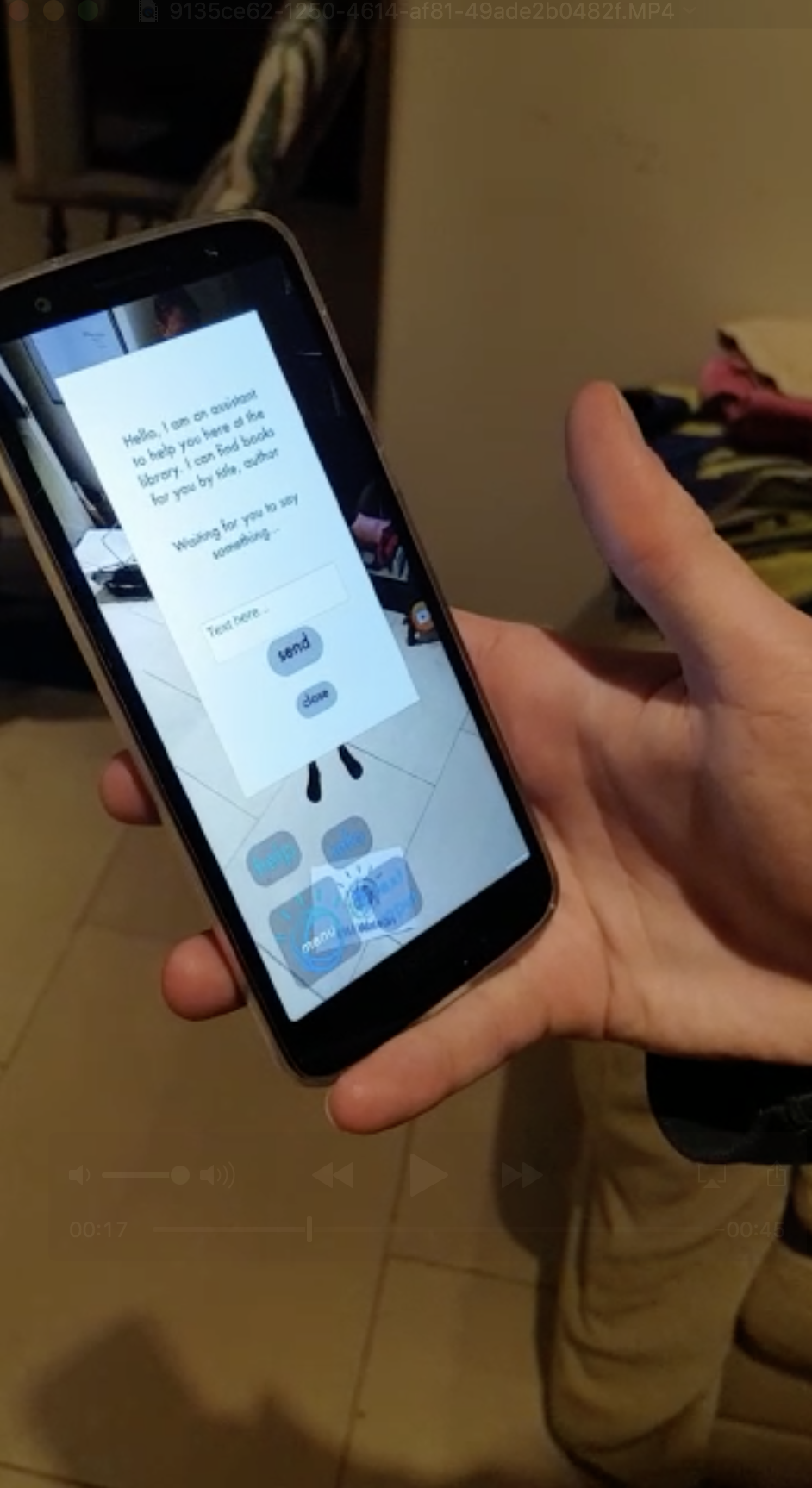
Our day to day testing strategy consisted of three main methods:
- Manually testing webhook responses. Oliver did this via the Azure Function command line which
allowed him to enter different types of JSON query and check that the webhook returned the appropriate response.
- Manually testing the chatbot using the Watson GUI. Lilly did this, using the use case maps in the design section.
Each query would be entered, both with a recognized entity and with an unrecognized entity and checking the
appropriate response. A screenshot of testing via the Watson GUI is included below. With more time we might have
been able to build an automated testing net for Watson using a service like POSTMan.
- Manually testing the AR functionality by repeatedly building it to a mobile device and using Development debugging
in the unity console. This was our main method of testing the pipeline of the entire app and solving issues with the AR interface.
This was quite a clunky way of testing because each build takes some time, however the Unity Live Debugging platform
for mobile unfortunately does not yet support AR, so we did not have any other way of debugging and testing this functionality.
Towards the end of the project, we then conducted user testing. We had planned to do this with members of our class at
university in the final week of the project, but were not able to do so because UCL had closed down and brought our classes online.
However, we did manage to test the app with five friends and family members, and below you can see some images of our user testing.
- We stress tested our app in a noisy environment, in the lobby of a concert hall. This was definitely not as successful as testing
it in a live environment, with the avatar having difficulties in recognizing users’ speech. This is probably an issue to do with
Watson Speech-to-Text not being very good at handling these kinds of environments.


- To the best of our ability, we tested it with members of different generations, with age range 19 – 59.
- We tested our app on a Samsung Galaxy S8, a One Plus and a Moto G6.
Observations from user testing:
- People understood well what the avatar was and how to use it, and how to get help if necessary. Apart from
a few crashes (see known bugs), users were mostly able to complete tasks given to them, as long as the task
was sufficiently specific. General tasks like “find out about IBM” were less successful because people asked
questions that were not recognized by the avatar.
- The range of spoken requests was much larger than expected. Even when given a specific task like “find a
book by Agatha Christie”, people would phrase this in different ways, some of which were not recognized by
the chatbot. In future we would need to expand our avatar’s vocabulary of recognized requests in order for it
to be fully deployable in a real environment.
- The response times from Watson are sometimes too slow for people’s patience, especially when Watson is
fetching a complicated webhook query (like checking in for an appointment in a doctor’s surgery). This is
unsurprising given the number of different data channels required in one of these complex requests.
In future, we would want to find a way to optimize this further.
- People didn’t move around the avatar as much as we thought they would. We thought people would try to look
at the avatar from different angles or move around, but most people were focused on asking questions and listening,
and seemed to want to keep about 1-2m distance from the avatar, the average for a normal human conversation.
- The conversation flow is quite stilted, with generally one spoken request and one spoken answer. People seemed to
disengage after having asked a few questions and getting over the novelty factor of the avatar. In the future we
could use more complex animation or back-and-forth conversation flow to make the avatar more engaging.
Performance and Efficiency Testing
We conducted a sample of response times for the Watson response, where we timed the period from the end of the
user asking their question to the beginning of Watson speaking it aloud. The average was about 4 seconds, which
shows that there is still quite a bit of latency in our avatar that could be improves. The results of these tests are below:

Testing Difficulties
We did not manage to do any unit or integration testing, stress testing, or responsive design testing. Our testing strategy
was one of the least successful parts of our project. We had both external and internal difficulties that caused this:
External difficulties: We found it very hard to work out how to test an AR app that involves voice recognition. Our project
cannot be run in the unity simulator, and despite research we could not find any information on AR unit testing. It seems
that in this relatively new field user testing is the most widely used form of testing. Additionally, we had planned to do user,
performance and responsive testing in the last two weeks of the project, which was significantly disrupted by Covid-19.
We did not have access to an android tablet or multiple android devices to do stress or responsiveness testing during this time.
Internal Difficulties: we did not place as much importance on testing throughout as we should have, and we left our user
testing until the end of the project, when it was then difficult to do because of our classes being cancelled. We did this because
the app was not fully usable until the end and we also had our hands full with development work, but ultimately, we should have
been user testing throughout. We should have seen that we didn’t need to have a finished product in order to test it – we could have,
for example, tested the chatbot backend with users using the Watson GUI without having finished the AR functionality of the app.