Description
After merging data records to common categorizations, and clearing the data of obvious errors, to avoid potential reporting bias and other errors, a slicing algorithm was applied to cut out the less reliable part.
Observation
By going through the data distribution plots, we have the following observations:
- The number of data records varies from country to country, sometimes by orders of magnitude.
- The distribution of records are not even through time.
Examples:
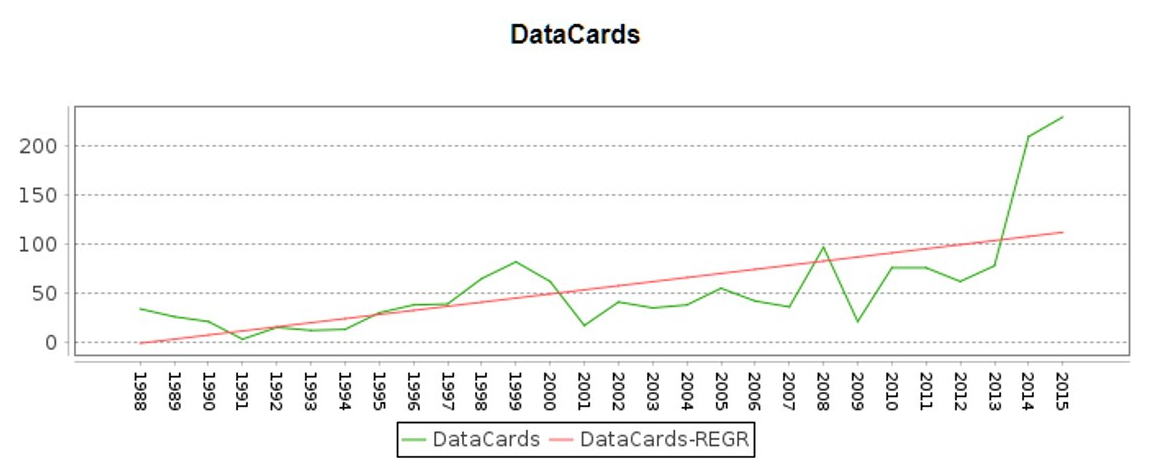
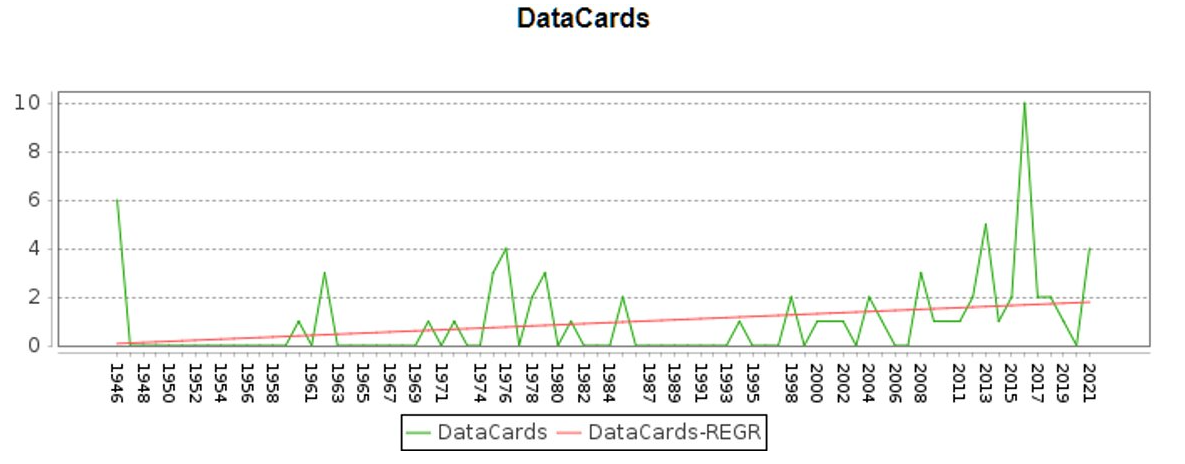
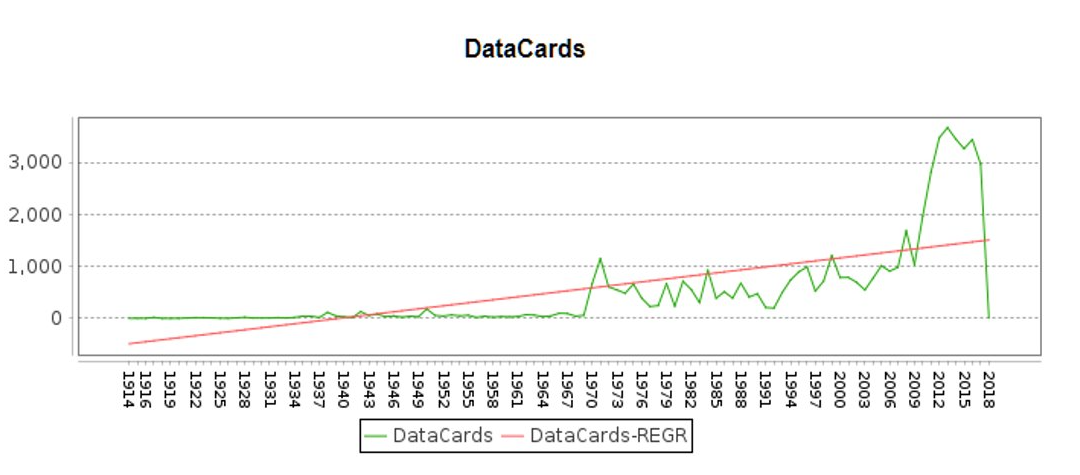
Assumption
The slicing algorithm is designed based on the following assumptions:
- The reliability and accuracy of every country increase through time.
- Hazards tend to be more frequently due to the global warming and climate change.
Algorithms
This algorithm monitors the gradient of the data records-time graph for every set of data, and cuts off the parts with abnormal gradients.
Evaluation
Hard to define abnormal threshold. May violate assumption one. Therefore it is not deployed.
This algorithm intends to skip suspicious parts by cutting off the first 5% records for each merged event and can be represented by the following equation:
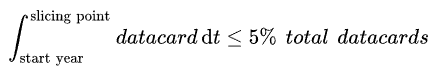
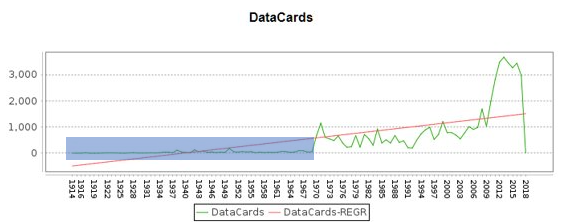
Fig.1. The first 5% records (in blue) were discarded
Evaluation
Not flexible and for data with trustful shape may reduce sample size. Ignore the content of the record, for countries including Saint Vincent and the Grenadines, the record of fatalities and affected people remains to be zero for all 10 records. This leads us to the third algorithm.
This algorithm is the extension of algorithm integration and intends to only keep the last 15 years’ record after the 21st century.
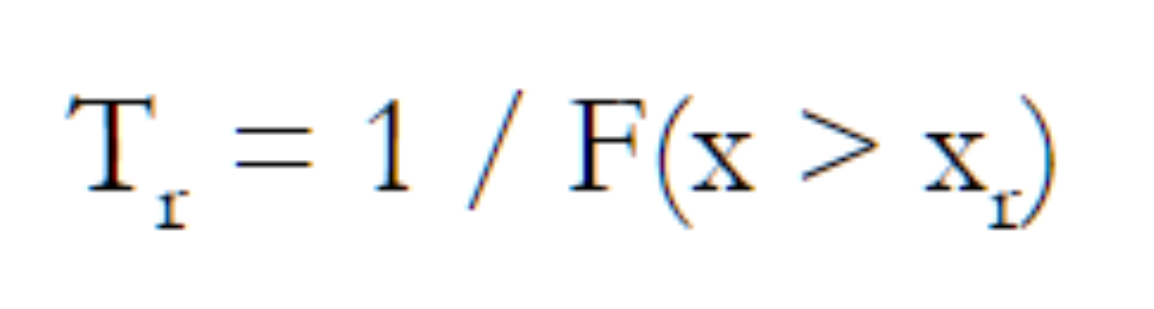 (1.1)
(1.1)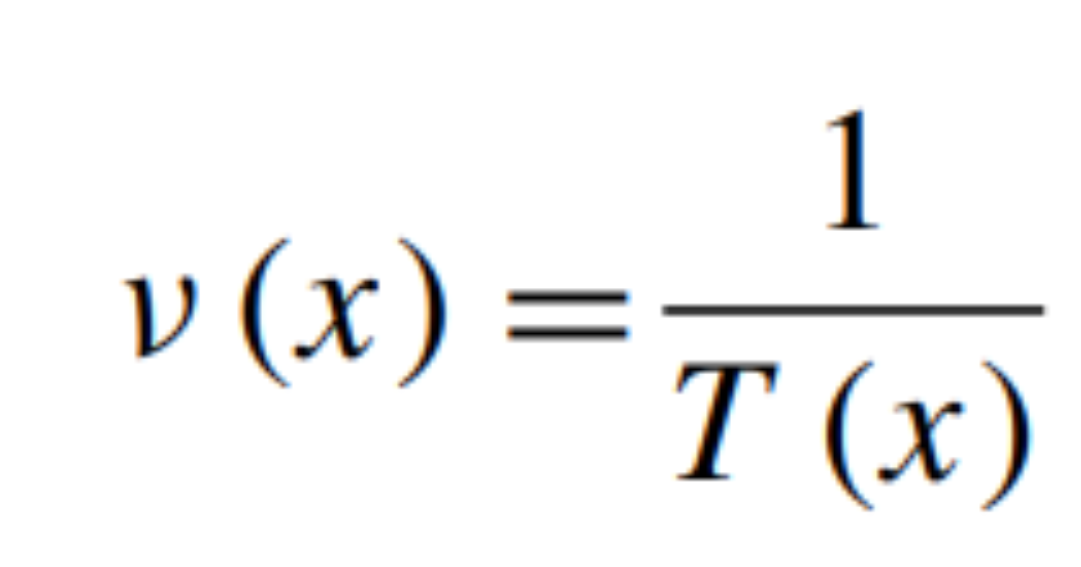 (1.2)
(1.2)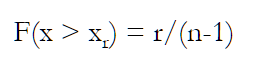 (1.3)
(1.3)