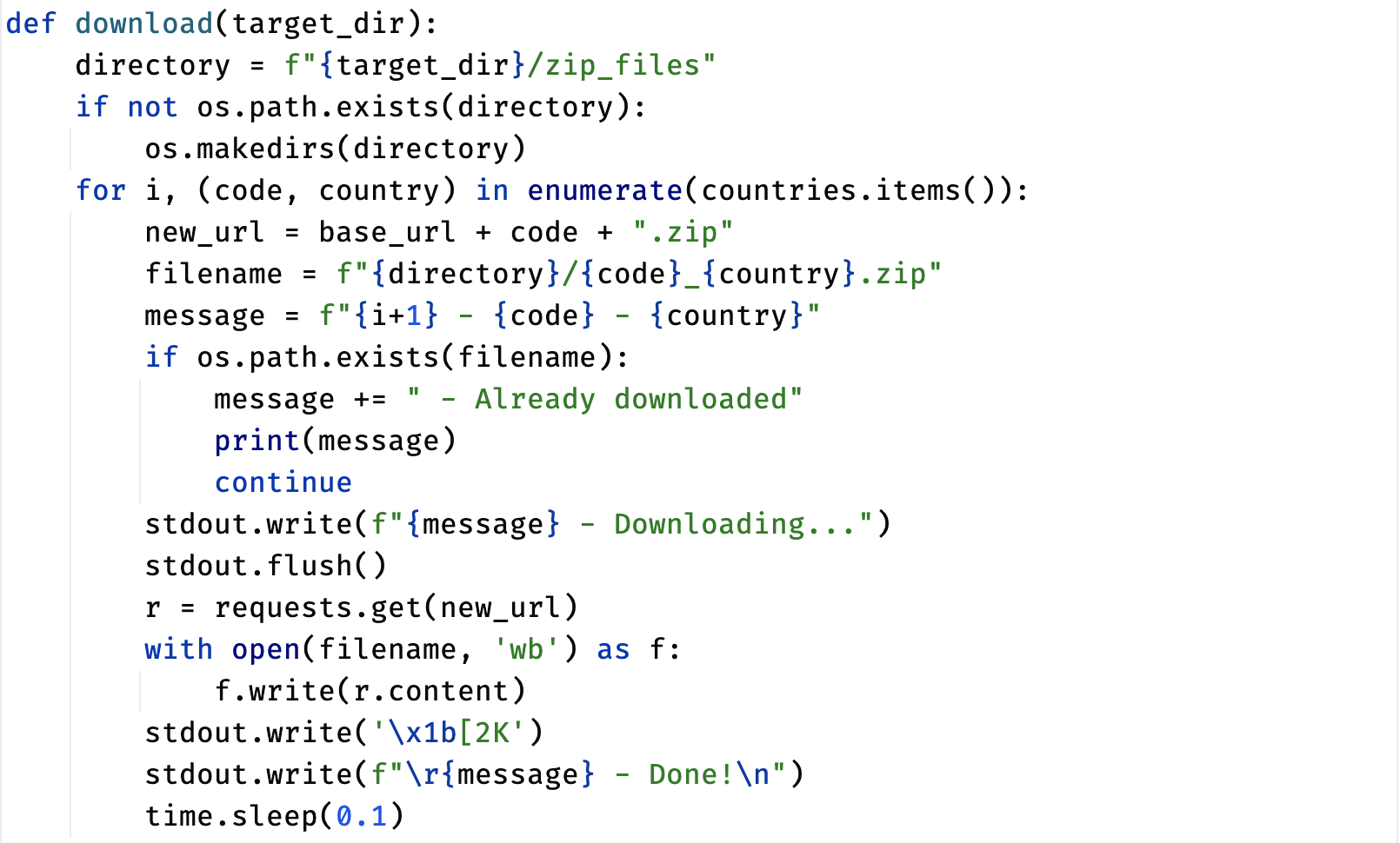
The DesInventar Dataset contains a vast amount of data related to natural disasters, across various countries and regions. Downloading this data one at a time would be a time-consuming process. To streamline this task, we used the BeautifulSoup and requests library to web-scrape the DesInventar website. As such, we were able to extract XML Files for each country and region, with the events that occurred within them.
Once we had collected this information, we were able to use DesInventar's public API to download all the files. This approach saved us a significant amount of time, not having to manually download the data for each country. Furthermore, it ensures the model can automatically update with the presence of new data.