Implementation of key functionalities
A detailed write up of our algorithms can be found in the Algorithms section.
This video, voiced by Rachel Mattoo, gives a concise overview of the reportQuery algorithm:
This video, voiced by Mark Anson, gives an demonstration of the NGO Extraction tool:
System architecture diagram
The proposed solution is semi-automated. Essentially, our name extraction program is a separate entity and allows the user to initially upload NGO reports, along with the corresponding NGO name. The user has the option to automate this process by using the automated name extraction algorithm. Once the pdfs have been uploaded, each pdf is converted into a JSON format using Azure Cognitive Services’ Computer Vision OCR tool. The Report Query System then uses the ALBERT model’s Question and Answering system to ask a custom list of questions to the pdf text. These questions directly correspond with the database’s tables and fields. The response for each question is directly inserted as a python SQL query into the database (Database 2).
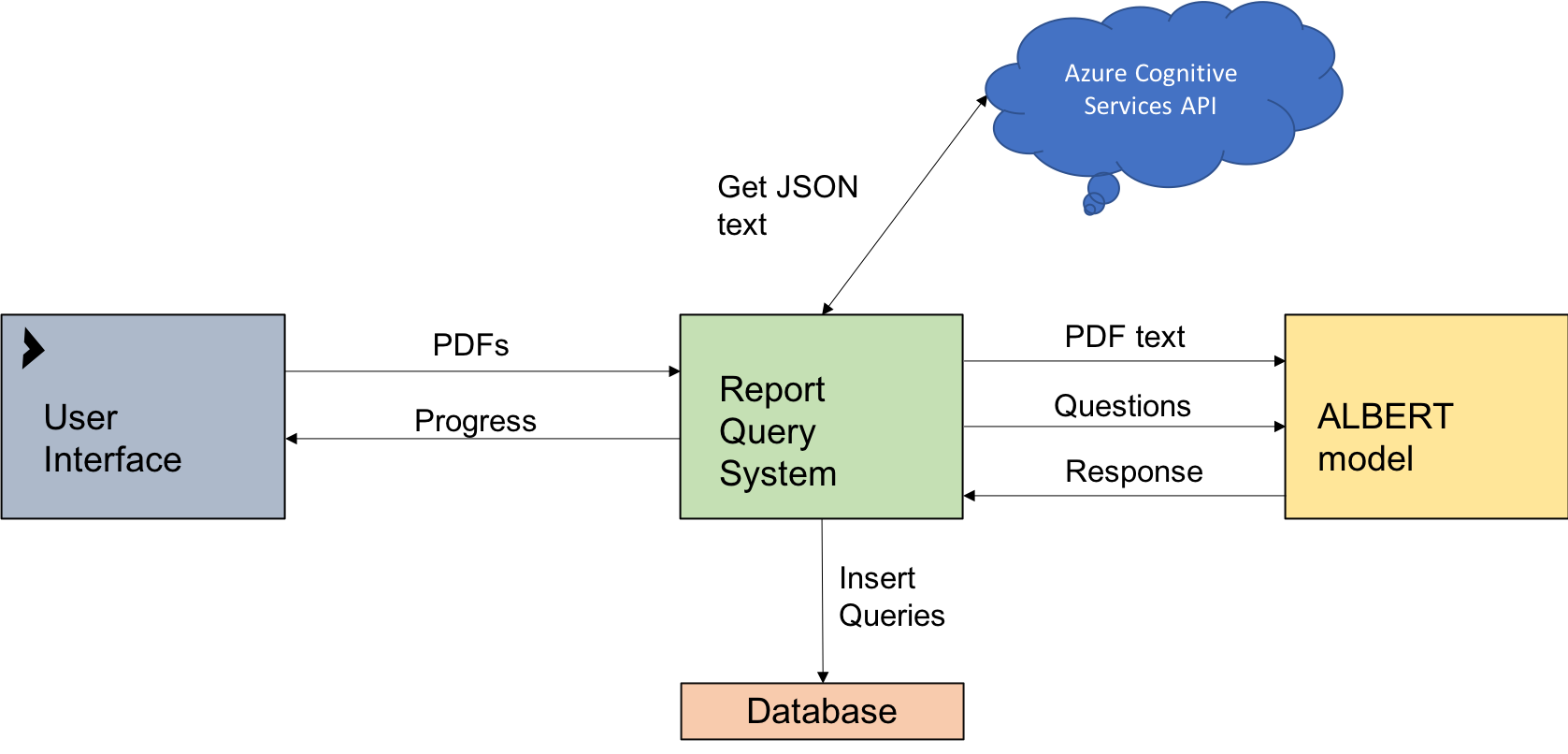
This is the architecture diagram for our reportQuery solution. It gives a good overview of how the different elements of our solution link together. The User Interface is a simple terminal window. No actual interaction is done on the user's part, as the interface just displays progress. The user's main interaction is supplying the documents they wish to extract data from.
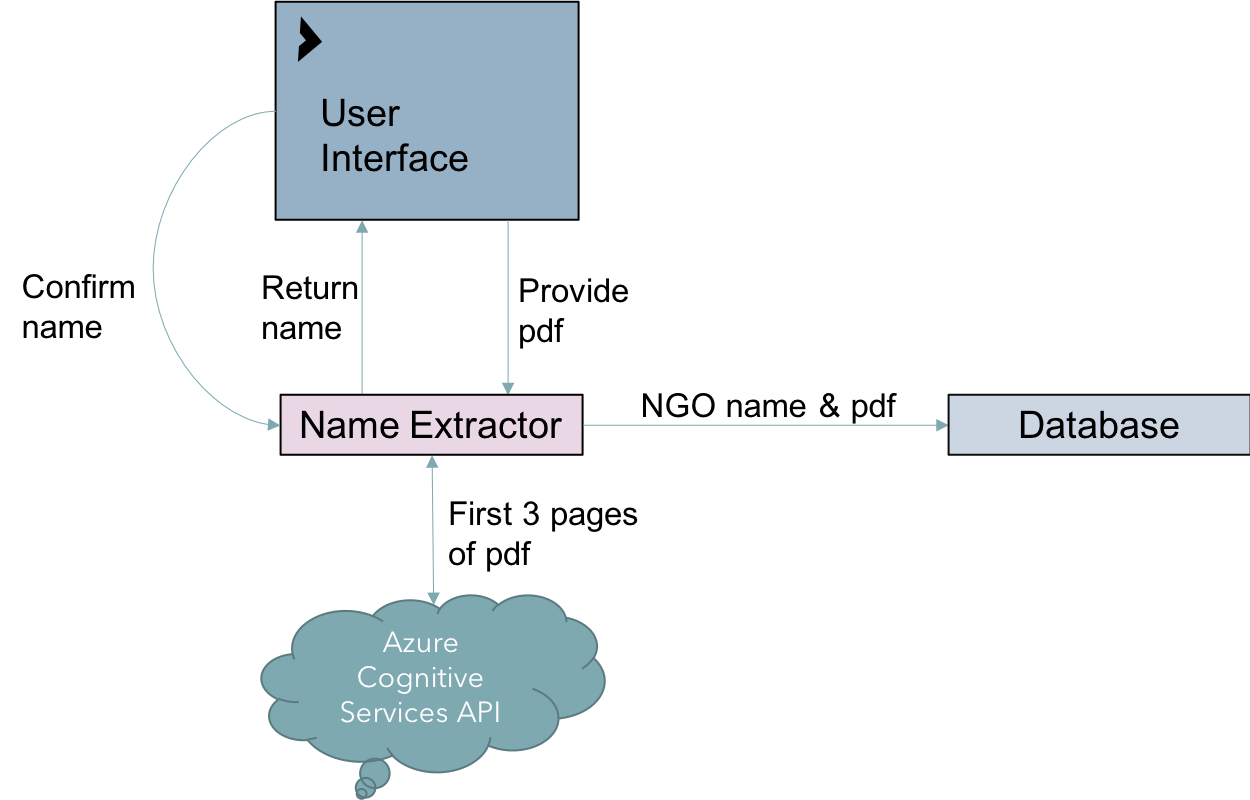
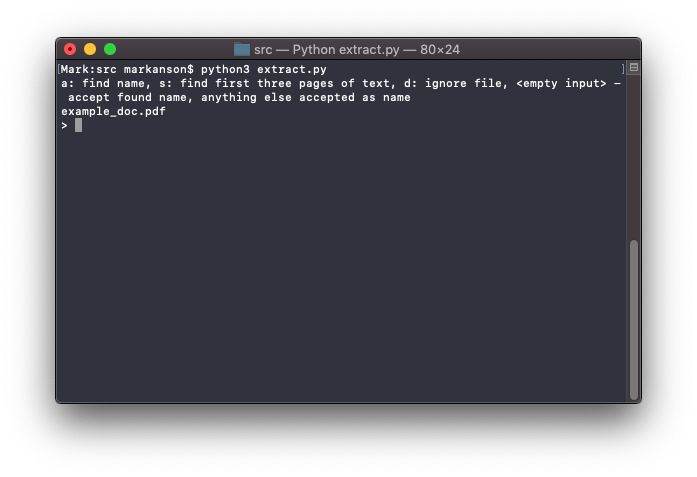
We also produced a separate architecture diagram for the name extraction tool. Although this tool is much smaller and less significant than the main reportQuery system, it allows the user to perform a necessary pre-processing element - supplying the NGO name of a NGO report. The tool operates in a terminal, iterating through all proided PDF documents and giving the user options on what to do, as seen below.
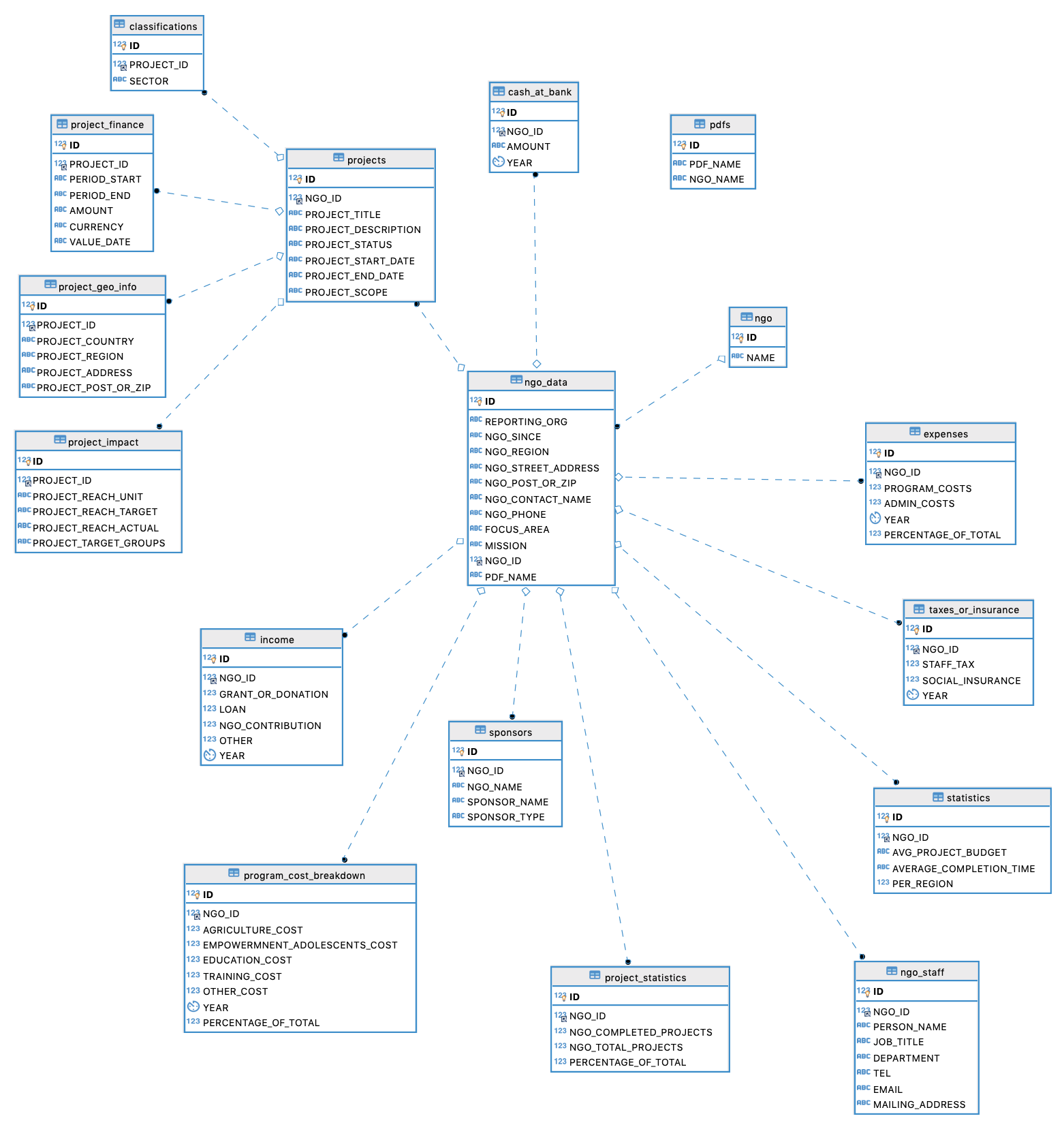
ER diagram for Database 1 (ANCSSC database)
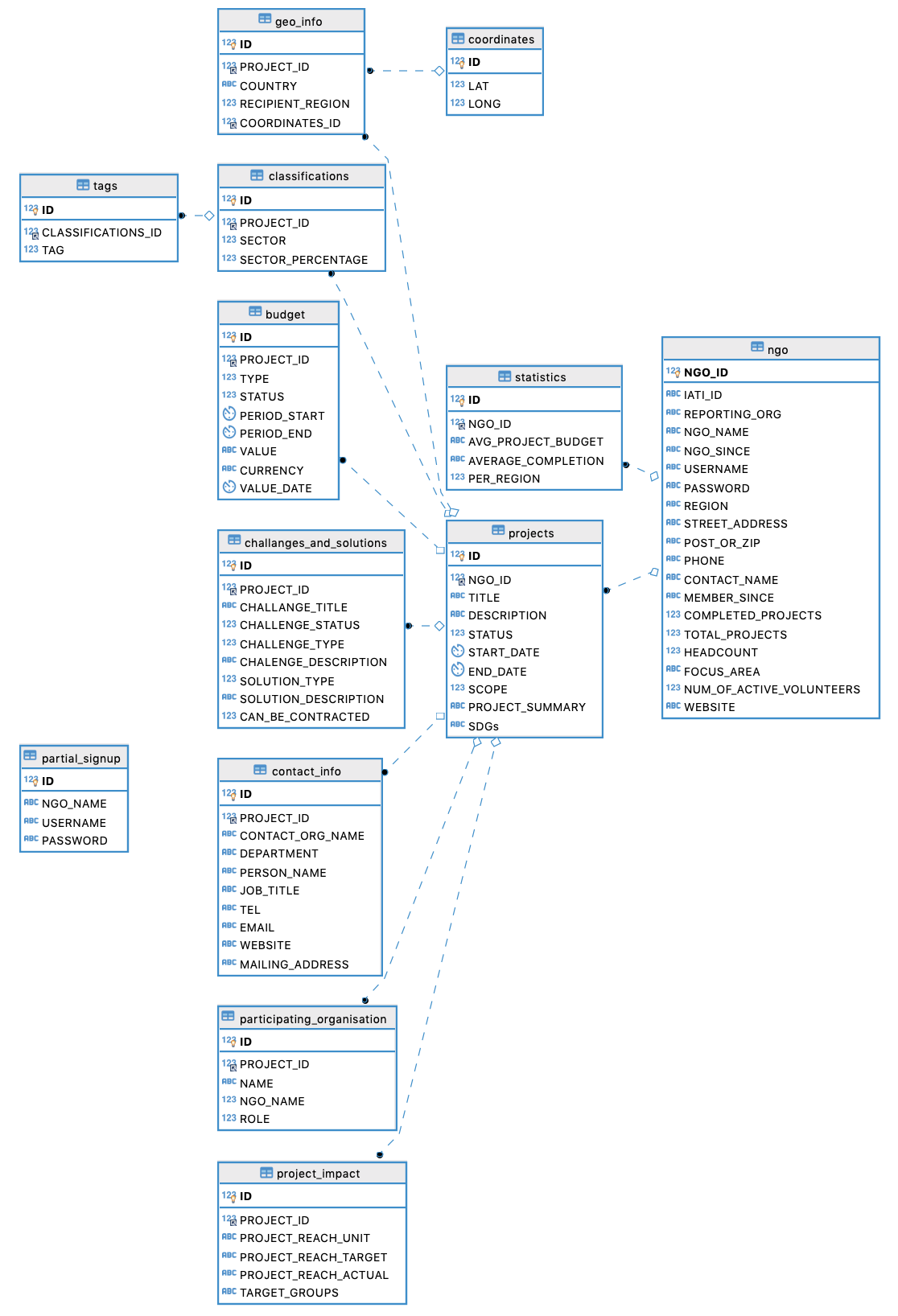
ER diagram for Database 2 (PDF extraction database)