Tools and Dependancies
BME680
The BME680 is the center of the project. It is a 4-in-1 sensor that measures temperature, humidity, pressure, and gas. We use the values read by the sensor to uniquely identify the scents.
The BME680 is the center of the project. It is a 4-in-1 sensor that measures temperature, humidity, pressure, and gas. We use the values read by the sensor to uniquely identify the scents.

Olfactometer
OWidgets' olfactometer is a custom-built device that is used to deliver the scents to the user. Providing short-duration scent stimuli, each of its 6 channels can be electronically activated - carrying a range of scents through an easily cleanable and replaceable cartridge.
OWidgets' olfactometer is a custom-built device that is used to deliver the scents to the user. Providing short-duration scent stimuli, each of its 6 channels can be electronically activated - carrying a range of scents through an easily cleanable and replaceable cartridge.

Raspberry PI
The Raspberry PI microcontroller is used to control everything in the system, from the Olfactometer to the BME680 sensor, and also to run the web server which hosts the interface to access the system.
The Raspberry PI microcontroller is used to control everything in the system, from the Olfactometer to the BME680 sensor, and also to run the web server which hosts the interface to access the system.

Python
Python is the main programming language used in the project. It is used to control the hardware and to run the web server, on the raspberry pi.
Python is the main programming language used in the project. It is used to control the hardware and to run the web server, on the raspberry pi.

Flask
Flask is a micro web framework written in Python. It is used to host the web server that provides the interface to access the system.
Flask is a micro web framework written in Python. It is used to host the web server that provides the interface to access the system.

TsFresh
TsFresh is a python library that is used to extract features from time series data. We use it to extract features from the sensor data.
TsFresh is a python library that is used to extract features from time series data. We use it to extract features from the sensor data.

Hardware Implementation
In our project, we've integrated the BME680 gas sensor for scent detection and OWidgets' Olfactometer for scent emission. Both hardware components are connected to a Raspberry Pi, serving as the central control unit. This setup ensures synchronous operation, enabling accurate detection and emission of scents in our system.
BME680 Sensor
The BME680 gas sensor is connected to the Raspberry Pi as shown in the following pinout diagram. All operations to and from the sensor are handled using the
Olfactometer
In our setup, the olfactometer is directly linked to the Raspberry Pi via the USB port, establishing a seamless connection for communication. The exact port is defined in
Integration of Olfactometer and Sensor
In our system architecture, both the
BME680 Sensor
The BME680 gas sensor is connected to the Raspberry Pi as shown in the following pinout diagram. All operations to and from the sensor are handled using the
SensorLogger class defined in sensor.py.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | class SensorLogger: def __init__( self, heater_temp_array: list[int], heater_duration_array: int, ): """Initializes sensor instance Arguments: heater_temp_array -- an array of 10 temp in C heater_duration_array -- an array of duration for each temp in ms """ # Initialize sensor with primary address, if that fails, use secondary address try: self.sensor = bme680.BME680(bme680.I2C_ADDR_PRIMARY) except (RuntimeError, IOError): self.sensor = bme680.BME680(bme680.I2C_ADDR_SECONDARY) # Set sensor settings self.sensor.set_humidity_oversample(bme680.OS_2X) self.sensor.set_pressure_oversample(bme680.OS_4X) self.sensor.set_temperature_oversample(bme680.OS_8X) self.sensor.set_filter(bme680.FILTER_SIZE_3) self.sensor.set_gas_status(bme680.ENABLE_GAS_MEAS) # Data structure to store data points # session_data = [[elapsed_time, temp, pressure, humidity, heater_idx, heater_temp, heater_dur, resistance]] self.session_data = [] self.heater_temp_array = heater_temp_array self.heater_duration_array = heater_duration_array self.heater_prof_len = len(heater_temp_array) self.globals = Globals() |
class SensorLogger:
def __init__(
self,
heater_temp_array: list[int],
heater_duration_array: int,
):
"""Initializes sensor instance
Arguments:
heater_temp_array -- an array of 10 temp in C
heater_duration_array -- an array of duration for each temp in ms
"""
# Initialize sensor with primary address, if that fails, use secondary address
try:
self.sensor = bme680.BME680(bme680.I2C_ADDR_PRIMARY)
except (RuntimeError, IOError):
self.sensor = bme680.BME680(bme680.I2C_ADDR_SECONDARY)
# Set sensor settings
self.sensor.set_humidity_oversample(bme680.OS_2X)
self.sensor.set_pressure_oversample(bme680.OS_4X)
self.sensor.set_temperature_oversample(bme680.OS_8X)
self.sensor.set_filter(bme680.FILTER_SIZE_3)
self.sensor.set_gas_status(bme680.ENABLE_GAS_MEAS)
# Data structure to store data points
# session_data = [[elapsed_time, temp, pressure, humidity, heater_idx, heater_temp, heater_dur, resistance]]
self.session_data = []
self.heater_temp_array = heater_temp_array
self.heater_duration_array = heater_duration_array
self.heater_prof_len = len(heater_temp_array)
self.globals = Globals()
The sensor operates on a schedule, and this schedule is provided to the SensorLogger in the form of arrays to the initialization method. This schedule is set to the sensor using the set_heater_profile method, that utilizes the BME680 sensor library's methods to configure the sensor.
1 2 3 4 5 6 7 8 9 | def set_heater_profile(self) -> None: """Sets gas heater array""" for i in range(self.heater_prof_len): if not self.globals.running: return self.sensor.set_gas_heater_profile( self.heater_temp_array[i], self.heater_duration_array[i], nb_profile=i ) |
def set_heater_profile(self) -> None:
"""Sets gas heater array"""
for i in range(self.heater_prof_len):
if not self.globals.running: return
self.sensor.set_gas_heater_profile(
self.heater_temp_array[i], self.heater_duration_array[i], nb_profile=i
)
Next, the get_data_point method gets a data point from the sensor for each heater temperature specified in the schedule, in the format: [data_idx, elaspsed_time, temp, pressure, humidity, heater_idx, heater_temp, heating_dur, resistance]. Each data point is appended to the self.session_data attribute. The globals variable here is updated with the most recent reading to allow for live monitoring on the front-end (more on that later).
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 | def get_data_point(self, elapsed_time: float, data_point_idx: int) -> None: """Requests and returns 10 data points of each 1 TPH and 1 gas resistance Arguments: elapsed_time {float} -- time from which function was called data_point_idx {int} -- the index of the current data point, all readings for a temp array are assigned a shared data point """ print(f"Data point: {data_point_idx}, Time: {round(elapsed_time, 2)}.") start_time = time.time() # Reset temp array self.set_heater_profile() # Initialize TPH reading used for all 10 gas readings tph = [] # Each data point in the format of [data_idx, elaspsed_time, temp, pressure, humidity, heater_idx, heater_temp, heating_dur, resistance] for heater_idx in range(len(self.heater_temp_array)): if not self.globals.running: return self.sensor.select_gas_heater_profile(heater_idx) if self.sensor.get_sensor_data(): # Only save the first TPH for a gas heater cycle, or tph empty if heater_idx == 0 or len(tph) == 0: cpu_temp = self.get_cpu_temperature() # TPH reading tph.extend( [ round(self.sensor.data.temperature, 2), round(self.sensor.data.pressure, 2), round(self.sensor.data.humidity, 2), ] ) if heater_idx == 0: print(f"Temp: {tph[0]} C, Pres: {tph[1]} hPa, Hum: {tph[2]} %RH, CPU Temp: {cpu_temp} C") # Wait for heater to stabilize with the heater duration in ms (minus 30ms to reach given temp) time.sleep((self.heater_duration_array[heater_idx] - 30) * 0.001) timestamp = round(elapsed_time + time.time() - start_time, 2) data_point = [data_point_idx, timestamp] # Gas reading heater_temp = self.heater_temp_array[heater_idx] heater_duration = self.heater_duration_array[heater_idx] if self.sensor.data.heat_stable: gas_resistance = round(self.sensor.data.gas_resistance, 2) data_point.extend( tph + [ heater_idx, heater_temp, heater_duration, gas_resistance, ] ) print(f"Dur: {heater_duration}, HT: {heater_temp}, GR: {gas_resistance} Ohms") else: # Still keep the data point array to length of 7 data_point.extend(tph + [heater_idx, None, None, None]) print( f"Missed a reading for gas profile index {heater_idx}: {heater_temp} C, {heater_duration}ms" ) self.globals.update_latest(time.time(), data_point) self.session_data.append(data_point) # If sensor failed to return data else: print("Failed to get sensor data.") print("\n") |
def get_data_point(self, elapsed_time: float, data_point_idx: int) -> None:
"""Requests and returns 10 data points of each 1 TPH and 1 gas resistance
Arguments:
elapsed_time {float} -- time from which function was called
data_point_idx {int} -- the index of the current data point, all readings
for a temp array are assigned a shared data point
"""
print(f"Data point: {data_point_idx}, Time: {round(elapsed_time, 2)}.")
start_time = time.time()
# Reset temp array
self.set_heater_profile()
# Initialize TPH reading used for all 10 gas readings
tph = []
# Each data point in the format of [data_idx, elaspsed_time, temp, pressure, humidity, heater_idx, heater_temp, heating_dur, resistance]
for heater_idx in range(len(self.heater_temp_array)):
if not self.globals.running: return
self.sensor.select_gas_heater_profile(heater_idx)
if self.sensor.get_sensor_data():
# Only save the first TPH for a gas heater cycle, or tph empty
if heater_idx == 0 or len(tph) == 0:
cpu_temp = self.get_cpu_temperature()
# TPH reading
tph.extend(
[
round(self.sensor.data.temperature, 2),
round(self.sensor.data.pressure, 2),
round(self.sensor.data.humidity, 2),
]
)
if heater_idx == 0:
print(f"Temp: {tph[0]} C, Pres: {tph[1]} hPa, Hum: {tph[2]} %RH, CPU Temp: {cpu_temp} C")
# Wait for heater to stabilize with the heater duration in ms (minus 30ms to reach given temp)
time.sleep((self.heater_duration_array[heater_idx] - 30) * 0.001)
timestamp = round(elapsed_time + time.time() - start_time, 2)
data_point = [data_point_idx, timestamp]
# Gas reading
heater_temp = self.heater_temp_array[heater_idx]
heater_duration = self.heater_duration_array[heater_idx]
if self.sensor.data.heat_stable:
gas_resistance = round(self.sensor.data.gas_resistance, 2)
data_point.extend(
tph
+ [
heater_idx,
heater_temp,
heater_duration,
gas_resistance,
]
)
print(f"Dur: {heater_duration}, HT: {heater_temp}, GR: {gas_resistance} Ohms")
else:
# Still keep the data point array to length of 7
data_point.extend(tph + [heater_idx, None, None, None])
print(
f"Missed a reading for gas profile index {heater_idx}: {heater_temp} C, {heater_duration}ms"
)
self.globals.update_latest(time.time(), data_point)
self.session_data.append(data_point)
# If sensor failed to return data
else:
print("Failed to get sensor data.")
print("\n")
Finally, the run method of the of class periodically calls the get_data_point method, using a variable called data_point_idx to keep track of the data points.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | def run(self, start_time: float, session_duration: float, sleep_time) -> None: """Records data points for a given duration Arguments: start_time -- time from which function was called session_duration -- duration for the experiment sleep_time -- time to sleep between each data point Raises: KeyboardInterrupt: if user interrupts the program """ try: elapsed_time = 0 data_point_idx = 0 while elapsed_time < session_duration: if not self.globals.running: return elapsed_time = time.time() - start_time self.get_data_point(elapsed_time, data_point_idx) data_point_idx += 1 time.sleep(sleep_time) except KeyboardInterrupt: raise KeyboardInterrupt |
def run(self, start_time: float, session_duration: float, sleep_time) -> None:
"""Records data points for a given duration
Arguments:
start_time -- time from which function was called
session_duration -- duration for the experiment
sleep_time -- time to sleep between each data point
Raises:
KeyboardInterrupt: if user interrupts the program
"""
try:
elapsed_time = 0
data_point_idx = 0
while elapsed_time < session_duration:
if not self.globals.running: return
elapsed_time = time.time() - start_time
self.get_data_point(elapsed_time, data_point_idx)
data_point_idx += 1
time.sleep(sleep_time)
except KeyboardInterrupt:
raise KeyboardInterrupt
Olfactometer
In our setup, the olfactometer is directly linked to the Raspberry Pi via the USB port, establishing a seamless connection for communication. The exact port is defined in
setUp/constants.pyUtilizing a serial interface, bidirectional communication with the olfactometer is facilitated. This interaction is managed through the Ow06 class within the ow06.py module. Within this class, pivotal methods such as write_com and read_com are defined to handle outgoing and incoming messages to and from the olfactometer, respectively. These methods serve as the backbone for all communication tasks, with other methods leveraging their functionality to execute various operations seamlessly.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | def write_com(self, msg: str) -> None: """Converting message to bytes and write it to serial port, Arguments: msg {str} -- string to write to serial port Raises: Exception: Serial errors or provided msg is empty SerialException: _description_ """ if self.connected == False: raise Exception( f"olfac: write_com - serial not connected. Have you called open_com()?" ) if msg is None or len(msg) == 0: raise Exception("olfac: write_com - msg parameter is empty") # Encoding in recommended format for serial communication msg = msg + "\n" msg = msg.encode("utf-8") if msg is None or len(msg) == 0: raise Exception("olfac: write_com - msg is empty after encoding") # Write to serial port try: self.serial.write(msg) self.serial.flush() except SerialException as e: raise SerialException( f"olfac: write_com - error while writing to serial port. Details: {e}" )def read_com(self) -> str: """Reads from serial port, decodes, and returns the first line""" if not self.connected: raise Exception( f"olfac: read_com - serial not connected. Have you called open_com()?" ) # Read from serial port line = None try: line = self.serial.readline() except Exception as e: raise Exception( f"olfac: read_com - error while reading from serial port. Details: {e}" ) # Decode and split line line = line.decode("utf-8").split() if line is None or len(line) == 0: raise Exception("olfac: read_com - line is empty after decoding") return line[0] |
def write_com(self, msg: str) -> None:
"""Converting message to bytes and write it to serial port,
Arguments:
msg {str} -- string to write to serial port
Raises:
Exception: Serial errors or provided msg is empty
SerialException: _description_
"""
if self.connected == False:
raise Exception(
f"olfac: write_com - serial not connected. Have you called open_com()?"
)
if msg is None or len(msg) == 0:
raise Exception("olfac: write_com - msg parameter is empty")
# Encoding in recommended format for serial communication
msg = msg + "\n"
msg = msg.encode("utf-8")
if msg is None or len(msg) == 0:
raise Exception("olfac: write_com - msg is empty after encoding")
# Write to serial port
try:
self.serial.write(msg)
self.serial.flush()
except SerialException as e:
raise SerialException(
f"olfac: write_com - error while writing to serial port. Details: {e}"
)
def read_com(self) -> str:
"""Reads from serial port, decodes, and returns the first line"""
if not self.connected:
raise Exception(
f"olfac: read_com - serial not connected. Have you called open_com()?"
)
# Read from serial port
line = None
try:
line = self.serial.readline()
except Exception as e:
raise Exception(
f"olfac: read_com - error while reading from serial port. Details: {e}"
)
# Decode and split line
line = line.decode("utf-8").split()
if line is None or len(line) == 0:
raise Exception("olfac: read_com - line is empty after decoding")
return line[0]
There are a set number of commands that can be sent to the olfactometer via the serial interface. These commands are used to control the olfactometer and are sent by the Ow06 class. The commands are as follows:
CHAN <chan_id> :STAT ON- Turns on channel <chan_id>CHAN <chan_id> :STAT OFF- Turns off channel <chan_id>CHAN <chan_id> :STAT?- Gets status of channel <chan_id> (True / False)
Integration of Olfactometer and Sensor
In our system architecture, both the
Ow06 and SensorLogger classes operate synchronously, adhering to a predefined schedule orchestrated within the DataSynthesizer class, found in main.py. This class serves as the central control unit for managing the interaction between the olfactometer and sensor logging functionalities.
To ensure streamlined operation, crucial setup parameters and constants are stored in the setUp/constants.py file. Here, essential variables such as file paths, olfactometer port configurations, gas profile settings, and other options are defined for easy access and maintenance.
The run method within the DataSynthesizer class stands as the key method of the system. This method orchestrates the execution of both the Ow06 and SensorLogger classes according to the specified schedule. Leveraging the constants provided in the constants.py file, the run method initializes necessary configurations and parameters, ensuring seamless operation of the system components.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | def run( self, heater_schedule_file_path: str, olfac_schedule_file_path: str, olfac_port: str, stabilisation_time: int, cycle_stabilisation_time: int, reading_sleep_time: float, cycle_duration: float, output_path: str, feature_extraction: bool, ) -> None: """Runs synthesizer, recording data to csv file Arguments: heater_schedule_file_path -- path to csv file containing heater schedule olfac_schedule_file_path -- path to csv file containing olfactometer schedule olfac_port -- serial port to connect to olfactometer stabilisation_time -- time to stabilise before beginning cycle cycle_stabilisation_time -- time to stabilise before each cycle reading_sleep_time -- time to wait between each reading in seconds cycle_duration -- duration of each cycle in seconds output_path -- path to output directory to create csv file feature_extraction -- boolean to enable feature extraction """ # Initialize Sensor try: self.sensor_init(file_path=heater_schedule_file_path) except Exception as e: raise Exception( f"DataSynthesizer: run - error while initializing sensor. Details: {e}" ) # read olfac schedule try: self.schedule = self.olfac_read_schedule(file_path=olfac_schedule_file_path) except Exception as e: raise Exception( f"DataSynthesizer: olfac_init - error while reading schedule. Details: {e}" ) ... |
def run(
self,
heater_schedule_file_path: str,
olfac_schedule_file_path: str,
olfac_port: str,
stabilisation_time: int,
cycle_stabilisation_time: int,
reading_sleep_time: float,
cycle_duration: float,
output_path: str,
feature_extraction: bool,
) -> None:
"""Runs synthesizer, recording data to csv file
Arguments:
heater_schedule_file_path -- path to csv file containing heater schedule
olfac_schedule_file_path -- path to csv file containing olfactometer schedule
olfac_port -- serial port to connect to olfactometer
stabilisation_time -- time to stabilise before beginning cycle
cycle_stabilisation_time -- time to stabilise before each cycle
reading_sleep_time -- time to wait between each reading in seconds
cycle_duration -- duration of each cycle in seconds
output_path -- path to output directory to create csv file
feature_extraction -- boolean to enable feature extraction
"""
# Initialize Sensor
try:
self.sensor_init(file_path=heater_schedule_file_path)
except Exception as e:
raise Exception(
f"DataSynthesizer: run - error while initializing sensor. Details: {e}"
)
# read olfac schedule
try:
self.schedule = self.olfac_read_schedule(file_path=olfac_schedule_file_path)
except Exception as e:
raise Exception(
f"DataSynthesizer: olfac_init - error while reading schedule. Details: {e}"
)
...
Then, the method goes on to read the olfactometer schedule and initialize the olfactometer. For each cycle in the schedule, the method waits for the stabilisation time, then turns on the olfactometer channels according to the schedule, followed by the sensor. The olfactometer runs on a thread, so that both the sensor and the olfactometer can run synchronously. It then waits for the cycle stabilisation time before turning off the channels and waiting for the next cycle.
042 043 044 045 046 047 048 049 050 051 052 053 054 055 056 057 058 059 060 061 062 063 064 065 066 067 068 069 070 071 072 073 074 075 076 077 078 079 080 081 082 083 084 085 086 087 088 089 090 091 092 093 094 095 096 097 098 099 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 | ... # Run schedule for cycle in self.schedule: if not self.globals.running: self.olfactometer.close_com() return stabilisation_time = 0 # Stabilise, usually only for very first round after sensor inactive for a few hours if stabilisation_time > 0: try: start_time = time.time() self.sensor_logger.run( start_time=start_time, session_duration=stabilisation_time, sleep_time=reading_sleep_time, ) self.sensor_logger.session_data = [] except Exception as e: raise Exception( f"DataSynthesizer: run - error while reading data. Details: {e}" ) try: channelNum, scentNum, duration = cycle # Initilize a new olfac instance for every olfactometer emission self.olfactometer = Ow06() try: self.olfactometer.open_com(olfac_port) except Exception as e: raise Exception( f"DataSynthesizer: run - error while opening olfac serial port. Details: {e}" ) # Note the datatime date_time = datetime.now() date_time = date_time.strftime("%Y-%m-%d-%H-%M-%S") # CYCLE STABILISATION if cycle_stabilisation_time > 0: try: start_time = time.time() self.sensor_logger.run( start_time=start_time, session_duration=cycle_stabilisation_time, sleep_time=reading_sleep_time, ) stabilisation_elapsed_time = time.time() - start_time total_data_points = self.sensor_logger.session_data[-1][0] + 1 # Shift the time stamps during stabilisation by the elapsed time (resulting in negative time stamp) for data_point in self.sensor_logger.session_data: # Shifts data_point_idx data_point[0] -= total_data_points # Shifts time data_point[1] = round( data_point[1] - stabilisation_elapsed_time, 2 ) except Exception as e: raise Exception( f"DataSynthesizer: run - error while reading data. Details: {e}" ) start_time = time.time() print( f"Beginning cycle: channel {channelNum}, scent {scentNum}, duration {duration}s" ) # Enable olfactometer channel if duration > 0 and channelNum > 0 and channelNum < 7: olfac_emission = threading.Thread( target=self.olfac_emission, args=(channelNum, duration), daemon=True, ) olfac_emission.start() else: olfac_emission = None # Read data try: self.sensor_logger.run( start_time=start_time, session_duration=cycle_duration, sleep_time=reading_sleep_time, ) except Exception as e: raise Exception( f"DataSynthesizer: run - error while reading data. Details: {e}" )... |
...
# Run schedule
for cycle in self.schedule:
if not self.globals.running:
self.olfactometer.close_com()
return
stabilisation_time = 0
# Stabilise, usually only for very first round after sensor inactive for a few hours
if stabilisation_time > 0:
try:
start_time = time.time()
self.sensor_logger.run(
start_time=start_time,
session_duration=stabilisation_time,
sleep_time=reading_sleep_time,
)
self.sensor_logger.session_data = []
except Exception as e:
raise Exception(
f"DataSynthesizer: run - error while reading data. Details: {e}"
)
try:
channelNum, scentNum, duration = cycle
# Initilize a new olfac instance for every olfactometer emission
self.olfactometer = Ow06()
try:
self.olfactometer.open_com(olfac_port)
except Exception as e:
raise Exception(
f"DataSynthesizer: run - error while opening olfac serial port. Details: {e}"
)
# Note the datatime
date_time = datetime.now()
date_time = date_time.strftime("%Y-%m-%d-%H-%M-%S")
# CYCLE STABILISATION
if cycle_stabilisation_time > 0:
try:
start_time = time.time()
self.sensor_logger.run(
start_time=start_time,
session_duration=cycle_stabilisation_time,
sleep_time=reading_sleep_time,
)
stabilisation_elapsed_time = time.time() - start_time
total_data_points = self.sensor_logger.session_data[-1][0] + 1
# Shift the time stamps during stabilisation by the elapsed time (resulting in negative time stamp)
for data_point in self.sensor_logger.session_data:
# Shifts data_point_idx
data_point[0] -= total_data_points
# Shifts time
data_point[1] = round(
data_point[1] - stabilisation_elapsed_time, 2
)
except Exception as e:
raise Exception(
f"DataSynthesizer: run - error while reading data. Details: {e}"
)
start_time = time.time()
print(
f"Beginning cycle: channel {channelNum}, scent {scentNum}, duration {duration}s"
)
# Enable olfactometer channel
if duration > 0 and channelNum > 0 and channelNum < 7:
olfac_emission = threading.Thread(
target=self.olfac_emission,
args=(channelNum, duration),
daemon=True,
)
olfac_emission.start()
else:
olfac_emission = None
# Read data
try:
self.sensor_logger.run(
start_time=start_time,
session_duration=cycle_duration,
sleep_time=reading_sleep_time,
)
except Exception as e:
raise Exception(
f"DataSynthesizer: run - error while reading data. Details: {e}"
)
...
The method also reads the sensor data at regular intervals and writes it to a CSV file. If feature extraction is enabled, the method also extracts features from the sensor data and writes them to a separate CSV file.
139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 | ... # Write data to csv try: self.write_data_to_csv( start_time=start_time, file_name=date_time, scent_num=scentNum, output_path=output_path, feature_extraction=feature_extraction, ) except Exception as e: raise Exception( f"DataSynthesizer: run - error while writing data to csv. Details: {e}" ) # Reset session specific attributes self.sensor_logger.session_data = [] self.olfac_end_time = None print( f"Finished cycle: channel {channelNum}, scent {scentNum}, duration {duration}s" ) # heater cooldown time.sleep(10) # if there is any exception, skip and go to the next scheduled cycle except Exception as e: print(f"{cycle} failed. Details: {e}") continue |
...
# Write data to csv
try:
self.write_data_to_csv(
start_time=start_time,
file_name=date_time,
scent_num=scentNum,
output_path=output_path,
feature_extraction=feature_extraction,
)
except Exception as e:
raise Exception(
f"DataSynthesizer: run - error while writing data to csv. Details: {e}"
)
# Reset session specific attributes
self.sensor_logger.session_data = []
self.olfac_end_time = None
print(
f"Finished cycle: channel {channelNum}, scent {scentNum}, duration {duration}s"
)
# heater cooldown
time.sleep(10)
# if there is any exception, skip and go to the next scheduled cycle
except Exception as e:
print(f"{cycle} failed. Details: {e}")
continue
Web Server Implementation
Our project's primary user interface is deployed via a Flask server. To start the server for accessing the web application-based UI, the user executes the app.py script. Within app.py, various routes are defined as functions. These routes serve as endpoints that are invoked when a client attempts to access a specific URL. These routes can function not only to render web pages but also to serve as APIs, enabling interaction with the server through HTTP requests.
Identification page
Config Page
Both the sensor configuration (/config-sensor) and olfactometer configuration (/config-olfac) pages are rendered using the same template. The template is populated with the appropriate form fields based on the configuration type. The form fields are pre-filled with the current configuration values, allowing the user to modify them as needed. Upon submission, the form data is sent to the server, which then updates the configuration files accordingly. This submission is performed by the submitForm function, which sends a POST request to the server at /submit-data with the form data. The formType variable specifies the type of configuration being submitted, and whether the file is being selected or changed. Then on the backend, the server receives the form data and updates the configuration files accordingly.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 | function submitForm(formID, formType, csv_names) { var formData = {formType: formType}; if (!validateForm(formID)) { document.getElementById(formID).reportValidity(); return false; } if (!editing & csv_names.includes(document.getElementById('csv-name').value + '.csv')) { showToast('toast-error', 'File name already exists. Edit it with the "Edit" button or choose a different name.'); return false; } // Extract form data from table for creation form (editing uses same form) if (formType == 'sensor-create' || formType == 'olfac-create') { var toastType = 'create'; var csvName = document.getElementById('csv-name').value; formData['csv_name'] = csvName; var values = []; // For each row, extract data and append to array $('#' + formID + ' tbody tr').each(function (index, row) { var rowFormData = {}; $(row).find('.form-select, input').each(function (idx, element) { rowFormData[element.name] = element.value; }); values.push(rowFormData); }); formData['values'] = values; } // Extract form data for selection form if (formType == 'olfac-select' || formType == 'sensor-select') { var toastType = 'select'; var configFilename = document.getElementById('config-filename').value; formData['config_filename'] = configFilename; } if (formType == 'olfac-select') { var repeatValue = document.getElementById('repeat').value; formData['repeat'] = repeatValue; } $.ajax({ type: 'POST', url: '/submit-data', contentType: 'application/json;charset=UTF-8', data: JSON.stringify(formData), success: function(response) { if (editing) { var toastText = 'Edited ' + csvName; } else if (toastType == 'create') { var toastText = 'Created ' + csvName + '.csv'; } else if (toastType == 'select') { var toastText = 'Set configuration to ' + configFilename; } showToast('toast-success', toastText); clearForm(formID); closeModal('create-form'); }, error: function(error) { if (editing) { var toastText = 'Error editing ' + csvName; } else if (toastType == 'create') { var toastText = 'Error creating ' + csvName + '.csv'; } else if (toastType == 'select') { var toastText = 'Error setting configuration to ' + configFilename; } else { var toastText = 'Unknown error: see console'; } showToast('toast-error', toastText); } }); // Prevent default form submission return false;} |
function submitForm(formID, formType, csv_names) {
var formData = {formType: formType};
if (!validateForm(formID)) {
document.getElementById(formID).reportValidity();
return false;
}
if (!editing & csv_names.includes(document.getElementById('csv-name').value + '.csv')) {
showToast('toast-error', 'File name already exists. Edit it with the "Edit" button or choose a different name.');
return false;
}
// Extract form data from table for creation form (editing uses same form)
if (formType == 'sensor-create' || formType == 'olfac-create') {
var toastType = 'create';
var csvName = document.getElementById('csv-name').value;
formData['csv_name'] = csvName;
var values = [];
// For each row, extract data and append to array
$('#' + formID + ' tbody tr').each(function (index, row) {
var rowFormData = {};
$(row).find('.form-select, input').each(function (idx, element) {
rowFormData[element.name] = element.value;
});
values.push(rowFormData);
});
formData['values'] = values;
}
// Extract form data for selection form
if (formType == 'olfac-select' || formType == 'sensor-select') {
var toastType = 'select';
var configFilename = document.getElementById('config-filename').value;
formData['config_filename'] = configFilename;
}
if (formType == 'olfac-select') {
var repeatValue = document.getElementById('repeat').value;
formData['repeat'] = repeatValue;
}
$.ajax({
type: 'POST',
url: '/submit-data',
contentType: 'application/json;charset=UTF-8',
data: JSON.stringify(formData),
success: function(response) {
if (editing) {
var toastText = 'Edited ' + csvName;
} else if (toastType == 'create') {
var toastText = 'Created ' + csvName + '.csv';
} else if (toastType == 'select') {
var toastText = 'Set configuration to ' + configFilename;
}
showToast('toast-success', toastText);
clearForm(formID);
closeModal('create-form');
},
error: function(error) {
if (editing) {
var toastText = 'Error editing ' + csvName;
} else if (toastType == 'create') {
var toastText = 'Error creating ' + csvName + '.csv';
} else if (toastType == 'select') {
var toastText = 'Error setting configuration to ' + configFilename;
} else {
var toastText = 'Unknown error: see console';
}
showToast('toast-error', toastText);
}
});
// Prevent default form submission
return false;
}
Monitoring Page
The monitoring page allows the user to view live values coming from the sensor, as well as start the setup. The key feature of this page is how live readings are obtained from the sensor, which runs on a different thread. This is made possible by the Globals class, which is a singleton class. This class stored various variables, the same copy of all of which are accessible throughout the system. This also allows the entire setup to be stopped whenever the command is sent from the monitoring page.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | class Globals: _instance = None def __new__(cls): if cls._instance is None: cls._instance = super(Globals, cls).__new__(cls) cls._instance.__initialized = False return cls._instance def __init__(self): if not self.__initialized: self.__initialized = True self.running = False self.latest_sensor_reading = {} self.error = None self.model_page = None self.training_running = False self.stop_training = False self.new_model = False self.new_model_name = None def update_latest(self, ts, data_point: list) -> None: self.latest_sensor_reading = {"x": ts, "y": data_point[2:5] + [data_point[-1]]} |
class Globals:
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super(Globals, cls).__new__(cls)
cls._instance.__initialized = False
return cls._instance
def __init__(self):
if not self.__initialized:
self.__initialized = True
self.running = False
self.latest_sensor_reading = {}
self.error = None
self.model_page = None
self.training_running = False
self.stop_training = False
self.new_model = False
self.new_model_name = None
def update_latest(self, ts, data_point: list) -> None:
self.latest_sensor_reading = {"x": ts, "y": data_point[2:5] + [data_point[-1]]}
The graph on the monitoring page is a Chart.js graph, which is updated every second with the latest data point. The data point is obtained from the Globals class, which is updated by the sensor thread. The updateChart() function is called every second to update the graph. The function makes an AJAX call to the server to get the latest data point, and updates the graph with the new data point.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | const NUM_OF_POINTS = 21;function updateChart() { // Check for new data point from server $.ajax({ url: '/get_data', type: 'GET', dataType: 'json', success: function (data) { if (!running || Object.keys(data) == 0) { return; } if (data.error) { alert('Error fetching data: ' + data.error); return; } // Add new data point // Convert ms timestamp to time var date = new Date(parseFloat(data.x) * 1000); var time = date.getHours() + ':' + date.getMinutes() + ':' + date.getSeconds(); liveChart.data.labels.push(time); liveChart.data.datasets[0].data.push(data.y[current]); liveChart.update(); }, error: function (error) { console.error('Error fetching data:', error); } });}setInterval(updateChart, 1000); |
const NUM_OF_POINTS = 21;
function updateChart() {
// Check for new data point from server
$.ajax({
url: '/get_data',
type: 'GET',
dataType: 'json',
success: function (data) {
if (!running || Object.keys(data) == 0) {
return;
}
if (data.error) {
alert('Error fetching data: ' + data.error);
return;
}
// Add new data point
// Convert ms timestamp to time
var date = new Date(parseFloat(data.x) * 1000);
var time = date.getHours() + ':' + date.getMinutes() + ':' + date.getSeconds();
liveChart.data.labels.push(time);
liveChart.data.datasets[0].data.push(data.y[current]);
liveChart.update();
},
error: function (error) {
console.error('Error fetching data:', error);
}
});
}
setInterval(updateChart, 1000);
On the identification page, the user can create a new model by choosing the "Create new" option in the dropdown, an entering the desired name for the new model. They can also choose an existing model from the dropdown list. Each time the user changes the model selected, the server creates a new
When the user clicks the "Create model" button, the name entered by the user is then saved as a global variable
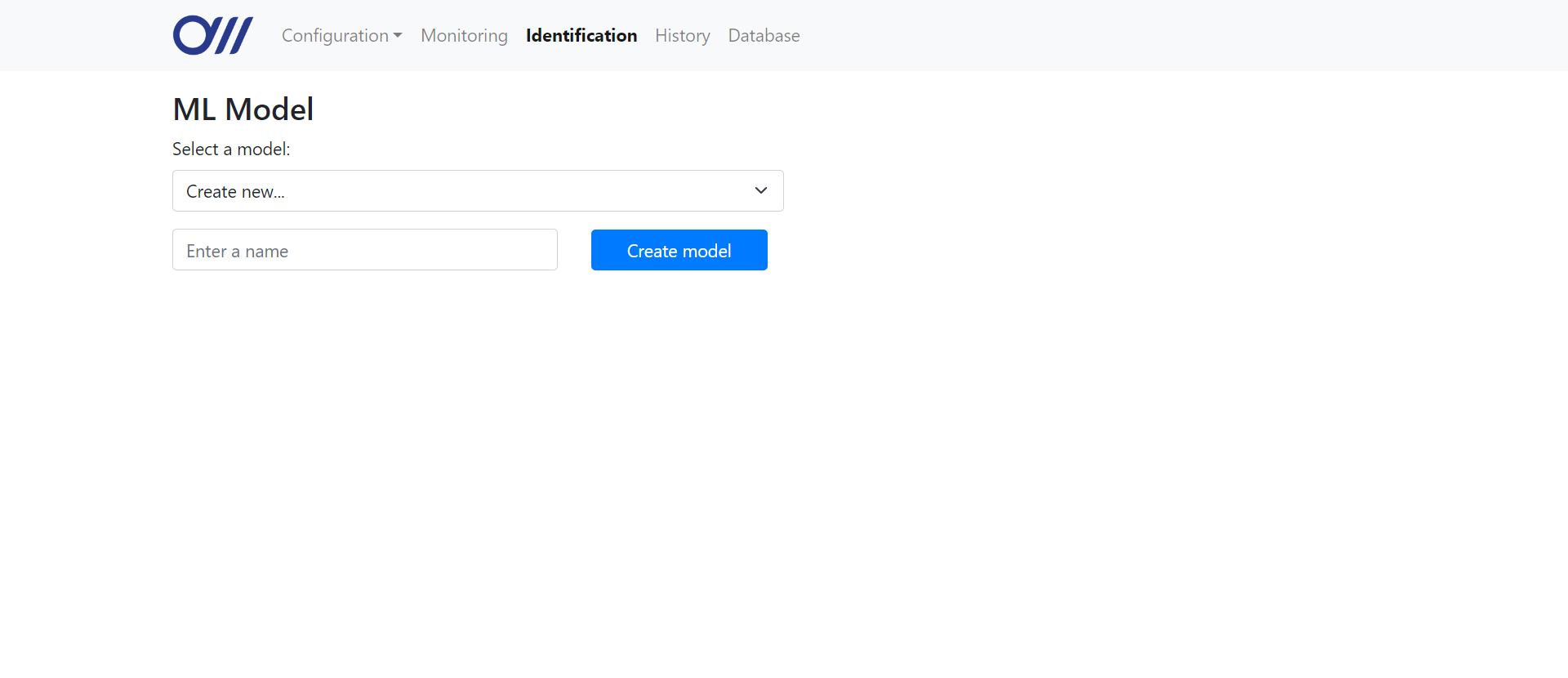
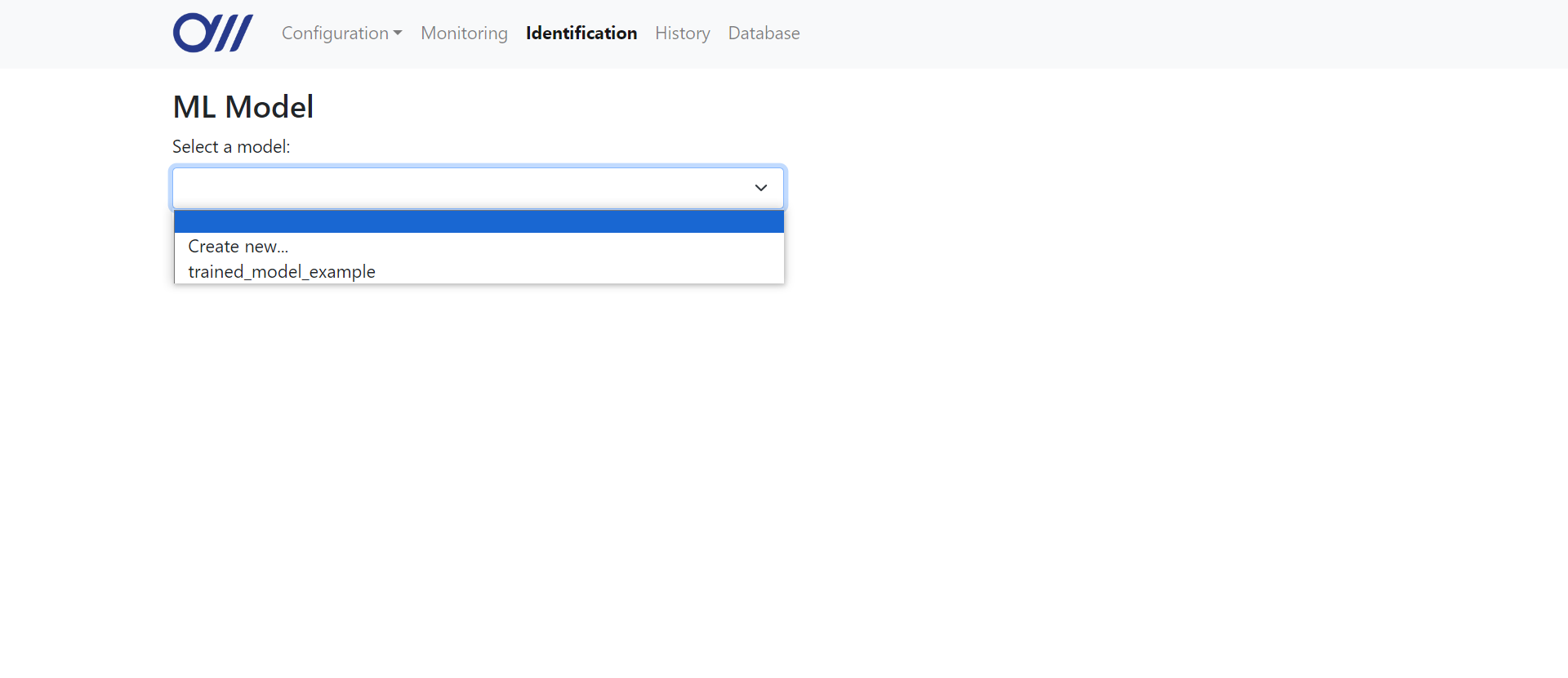
The user can also choose to use an existing model from the dropdown list. The Flask application routes the
There are two training modes which the user can choose between: easy (one-click) training, and advanced training.
For easy training, the user simply searches for a datafile by entering a range of dates and selecting a file from the dropdown list. Starting training brings up a modal element with a message box displaying progress update messages from the server. Every 1 second, the Javascript function
On the server's end, the
For advanced training, the user is taken through each step of creating and training a model. For steps which do not require any user input, the front-end displays a loading modal similar to the easy training one, retrieving messages from the
At each step where the user has to input their own parameters, the user is shown a dialogue box to input the parameters. Each step has a "Next" button which submits the data to the server using an AJAX call. The code snippet below shows the Javascript function for submitting the data for the second step.
The server-side function receives the data from the front-end and runs the respective function for that step of model training. It returns any messages to be displayed at the next step of training.
When training is complete, training results are updated and displayed on the page using an AJAX request to retrieve the results. This includes a classification report, a confusion matrix, and 2 graphs displaying the training loss and training accuracy. These graphs are interative and created with Chart.js; the user can zoom in and out of the graphs to view them in greater detail.
The user can also choose a file to identify by searching by a range of dates. The server sends a similar AJAX request to the server and receives the identification results, which are displayed in a bar chart.
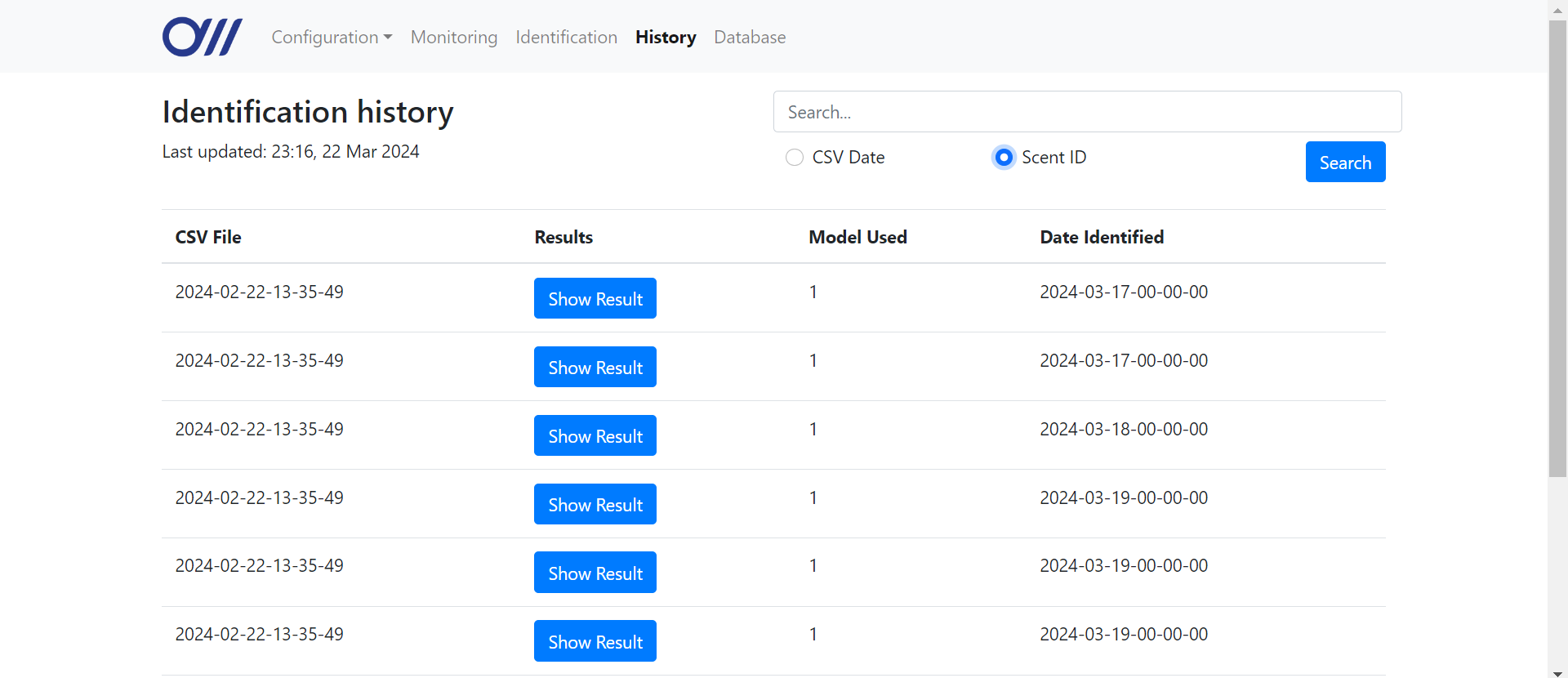
History page
When the user opens the history page, the Flask application routes the
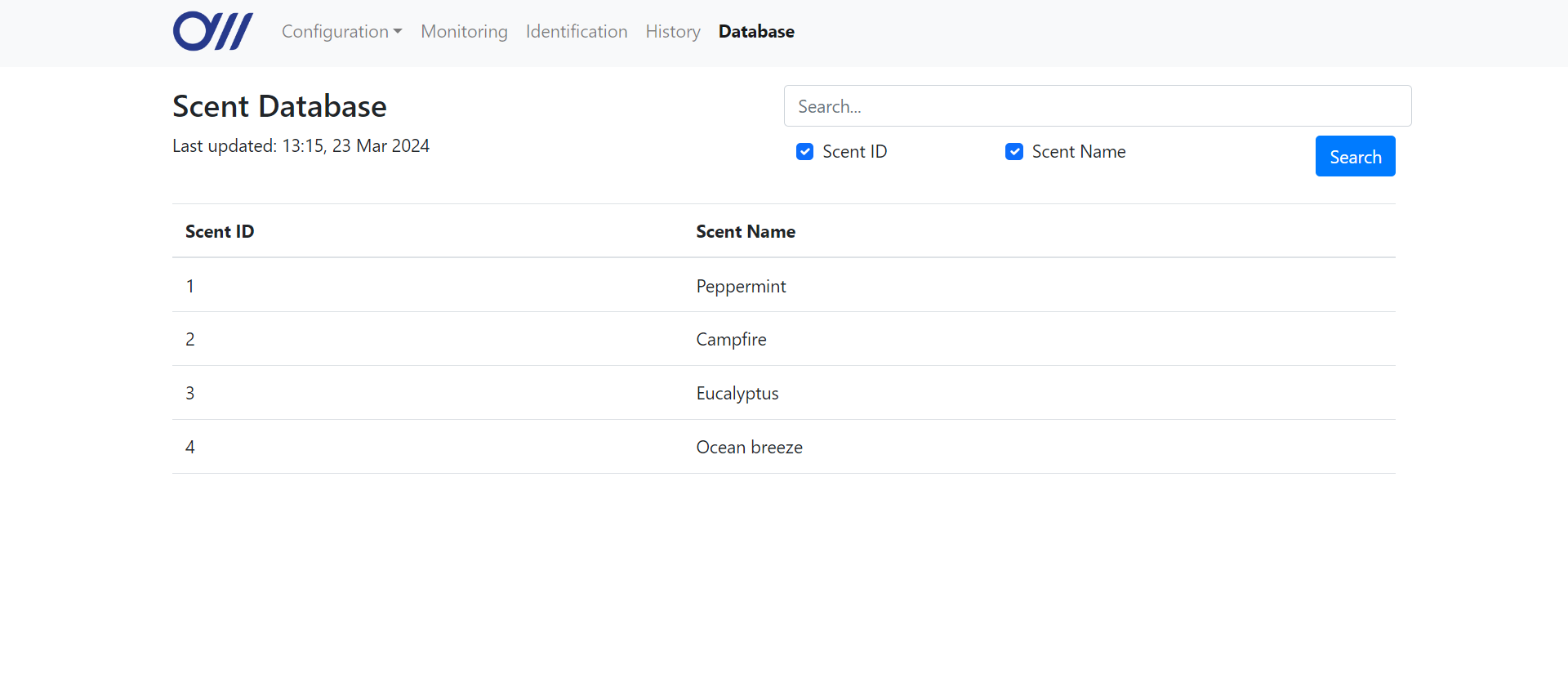
Scent database page
The scent database can be viewed at the
ModelPage object, from the existing model's path if the user selected an existing one and initialising it without reading from a directory otherwise. The new object is then stored as global_variables.model_page.When the user clicks the "Create model" button, the name entered by the user is then saved as a global variable
global_variables.new_model_name and the global variable global_variables.new_model, which is a boolean, is set to True to indicate that the model being trained does not have an existing directory and a new directory must be created. Once training is complete and the model is saved, the new model is added to the model database with the name stored in global_variables.new_model_name.The user can also choose to use an existing model from the dropdown list. The Flask application routes the
/identification URL to run the function identification to display the page. In this function, the database is read from the model database file, specified in constants.py as MODEL_DB_PATH. The 2-dimensional array returned by readDB is passed into the Jinja placeholders in the HTML file, which then dynamically populates the dropdown list in the UI with the model names (shown below).1 2 3 4 5 | @app.route('/identification')def identification(): db = db_handler.ModelDBHandler(MODEL_DB_PATH) results = db.readDB() return render_template('identification.html', data=results) |
@app.route('/identification')
def identification():
db = db_handler.ModelDBHandler(MODEL_DB_PATH)
results = db.readDB()
return render_template('identification.html', data=results)
There are two training modes which the user can choose between: easy (one-click) training, and advanced training.
For easy training, the user simply searches for a datafile by entering a range of dates and selecting a file from the dropdown list. Starting training brings up a modal element with a message box displaying progress update messages from the server. Every 1 second, the Javascript function
getLoadingModalText is called. This function uses AJAX to send a GET request the server at the route /get-loading-text to retrieve the latest message.01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 | function getLoadingModalText() { $.ajax({ type: 'GET', url: '/get-loading-text', contentType: 'application/json;charset=UTF-8', success: function(response) { trainingRunning = response['running']; if (response['message'] != undefined && response['message'] != '') { p = document.createElement('p'); p.textContent = response['message']; document.getElementById('loading-modal-console-content').appendChild(p); } }, error: function(error) { // Abort and show error message showToast('toast-error', 'Error: see console.'); } });} |
function getLoadingModalText() {
$.ajax({
type: 'GET',
url: '/get-loading-text',
contentType: 'application/json;charset=UTF-8',
success: function(response) {
trainingRunning = response['running'];
if (response['message'] != undefined && response['message'] != '') {
p = document.createElement('p');
p.textContent = response['message'];
document.getElementById('loading-modal-console-content').appendChild(p);
}
},
error: function(error) {
// Abort and show error message
showToast('toast-error', 'Error: see console.');
}
});
}
On the server's end, the
get_loading_text function checks for any new messages from the training, which are stored in the temp_messages attribute of the ModelPage object in the global_variables object. It then returns the new message if any is found. It also returns whether the training is still running, so that the front-end knows when it should close the loading modal.1 2 3 4 5 6 7 8 9 | prev_index = 0@app.route("/get-loading-text", methods=['GET'])def get_loading_text(): global global_variables, prev_index cur_msg = '' if global_variables.model_page and len(global_variables.model_page.temp_messages) > prev_index: cur_msg = global_variables.model_page.temp_messages[prev_index] prev_index += 1 return jsonify({'running':global_variables.training_running, 'message': cur_msg}) |
prev_index = 0
@app.route("/get-loading-text", methods=['GET'])
def get_loading_text():
global global_variables, prev_index
cur_msg = ''
if global_variables.model_page and len(global_variables.model_page.temp_messages) > prev_index:
cur_msg = global_variables.model_page.temp_messages[prev_index]
prev_index += 1
return jsonify({'running':global_variables.training_running, 'message': cur_msg})
For advanced training, the user is taken through each step of creating and training a model. For steps which do not require any user input, the front-end displays a loading modal similar to the easy training one, retrieving messages from the
temp_messages attribute of the ModelPage object in the same way.At each step where the user has to input their own parameters, the user is shown a dialogue box to input the parameters. Each step has a "Next" button which submits the data to the server using an AJAX call. The code snippet below shows the Javascript function for submitting the data for the second step.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | function submitFeaturesStep2(formID) { var formData = {}; var mode = $('input[name="fstep2-mode"]:checked').val(); formData['mode'] = mode; // Retrieve values of advanced options if applicable if (mode === 'advanced') { if (!validateForm(formID)) { document.getElementById(formID).reportValidity(); return false; } formData['filterStr'] = $('#discardInput').val(); formData['retainStr'] = $('#retainInput').val(); formData['nSignificant'] = $('#nSignificantInput').val(); } $('#ml-model-buttons-2').children().first().removeClass('d-none'); $('#ml-model-buttons-2').children().eq(2).attr('disabled', 'true'); $.ajax({ type: 'POST', url: '/features-step2', contentType: 'application/json;charset=UTF-8', data: JSON.stringify(formData), success: function(response) { $('#ml-model-buttons-2').children().first().addClass('d-none'); $('#ml-model-buttons-2').children().eq(2).removeAttr('disabled'); messages = response['messages']; displayMessagesInField('mstep1-messages', messages); modelStep1(); }, error: function(error) { $('#ml-model-buttons-2').children().first().addClass('d-none'); $('#ml-model-buttons-2').children().eq(2).removeAttr('disabled'); // Abort and show error message showToast('toast-error', 'Error: see console.'); } }); // Prevent default form submission return false;} |
function submitFeaturesStep2(formID) {
var formData = {};
var mode = $('input[name="fstep2-mode"]:checked').val();
formData['mode'] = mode;
// Retrieve values of advanced options if applicable
if (mode === 'advanced') {
if (!validateForm(formID)) {
document.getElementById(formID).reportValidity();
return false;
}
formData['filterStr'] = $('#discardInput').val();
formData['retainStr'] = $('#retainInput').val();
formData['nSignificant'] = $('#nSignificantInput').val();
}
$('#ml-model-buttons-2').children().first().removeClass('d-none');
$('#ml-model-buttons-2').children().eq(2).attr('disabled', 'true');
$.ajax({
type: 'POST',
url: '/features-step2',
contentType: 'application/json;charset=UTF-8',
data: JSON.stringify(formData),
success: function(response) {
$('#ml-model-buttons-2').children().first().addClass('d-none');
$('#ml-model-buttons-2').children().eq(2).removeAttr('disabled');
messages = response['messages'];
displayMessagesInField('mstep1-messages', messages);
modelStep1();
},
error: function(error) {
$('#ml-model-buttons-2').children().first().addClass('d-none');
$('#ml-model-buttons-2').children().eq(2).removeAttr('disabled');
// Abort and show error message
showToast('toast-error', 'Error: see console.');
}
});
// Prevent default form submission
return false;
}
The server-side function receives the data from the front-end and runs the respective function for that step of model training. It returns any messages to be displayed at the next step of training.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 | @app.route('/features-step2', methods=['POST'])def features_step2(): global global_variables data = request.get_json() mode = data['mode'] if mode == 'auto': messages = global_variables.model_page.manually_select_features() pass elif mode == 'advanced': filterStr = data['filterStr'] retainStr = data['retainStr'] nSignificant = int(data['nSignificant']) messages = global_variables.model_page.manually_select_features(filterStr, retainStr, nSignificant) return jsonify({'messages': messages}) |
@app.route('/features-step2', methods=['POST'])
def features_step2():
global global_variables
data = request.get_json()
mode = data['mode']
if mode == 'auto':
messages = global_variables.model_page.manually_select_features()
pass
elif mode == 'advanced':
filterStr = data['filterStr']
retainStr = data['retainStr']
nSignificant = int(data['nSignificant'])
messages = global_variables.model_page.manually_select_features(filterStr, retainStr, nSignificant)
return jsonify({'messages': messages})
When training is complete, training results are updated and displayed on the page using an AJAX request to retrieve the results. This includes a classification report, a confusion matrix, and 2 graphs displaying the training loss and training accuracy. These graphs are interative and created with Chart.js; the user can zoom in and out of the graphs to view them in greater detail.
The user can also choose a file to identify by searching by a range of dates. The server sends a similar AJAX request to the server and receives the identification results, which are displayed in a bar chart.
History page
When the user opens the history page, the Flask application routes the
/history URL to run the function history to display the page. The history database is read from the CSV file stored at the path specified in constants.py as HISTORY_DB_PATH. The user can search for records by entering a query in the search bar, selecting a date range, and choosing to search by the CSV name or scent IDs in results. The query is submitted via a GET request to the same URL, which then carries out the relevant search to get the results. If there is no query, the results are simply the entire database (retrieved via the readDB method). The results from the database are passed into the Jinja placeholders in the HTML file, which then dynamically populates the table in the UI with the records from the database (shown below). 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 | @app.route('/history', methods=['GET'])def history(): db = db_handler.IdentifiedDBHandler(HISTORY_DB_PATH) query = request.args.get('query') startDate = request.args.get('startDate') endDate = request.args.get('endDate') searchType = request.args.get('searchType') if searchType == "date": startDate = startDate.replace("T", "-").replace(":", "-") endDate = endDate.replace("T", "-").replace(":", "-") results = db.searchByDate(startDate, endDate) elif searchType == "scent": results = db.searchByField(query, False, True, False) else: results = db.readDB() return render_template('history.html', data=results) |
@app.route('/history', methods=['GET'])
def history():
db = db_handler.IdentifiedDBHandler(HISTORY_DB_PATH)
query = request.args.get('query')
startDate = request.args.get('startDate')
endDate = request.args.get('endDate')
searchType = request.args.get('searchType')
if searchType == "date":
startDate = startDate.replace("T", "-").replace(":", "-")
endDate = endDate.replace("T", "-").replace(":", "-")
results = db.searchByDate(startDate, endDate)
elif searchType == "scent":
results = db.searchByField(query, False, True, False)
else:
results = db.readDB()
return render_template('history.html', data=results)
Scent database page
The scent database can be viewed at the
/scent-database URL, which routes to the database function in app.py. This function retrieves the database with a ScentDBHandler object, carrying out the relevant search based on the GET request parameters. The results are passed into the Jinja placeholders in the HTML file, which then dynamically populates the table in the UI with the records from the database (shown below).01 02 03 04 05 06 07 08 09 10 11 12 13 | @app.route('/scent-database', methods=['GET'])def database(): db = db_handler.ScentDBHandler(SCENT_DB_PATH) query = request.args.get('query') id = True if request.args.get('id') else False name = True if request.args.get('name') else False if query: results = db.searchByField(query, id, name) else: results = db.readDB() return render_template('scent-database.html', data=results) |
@app.route('/scent-database', methods=['GET'])
def database():
db = db_handler.ScentDBHandler(SCENT_DB_PATH)
query = request.args.get('query')
id = True if request.args.get('id') else False
name = True if request.args.get('name') else False
if query:
results = db.searchByField(query, id, name)
else:
results = db.readDB()
return render_template('scent-database.html', data=results)
Machine Learning Implementation
Machine Learning Package
Using the same machine learning scripts that were used for research and environment testing, we packaged them into 3 distinct classes to offer users a streamlined process accessible from the UI, simplifying the traditionally complex feature extraction and training process to achieve a generally applicable package to identify compounds in the environment. FeatureSelector handles initial feature selection and relevance calculations to allow filtering of features obtained from the raw readings during data collection. ModelTrainer then handles pre-processing, training, and validation. These two classes are instances of the ModelPage class, which is an interface to access the processes either through Jupyter Notebook for testing or the frontend of the UI to package the functionalities into simplified steps. For
Feature Selector
It consists of the
The
The
The
The
Model Trainer
The
The ModelPage class is an interface that holds the instances and provides a simpler access to the FeatureSelector and ModelTrainer classes, which is accessed directly by the frontend. It provides guardrail checks before calling the functions from the relevant classes, and passes any relevant information between the FeatureSelector and ModelTrainer. The more notable functions are listed below:
Using the same machine learning scripts that were used for research and environment testing, we packaged them into 3 distinct classes to offer users a streamlined process accessible from the UI, simplifying the traditionally complex feature extraction and training process to achieve a generally applicable package to identify compounds in the environment. FeatureSelector handles initial feature selection and relevance calculations to allow filtering of features obtained from the raw readings during data collection. ModelTrainer then handles pre-processing, training, and validation. These two classes are instances of the ModelPage class, which is an interface to access the processes either through Jupyter Notebook for testing or the frontend of the UI to package the functionalities into simplified steps. For
FeatureSelector and ModelTrainer, their functions return messages containing a list of strings, the relevant information specifying what actions were performed based on the input parameters. This is to give both users and data analysts a clear view of operations at every stage to ensure the expected behavior.
Feature Selector
It consists of the
FeatureSelector class which handles feature selection as well as feature relevance calculations, allowing user a view at the significance of each feature for their particular classification task. This allows users to filter features as they see fit, potentially lowering the compute requirements of the classification task by only retaining relevant features for the task at hand without sacrificing accuracy.The
load function takes resistance_features_raw_path and labels_path to the csv files as parameters. resistance_features_raw_path consists of columns of features and rows of the corresponding values of the samples, while labels_path contains a list of the scent classes used for identification. This function must be called at least once, but can be called for as many times as necessary to load additional features and the labels into the class attributes, mainly for cases where additional training to an existing model is needed or when the user wishes to compare multiple files from different data collection sessions. Some preliminary checks include checking the lengths of the files match, and discarding duplication. Otherwise it stores the csv files as pandas DataFrames and Series for further processing, and returns relevant information such as class distribution. It also immediately calls the get_feature_relevance function, as it is necessary immediately after loading raw files.The
get_feature_relevance function takes no parameters, and gets the pandas DataFrame of feature relevance table using the calculate_relevance_table function in the tsfresh library, returning the p-value of each feature for the classification task at hand. This is stored as the original_features_relevance_table and original_relevant_columns as class attributes, used for filtering by users later on. original_features_relevance_table will contain the columns below, while the original_relevant_columns stores only the names of the features of DataFrames later.
feature,type,p_value_1,relevant_1,p_value_4,relevant_4,p_value_3,relevant_3,p_value_2,relevant_2,n_significant,relevant
The
manually_select_features function takes in optional parameters for final filtering before the data is sent to ModelTrainer for preprocessing. Its results will be stored in the filtered_features_relevance_tables and the filtered_features_columns, instead of the original. This step is necessary as the filtered tables and columns are used for preprocessing later, not the original. It must be called at least once but can be called for however many times necessary by the user. The four parameters are criteria for filtering:
filter_string-- string to filter out featuresretain_string-- string to retain featuresn_significant-- minimum number of classes that a feature must be relevant to to be retainedfrom_original-- whether to select from the original features relevance table, or use already filtered attributes for finer filtering
n_significant is by far the most useful parameter to determine the size of the dataset used to train the model, and is hence an important attribute to balance model complexity and accuracy. Below is a code snippet illustrating how the input parameters are used to filter existing DataFrames stored as class attributes:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | def manually_select_features( self, filter_string: str = None, retain_string: str = None, n_significant: Optional[int] = 1, from_original: Optional[bool] = True,): """Provided strings, select features. Filter string disregards all features which contain the filter string. Retain string disregards all features which do not contain the retain string. Arguments: filter_string -- string to filter out features retain_string -- string to retain features n_significant -- minimum number of classes that a feature must be relevant to to be retained from_original -- whether to select from the original features relevance table """ if ( self.original_features_relevance_table is None or self.original_relevant_columns is None ): self.get_feature_relevance() if n_significant < 1 or n_significant > len(self.classes): raise RequireFeedbackException( f"Feature selector -- manually_select_features: n_significant must be between 1 and the number of classes ({len(self.classes)}). {n_significant} not in range." ) self.n_significant = n_significant if from_original: length_before = self.original_relevant_columns.shape[0] if retain_string is not None: relevant_columns = self.original_relevant_columns[ self.original_relevant_columns.str.contains( retain_string, case=False ) ] elif filter_string is not None: relevant_columns = self.original_relevant_columns[ ~self.original_relevant_columns.str.contains( filter_string, case=False ) ] else: relevant_columns = self.original_relevant_columns |
def manually_select_features(
self,
filter_string: str = None,
retain_string: str = None,
n_significant: Optional[int] = 1,
from_original: Optional[bool] = True,
):
"""Provided strings, select features. Filter string disregards all features
which contain the filter string. Retain string disregards all features which
do not contain the retain string.
Arguments:
filter_string -- string to filter out features
retain_string -- string to retain features
n_significant -- minimum number of classes that a feature must be relevant to to be retained
from_original -- whether to select from the original features relevance table
"""
if (
self.original_features_relevance_table is None
or self.original_relevant_columns is None
):
self.get_feature_relevance()
if n_significant < 1 or n_significant > len(self.classes):
raise RequireFeedbackException(
f"Feature selector -- manually_select_features: n_significant must be between 1 and the number of classes ({len(self.classes)}). {n_significant} not in range."
)
self.n_significant = n_significant
if from_original:
length_before = self.original_relevant_columns.shape[0]
if retain_string is not None:
relevant_columns = self.original_relevant_columns[
self.original_relevant_columns.str.contains(
retain_string, case=False
)
]
elif filter_string is not None:
relevant_columns = self.original_relevant_columns[
~self.original_relevant_columns.str.contains(
filter_string, case=False
)
]
else:
relevant_columns = self.original_relevant_columns
The FeatureSelector class also has save and load functions. When provided a path, it saves or loads the necessary attributes to recreate the class using only the saved files, which is called by ModelPage for loading previous sessions or saving current session for analysis or further training at a later date. This is to minimize the chance of alterations to the scent database later affecting the work from previous sessions be unrecreatable. The format in which the files are saved is shown below:
Parameter,Value
resistance_features_raw_path,resistance_features.csv
labels_path,labels.csv
original_features_relevance_table_path,original_features_relevance_table.csv
original_relevant_columns_path,original_relevant_columns.csv
filtered_features_relevance_table_path,filtered_features_relevance_table.csv
filtered_relevant_columns_path,filtered_relevant_columns.csv
n_significant,3
The
feature_selector_attributes.csv file simply stores the paths and n_significance for analysis at a later date.
Model Trainer
The
ModelTrainer class contains all the attributes necessary to restart or continue model training, when given the DataFrame of the original data and the list of features to use for training. Its attributes are shown in the following code snippet:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | # Saved attributesself.attributes = { "date_created": None, "data_modified": None, # Training data "X_train": None, "X_test": None, "y_train": None, "y_test": None, "classes": None, "scent_to_class_map": None, "class_to_scent_map": None, "relevant_features_column": None, # Model "block_config": None, "model": None, # Hyperparameters "lr": None, "optimizer": None, "loss_fn": None, "epochs": None, "batch_size": None, "weight_decay": None, "device": None, "epoch_per_validation": 1, # Metrics "epoch_losses": [], "epoch_test_accuracy": [], "highest_accuracy": 0, "epoch_of_highest_accuracy": 0, "classification_reports": [], "confusion_matrices": [],}# Temp attributesself.temp_best_model, self.temp_best_optimizer = None, Noneself.train_loader, self.test_loader = None, Noneself.training_progress = []self.finished_training = False |
# Saved attributes
self.attributes = {
"date_created": None,
"data_modified": None,
# Training data
"X_train": None,
"X_test": None,
"y_train": None,
"y_test": None,
"classes": None,
"scent_to_class_map": None,
"class_to_scent_map": None,
"relevant_features_column": None,
# Model
"block_config": None,
"model": None,
# Hyperparameters
"lr": None,
"optimizer": None,
"loss_fn": None,
"epochs": None,
"batch_size": None,
"weight_decay": None,
"device": None,
"epoch_per_validation": 1,
# Metrics
"epoch_losses": [],
"epoch_test_accuracy": [],
"highest_accuracy": 0,
"epoch_of_highest_accuracy": 0,
"classification_reports": [],
"confusion_matrices": [],
}
# Temp attributes
self.temp_best_model, self.temp_best_optimizer = None, None
self.train_loader, self.test_loader = None, None
self.training_progress = []
self.finished_training = False
-
pre_process_data- Given a pandas DataFrame of the features for every sample, and the Series of features to retain, filter the DataFrame by the features to include. Then, it transforms the features DataFrame and labels Series into numpy arrays, which are then standardised to reduce sensor and session variability. It is then split into training and testing sets according to the input parameter test_size, and stored as pytorch Tensors as class attributes X_train. Additionally, the function creates a scent_to_class_map< and class_to_scent_map to map between the scent number and integer class, as there may be discrepancies between how the scents are numbered, and strict integer classes starting from 0 are necessary for training. It returns the relevant information such as test size and number of samples back to the user.
-
get_block_config- Given an integer number, it generates the configuration that is a list of tuples of (input_dim, hidden_dim, output_dim) to create the neural network with. The model aims to half the number of dimensions at each block, while the function makes sure that the first input_dim matches the number of features, and the last output_dim matches that of the number of classes, and any input_dim and their preceding output_dim must match in dimensions. The configuration is stored as a class attribute block_config.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | def get_block_config(): ... scale_inverse = 4 block_config = [ ( features, max(1, (features - classes) // scale_inverse), ( classes if blocks == 1 else max(1, (features - classes) // scale_inverse) ), ) ] for block in range(1, blocks): input_dim = block_config[block - 1][-1] hidden_dim = input_dim // 2 if block == blocks - 1: output_dim = classes else: output_dim = hidden_dim block_config.append((input_dim, hidden_dim, output_dim)) ( messages.extend( [ f"Selected {blocks} blocks for {features} features.", f"Each block will aim to half the dimensions at each layer.", ] ) if blocks else None ) # List[tuple(input_dim, hidden_dim, output_dim)] self.attributes["block_config"] = block_config messages.extend( [ f"Block configuration set: (input_dim, hidden_dim, output_dim): {block_config}" ] ) return messages |
def get_block_config():
...
scale_inverse = 4
block_config = [
(
features,
max(1, (features - classes) // scale_inverse),
(
classes
if blocks == 1
else max(1, (features - classes) // scale_inverse)
),
)
]
for block in range(1, blocks):
input_dim = block_config[block - 1][-1]
hidden_dim = input_dim // 2
if block == blocks - 1:
output_dim = classes
else:
output_dim = hidden_dim
block_config.append((input_dim, hidden_dim, output_dim))
(
messages.extend(
[
f"Selected {blocks} blocks for {features} features.",
f"Each block will aim to half the dimensions at each layer.",
]
)
if blocks
else None
)
# List[tuple(input_dim, hidden_dim, output_dim)]
self.attributes["block_config"] = block_config
messages.extend(
[
f"Block configuration set: (input_dim, hidden_dim, output_dim): {block_config}"
]
)
return messages
-
construct_model- Given the block_config of the class, the Net class is constructed by sequentially adding smaller Block networks with the dimensions specified by the block_config. the total parameters and information on the model architecture is returned to the user.
-
prep_training- Creates the optimizer, DataLoaders, and cost function used for training with the specified input parameters, which is then stored as a class attribute for later use.
01 02 03 04 05 06 07 08 09 10 | def prep_training( self, optimizer: Optional[str] = "adam", lr: Optional[float] = 0.001, epochs: Optional[int] = 200, batch_size: Optional[int] = 32, weight_decay: Optional[float] = 0.01, epoch_per_validation: Optional[int] = 10, ): ... |
def prep_training(
self,
optimizer: Optional[str] = "adam",
lr: Optional[float] = 0.001,
epochs: Optional[int] = 200,
batch_size: Optional[int] = 32,
weight_decay: Optional[float] = 0.01,
epoch_per_validation: Optional[int] = 10,
):
...
-
train_model- After the prerequisites are met, the model is trained for the specified number of epochs, and validated every number of epochs as defined by the epoch_per_validation. It stores all the metrics in class attributes for later analysis. self.finished_training is a boolean used by other threads on the front end to check if the training is complete, and fetches most recent training information while training is underway.
-
validate- Switches the model to evaluation mode to ensure no gradient information is stored to minimize memory usage, then tests the performance of the model using the test dataset. A copy of the state dictionary and results of the validation are separately stored if the accuracy is the highest of the training run, for later display and model saving.
-
save and load
- The model saves all necessary class attributes in a pytorch .pt file to ensure training can be continued and inferences can be made at anytime with the saved attributes, simply by instantiating a new ModelTrainer class and loading the saved attributes. The attributes are also used to display metrics by the ModelPage when the user browses through the UI. Only the state dictionary of the model is saved, along with the configuration, instead of the entire model along with its weights. This results in longer load time but ensures the model does not take up more space than necessary.
The ModelPage class is an interface that holds the instances and provides a simpler access to the FeatureSelector and ModelTrainer classes, which is accessed directly by the frontend. It provides guardrail checks before calling the functions from the relevant classes, and passes any relevant information between the FeatureSelector and ModelTrainer. The more notable functions are listed below:
-
alter_block_config- Replace the current block configuration in ModelTrainer with a new one, by either specifying the number of blocks, or directly altering the block configuration. It uses the get_block_config function from ModelTrainer when an integer number of blocks are specified, or operate directly on the specified block_config that is a list of tuples of (input_dim, hidden_dim, output_dim) for advanced configuration. It also checks that the dimensions provided are correct.
-
train_model- checks the prerequisites to model training before beginning training on a separate thread. This is so that it can check for the training progress in the meanwhile using self.model_trainer.finished_training and self.model_trainer.training_progress, storing the most recent information in self.temp_messages for access by the frontend.
-
plot_metrics- Creates the metrics to display on the front end after training, by returning the x and y values of the training loss and testing loss in the format the frontend expects, also calculating the correct epochs to display according to ModelTrainer's epochs_per_validation. The metrics returned are shown below:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 | { "train_loss_x": train_loss_x, "train_loss_y": self.model_trainer.attributes["epoch_losses"], "test_accuracy_x": train_loss_x, "test_accuracy_y": self.model_trainer.attributes["epoch_test_accuracy"], "classification_report": self.model_trainer.attributes[ "classification_reports" ][self.model_trainer.attributes["epoch_of_highest_accuracy"] - 1].split( "\n" ), "confusion_matrix": self.model_trainer.attributes["confusion_matrices"][ self.model_trainer.attributes["epoch_of_highest_accuracy"] - 1 ].tolist(),} |
{
"train_loss_x": train_loss_x,
"train_loss_y": self.model_trainer.attributes["epoch_losses"],
"test_accuracy_x": train_loss_x,
"test_accuracy_y": self.model_trainer.attributes["epoch_test_accuracy"],
"classification_report": self.model_trainer.attributes[
"classification_reports"
][self.model_trainer.attributes["epoch_of_highest_accuracy"] - 1].split(
"\n"
),
"confusion_matrix": self.model_trainer.attributes["confusion_matrices"][
self.model_trainer.attributes["epoch_of_highest_accuracy"] - 1
].tolist(),
}
-
identify- Identifies the scents which are present in the environment when provided the path to a features.csv file. It first checks if the provided features contain the ones used by the trained model, then scales and transforms the data into tensors in the expected format, and gets the prediction of the model in inference mode. It then maps the predicted classes back to the scent classes and returns the predictions as an array.
-
easy_train- Runs all the functionalities in ModelPage to self.plot_metrics, in the order that is expected when provided the features_raw_path and labels_path. It uses default values but allows additional parameters for configurability. This provides the users a convenient one-click option to get a suitable algorithm for the provided data, but is also used for research purposes in JupyterNotebook.
Database Implementation
We have three main databases. Each database is stored in a CSV file. The paths for these files are configurable and can be set in the
Each of the three Python classes inherit from a parent class,
Scent Database
constants.py file. The details of each database are summarised in this table:| Database | Path | Python Class |
|---|---|---|
| Scent | scent_db.csv | ScentDBHandler |
| Model | model_db.csv | ModelDBHandler |
| History | history.csv | IdentifiedDBHandler |
Each of the three Python classes inherit from a parent class,
DatabaseHandler. This is an abstract class which defines the required methods for all the database classes. It also defines the function readDB() which returns the entire database as a 2-dimensional array, when the entire database's records are required by another function.
All known scents are stored in a database
When the front-end needs to read from the database, a
The
Each scent has a unique ID number. This ID is assigned when the scent is added to the database, using the
The
To search by all fields, the user can call the
To rename a scent, the user can also use the
Model Database
scent_db.csv. Each scent is stored in a new line, in the format scent_id|scent_name.When the front-end needs to read from the database, a
ScentDBHandler object is created. The initialisation method __init__ of the class reads from the database, splitting the data by the delimiter | into a two-dimensional array, where each sub-array is a single record.01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 | def __init__(self, databaseName): self.db = [] self.databaseName = databaseName try: with open(databaseName, 'r') as f: for line in f: newData = line.strip().split('|') self.db.append(newData) except FileNotFoundError: print(f"Database file '{databaseName}' not found. Creating new file.") with open(databaseName, 'w') as f: pass print("Initialised scent database") except Exception as e: raise Exception( f"ScentDBHandler - error initialising database from file '{databaseName}'. Details: {e}" ) |
def __init__(self, databaseName):
self.db = []
self.databaseName = databaseName
try:
with open(databaseName, 'r') as f:
for line in f:
newData = line.strip().split('|')
self.db.append(newData)
except FileNotFoundError:
print(f"Database file '{databaseName}' not found. Creating new file.")
with open(databaseName, 'w') as f:
pass
print("Initialised scent database")
except Exception as e:
raise Exception(
f"ScentDBHandler - error initialising database from file '{databaseName}'. Details: {e}"
)
The
ScentDBHandler class saves any changes made to the database file by calling the writeDB method. This method writes the entire database, stored in the self.db attribute, to the CSV file, overwriting the existing file. The method is called after any changes are made to the database, such as adding, deleting or editing a scent.01 02 03 04 05 06 07 08 09 10 | def writeDB(self): try: with open(self.databaseName, 'w') as f: for record in self.db: f.write("|".join(record) + '\n') except Exception as e: raise Exception( f"ScentDBHandler - error writing to database file. Details: {e}" ) |
def writeDB(self):
try:
with open(self.databaseName, 'w') as f:
for record in self.db:
f.write("|".join(record) + '\n')
except Exception as e:
raise Exception(
f"ScentDBHandler - error writing to database file. Details: {e}"
)
Each scent has a unique ID number. This ID is assigned when the scent is added to the database, using the
add method. Each time a new scent is added, the new ID is assigned by incrementing the last ID added in the database by one (i.e. the new ID is the number of records in the database after adding the new scent).
01 02 03 04 05 06 07 08 09 10 11 | def add(self, name): try: id = str(len(self.db) + 1) self.db.append([id, name]) self.writeDB() return id except Exception as e: raise Exception( f"ScentDBHandler - error adding scent {name} to database. Details: {e}" ) |
def add(self, name):
try:
id = str(len(self.db) + 1)
self.db.append([id, name])
self.writeDB()
return id
except Exception as e:
raise Exception(
f"ScentDBHandler - error adding scent {name} to database. Details: {e}"
)
The
ScentDBHandler class also has a method searchByField which searches for a scent by a given field. The method takes in a query key and booleans to allow the user to specify which fields to include in the search. It also takes a boolean exact which specifies whether the search results should be an exact match to the given query; this is set to False by default. The search results are then returned as a 2-dimensional array, with each record in the results stored as a sub-array.To search by all fields, the user can call the
search method, which simply calls the searchByField method with all fields included in the search.01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | def searchByField(self, key, id, name, exact=False): try: results = [] for record in self.db: if exact: if id and key == record[0]: results.append(record) elif name and key == record[1]: results.append(record) else: if id and key in record[0]: results.append(record) elif name and key.lower() in record[1].lower(): results.append(record) return results except Exception as e: raise Exception( f"ScentDBHandler - error searching for '{key}'. Details: {e}" ) def search(self, key): return self.searchByField(key, True, True) |
def searchByField(self, key, id, name, exact=False):
try:
results = []
for record in self.db:
if exact:
if id and key == record[0]:
results.append(record)
elif name and key == record[1]:
results.append(record)
else:
if id and key in record[0]:
results.append(record)
elif name and key.lower() in record[1].lower():
results.append(record)
return results
except Exception as e:
raise Exception(
f"ScentDBHandler - error searching for '{key}'. Details: {e}"
)
def search(self, key):
return self.searchByField(key, True, True)
To rename a scent, the user can also use the
updateName method, which takes in the scent's ID and the new name. The method first searches for the scent by the given ID, then updates the name of the scent in the database by deleting the old record and adding the updated one.01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 | def updateName(self, id, name): try: results = self.searchByField(id, True, False) if results != []: results = results[0] results[1] = name self.delete(id) self.db.append(results) self.writeDB() else: raise Exception( f"ScentDBHandler - error updating name for scent ID {id}. Scent ID not found." ) except Exception as e: raise Exception( f"ScentDBHandler - error updating scent name for scent ID {id}. Details: {e}" ) |
def updateName(self, id, name):
try:
results = self.searchByField(id, True, False)
if results != []:
results = results[0]
results[1] = name
self.delete(id)
self.db.append(results)
self.writeDB()
else:
raise Exception(
f"ScentDBHandler - error updating name for scent ID {id}. Scent ID not found."
)
except Exception as e:
raise Exception(
f"ScentDBHandler - error updating scent name for scent ID {id}. Details: {e}"
)
All models created by the user are stored in a database
When the front-end needs to read from the database, a
History Database
model_db.csv. Each scent is stored in a new line, in the format model_id|model_name|date_last_updated.When the front-end needs to read from the database, a
ModelDBHandler object is created. It has the following methods which are implemented similarly to the ScentDBHandler class:
__init__: Initialisation methodwriteDB: Writes database to CSV fileadd: Adds new model with specified name and date updatedsearchByField: Search for a record by fields (any combination of ID, name or date)search: Search by all fieldsupdateName: Edits the name of the model and updates the "last updated" date
The history database stores all identification results from the user. The database is stored in a CSV file named
When the front-end needs to read from the database, an
The
The
history_db.csv. Each record in the database is stored in the format csv_name|result|model_id|date_identified, where result is a string of scent IDs concatenated together with commas between each ID (i.e. scent_id1,scent_id2,...).When the front-end needs to read from the database, an
IdentifiedDBHandler object is created. It has the following methods which are implemented similarly to the ScentDBHandler class:
__init__: Initialisation methodwriteDB: Writes database to CSV fileadd: Adds new model with specified name and date updatedsearch: Search by all fieldsupdateName: Edits the name of the model and updates the "last updated" date
The
searchByField method allows the user to search for an identification result by query key in any combination of fields. It takes in booleans to allow the user to specify which fields to include in the search (CSV name, result and model used). If searching by the result, the method checks if the query is found in any of the scent IDs in the result string. If searching by the model used, the method searches the model database to find matches for the model name, creating an array storing the IDs of any matches. It then looks for matches of the model IDs in the array to the records in the history database. The search results are returned as a 2-dimensional array, with each record in the results stored as a sub-array.01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | def searchByField(self, key, csv_name, result, model_used): try: results = [] if model_used: modelDB = ModelDBHandler(MODEL_DB_PATH) modelNames = modelDB.searchByField(key, False, True, False) for record in self.db: if csv_name and key in record[0]: results.append(record) elif result and key in record[1]: results.append(record) elif model_used: for name in modelNames: if key in name: results.append(record) return results except Exception as e: raise Exception( f"IdentifiedDBHandler - error searching for '{key}'. Details: {e}" ) |
def searchByField(self, key, csv_name, result, model_used):
try:
results = []
if model_used:
modelDB = ModelDBHandler(MODEL_DB_PATH)
modelNames = modelDB.searchByField(key, False, True, False)
for record in self.db:
if csv_name and key in record[0]:
results.append(record)
elif result and key in record[1]:
results.append(record)
elif model_used:
for name in modelNames:
if key in name:
results.append(record)
return results
except Exception as e:
raise Exception(
f"IdentifiedDBHandler - error searching for '{key}'. Details: {e}"
)
The
searchByDate method allows the user to search for identification records between two dates. Since all dates are stored in the format dd-MM-yyyy-hh-mm-ss, the method compares the string for the date identified to the strings for the start and end dates to determine if the record is in the range specified. The results are returned similarly to the other search functions, in a 2-dimensional array.01 02 03 04 05 06 07 08 09 10 11 12 | def searchByDate(self, startDate, endDate): try: results = [] for record in self.db: if startDate <= record[0] <= endDate: results.append(record) return results except Exception as e: raise Exception( f"IdentifiedDBHandler - error searching for records between {startDate} and {endDate}. Details: {e}" ) |
def searchByDate(self, startDate, endDate):
try:
results = []
for record in self.db:
if startDate <= record[0] <= endDate:
results.append(record)
return results
except Exception as e:
raise Exception(
f"IdentifiedDBHandler - error searching for records between {startDate} and {endDate}. Details: {e}"
)