
SYSTEM DESIGN
- Home
- System design
System Architecture
The architecture of the sampling tool can be divided into two main components, the frontend and the backend. Although, we could have kept them in one place, for example by setting up a “single page application”with React and Django tightly coupled, we decided to separate them. This decision was made because we wanted our Sampling API to be as modular as possible. The frontend we developed is one way of implementing the Sampling API, but it is certainly not the only one. By keeping the frontend and the backend separated with polyrepos we essentially developed two different but compatible applications.
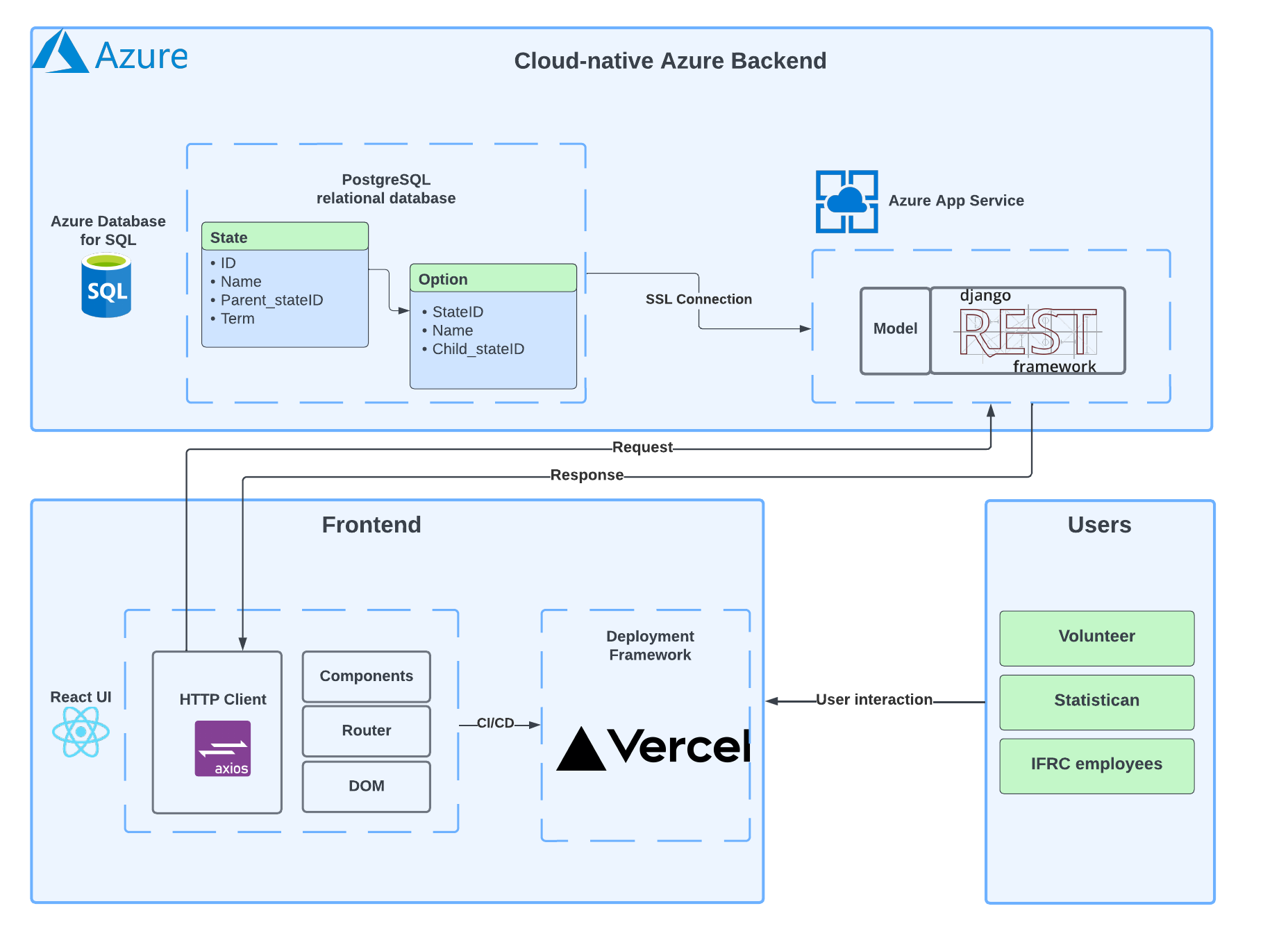
The backend is a fully cloud-native application deployed to Azure. After agreeing on our technology stack we started setting up our development environment on Azure. First, we initialised our Django REST framework on Azure App Services and connected it to our database that resides on Azure PostgreSQL Server with a simple SSL connection. The database is serialized using Django and is then linked to the REST framework via Django Models. The database itself consists of two tables and store the states of our decision tree. These are used to construct the decision tree on the frontend. When an API call is made the Django model of the database Finally, we deployed our application to https://ifrc-sampling.azurewebsites.net/api/ to be able to establish communication with the frontend.
The frontend does not utilise any component or UI framework like Material UI, so setting up the environment was fairly simple. We initialised our React application and configured SCSS for styling and TypeScript for the frontend application logic. We established the connection with the API using the promise-based Axios HTTP library. Once on Github, we set up a continuous integration (CI) pipeline using Vercel that provides preview as well as production builds. Meaning we could quickly test out our changes on a preview deployment and only merge with production if it has passed every test.
Database ER Diagram
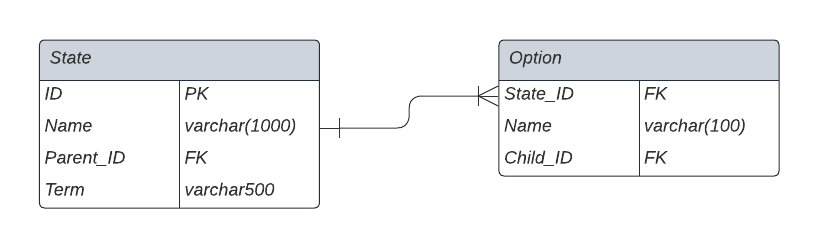
The ER digram above shows the different tables and their relationship in our database. The State table stores the questions (i.e., states) of the decision tree that’s implemented on the frontend. This decision tree is the foundation of the entire sampling tool and is set up in a way such that it is easy to extend. As of now, there are only around 15 states in the database but this can be extended to hundreds if the IFRC wishes to introduce more complexity to the tool. The State table is then associated with the Option table which stores the possible options (i.e., answers) to a given question. A state can have more than two options and options have specific children (i.e., Child_ID) that define the path the user is taking in the decision tree.
Calculators UML Diagram
The future of our project involves other developers (i.e., IFRC GO development team) to extend and embed our sampling tool. To provide as much support as possible to the GO team we put emphasis on code documentation and the application of sound design principles. One of the key principles we applied on the backend was abstraction and the inheritance relationship between Python classes. The initial idea was to set up a class called Calculator to act as a parent to the sampling calculator. However, while developing, we realised that all four sampling calculator types fundamentally rely on the simple random sampling approach. Namely, the SimpleRandom class has four instance variables, margin of error, population, confidence level and non-response rate, and various helper and getter functions that are shared across the four calculator classes. The UML diagram visualises these commonalities and relationships between classes and acts as an accurate specification for new developers on the project.
