Summary of achievements
MoSCoW List (Iteration 2)
| ID | Requirements | Priority | Completed status | Contributors |
|---|---|---|---|---|
| 1 |
Database 1 -ANCSSC database for web app (used by Team 37 and Masters team)
|
MUST | After multiple revisions following input from both the Masters team and Team 37, the database is fully implemented and ready to be used. | Mark |
| 2 |
PDF data extraction tool
|
MUST | reportQuery system as well as relevant ancillary elements fully implemented and run on large number of PDF documents. | Yansong, Rachel, Mark |
| 3 |
Database 2 (UN "Knowledge-base")
|
MUST | Database 2 fully implemented and in use to store data produced from our BERT model. | Rachel |
| 4 |
Quality documentation for PDF extraction tool
|
SHOULD | Documentation exists in several places, notably, the repository readme and this website itself. | All |
| 5 | Statistical analysis tool
|
COULD | - | - |
| 6 | Front end access to database 2
|
COULD | - | - |
| 7 | Build generative adversarial network (GAN)
|
WOULD LIKE | - | - |
| 8 | Machine Learning based recommendation algorithm
|
WOULD LIKE | - | - |
| 9 | Link database 1 & 2 into a single coherent structure | WOULD LIKE | - | - |
List of known bugs
- PDF extractor - some questions work better than others at accurately obtaining information from the reports. For instance, the algorithm strugged to accurately find phone numbers, often returning email address or completely unrelated information.
- PDF extractor - One error encountered during integration testing for the ALBERT algorithm and Database 2 was that all the fields, apart from the primary/foreign keys, were not set to NULL. These fields were changed to be default NULL because it could not be guaranteed that the ALBERT algorithm would return a value. Another error encountered was that the ALBERT system could only return string values, so each field data type was changed to only store varchar.
Individual contribution table
| Work Packages | Rachel Mattoo | Yansong Liu | Mark Anson |
|---|---|---|---|
| Client liaison | 70% | 15% | 15% |
| Requirement Analysis | 33% | 33% | 33% |
| Research | 33% | 33% | 33% |
| Programming (PDF extractor) | 25% | 65% | 10% |
| Programming (SQL insertion) | 0% | 20% | 80% |
| Database 1 management | 0% | 0% | 100% |
| Database 2 management | 100% | 0% | 0% |
| Testing (PDF extractor) | 30% | 40% | 30% |
| Bi-weekly report | 100% | 0% | 0% |
| Website editing | 20% | 0% | 80% |
| Video production | 25% | 25% | 50% |
| Overall Contribution | 33% | 33% | 33% |
Critical evaluation of the project
User interface / user experience
During development we have not had a heavy focus on a user interface. The priority of such an interface was always limited, as future projects will shape the way in which our technology is used. We stuck to terminal output and input, which is effective and easy to manage.
Functionality
Our final deliverable carries out its intended functionality, as per our user-requirements. We will address each of the MUST and SHOULD requirements, discussing the extent to which each requirement was successfully met and identifying areas for improvement.
1) Database 1 – ANCSSC database for web app
This Database was created to host information for the master’s team, for their front-end web app, and Team 37, to include geographical location details. Creating the database required multiple iterations as the master’s team constantly updated their user requirements or improved on their current prototype designs. The backbone of the database was built on guidelines provided by Matt, a member of the ANCSSC and Team 37’s client. After multiple meetings with both the Master’s team and Matt, we managed to successfully create a database which satisfied both their requirements. We also provided the master’s team a copy of the SQL script we created to build the database and some sample queries, so that they can make alterations in the future if need be.
2) PDF Extraction tool
Extract relevant information from pdf NGO reports
The PDF extraction tools mostly manages to extract relevant information from the NGO reports. This includes information such as project information, staff details, NGO details. There are a few samples of garbage data scattered in the database, due to the BERT model misinterpreting the pdf text in the context of the question asked. This was something we expected when we chose our model, since it has not been finetuned in the context of NGO report data. The reason our model is not finetuned is because it is incredibly resource intensive and time consuming, as it involved creating a large custom list of questions in the context of our data, and powerful GPUs to train our model on those questions.
- Using Azure Cognitive Services
The PDF extraction tool successfully uses the Microsoft Azure Cognitive Services Computer Vision OCR API. This uses optical character recognition to convert pdf reports, in image format, into JSON text format. Cognitive Services is much more powerful compared to open source alternatives and the price justifies the improvement in performance. It is also within the ANCSSC monthly budget, as highlighted by the cost matrix.
- ALBERT Question and Answering system to extract data from natural language
The ALBERT model, an upgrade on BERT and developed by researchers at Google AI, was chosen because it has the highest accuracy according to the SQuAD rankings. ALBERT works well at extracting relevant information from natural language. However, even though it can work on any length of text, it is more optimized for a smaller length of text and for returning the best answer based on probabilities. This would not be the case if we had fine-tuned our model.
3) Database 2 – UN” Knowledge-base”
This database contains fields to store information extracted from the annual NGO reports using PDF Extraction tool. The design for the ER diagram had undergone multiple revisions as involved analyzing multiple reports to determine how to structure the information. Through testing, each field except the primary key fields was changed to DEFAULT NULL and varchar data-type. This is because sometimes the model may not find an answer and the answer can only be returned as a string data type.
4) Quality documentation for PDF extraction tool
We have provided quality documentation for PDF extraction tool. We have written an extensive deployment manual and the report website, as well the bi-weekly reports, highlight the large amount of research involved to produce our final deliverable.
Stability
There are a few things we did in order to ensure stability. Firstly, for our database structures, utilising a service such as Azure helps guarantee uptime, with Azure guaranteeing at least 99.9% availability [1]. For our reportQuery system, we spent some time thinking about the stability of uploads to our SQL database. We would often find the database connection would time out and crash the program. Our solution is to have objects specifically for uploading data to the database, so that the connection to it is re-established each time we have new data to upload, rather than holding one connection open continuously.
Due to the nature of our project, we did not spend time setting up a comprehensive test suite for our program, however such a suite would be useful to grantee stability of the program. We still did however perform plenty of testing of the program, with it now having seen around 100 PDF documents, and has been left to run for extended periods of time. So we do have a reasonable basis to suggest this program is stable.
Efficiency
As a developer we always bear sustainability in mind while developing our program, especially creating such a computational demanding system. In our system, the most demanding part is the bi-directional encoder representations from transformers (BERT) algorithm. Answering a single question usually takes around 20 seconds on a Nvidia Titan X graphic card. Usually, over 50 questions are generated for harvesting a pdf, which makes the entire extraction more than 15 minutes. And this time will scale up as either the length of the report getting longer, or large amount of reports need to be processed. In order to shorten the time, we observed our algorithm working and found that the conversion of the context takes around 50% of the total time spend on answering a question. To solve this issue, we changed our algorithm from figure 1 to figure 2. In stead of answering one question at a time, we combine as many questions as possible and make all those questions as a single batch. For each batch, the algorithm only convert context once, which greatly reduce the processing time as well as computational power. After making this change, we shorten the processing time of a pdf from more than 15 minutes to 10 minutes, which saves at least 12 hours to process all the pdfs we have.
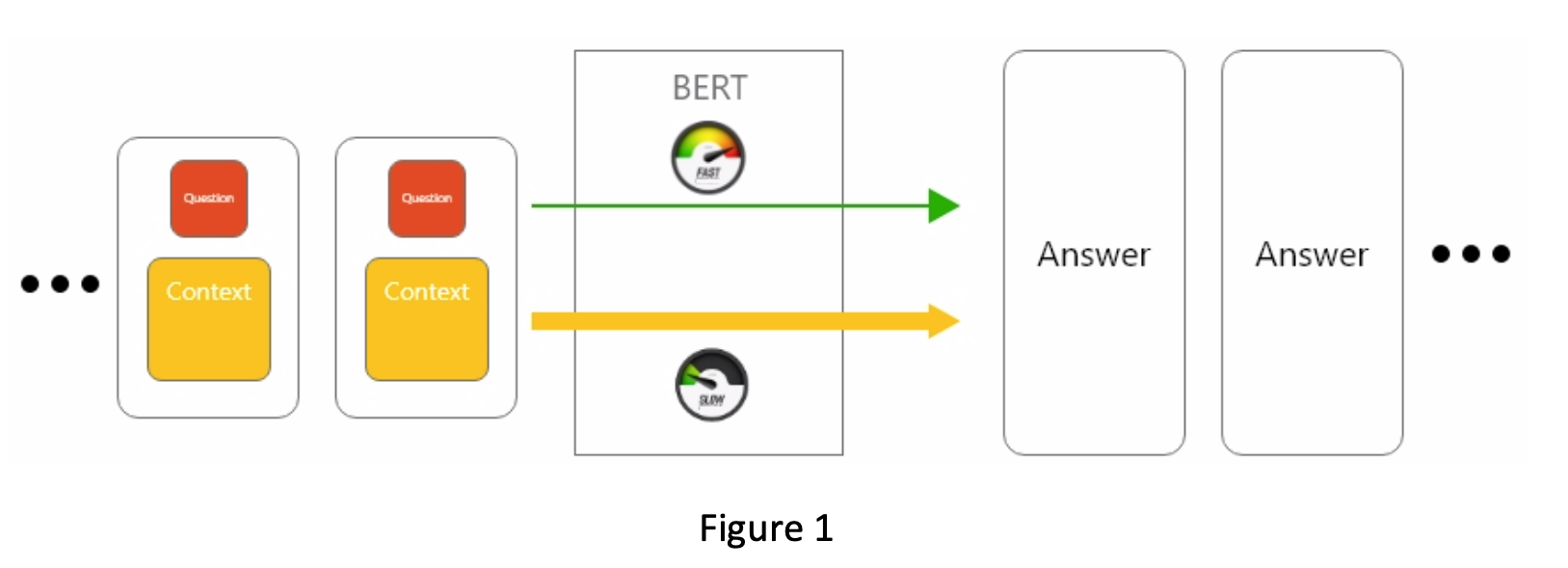
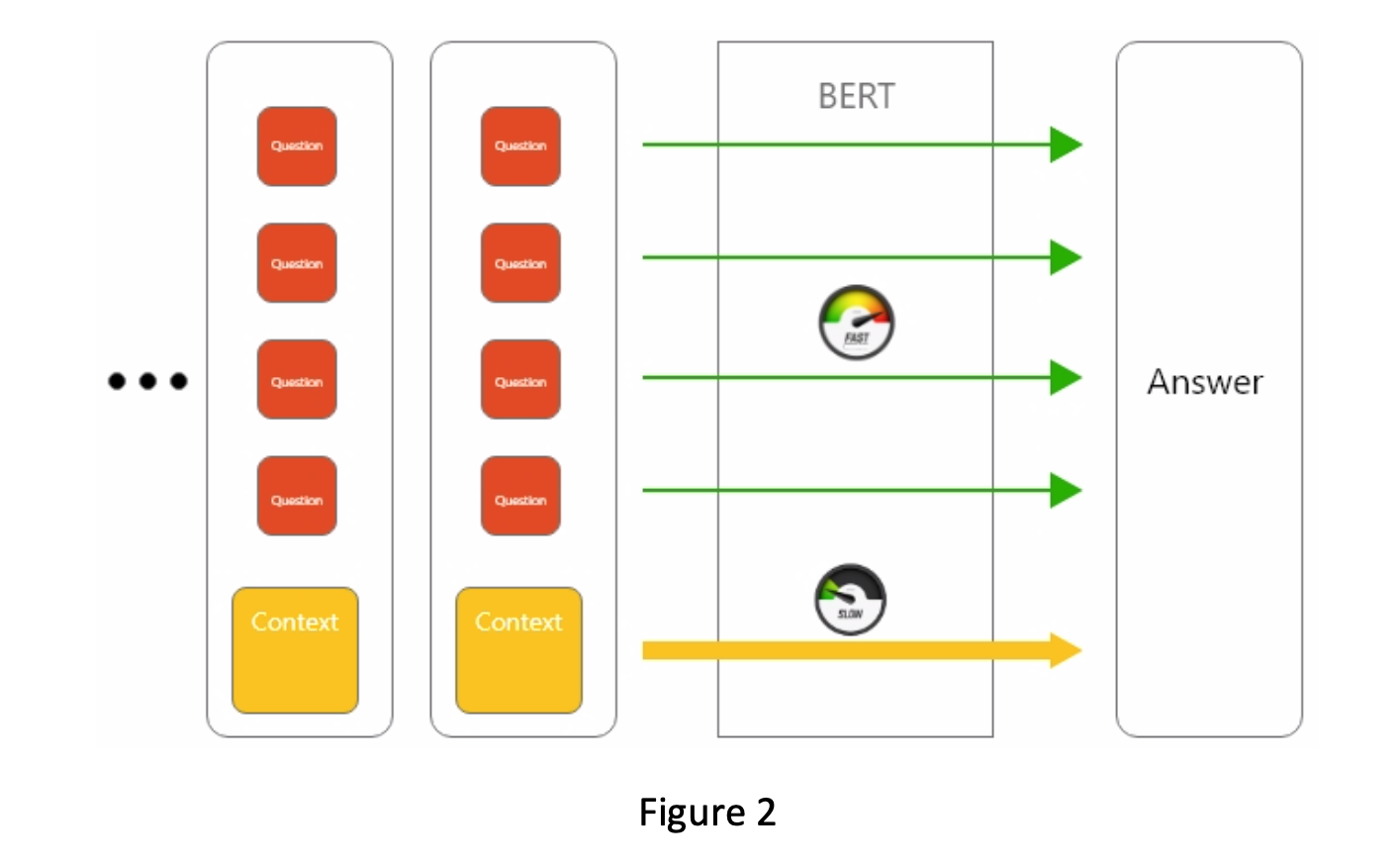
Compatibility
Our programs and data structures are built with the future in mind. We want our project to be extended into the future, so it is important that our code can be compatible with future work. We also want our project to be compatible with any future changes in requirements from the ANCSSC. We believe that this has been achieved in a few ways. Firstly, for our two database structures we have provided our client with the facilities to rebuild and edit them by giving them the raw SQL used to build the database. We have also provided them with CSV files from the data we stored in database 2 if they decide it would be easier to store it offline. In terms of our reportQuery system, we have made effort to split up the code into as many functions and objects as possible, so that components can be changed and re-used as needed in the future. For instance, our solution for storing the answers to questions is stored in two-dimensional dictionary structure designed to imitate the structure of our database. If a future developer wanted to use a different database structure, they could replace the elements in our dictionary with what they needed, while maintaining the core structure underneath.
Maintainability
Designing a program is not hard. Creating a prototype that other programmers can easily improving, maintaining and reusing is hard. Regarding maintainability, we adopted an opensource library that has great community to improve maintainability.
For any possible future development, developer can use any model publish on this community. They cover almost any field, medical, Wikipedia, science, biology, etc., and different language Spanish, Chinese, German, Swedish. This enables unlimited possibility. Using this community for future development, developer can save huge amount of computational power and months of time. Most importantly, all developer needs to do is just change one line of code.

Project management
This project was managed effectively in a few different ways. The cornerstone of any well managed project is an efficient team, which is something we definitely achieved. Our team would regularly check in on Messenger as well often daily physical meetings to keep on on top of tasks.
We were a big believer in working as a group rather than working individually. Commonly, we would schedule a two hour block to work in, discussing what needed to be done and then working hard on whatever task needed our attention. This not only made sure we were actually doing the work, but allowed us to ask questions to one another and keep track of the project as a whole. Often in these kind of projects, teammates can become detached from what others are doing, this was certainly not the case for us.
We tried very hard to establish working timeframes throughout our project, this sometimes proved difficult to stick to, as our plans would often have to adapt to fit around problems we came across or new research we had made. For instance, our timeframe regarding our original PDF extraction solution was completely abandoned when we moved to looking at BERT.
We have worked well as team to successfully meet our requirements. The process has been challenging since we have had to communicate with multiple teams and liaise with multiple people, including Dean for technical support and our NLP expert, Dr. Pontus Stenetorp. Documenting these meetings and updating each other through platforms such as messenger has enabled us to meet our deadlines. Everybody in the team was very supportive of each other and we compensate for each other’s weaknesses by allocating tasks based on our strengths.
During to the situation regarding COVID-19, we switched to Microsoft Teams, as messenger is not easily available in China. This allowed us to efficiently communicate and share resources, so that our project deliverables were of the highest quality possible.
Future Work
Advancements to our reportQuery system
As with any projects, there are plenty of things we would have liked to have done, or hope that future teams would be able to do. Obviously, we wanted to be able to implement a synthetic data generator using a generative neural network to produce the kind of recommendations the UN wanted, but sadly the time-frame prevented this. It is possible such a project would take longer than even 6 months.
On a smaller scale we did want to have tools to do statistical analysis on the data we had produced, but again due to time constraints we put all of our focus into perfecting what we had, i.e. our reportQuery system and database, rather than work on new things.
Applications to other sectors
We believe such systems of querying large amounts of data has real useful applications in many different sectors. Most notably, we believe that this technology has real potential in the health-care sector and the NHS. The NHS handles a lot of letters sent in between staff and patients. Often doctors and nurses have to manually transcribe data from these letters into their database systems or onto separate forms. A BERT system, particularly one well trained on the particular letter dataset, could provide invaluable as a way to save time on paperwork as well as hopefully improving accuracy of transcribed information. This in turn could make the transition into systems such as FHIR much easier. Sheena Visram introduced us to John Booth, the Senior Data Steward for GOSH DRIVE, who seemed very interested in the idea. He told us to work with the MIMIC dataset, a "freely accessible critical care database" containing anonymous health data.
Potential future Systems Engineering project
Sheena suggested to us that a project working with the NHS to retrieve information from these NHS letters could make a great Systems Engineering project for next years cohort. Our team is definitely behind this idea as it would be great to see our work go on to create some real benefit in the health sector.
Cost Matrix
| Element | Cost | Details |
|---|---|---|
| Azure MySql Database | £19.20 per month | Minimum settings - single compute core, 5gb storage. Majority of cost comes from compute core. |
| Azure Cognative Services Computer Vision | (0-1 million requests) £0.746 per 1,000 transactions. | In our case, this has never exceeded £8 a month. Pricing details can be found here. |