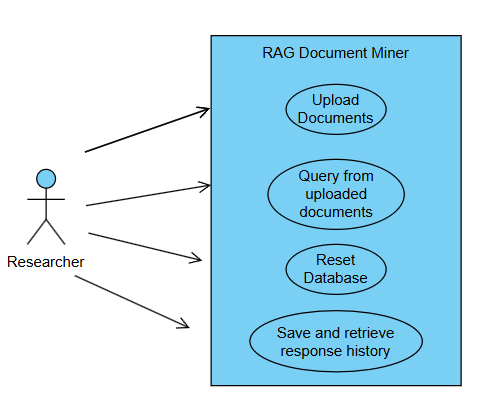
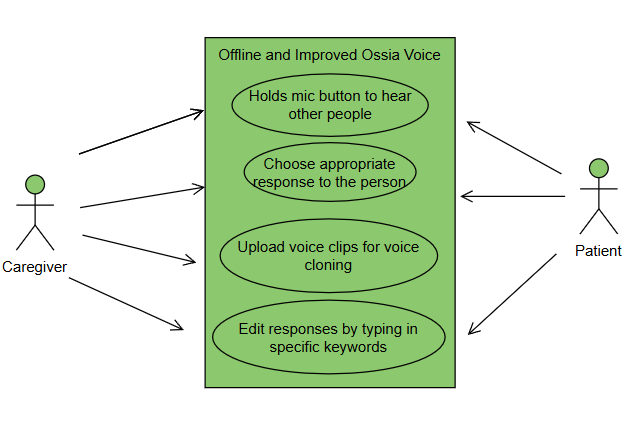
User Personas
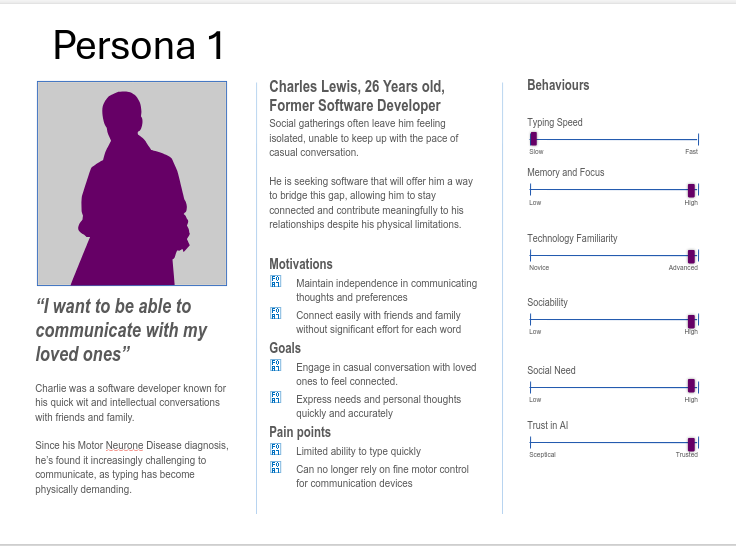
Persona 1: Charles Lewis
Charles was an intelligent software developer who was known to be very open and conversational. However, that all changed since he was diagnosed with Motor Neurone Disease (MND). Over time, Charles' speech abilities deteriorated very quickly. Furthermore, he has also found other text-to-speech tools very difficult to use since his ability to type has also become very exhausting for him due to his deteriorating motor skills. Previosuly very social, nowadays Charles often feels like an afterthought at social events which has led to him feeling isolated and depressed. Charles is seeking software that will help him to be able to communicate with his friends and family whilst also requiring minimal typing. Charles is also not in the greatest financial situation since he has had to quit his job and is currently surviving off of savings and his disability benefits. As a result, he requires software that will not force him to have to rack up many charges and ideally be free to use. Charles has found the new Ossia Voice to be a revolution in his day-to-day life. Charles had previously used an OpenAI API and was very impressed with the software. However, he couldn't continue using it due to financial constraints. With the option to use offline models, and since Charles has access to a good quality device from his software engineering days, he was able to use a high-performing model. This resulted in him being able to massively improve his social life, almost to how it was pre-diagnosis. He also made use of the voice cloning mechanism and many of his friends have commented saying that they feel like they have Charles back rather than previously feeling like they were still talking to a machine. It has massively improved his mental health and wellbeing whilst also removing his previous feelings of isolation.

Persona 2: Grace Patel
Grace is an elderly lady who is a former teacher. She used to be described by friends as a "social butterfly". However, a few years ago she was diagnosed with a muscle disorder causing her to have reduced mobility and speaking abilities. Grace has a caregiver who helps her with her daily tasks. She has found that the current text-to-speech tools are not very intuitive and require a lot of manual setup. Grace's caregiver has also found that the current tools are not very reliable and often require her to step in and help Grace. Grace is looking for a tool that will help her to communicate with her friends and family more easily and without the need for constant recalibration or having to rely on her caregiver as much. Grace was astounded at the extents the Ossia Software we produced could reach. Since, she is not very technical. She found the large and easy to use menu very inviting whilst also being clear to see without her glasses. She found it very simple and since the offline models produce what she wants to say most of the time, she hardly has to type in any words. Grace has mentioned that because of this, she hasn't had to rely on her caregiver as much and our software has helped her to get her independence back. Additionally, with Grace being a former teacher. She also tried out our RAG document miner tool. As a former educator, she had a strong affinity for organising and accessing information quickly. The tool allowed her to easily extract and reference key documents, enhancing her communication and helping her reconnect with the wealth of knowledge she’d accumulated over the years. She also mentioned that due to the simple and intuitive user interface she found it very easy to use despite her accessibility issues.