Frontend
Uploading and reading the file
In order to upload the file , we implemented two options either dragging or dropping the file or uploading
using the file explorer . To get the Frontend working , we used another extension in flask - dropzone.
This essentially highlights a certain area where you can drop files. We used the dropzone extension to
implement This feature. We specified the upload path, max size of files at the start. The dropzone
initialisation code is added in the html page.
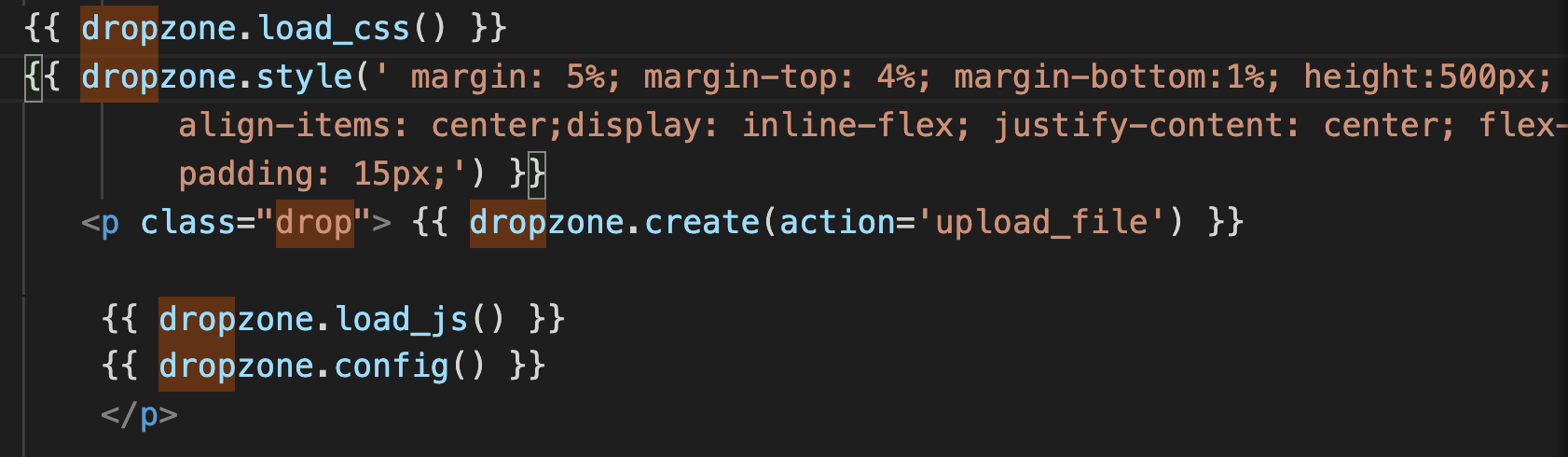
We specify the styles used by dropzone using dropzone.styles and load_css. Similarly, in order to
create and config - enter the url for the next point is done by dropzone.create (action="the url for the
next endpoint") + dropzone.config. The endpoint is the upload_file function which renders the home page.
The file name is obtained by "request.files[file]" as request.Files is a dictionary with multiple values
of uploaded content which is then used to save the file in the UPLOAD_FILE directory (path is specified at
the start). Next part of the code is responsible reading the file and returning an abstract or the content
of a file in one variable.
There is another fucntion readFile, which takes in the name of the file and bits in
returns the content of the file as one string which is then used in the code later.
Moving variables around ( from one page to the other )
In our project we only need the abstract to be read manually. In the code, we
declared an empty dictionary at the start.

The dictionary stores all the abstract under abs key value.
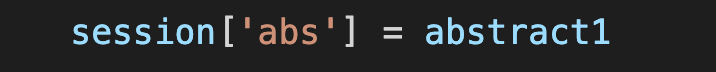
In order to use the abstract in other functions we stored it in a dictionary which can be accessed
by entering the key value.

Text boxes and user inputs
The user has to enter the title of the article in the textbox and can choose the model they want a prediction from, using the dropdown box.
All of these elements are included in a HTML form. The HTML forms enctype is equal to multi form data, so that we can get the
data entered by the users from the components in Flask. The action attribute of the form is set to the analysis function
which calls the next page.
Each component has a unique class name, ID and name, which is used to store the value, for use, in other functions.
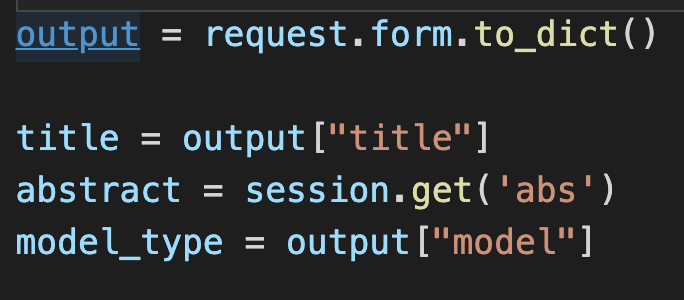
In the analysis function, we can access the title and the model chosen by the user using the code above. The values entered
by the user are saved in a dictionary which is retrieved by calling request.form.toDict(), which gets all the inputs from the form.
This makes it easier to retrieve each value based on key. For example, to get the
title of the article entered by the user, it can be retrieved by searching for the key (name attribute value of the textbox) in
the dictionary. The code for the following is shown below. *Form section has the code for the textbox and
flask section has the python code.
Form: flask:
flask: 
Search bar (Feature)
Backend
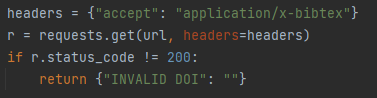
From the search bar, users are allowed to enter a DOI (Digital Object Identifier) which is unique for each paper and get metadata about the paper. This is done by making an API call to https://dx.doi.org with the appropriate DOI. The information is parsed into a dictionary as key/value pairs.
If the response is not HTTP Status 200 OK, it means the request has failed and we replace the key/value pairs with just a "INVALID DOI" key, "" value pair.
Frontend
To display the information from the search page dynamically, we needed to use embedded python supported by flaskr
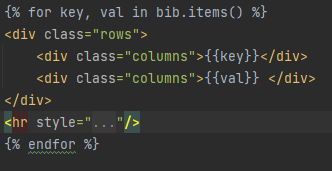
Here, we used a for loop to iterate through all items in the dictionary and display them in rows. Each row would have two columns, one for the key and one for the value. Using this to display the contents of the dictionary is one of the reasons why we chose to handle a non-200 response from the API as a "INVALID DOI" key/value pair - there is no extra work that needs to be done to handle this scenario.
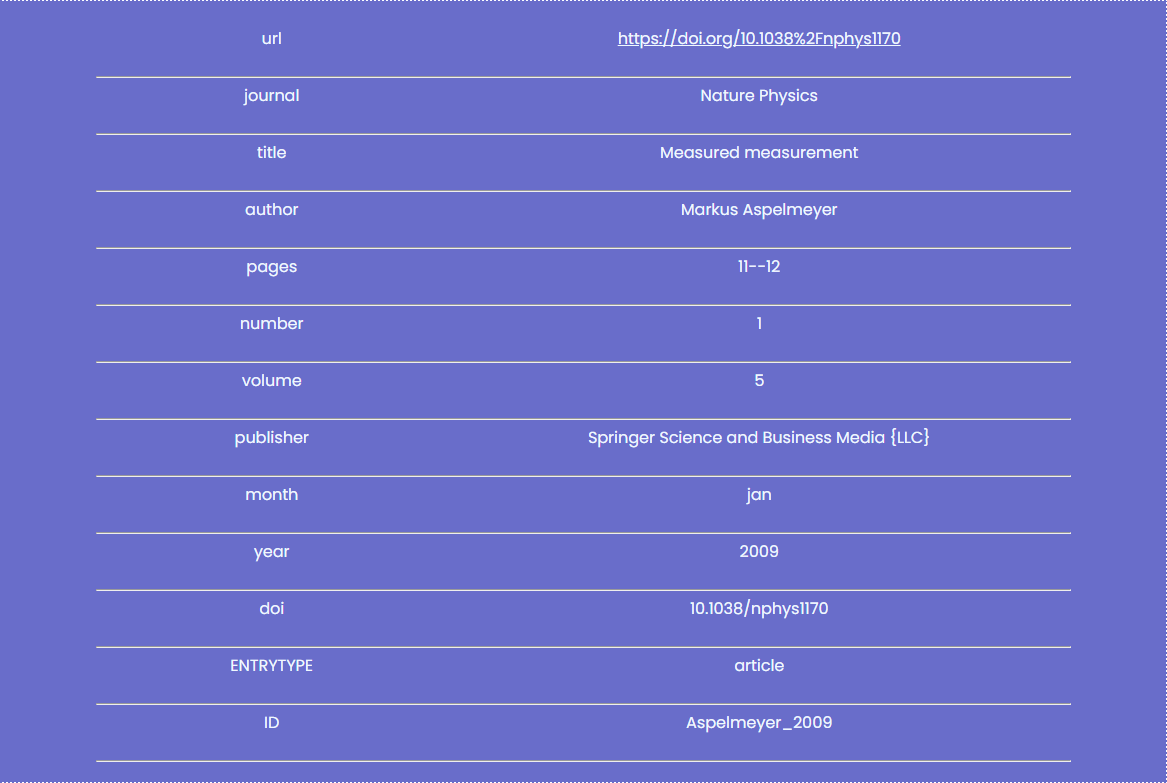
This is the result of the embedded python, and how it will look like to the user.
Backend (Citation prediction)
Tokenizer and model
Firstly, the text needs to be processed by an AllenAI SPECTER model. We utilise the transformers library to obtain the appropriate tokenizer and model. It is key to recognise that in this function, no such processing occurs. It is simply the function that initialises the tokenizer and model.

The AutoTokenizer and Automodel methods are part of the transformers library.
SPECTER vectors
A function is written to obtain the SPECTER vectors. It takes as input the tokenizer and model, as well as the title and abstract. Then, it processes these text and obtains the embeddings from the inputs. The tokenizer is used to preprocess the input into a usable result for the model. Once the inputs are run through the model, we extract the embeddings from it.
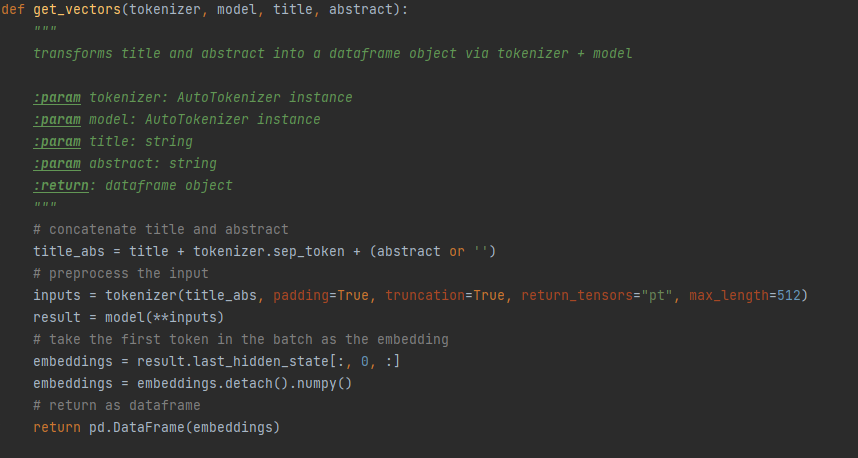
To work with this data easier, we chose to convert the embeddings into a pandas Dataframe object.
Unpacking models
It is not feasible (or realistic) to have a model that is loaded on demand, therefore we choose to pre-train our models and pickle them, then unpack them when the web application starts up.
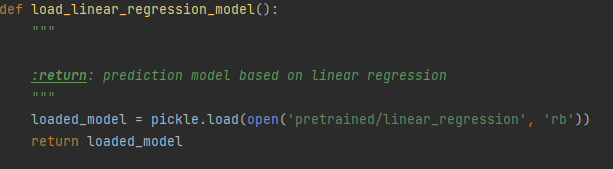
This above function is an example of loading a model, specifically it loads the linear regression model.
Predicting the citation count
With the prior work done, the actual prediction of the citation count is relatively straightforward. It takes as input a model as well as the title and abstract, and obtains a prediction from the model's predict() function.
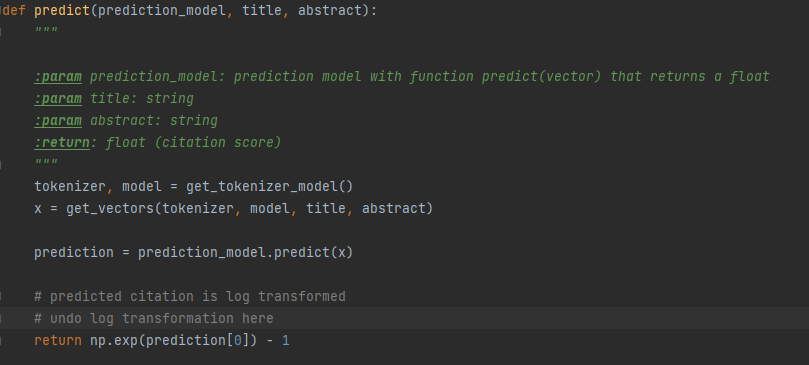
Since our models are log transformed, the initial output is also log transformed. Therefore we need to process the data by applying the natural exponential and then subtracting one from it.