The system is composed of three distinct components: the Data Downloader, Data Processor, and Data Visualizer.
The primary function of the Data Downloader is to acquire datasets from DesInventar and convert them to CSV format if they are in XML. Following the download process, the filenames of all sub-type files are stored in separate text files for future reference. For example, ‘flash flood.csv’ will be stored in ‘flood.txt’ as one line of texts.
Data Processor is responsible for cleaning, aggregating/merging, and slicing datasets to shape our data for visualisation.
Data Visualizer generates loss exceedance curves with significant points marked and corresponding loss exceedance tables.
Data refers to datasets downloaded from DesInventar, stored under the folder named 'data', see Data Storage section for more information.
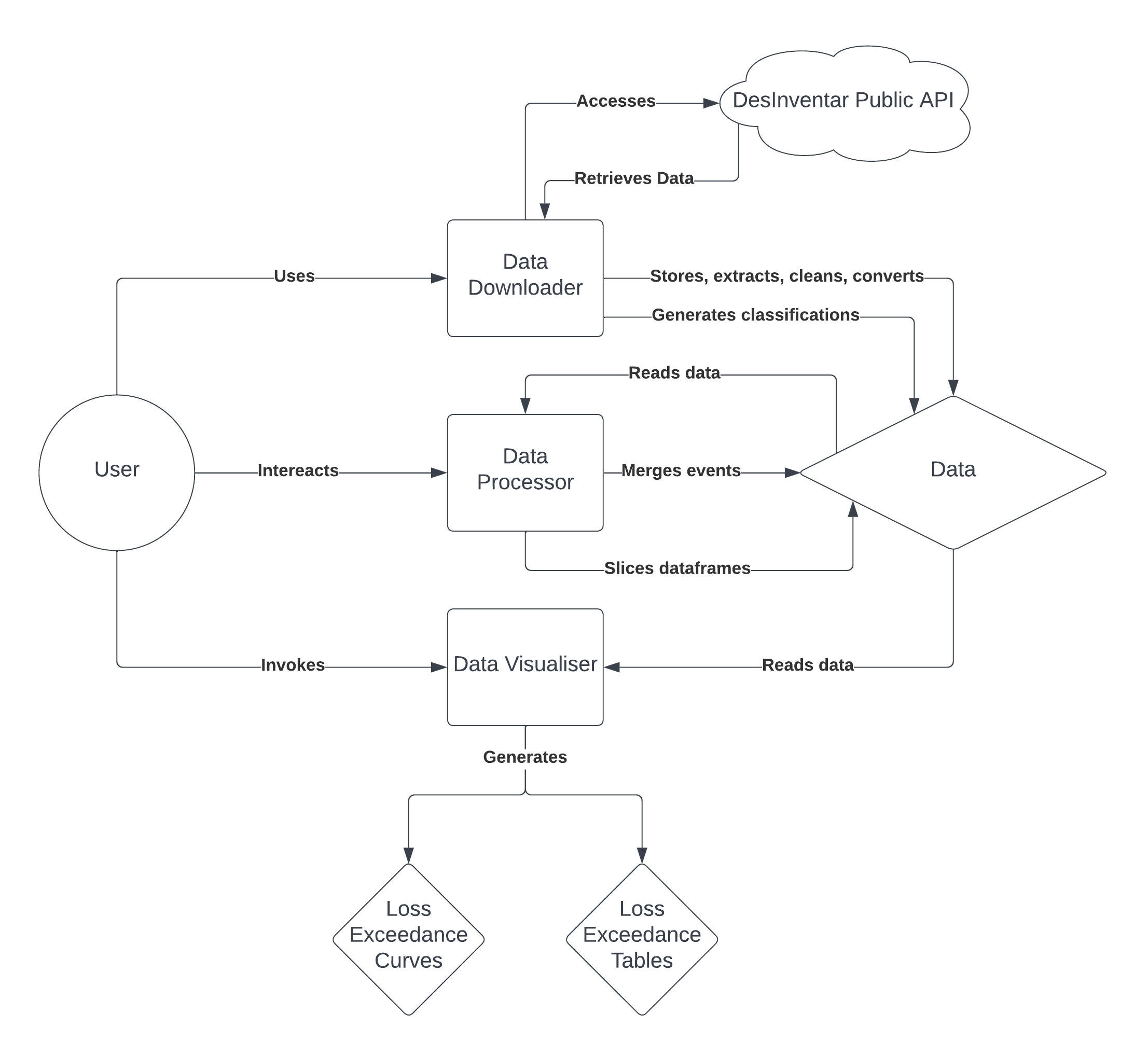

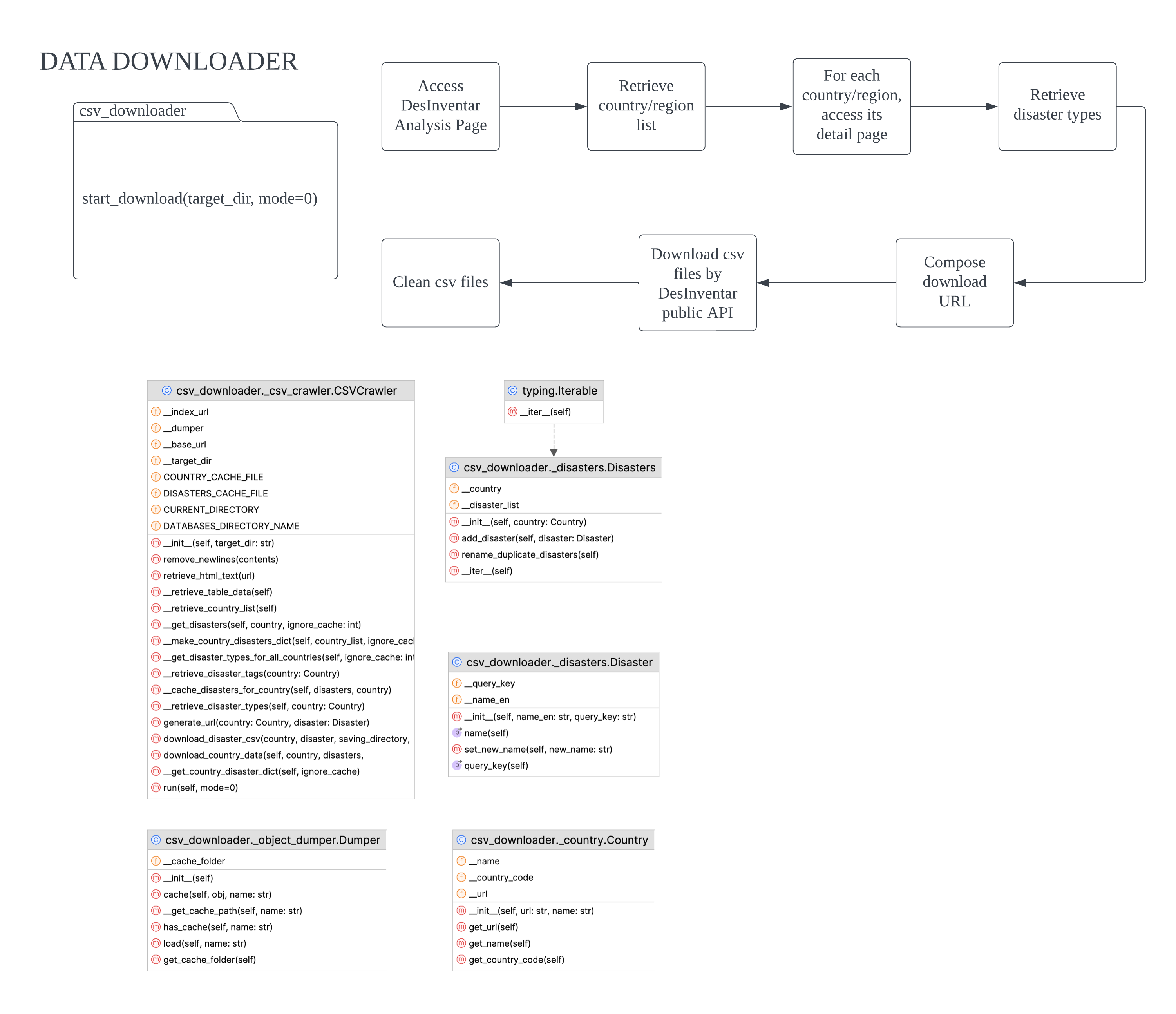
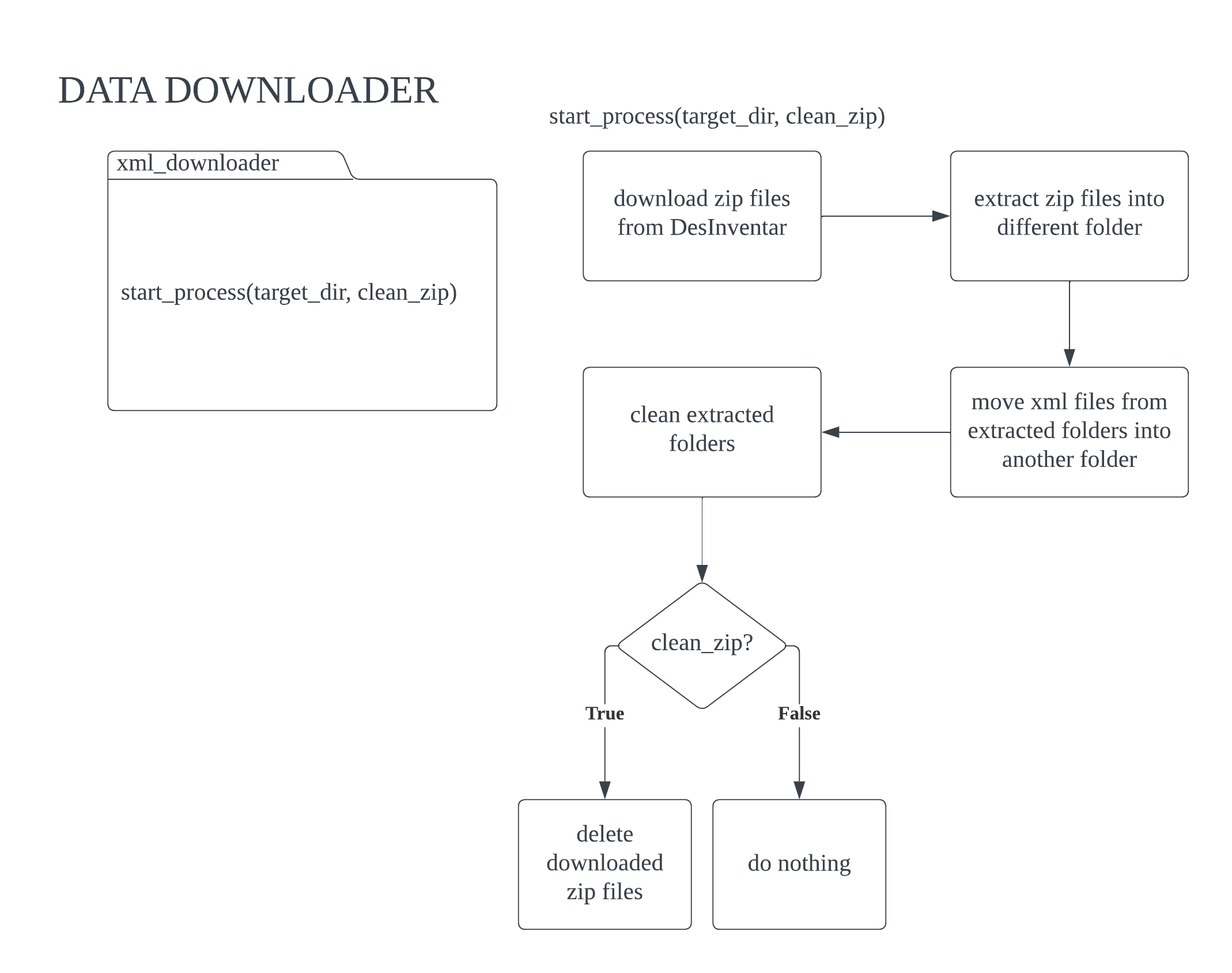

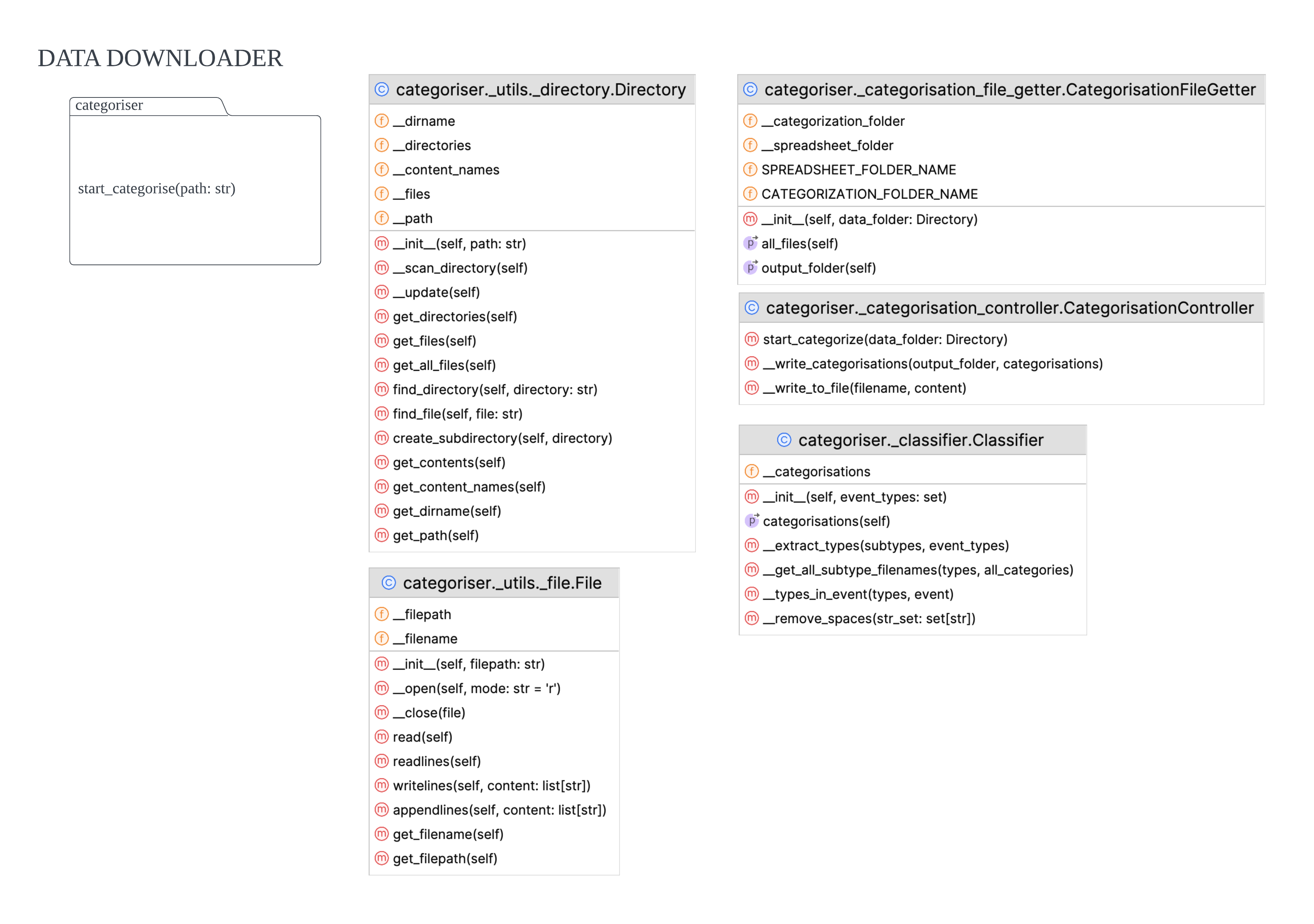


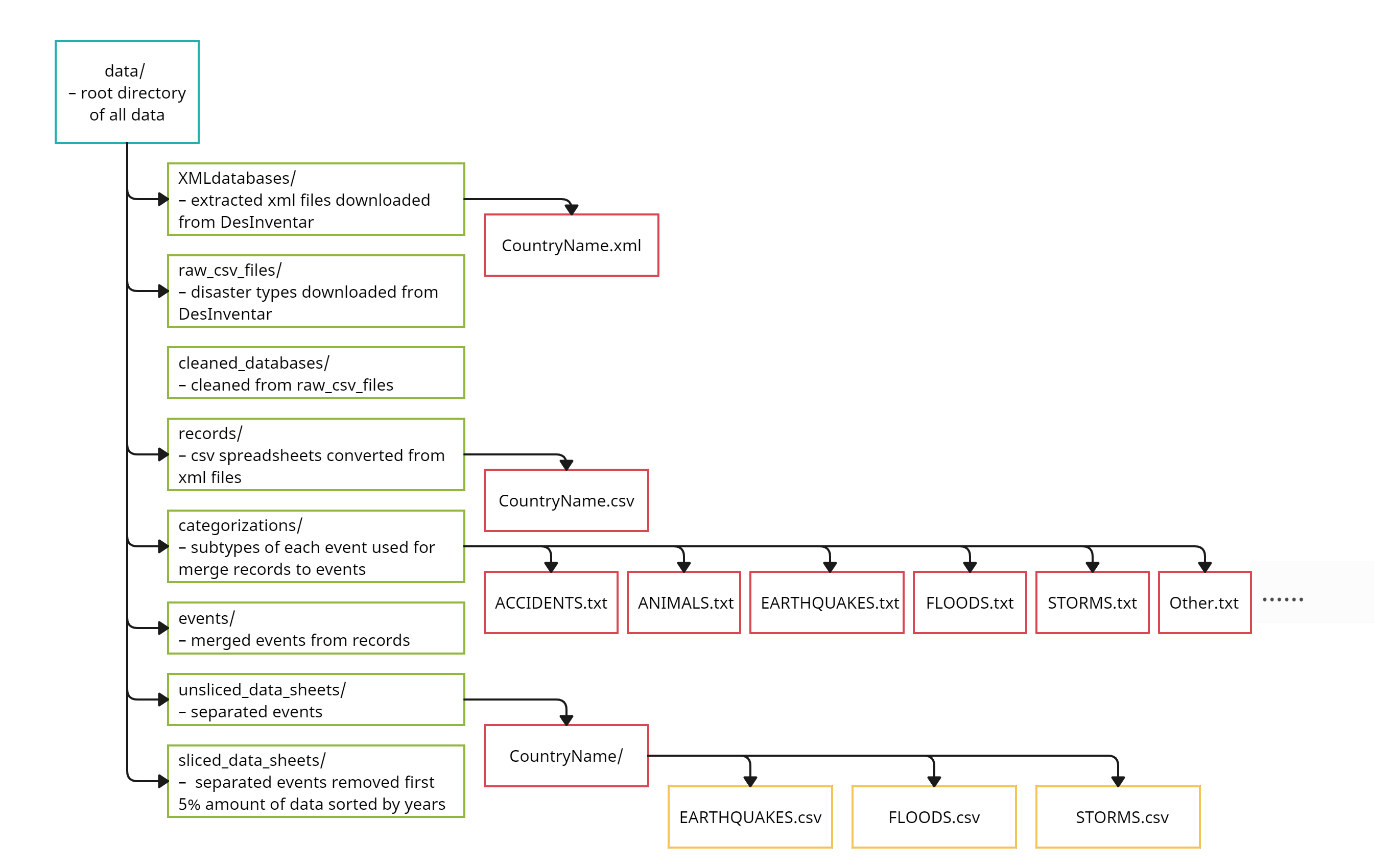
 Diagram.png)