Technology Review
- Spotify
- Youtube
- System Audio
- Platform & Framework
- AI & Models
- Summary of Technical Decisions
Spotify
Selecting the right audio technology was a critical aspect of our project, as it directly influenced the user experience and the system’s ability to provide an immersive and interactive environment. Our goal was to integrate a flexible, scalable, and legally compliant solution that allowed users to bring their own music into the system while ensuring smooth playback and real-time interaction.
Originally, we planned on integrating with Spotify to allow users to select songs from their vast library. We chose Spotify initially due to our team’s prior familiarity with its Web APIs and robust playback features.
Our first approach involved using Spotify’s Web Playback Software Developer Kit (SDK), which enables applications to function as standalone Spotify playback devices, similar to native Spotify apps [1]. During the early stages of our project, we successfully built a prototype using React that ran smoothly within a browser environment, complete with full login, authentication, and credential management.
However, when transitioning this functionality to our final Electron-based desktop application, we encountered significant issues. While the majority of Spotify’s APIs functioned as intended, playback consistently failed, returning a “Playback Error 500,” an error that Spotify’s documentation indicated should not occur under normal circumstances [2].
Further investigation revealed that this playback error was due to Spotify’s implementation of Widevine, a Content Decryption Module (CDM) developed by Google for Digital Rights Management (DRM). Spotify utilises Widevine to protect its audio streams from unauthorised access by securely decrypting audio in-browser environments such as Google Chrome, which has native Widevine support [3]. Electron, however, lacks native Widevine support, resulting in playback failing due to Spotify’s DRM restrictions. Attempts to manually integrate Widevine into Electron using a specialised Electron fork (Cast Labs) [4] were partially successful—audio would briefly play (approximately 30 seconds) before Spotify’s strict playback environment checks led to playback abruptly stopping, causing additional unpredictable behaviours like phantom skipping of songs. Consequently, Spotify’s Web Playback SDK proved unusable for our executable desktop application.
As an alternative, we explored leveraging Spotify’s native application as the primary player, synchronising our visuals via their Web API using the Audio Features and Audio Analysis endpoints. These endpoints would have provided real-time song information, such as beats and musical features, to control aspects of our sensory room (e.g., lighting). Unfortunately, Spotify deprecated these critical API endpoints in November 2024, citing their intention to build a more secure platform [5]. Despite Spotify promising replacement endpoints within a week of the announcement [6], four months have since elapsed without any new API releases.
Due to these persistent technical barriers, we ultimately abandoned Spotify integration. We instead pivoted towards a solution involving custom audio analysis performed on songs downloaded from YouTube, uploaded directly to our application, or recorded from system audio. This alternative provided greater flexibility, reliability, and overall control over the sensory experience.
References
[1] Spotify. “Web Playback SDK | Spotify for Developers.” Accessed: Mar. 22, 2025. [Online]. Available: https://developer.spotify.com/documentation/web-playback-sdk
[2] Spotify. “API calls | Spotify for Developers.” Accessed: Mar. 22, 2025. [Online]. Available: https://developer.spotify.com/documentation/web-api/concepts/api-calls
[3] Google. “Widevine DRM - Google Widevine.” Accessed: Mar. 22, 2025. [Online]. Available: https://www.widevine.com
[4] Cast Labs. “electron-releases: CastLabs Electron for Content Security.” Accessed: Mar. 22, 2025. [Online]. Available: https://github.com/castlabs/electron-releases
[5] Spotify. “Introducing some changes to our Web API | Spotify for Developers.” Accessed: Mar. 22, 2025. [Online]. Available: https://developer.spotify.com/blog/2024-11-27-changes-to-the-web-api
[6] Spotify Community. “About the latest changes to current Web APIs (Deprecations).” Accessed: Mar. 22, 2025. [Online]. Available: https://community.spotify.com/t5/Spotify-for-Developers/About-the-latest-changes-to-current-Web-APIs-Deprecations/td-p/6547114
Youtube
After abandoning Spotify integration due to DRM restrictions and API deprecations, we pivoted towards YouTube as an alternative source for audio playback. Our approach involved using yt-dlp, a widely used open-source tool for downloading media from online platforms, in conjunction with FFmpeg, a powerful multimedia framework for processing and converting audio files. This allowed us to extract high-quality audio from YouTube videos, giving users the flexibility to bring their own content into the system.
While this method provided greater control, reliability, and compatibility compared to Spotify’s restrictive APIs, it also introduced legal challenges regarding the downloading and storage of copyrighted audio. To ensure compliance with legal and ethical standards, we ultimately decided to retain this functionality within the system for non-restricted content while exploring alternative methods. This led us to implement a recording feature, allowing users to capture audio directly from their device—offering a more legally compliant way to integrate music into the system.
References
[1] YouTube. “Terms of Service - YouTube.” Accessed: Mar. 23, 2025. [Online]. Available: https://www.youtube.com/static?template=terms
System Audio
To adhere to the legal Youtube requirements and expand on the possible songs past youtube, we researched into the possibility of taking an audio recording and pass that in as an mp3 file to the database.
One option was to use the hardware’s microphone to record live audio and record as an mp3, but this deteriorated the quality of the music a lot depending on the microphone quality and some desktop / laptops may not have a microphone by default.
As FFmpeg could convert most media types into any other, we realised that letting the user upload any audio file allowed the user flexibility to obtain the song in any way they like, be it recording live voice on phones or uploading their favourite custom song. To make it easier for them to record songs from the internet, we integrated the system audio recorder built into electron application.
Platforms
One of the most critical requirements for our project was that the application had to be an executable, meaning the chosen platform needed to support packaging and distribution as a standalone application. This requirement ruled out web-based solutions and influenced our evaluation of different frameworks. Additionally, the platform needed to handle real-time rendering, interactive UI components, and external hardware integration while maintaining stability and performance. Below, we compare these technologies, detailing why some were chosen while others were ultimately discarded.
-
UE5
Our initial choice for building the project was Unreal Engine 5 (UE5). As a powerful graphical engine widely used in the game industry, UE5 offered the potential to create highly appealing visuals. We explored its capabilities and found that it could render impressive visual effects that respond to music frequencies—making it a strong candidate for implementing our visualiser.
After several attempts, our team successfully developed fully functional, dynamic particle visuals. However, we encountered significant challenges when trying to integrate UE5 with other components of our system due to its limited compatibility. While the visuals produced closely aligned with our design goals, it proved extremely difficult to incorporate AI features and customisable components.
On top of that, the steep learning curve is also a challenge. UE5 mainly uses C++ and it could be time-consuming to learn and maintain the system due to the lack of experience with game engine within the team.
Lastly, UE5 is primarily designed for AAA games and high-end rendering tasks, which significantly increased the system requirements. This makes it less budget-friendly and may limit accessibility for our target users, such as clients with modest hardware or educational institutions.
-
Dear ImGui
As part of our initial exploration into Unreal Engine 5 (UE5) for real-time rendering, we researched Dear ImGui, a popular immediate-mode GUI library designed for high-performance applications. Given UE5’s focus on high-quality 3D rendering, we considered using Dear ImGui to build a lightweight, responsive user interface overlay that would allow for real-time parameter adjustments without affecting performance. Dear ImGui's low-latency, minimal-memory footprint made it an attractive option for developing interactive control panels within UE5, ensuring a seamless experience for users interacting with our system.
However, as our research progressed, we encountered several challenges. Dear ImGui, while excellent for debugging tools and in-engine controls, lacked the flexibility needed for a full-featured user interface. It was not well-suited for complex UI layouts, modern styling, or extensive user interaction, which became a significant limitation as our project evolved. Additionally, as we evaluated other platform options, such as MFC and Electron, it became clear that Dear ImGui’s immediate-mode rendering approach was not ideal for the final packaged application. Since we ultimately moved away from UE5 in favour of a different architecture, Dear ImGui was no longer a viable option, leading us to explore alternative UI frameworks better suited to our needs.
-
MFC
Following our initial exploration of UE5 and Dear ImGui, we considered MFC (Microsoft Foundation Classes) as a potential solution for developing a Windows-native executable. Given that our application required packaging as a standalone executable, MFC appeared to be a strong candidate due to its deep integration with Windows APIs, robust native performance, and long-standing use in enterprise applications. MFC offered a stable environment for building traditional desktop applications with direct access to Windows system resources, making it a compelling choice for handling UI elements, system-level interactions, and efficient hardware integration.
Despite its advantages, MFC’s limitations became apparent as our project requirements evolved. While it excels at building standard Windows applications, its outdated UI design, steep learning curve, and lack of modern flexibility made it less suitable for the interactive and visually rich experience we aimed to create. Additionally, while cross-platform compatibility was not a core requirement, some of our team members were developing on macOS, making it difficult to efficiently collaborate, test, and debug an MFC-based application. This led us to move forward and explore Electron, which provided a more modern, flexible, and scalable UI framework while still allowing us to package the application as an executable.
-
Electron
After evaluating UE5 with Dear ImGui and considering MFC, we ultimately chose Electron as the foundation for our application. Electron provided the perfect balance between customisability, modern UI capabilities, and the ability to package the application as a standalone executable, which was one of our most critical requirements. By leveraging web technologies (HTML, CSS, JavaScript) within a desktop environment, Electron allowed us to create a visually engaging, interactive, and feature-rich interface while maintaining complete control over audio processing, external hardware integration, and real-time rendering.
One of Electron’s biggest advantages was its developer-friendly ecosystem. Since many of our team members were already familiar with JavaScript/typescript and web development frameworks, transitioning to Electron allowed us to rapidly prototype, iterate, and refine the UI without the steep learning curve associated with MFC or Unreal Engine. Additionally, Electron’s vast library support made it easy to incorporate audio analysis, visualisation tools, and external device communication, ensuring we could seamlessly integrate features like Philips Hue lighting and real-time music-driven effects.
Another key reason for choosing Electron was its ease of development and testing across different machines. While cross-platform functionality was not a primary goal, some of our team members were working on macOS, making it difficult to efficiently collaborate with MFC, which is Windows-exclusive. Electron eliminated this friction, allowing the entire team to develop and test the application without compatibility issues.
Additionally, our application relied on AI models for LLM, Speech-to-Text (S2T), and Text-to-Image (T2I) functionalities. These required a platform that could seamlessly integrate and manage multiple AI-driven executables, making Electron a natural fit due to its flexibility in handling process management and external executables within a packaged environment. Electron did come with some trade-offs, such as higher memory usage compared to native applications and a reliance on Chromium, which can lead to performance overhead. However, given the scope of our project, these drawbacks were outweighed by the benefits of fast iteration, modern UI capabilities, and a robust development ecosystem. Ultimately, Electron enabled us to build an immersive, interactive, and packaged desktop application that met all of our core requirements without sacrificing flexibility or usability.
-
Three.js
After abandoning UE5 and Dear ImGui, our team began searching for more lightweight alternatives. We soon discovered Three.js, a library designed for rendering visuals in a web-based environment. Since we had already decided to build our application using Electron and React, Three.js was straightforward to integrate, thanks to its compatibility with HTML, CSS, and other JavaScript libraries. This made Three.js a more suitable choice compared to UE5.
As our research progressed, we also found that Three.js provides a variety of APIs—including
AudioLoaderandAudioAnalyser—that can simplify the creation of audio-reactive particle effects. These features offer a convenient way to implement real-time visual responses to music or sound input.Finally, Three.js is both more cost-effective and more accessible than UE5. Its open-source nature and lightweight architecture mean it can render smoothly on most modern devices, even those with limited hardware resources. This makes our application more user-friendly and helps ensure a broader reach for those with modest system capabilities.
AI
Our project required 3 different Generative AI (GenAI) types to be integrated for the following reasons:
- Large Language Model (LLM) to analyse the song and generate automatic
- Speech to Text Model (S2T) to extract the lyrics from the music file
- Text to Image Model (T2I) to generate automated background and shader generation for the music
Care was taken in choosing the correct models and platform for the music
Library & Programming Language
Our primary AI Solution was to use OpenVINO C++ library for both LLM and S2T models and python diffusers library for T2I.
OpenVINO C++ code was compiled with the aid of CMake & a dynamic OpenVINO library; python diffusers was compiled using pyinstaller.
This allowed the AI to function as multiple standalone executables as well as being optimised for the Intel hardware provided by our sponsor.
Below is a list of alternative languages / libraries we considered and reasons why we did not use them:
-
Javascript: Pros: idealistic option as our main framework was built on electron, which uses js or ts. Integrating our AI directly into these language would allow our data pipeline to be much cleaner.
- OpenVINO JS
- Pros: Created by our sponsor, Intel, so guaranteed to work on provided hardware
- Cons: Limited support for only simple Neural Network algorithms using tensor inputs. The official documentation was poorly documented and it was hard to figure out whether the necessary functions for running our GenAI model was ported
- Transformer JS
- Pros: supports ONNX and GGUF format, the 2 most widely used formats for representing GenAI models. The de-facto method when running AI on majority of websites so plenty of instructions and documentation. Supports multimodal inputs and computer vision / audio supported.
- Cons: primarily supported remote server-client based models. Due to our requirements, our AI had to work fully offline and on device
- WebLLM
- Pros: Very simple API and well documented + supported by the JS community for offline AI
- Cons: Required a browser-based data cache storage, which was hard to support in electron. Moreover the stable diffusion integration required WebGPU and was still in its beta process
- Final Decision: All libraries in Javascript had a significant flaw which was not suitable for our project. More critically, Running LLMs on JS was very slow, taking double the speed of most default AI programs
- OpenVINO JS
-
C++ libraries: Fast language and as target hardware specified in project specification, do not have to support multiple architectures in our product
- Llama Cpp
- Pros: Supports a large range of offline models, which was suitable for our product. Very well documented and plenty of sample code. De-facto method for running LLMs locally on machines.
- Cons: required opening a port and running internal server for AI functionality. only supports functionalities for LLM and does not support other GenAI features.
- Stable Diffusion Cpp
- Pros: out-of-package executable which runs Stable diffusion image generation on any machine.
- Cons: Very slow execution speed (around 20min per image) and very low quality images which rarely follow specified image prompts on low spec machines.
- OpenVINO C++
- Pros: optimised for intel hardware, documented to an extent. GenAI addon exists which allows any GenAI. Supports multiple Model types including computer vision and audio. Created their own OpenVINO Intermediate Representation (IR) format, optimised for inference and storage from openvino libraries.
- Cons: Most of document specific for python and little documentation specific for C++, requiring reference to library source code to understand library. Recommended Dynamic Library loading via OpenVINO toolkit installation rather than static compilation and barely any performance gains despite losing the flexibility of supporting multiple input model and hardware acceleration formats.
- Final Decision: despite having lack of documentation, OpenVINO C++ met the majority of our requirements. However, the T2I model gave a silent error which finished the program as soon as an instance was initialised. This bug was related to the library itself as the same effect happened on the sample models that Intel provided on their Github. Therefore, a separate library was required which supported T2I.
- Llama Cpp
-
Python Compilers
As the final product is required to run in a packaged application, we cannot run the native python code on the machines, requiring packages
- Nuitka: Compiler which converts the python code into an equivalent C code. Final executable is usually faster than the original code. However, not all libraries are supported with Nuitka and openvino was one of them.
- Pyinstaller: Packager which packages all required modules into a bundle and runs the python semi-natively from the final distribution. As it has to unpackage the libraries first, takes time to load the code in but execution time is the same as normal code.
Although both compilers worked to an extent, we chose pyinstaller for its simplisity for our project.
-
Other Python Image Generation libraries
-
OpenVINO GenAI
- Pros: Same provider of library as used in C++ so similar code can be used. A lot of documentation and samples acompanying this.
- Cons: Very hard to compile in both Nuitka & Pyinstaller as contains hidden dll file linkage that the game does not require
-
PyTorch
- Pros: Well suited for GenAI and flexible to use for a wealth of optimisation of the model itself. Huggingface integration and large community to ask for support.
- Cons: Contains a wealth of methods for multiple AI model formats so final executable with pyinstaller or nuitka is large (1-2GB).
-
Diffusers
- Pros: Developed by huggingface so default integration with huggingface models. Very simple API which allows for all inference settings involved with T2I generation. Library sise isn’t as large as majority of other. Works out of the box with Pyinstaller and Nuitka, without extra configuration
- Cons: Only supports Image generation. Does not allow model optimisation from its libray.
-
Final Decision: Diffusers as they provide the best balance between final binary size and ease of integration into our product. For this project, we did not have enough time to optimise the model itself so was not a necessary function of the library. The library just had to run the model at an acceptable standard
-
Models
Whilst choosing the best models for our program, there were a few considerations that were:
- Maximum size of 7GB, preferably 3GB: we intend to use 3 different models so we do not want the program to clog up too much of the user’s disk space
- Completely local: the models must have public weights so it can be run locally, there must be no api connections to external websites. Preferably open source models with free contracts.
- Runs comparatively well on CPU: the users may have limited hardware without GPUs or NPUs, the only hardware we may assume is an Intel CPU
Following these pre-requisites, I compared a few models to generate the following outputs that are require from:
- Generate unique colours that fit the song from the lyrics
- Extract and analyse unique objects and backgrounds from the lyrics
- Automatically generate prompts to be passed to the image generation model
LLM
Our final choice was the Gemma 2 9B it, which demonstrated the required balance between unique output, model disk size and inference time on medium end CPUs.
-
Mistral AI: Created by French AI startup and trained off the Llama base model with sliding window attention mechanism. High quality fully open source model used in many offline AI applications.
- Pro: Their 8B instruct model was of very high accuracy, creating a very varied output for the prompts and colours. Ran fairly reliably on CPU.
- Con: Took up a lot of disk space, with minimum of around 24GB
- Verdict: takes too much disk space to be of use in the final product
-
DeepSeek R1: First open source high performing Chain of Thought model, released in midst of testing out various LLM (January 2025)
- Tested the distilled models as original model of 671B parameters was too large
- Pros: models above 14B parameters were produced the most unique and well-reasoned colours and prompts by far above other models
- Cons: Took more time to generate as with all Chain of Thought models. lower parameter count than 14B tend to produce a lot of gibberish and get stuck into a loop of thought, without producing any output at the end. The 14B parametr model had a disk size of 31GB.
- Verdict: Due to hardware constraints of user, unusable
-
Llama: open source models created by meta
- Pros: large range of models with instruct variations being specific and producing decent quality colour outputs. Lots of examples of quantised products on the internet and plenty of support.
- Cons: Slightly too simple model structure limits creativity with prompt generation and colour. Terms and Conditions require the creator of the product to pay meta a subsidy after reaching a certain use count
- Verdict: usable model but T&C make it unscalable for future applications
-
Gemma: Open Source version of Google’s official Gemini AI
- Pros: High quality output from their distilled low parameter count models. IR format (for OpenVINO) already created under Intel’s HuggingFace page so minimal integration required. Runs fairly well on middle end CPUs
- Cons: Suffers slightly from hallucination when not given enough prompts
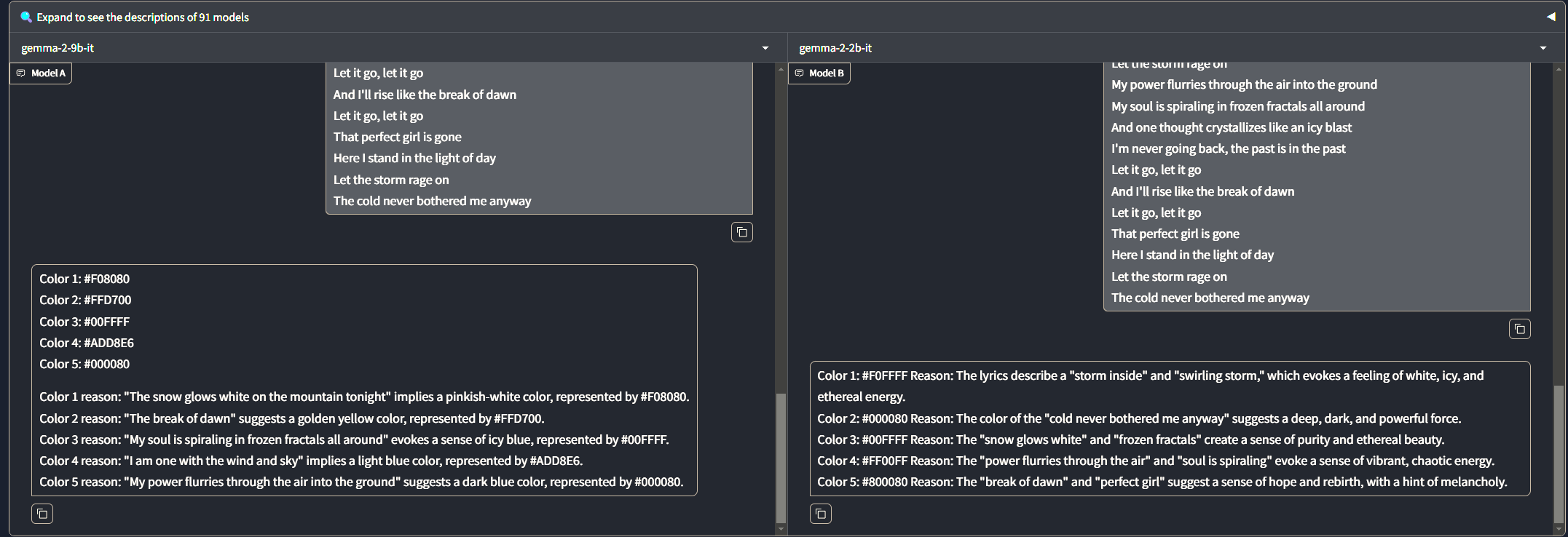
Whilst testing out multiple parameter models, we noticed that lower parameter models kept on generating similar colours in the colour extraction, as illustrated below with the gemma 2 models in lmarena. Moreover, most open source implementations of lower parameter models limited the input prompt tokens heavily, which prevented us from passing in the full lyrics for analysis to the song.
lmarena comparison https://lmarena.ai/?arena
Speech 2 Text (S2T)
Although other options were investigated, the community favourite open source Whisper was by far the most popular and analysed most songs with minimal discrepancies. Whisper is the open source version of OpenAI’s S2T model.
The grammar and majority of the nouns were correct, excluding some . Although this project does not support multiple languages, whisper does have the option to very easily change analysis languages too.
There were few open source S2T models and most required requests to an online server via their official APIs, costing a cheap yet non-negligible API cost. The few other open source models had some kind of flaw such as DeepSpeech, which is no longer officially supported or maintained.
Moreover, the S2T was only required for writing the mp3 audio to lyrics which whisper converted in under 1min per song (of roughly 4min length), which was acceptable given that our project is not time sensitive
Text 2 Image (T2I)
The SDXS-512-DreamShaper model was used due to compatibility with our chosen Diffusers library and fast generation speed
-
Stable Diffusion v1.5 / v2
- Explanation: model used for testing in early stages of T2I research whilst python compilation proved to be a problem. The original weights from the base model was passed into the Stable Diffusion Cpp
- Con: As detailed in the Library & Programinng Languages section above, took average 20min to generate bad quality image as shown. Original weights from the model are required, therefore no optimisation or quantisation can be done to the models.

-
SDXS-512-0.9-openvino
- An openvino optimisation of the Stable Diffusion XS model, producing images at a very fast rate of around 1.5s/picture
- The model has been converted to OpenVINO IR format so was compatible with OpenVINO GenAI but not OpenVINO G
-
SDXS-512-DreamShaper
- Fine-tuned model from the Dream Shaper model, which was further fine tuned from Stable Diffusion XS model
- Fast image generation of 2s/picture, compatible with diffusers library, but does have limit of 77 token inputs to image
- Has LORA support pre-built into the model structure, which was not utilised in our product but may be a potential future
Summary of Technical Decisions
After extensive research and evaluation, we made the following key technical decisions for our audio visualiser project:
-
Platform and Framework:
- Selected Electron as our primary platform due to its ability to package as a standalone executable, cross-platform development capabilities, and integration with modern web technologies.
- Chose Three.js for visualisation over UE5 for its lightweight nature, web compatibility, and built-in audio analysis capabilities.
- Abandoned Spotify integration due to DRM issues and API deprecations, opting instead for a hybrid approach of direct file uploads and system audio recording.
-
AI Architecture:
- Implemented a multi-model AI system with separated components for different functions:
- Gemma 2 9B model for LLM functionality (song analysis, prompt generation)
- Whisper model for Speech-to-Text to extract lyrics from audio
- SDXS-512-DreamShaper for Text-to-Image generation with fast 2s/image performance
- Used OpenVINO C++ for LLM and S2T components to optimise for Intel hardware
- Employed Python with Diffusers library for T2I component due to compatibility issues with OpenVINO
- Implemented a multi-model AI system with separated components for different functions:
-
Audio Processing:
- Implemented multiple audio input methods (file upload, YouTube download via yt-dlp, system audio recording) to maximise flexibility while addressing legal concerns
- Used FFmpeg for audio format conversion and processing
- Integrated Three.js AudioLoader and AudioAnalyser for real-time frequency analysis and visualisation
-
Development Approach:
- Prioritised offline functionality to ensure the system works without internet connection
- Balanced performance with quality, optimising models to run efficiently on CPU-only systems
- Ensured all AI components could function as standalone executables within the packaged application
These decisions were guided by our core requirements for a portable, accessible, and legally compliant audio visualisation system that provides therapeutic benefits for autistic children while maintaining compatibility with modest hardware specifications.