SHA-256
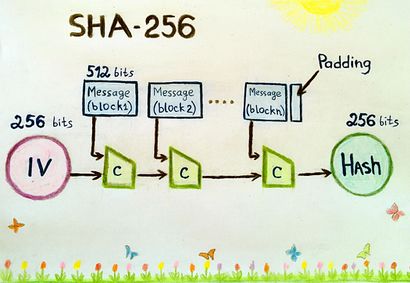 |
We are planning to use SHA-256 hashing to create the hash stored in our blockchain. This is because it is one of the most secure hashing algorithms available presently. What makes SHA-256 unique compared to other hashing algorithms is that it is classified as a 'one-way' hashing function - this means that anyone can produce an output when you provide an input to the algorithm, but it is impossible to do the reverse, meaning that the input is totally secure. It is also collision-resistant, which means that it is impossible for the same hash to be produced |
As we are using the download link of the blob storage directly, we need to ensure the uniqueness of the file name otherwise, it may lead to problems. Our solution was to hash the file name before uploading to the blob storage, this way we will know that the file name is always unique. We first receive the form from the front-end application and pass the name of the file into a helper function called getBlobName() [Figure 1.1]. getBlobName() is where the actual hashing of the filename occurs, we first generate a randomly generated value and prepend that to the original file name. We did this just in case users uploaded two files of the same name, adding a random identifier will further ensure uniqueness of the file name even before hashing. The returned value from getBlobName() will be the hashed string containing the generated value and the file name. As the files that will usually be upload are CAD files, hashing the contents of the file would prove to be difficult. However, we actually had an idea to hash the streams converted from the buffers of the file to push the uniqueness of the hash but due to the time constraints, we were unable to implement this idea further and had to settle for the current hashing method we utilize.
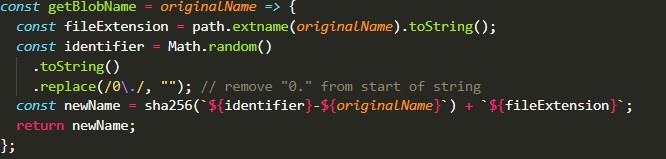
[Figure 1.1] getBlobName returns a string containing the hash of the identifier and file name with the file extension appended to the hash.