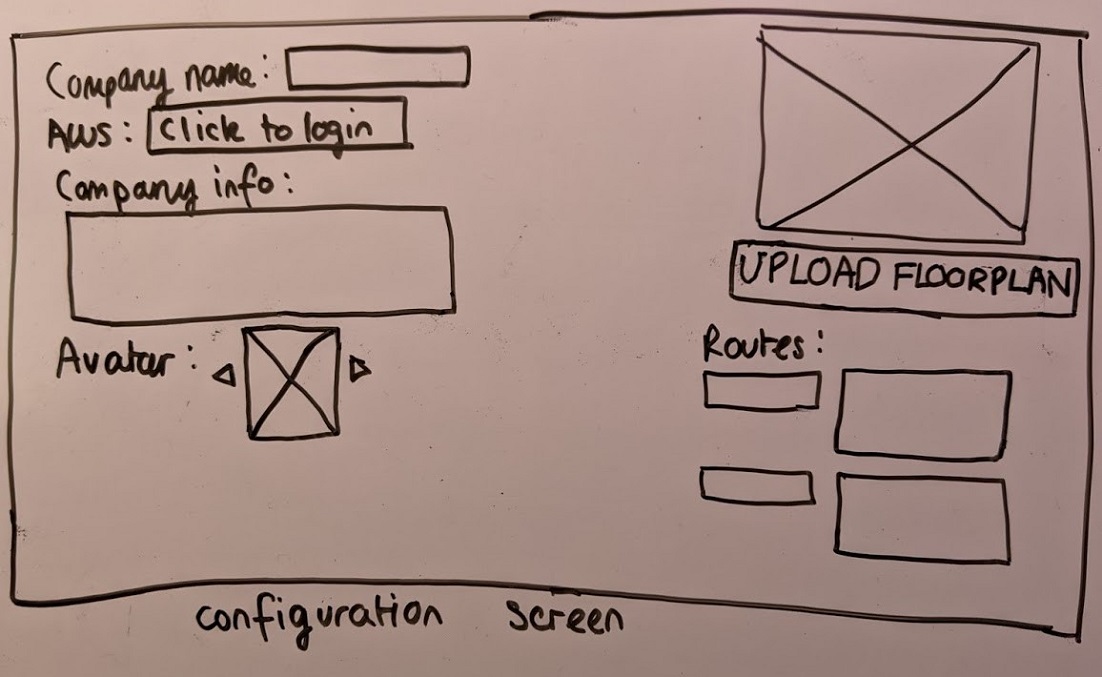

Using Balsamiq Cloud, we created an interactive prototype to show our design ideas and the interaction between the assistant and the user, here is the video. The speech bubbles represent voice commands from the user. (Note: the info button on the config page was added after the prototype evaluation)

We used an analytic evaluation by evaluating our prototype through heuristics.
| Location | Heuristic | Problem | Solution | Severity |
|---|---|---|---|---|
| Configuration page | Help and documentation | There is no guidance on how to setup the configuration page. | Create a help popup in the configuration page | 3 |
| Location | Visibility of system status | Once a voice command is inputted, there is no indication if the system is taking a while to respond or if it has crashed. | Have an animated thought bubble above avatar to represent that system is processing. | 2 |
| Location | Recognition rather than recall | User may forget how to activate or ask for some specific things from the assistant. | Display suggested questions if a user is detected but there is no input. | 2 |
Preece, J., Sharp, H., & Rogers, Y. (2019). Interaction design: beyond human-computer interaction, Wiley, 5th Edition Section 1.7.3
The decision to use Alexa is made by the previous year's student and we decided to build upon that. The system architecture had gone through some modification in order to simplify the use of our system.

As seen above, this project contains 3 separate but connected components, which together supports our Alexa integration. Essentially, user's queries are listened and sent by the Alexa client to the Alexa voice service to be processed by Amazon. If the user uses our skill, the Alexa voice service will send requests over https to our skill server, which will process the request and send the text response back to Alexa. It would also send control messages to the Unity front-end (which is the "UI" of this system) to facilitate video playing, lip sync, navigation, etc.
Unlike previously, the Alexa client now also runs on Windows, which means that running a Linux virtual machine on the client's Windows screen is no longer necessary. The Alexa client can run on the same operating system as the unity front-end.
The skill server is a Flask (Python) http(s) server. We used a "HTTP polling" approach (due to websocket library not working properly) for sending messages to Unity. Unity will periodically request /msg, and the server will return the current state, which consists of what the current response is, whether Unity should play video, etc. as well as the timestamp of when the state was updated last.
For the Alexa client, we pulled the source of the official C++ Alexa client and slightly modified it to suit our system:
To communicate with Unity, we also wrote a Python script which is supposed to be run alongside the client, which starts up a local http server and use the same polling approach used in the skill server to let Unity get messages from it.
The official Alexa client does not contain hot word detection (recognizing when the user calls "Alexa" and hence start listening for query), so this is implemented by using an third-party library in the python script, and asking Alexa to start listening when we detected user saying "Alexa".
Finally, the Unity client uses basic C# code to talk with the two components above via HTTP(S).
After not being able to find a suitable existing solution for how to detect rooms on a floor plan, we developed our own. Here is how it works:
With this algorithm, heart-shaped rooms are detected as two rooms, instead of only one. To fix this, we added a loop that iterates through all the rooms and fixes these problems. If 2 rooms contain lines that are next to each other and the ranges of white pixels have at least one pixel in common the 2 rooms are combined into 1. The loop continues until it iterates consecutively through all the remaining rooms without having to combine any 2 of them.
[1] For fast checking which room a pixel belongs to, an array with length h*w is created (h-height of the picture, w-width of the picture) to store which room is each pixel assigned to. Pixel (x, y) would be indexed (y*h + x) in the array and it can easily be checked which room is it assigned to. When a range of white pixels and the room it belongs to are found, each element in the array, corresponding to a pixel in the range is updated with the room that is found.
To fully automate the set up for the navigation feature, after detecting where the rooms are, we needed to also get the best route to them. Here is how it is done:
To simplify skill server setup, we wrote a completely automated configuration script, which will build a Docker container with all the dependencies, get certificates from Let's Encrypt, and setup systemd services which will start the skill server on boot and allow it to run in background, removing the need for user to run "screen" themselves.
To simplify the client installation (Unity front-end and Alexa client), we pre-compiled everything that we can and packaged them as zip files, and linked to those packages in our user manual. This means that user doesn't need to have Unity installed, and they wouldn't need to wait for the Alexa client to compile either.
Configuration for the Unity front-end are read from a JSON file. We wrote a html page to generate such JSON file with a UI for some configuration changes, so that user doesn't need to manually modify JSON themselves.
For this task, we created a very Simple GUI where the user should just upload a picture of a floor plan and enter the names to each room.
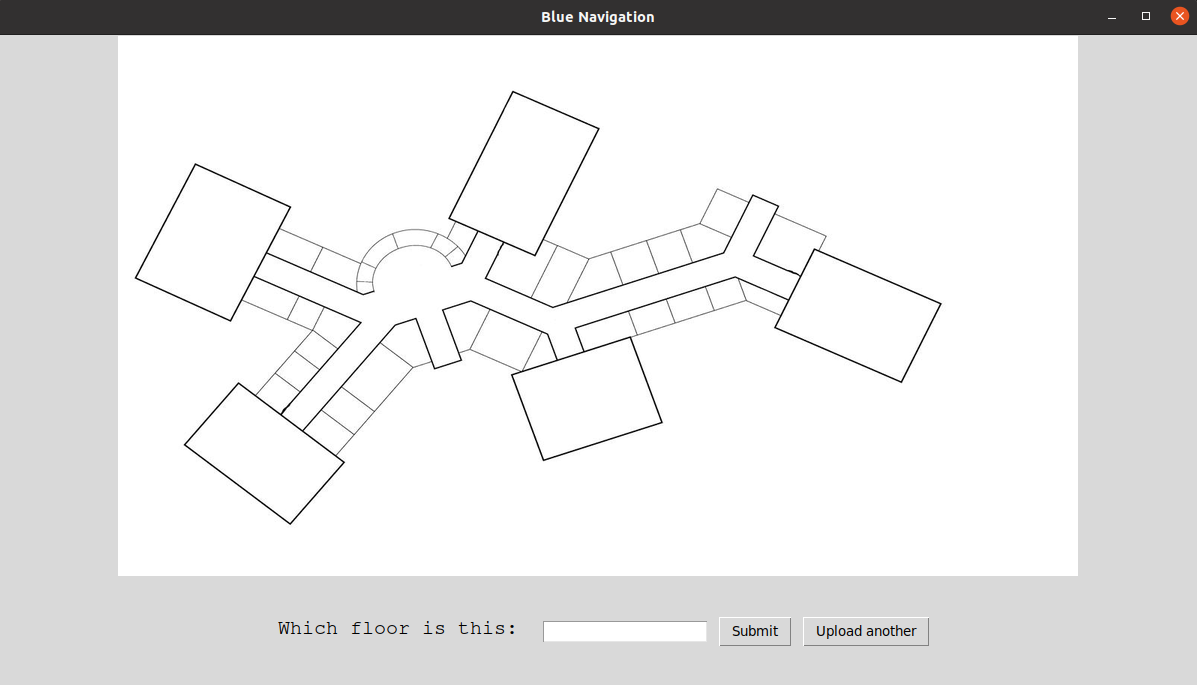
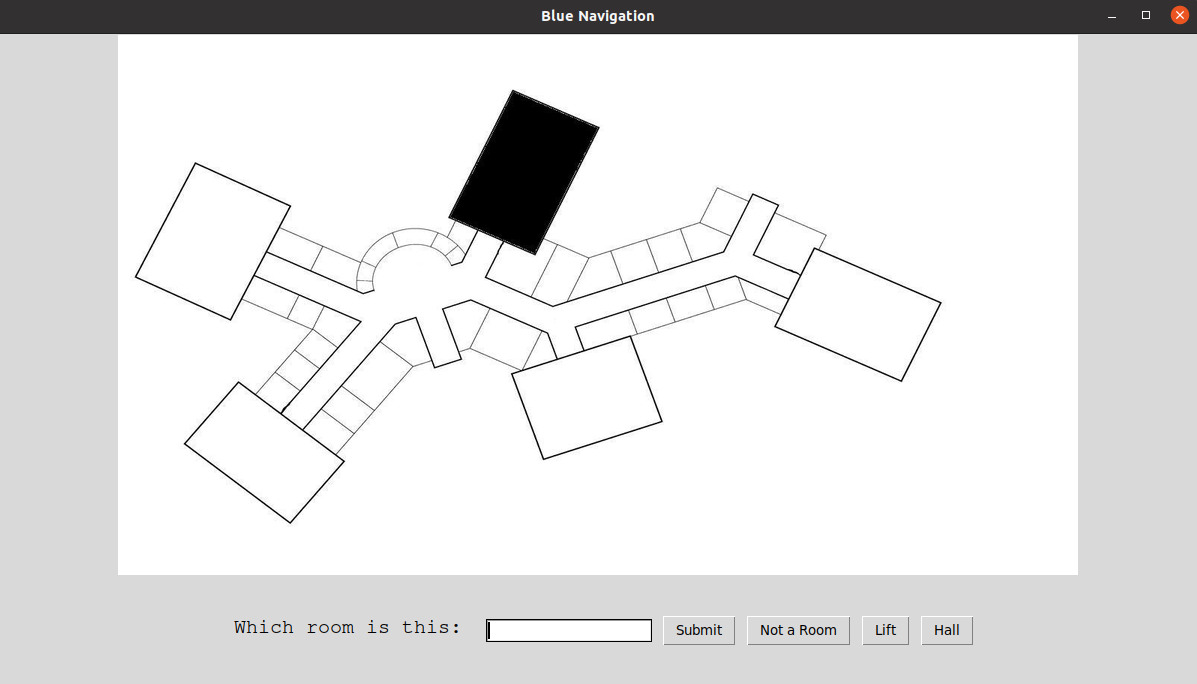
One of our requirements was to improve the background. The client suggested a background that shows a different weather state depending on the real time weather.
The implementation of this mainly involves Unity scripts and calling a Weather API to receive information about the live weather. There is a coroutine in weatherControl.cs which calls the weather api using UnityWebRequests. Then using SimpleJSON to parse the JSON from the API, the system knows the weather.
There are many different weather states so the script groups them into 4 states: Clear, Clouds, Rain and Snow. Clouds, Rain and Snow share the same skybox of a cloudy background. Rain and Snow use particle systems to create their visual effects. Clear uses its own skybox with a clear sky.
The main Update() method of the script calls the coroutine every 10 minutes since the API is limited to 60 calls per minute and 1,000,000 calls per month.
The face tracking involves usage of a library called OpenCV plus Unity. The implementation of this library is the same as last year's team, linked here. To repeat, the user's face is detected using a webcam. The webcam view is split into 7 sections (columns). The user's face is located in 1 of the 7 sections and this value is returned from the script. The value is then used to control the assistant's rotation.
The player script works as follows: the script gets the value of the avatar's rotation and converts it to an integer. If this value is greater than 180, it means the avatar has rotated in the negative direction (since the rotation values Unity scripts receive are never negative) so 360 will need to be subtracted from the rotation value. If the value received from the face tracking script is not the same value as the angle of the avatar (they are set to map equally to each other), then the head and/or the body will keep rotating until it reaches the same value.
To ensure reliability, we wrote automated unit tests for the skill using our test Alexa client and a Unity unit test which uses the Unity test runner.
Given the nature of our project, user acceptance testing was very important. At the request of our client, we showed them our project every 2 weeks. Rather than only showing them the program all the way at the end, we had liaised with them regularly to conduct User Acceptance Testing. This allowed us to receive continuous feedback from our client and accommodate for any changes that they require, whether it may be incorrect outputs or the system simply not working.
| ID | Requirement | Priority | State | Contributors |
|---|---|---|---|---|
| 1 | Improved Background | Must | ✓ | Victoria |
| 2 | Navigation System | Must | ✓ | Kaloyan |
| 3 | Simplify Installation | Must | ✓ | Tingmao |
| 4 | Configurable 3D model | Must | ✓ | Tingmao |
| 5 | Portrait Mode Support | Must | ✓ | Victoria, Tingmao |
| 6 | Menu Screen | Must | ✓ | Kaloyan |
| 7 | Add branding | Should | ✓ | Victoria |
| 8 | Improved Face Tracking | Should | ✓ | Victoria |
| 9 | Improved Video Player | Should | ✓ | Tingmao |
| 10 | Reporting | Should | X | |
| 11 | IoT Integration | Could | X | |
| 12 | Change Language | Could | X | |
| Key Functionalities (must have and should have) | 90% completed | |||
| Optional Functionalities (could have) | 0% completed | |||
| ID | Bug Description | Priority |
|---|---|---|
| 1 | Alexa client is not always able to maintain sessions, causing users to need to say "Open Blue Assistant" again or "Ask Blue Assistant …" all the time | High |
| 2 | Alexa client is often unable to recognise asking for navigation directions (although the test client can) | High |
| 3 | Alexa may sometimes mishear the user | Low |
| 4 | Face detection often fails if the lighting where the user's face is located is too dark | Low |
| 5 | Face detection often glitches when there is more than 1 face detected | Low |
| Work packages | Tingmao | Kaloyan | Victoria |
|---|---|---|---|
| Client liaison | 30% | 30% | 40% |
| Requirement analysis | 33% | 33% | 34% |
| Research | 30% | 50% | 20% |
| UI design | 10% | 40% | 50% |
| Programming | 55% | 30% | 15% |
| Testing | 100% | 0% | 0% |
| Development Blog | 34% | 33% | 33% |
| Report Website Editing | 40% | 20% | 40% |
| Video Editing | 0% | 0% | 100% |
| Overall Contribution | 34% | 33% | 33% |
| Main Roles | Backend developer, Tester, Researcher | Frontend developer, Researcher | Frontend developer, UI designer, Report editor |
The interface is simple and since there is no need for any GUI, the main focus is to signal to the user that the system is voice controlled which has been completed through the speech bubbles appearing. When a video plays, the avatar moves to the side and is still in view from the user.
The main project goals have been achieved and the new functionalities we implemented are all working. The user can ask the assistant for directions, company info etc and the installation of the project onto a company's device has been greatly simplified. Although, if the hardware is not great, the Alexa client can struggle to pick up the user saying 'Alexa' or mishear their commands.
The back end of the assistant is run on Amazon's Alexa Voice Service which is used widely across the world so it is considerably stable. Although a poor internet connection may result in slower responses. We have removed the need to run a Linux virtual machine which improves the overall stability of the project. Hardware may also impact the project - poorer system hardware may cause the project to function poorly.
The face tracking feature does not work on Linux machines so the Unity front end should be ideally run on Windows (we have not tested MacOS but in principle it should work). The Alexa Client can be run on Linux (it is actually designed to be run on Linux), we have used mingw to allow it to run on Windows so it can be run on the same machine as the Unity front end without the need of a vm. The skill server can in principle be run on Windows but we did not test or investigate this.
The project has been documented with our user manual to assist with setting up and maintaining the project. The project can easily be extended to implement more features - with Amazon intents, the developer simply needs to add it to the Alexa skill and create a python file in the 'handled_intents' folder with the intent name.
The project was managed fairly well. We used 'Plan' in Microsoft Teams with an Agile method. The team would meet with the client on a fortnightly basis and the client would assign each team member a new sprint for the next 2 weeks. In the meetings, we would be able to do live demos and receive live feedback on the project. Since we also had a 3rd year student working on the project, the team kept in frequent contact with him through Teams.
The lip synchronisation is still not perfect, it assumes that each syllable takes the same amount of time so sometimes, the assistant’s lip synchronisation becomes quite out of sync with the voice output. If there was more time, this could be improved.
The project could be developed to move off Alexa which would allow for more control over the assistant – such as having a custom hotword and not requiring the user to open our skill to use the custom voice commands. The hotword detection is also slightly inconsistent, sometimes requiring the user to say ‘Alexa’ more than once for it to trigger but with a custom made voice controlled client, this can be more tailored. We could train a custom hot word detection.
Although we have simplified the installation, it could still be further simplified – our current solution still requires the user to install some dependencies such as Python, Java and msys2. Perhaps an installer could be created for the project to automatically carry out the steps documented in the user manual.
The software is an early proof of concept for development purposes and should not be used as-is in a live environment without further redevelopment and/or testing. No warranty is given and no real data or personally identifiable data should be stored. Usage and its liabilities are your own.
See a list of open source libraries & assets used
For ease of development, this project provides pre-compiled binaries made with Unity, usage of which are subject to restrictions in the Unity Software Additional Terms. This is not legal advice.