SYSTEM DESIGN
System Architecture
The overall system is made up of a frontend component with the Next.js React framework, a backend component with the web framework Flask in Python, and a database component containing the SQL database and the vector database.
Next.js is responsible for receiving requests from the user such as storing PDFs, which is done in the frontend component to display said PDFs to the end user easily and removes the need for a proxy when the backend retrieves those files. Furthermore, it can send API requests to the backend and display the response on the web page.
The backend utilises the Flask microweb framework, which can interact with the frontend to handle API requests. It can upload and retrieve relevant text chunks from the Pinecone vector database and read/write data to the SQL database. Flask also interacts with OpenAI’s large language models to generate the systematic review.
The Pinecone vector database is made up of text chunks converted to vectors, which contain metadata of the text’s origin, section category and plaintext. Querying the database yields the most related text chunk and is returned to the backend. The SQL database stores user details as well as previously generated systematic reviews linked with users. SQL statements are used to add, delete and retrieve data from tables, which is returned to the backend in JSON format.
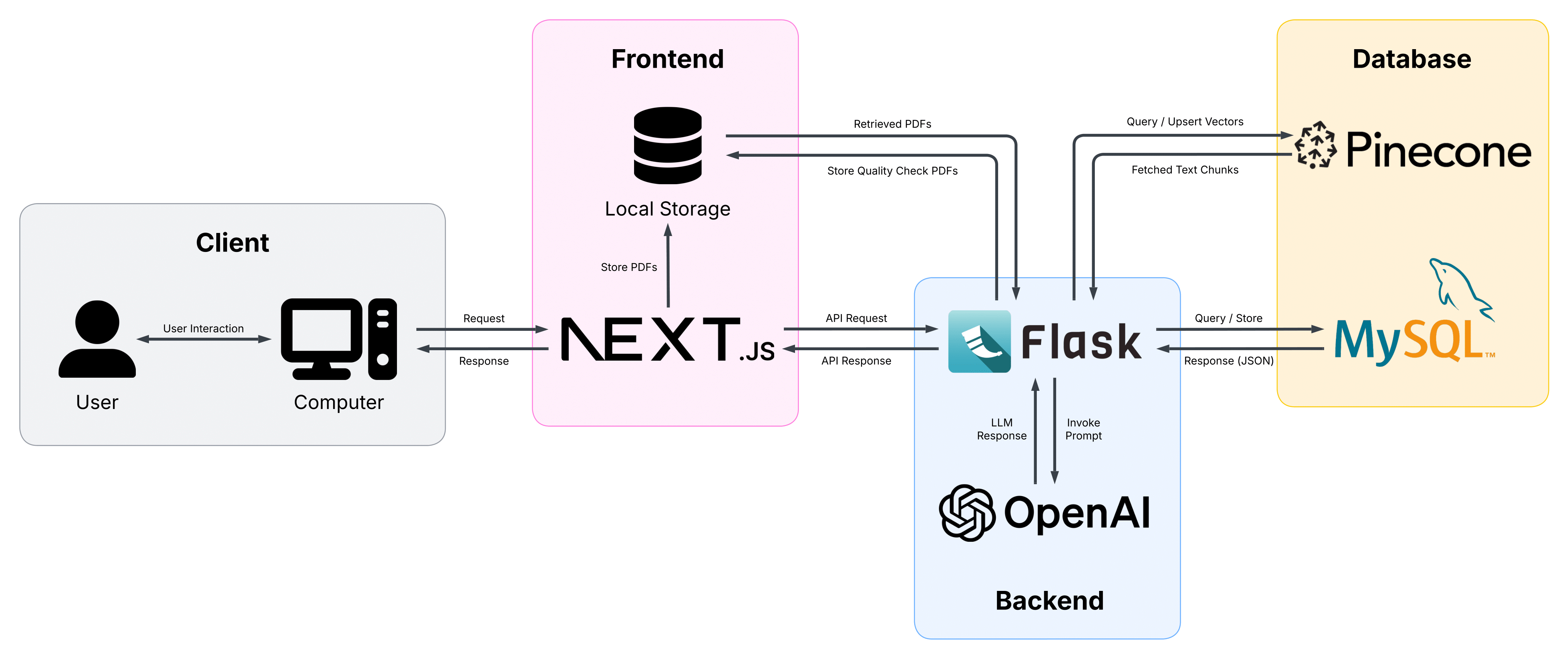
Figure 1: System architecture diagram of the RAG backend
Sequence Diagrams
This is a sequence diagram that demonstrates the interactions between each system component (including the frontend, backend and databases) in sequential order when the user generates a systematic review.
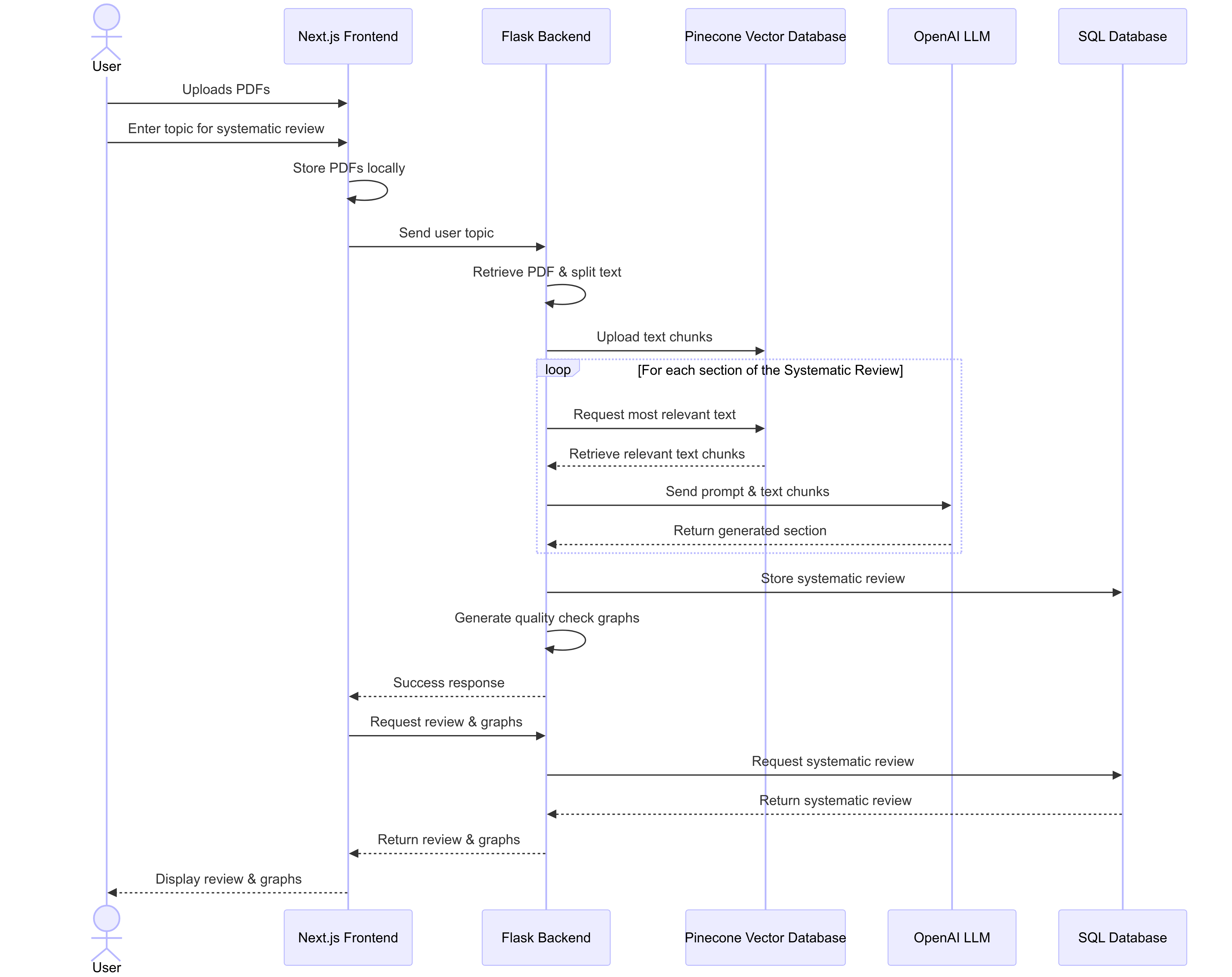
Figure 2: Sequence diagram of the systematic review generation process
Data Storage
ER Diagram
This is an entity-relationship (ER) diagram of the SQL database we use to store the user’s login information and the history of systematic reviews. For one user, there can be zero or many systematic reviews (history) linked with them. This linkage is done between the user_id. The ‘timestamp’ datatype stores the date and time and is generated by MySQL when the instance of the table entry is created.
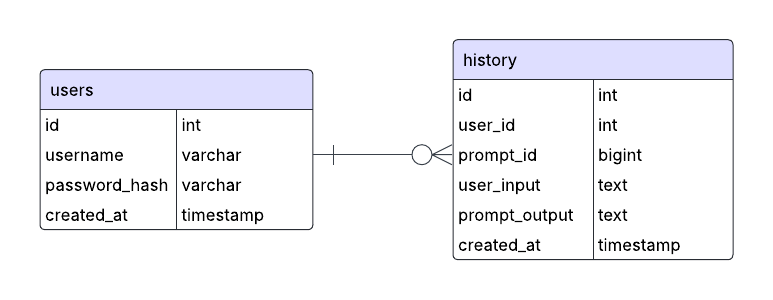
Figure 3: Entity-relationship (ER) of the SQL database
Packages and APIs
PyMuPDF
Converts PDF documents into raw text for easier processing by the system.
LangChain
Handles text processing including text splitting and human message management.
OpenAI
Converts text chunks into high-dimensional vectors using an embedding model.
Pandas
Used for data manipulation and analysis, creating data frames for quality check visualizations.
Matplotlib
Generates visualized graphs for data analysis and quality checks.
Flask
Web framework handling backend operations, HTTP requests, and API endpoints.
Bcrypt
Secures user passwords through hashing before database storage.
MySQL
Relational database system storing user authentication details and usage history.
Next.js
React framework that does server-side rendering for displaying static pages with inbuilt JSX.
TailwindCSS
UI framework used to efficiently style the website.
python-dotenv
Manages environment variables for application configuration.
Pinecone
Vector database for efficient similarity search and storage of embeddings.
OpenAI
Provides access to powerful LLM models and AI capabilities.
Together
Alternative platform for accessing various open-source language models.
langchain-community
Community-contributed components and integrations for LangChain.
lxml
Library for processing XML and HTML documents.
transformers
State-of-the-art natural language processing models and tools.
tf-keras
Deep learning framework for building and training neural networks.
pypdf
PDF toolkit for splitting, merging, cropping, and transforming PDF pages.
markdown-pdf
Converts Markdown documents to PDF format.
mysql-connector-python
Python driver for communicating with MySQL databases.
seaborn
Statistical data visualization library based on matplotlib.
pdfplumber
Extracts text and analyzes PDF documents with detailed page information.
chardet
Character encoding auto-detection for text files.
wordcloud
Generates word cloud visualizations from text.
scikit-learn
Machine learning library for classification, regression, and clustering.
nltk
Natural Language Toolkit for text processing and analysis.
pytest
Framework for writing and running tests in Python.
tqdm
Provides progress bars for loops and iterables.
Authentication API
POST /api/register- User registrationPOST /api/login- User authenticationPOST /api/query_user- Get user details
Review Generation API
POST /api/upsert- Initialize PineconePOST /api/generate- Generate reviewPOST /api/quality_check- Quality analysis
History Management API
POST /api/save- Save reviewPOST /api/query- Get reviewPOST /api/query_user_history- User historyPOST /api/delete_user_history- Delete review