Final product
Overview of BERT
The functionality of BERT can be analogized by children doing reading comprehension task. Given a paragraph of reading material and several questions regarding that material, a child would be required to answer all the questions concisely and accurately. The normal steps for a human doing reading task is to read the material, read the questions and answer the question based on the material. However, because machines cannot really understand natural language, BERT uses numbers to represent words. Every single word can be represented by a particular number. BERT models then use all these numbers to create two high-dimension vectors. One number for the context and another for the question. The mathematical approach used is to measure the distance between the dimension of the context vector and the dimension of question vector. The shorter the distance between the two vectors the closer the meaning between them. Then BERT will return the vector with shortest dimension, as well as the text surrounding it. Then those numbers will be translated to the source language again as the final answer.
Our reportQuery system
In this section we will briefly explain how all the features have been implemented. The code can be divided into 4 parts, as shown by the BERT algorithm diagram. Each part is implemented in a single script. The first part (the red box) imports all the pdfs which need to be processed from the input folder, and these pdfs are converted to in an image format using the pdf2image python library. pdf2image is a python wrapper for pdftoppm and pdftocairo to convert PDF into a PIL image object. This is because some pdfs in the input folder are already in an image format and so each pdf is converted into an image to ensure uniformity. The algorithm then uses Microsoft Azure’s Cognitive Services Computer Vision OCR API to use optical character recognition to iterate through each page and convert these images into a JSON format. This JSON format is then converted into a string format.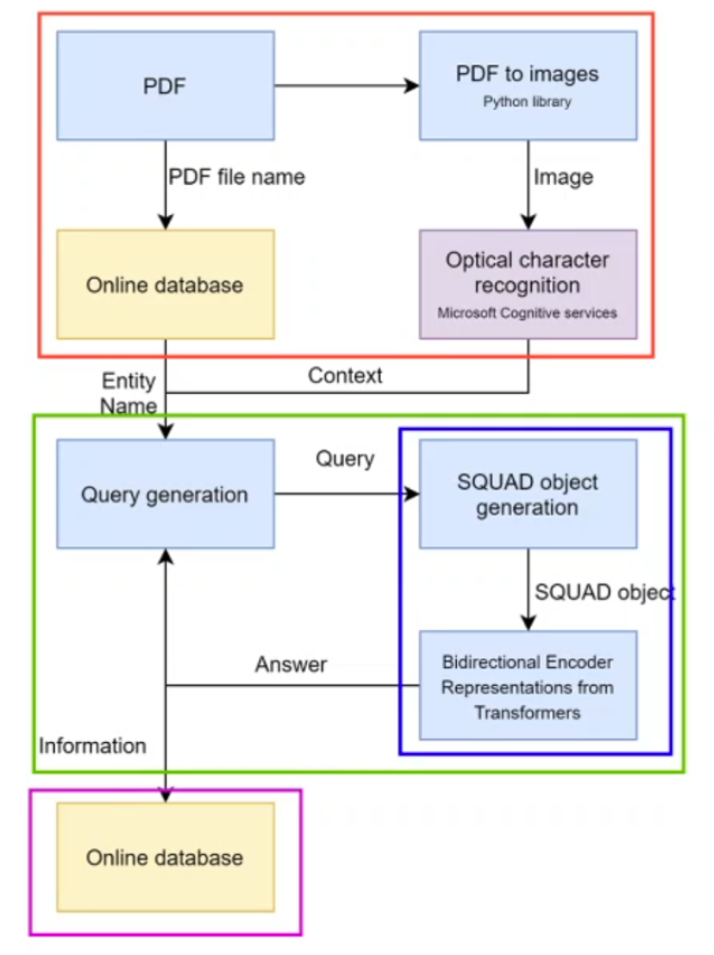
For each pdf, the first thing to do is get the name of NGO associated with the annual report, from the online database (Database 2 – UN “knowledgebase”) hosted on Azure. The names have already been uploaded to the database using the name extraction algorithm. The name extraction algorithm essentially allows the user to upload their pdfs to Database 2, under the pdfs table, and to choose whether to manually input the NGO name associated with the pdf or automate this process by using our name extraction algorithm. If the user chooses to use the name extraction algorithm, they must authenticate the output is correct before it can be uploaded to the database. The name extraction algorithm is a separate entity from the main BERT algorithm and has an accuracy of around 50%. We had to manually automate name extraction because BERT cannot recognise named entities such as NGO names because these words are unfamiliar to the corpus which BERT has been pre-trained on.
Now that we have the entity (NGO) name and the content of the report, this is passed on the Query generation part of the algorithm (green box). The Query generation part is entirely done in the Questions.py, where the answer for the previous question is used to generate the next question. For example, we want our algorithm to return a list of PROJECTS for each NGO. Then for each PROJECT, we want to ask the ALBERT* model further questions about this particular project such as project mission, start date, end date, location etc. So essentially the list of project names returned by ALBERT inform the questions asked about each project, using the project name. After the questions have been generated, they are sent to the ALBERT model (in docQuery_utils.py). The text and the questions are packaged into a single SQuAD object (blue box), and then passed to ALBERT. In order to simplify query generation with the ALBERT question and answering system, we used the Hugging Face Transformer python wrapper. The model generates a set of 20 predictions for each question, based on answers with the highest probability of being correct. We changed docQuery_utils.py so that the all the answers are returned as text, and not just the best answer with the highest probability, which the model was previously configured to do. For example, for NGO address, we want the “best” answer (bestPredictionText) whereas for Project names we want all the possible names (nBestAnswerPredictionsText) so we choose the top 10 predictions returned by the ALBERT model.
The answers are returned to Questions.py which packages them and in turn returns the package to ‘docQuery long context.py’. This data is then passed to submitDataToDB.py, which uploads the data to the corresponding table and field of the database, depending on the content of the answer. The reason we can easily determine table and field name is because Questions.py returns the answers to the questions as a list of nested dictionaries of table and field information for each table in the database. This allows us to iteratively write python insert SQL queries, so that this information can be directly uploaded to the database.
* For more information on ALBERT, an upgrade based on BERT, please refer to information on the different models under the research section.
Improvements
There are a few samples of garbage data scattered in the database, due to the BERT model misinterpreting the pdf text in the context of the question asked. This was something we expected when we chose our model, since it has not been finetuned in the context of NGO report data. The reason our model is not finetuned is because it is incredibly resource intensive and time consuming, as it involved creating a large custom list of questions in the context of our data, and powerful GPUs to train our model on those questions.
Name extraction tool
The name extraction tool provides a necessary pre-process, linking the name of the NGO described in a report with the PDF name of that report.
The algorithm's main feature is a loop that iterates through all PDF documents provided in the "reports" directory, minus those that appear already in the database. The user can either use the name extraction function, get the first three pages of report text, ignore the report, or provide their own name. The final name is then uploaded to the "pdfs" table of our Database 2 via an SQL insert query.
For the actual "readReport" element that does the name extraction, the algorithm works by first reading the first three pages of text. The idea is that the first thee pages will in most cases contain the name of the NGO, balancing the overhead in time and resources that comes from processing multiple pages. The tool then looks at two main elements, the report's filename, and web links and emails found within those reports. It then tries to find a series of words from the first three pages that also appear in the same order in these elements. In testing, it was found that urls and emails tend to give the most accurate responses, so the algorithm first checks these elements before checking the filename.
Prototype 1
Overview diagram
PDF extraction tool
Algorithm
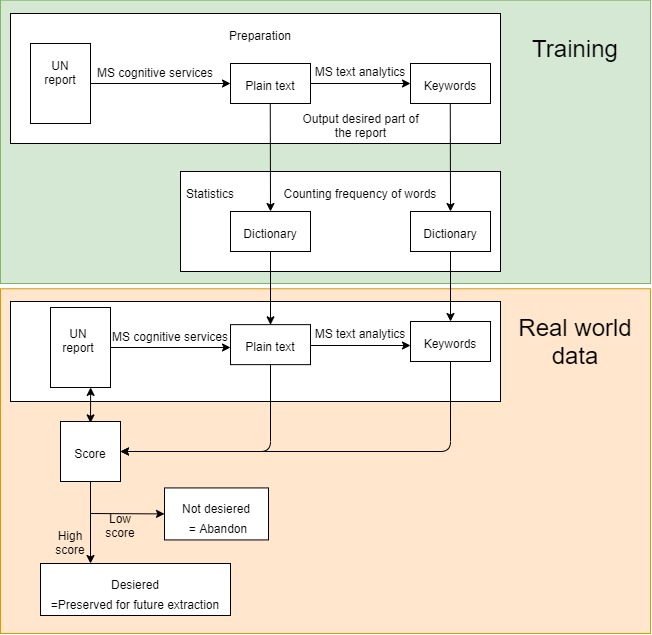
We input desired a particular part of the UN report as the training dataset. In this example, the training dataset consists purely of financial information. This is because financial information is fit for our purpose because the information is quantifiable, and so we can easily spot trends and patterns.
The Microsoft Cognitive Services Ink recognition API converts this pdf text into plain text. The Microsoft Cognitive Services Text Analytics API is then run on this plain text to extract the key words from the file. In order to build the dictionaries, two empty dictionaries are created initially. Each word in the plain text is checked to see if it exists in the dictionary. If it doesn’t, then it is added to the dictionary. If not, a counter is incremented to indicate a higher frequency for the corresponding word. The same process is applied to create a keyword dictionary.
The resulting dictionaries are exported as a search facility for another data set, which could be another UN report, for example. The same process is applied to this section, where Ink Recognition API is used to convert the pdf into plain text and the MS Text Analytics API is used to extract the keywords from the file. Afterwards, each word in the plain text and keywords are checked against the corresponding dictionaries (generated by the training dataset) and allocated a score. The score is higher for keyword match than a plain text word match.
At the end, both the plain text and keyword scores are accumulated. If the score is high enough, the input will be preserved for future extraction. If it’s too low, the input is not desired so this part will not be considered for future extraction. Essentially, the aim of this process is to check the relevancy of the information in each section of the report so that we only preserve the relevant sections for future analysis. The information in the relevant sections will be used to build the database.
This video, voiced by Rachel Mattoo, gives an overview of this algorithm:
Ink Recogniser
- An AI service that does OCR Recognition.
- Recognize digital information from pdf files. It can recognise 63 languages and locales.
- Makes inked content searchable.
- Digital ink data is presented in JSON format and it also includes REST APIs so that you can integrate into your applications across Windows, IOS, Android and the web.
Text Analytics
Detect sentiment, key phrases, named entities and language from your text