Initial research & events of note
Term 1
Initial consultation with our clients
Our first step upon receiving our project details was to communicate directly with our clients, we asked as many questions of them as possible to get a sense of the project. This initial communication was marred by a few misunderstandings, most notably confusion between our teams and the Masters project teams also working for the ANCSSC, however we had the confusion resolved in good time and created a good understanding of our requirements. We also utilised the advice and guidance of Dean Mohamedally and Joseph Greener, who helped us understand the big picture of our project and begin to see a way forward.
Research into data collection methods
In terms of data collection via forms, we looked at platforms such as Google forms and Microsoft forms, as well as other tools such as Excel. Different data collection methods suit different needs, so for more general data, we decided that Microsoft forms would be the most appropriate. For more complex financial information, a form in an excel spreadsheet provides the flexibility we need whilst still providing ample familiarity to users.
Term 2
Conversation with Dr Pontus Stenetorp
Moving into what we considered at the time to be "Phase 2" of our PDF extractor development. We wanted a way to isolate details (e.g. financial records) from a page in which we knew they were present. We decided the best way to go about doing this would be through the use of NLP techniques. We got in contact with a UCL NLP expert, Dr Pontus Stenetorp, and arranged a meeting. In this meeting he explained a few NLP techniques that would have a profound impact on our project from then on. These were "Chunking" and the use of a "BERT" algorithm.
Related Technologies
Databases (Data storage)
Alternative solutions
There are a few different solutions for data storage, including:
- Storing data in files
- MS SQL
- MySQL
- MongoDB
Each has their pros and cons. MS SQL databases are incredibly cheap to host on azure [1] , but are closed source, has no easy way to handle the database graphically, and is a lot more difficult to work with than MySQL [2]. Storing data in files is fine for a small dataset, but with the large amount of data the ANCSSC will be storing in our Database 1, this would become unwieldy. Finally, MongoDB is new and exciting, but does not necessarily allow for the kind of data querying we are looking for [3]
As such, we opted for a MySQL database
Alternative devices
In terms places to host our database structure, the choice was between hosting locally, or using a cloud service such as Azure. Although hosting a database locally is only as expensive as keeping a machine running, for our Database 1, this would require a lot of maintenance and technical know-how to keep running. As such, a cloud service, in this case Azure, might provide an easier solution for the ANCSSC to ensure stability, constant uptime, and easy resource scaling. [4]
PDF extraction
Overview
Extensive research into the creation of a PDF extraction tool has created a whole host of alternative solutions, approaches, devices, and algorithms. Some were immediate dead ends, and some went through development until we managed to find something better. This task took up the bulk of our development time and was by far the most complex and difficult element of our project. We knew from the start that a perfect solution was almost impossible, and our aim has always been to create something that provides as much usefulness as possible. The technologies and solutions below will mostly be in chronological order of development.
Alternative solutions
"Automatic", "Semi-Automatic", and "Manual" processing
An issue we kept debating during initial research and planning was how much of this process should automated or left as manual. At the beginning of the project, we struggled for a long time to find any solution that would be effective over a large number of documents, and as such leaned much more heavily on making the process semi-automatic or mostly manual. Obviously the drawback of such a scenario would be that it would take a lot more time and effort to extract useful data from PDFs. After the discovery of BERT we realised that we could in fact do most of the extraction automatically as intended. The end result is that of a mostly automated system. We were unable to find an efficient and reliable way to extract data from tables, so that part may have to be done by hand, but all text extraction can be handled automatically.
Alternative algorithms
PDF extraction - LDA and t-SNE
Our initial research focused heavily on few key aspects. First was how we were going to implement the PDF extractor tool. Following the advice of Joseph Greener, we looked at the LDA (Latent Dirichlet allocation) [5] and t-SNE (t-Distributed Stochastic Neighbor Embedding) [6] algorithms. This lead us to a project written by a previous UCL student, David Rudolph, which could analyse an uploaded PDF. [7] The project consisted of a Python program and it's corresponding dissertation. A screenshot of the python program is shown below, having uploaded one of our PDF files.
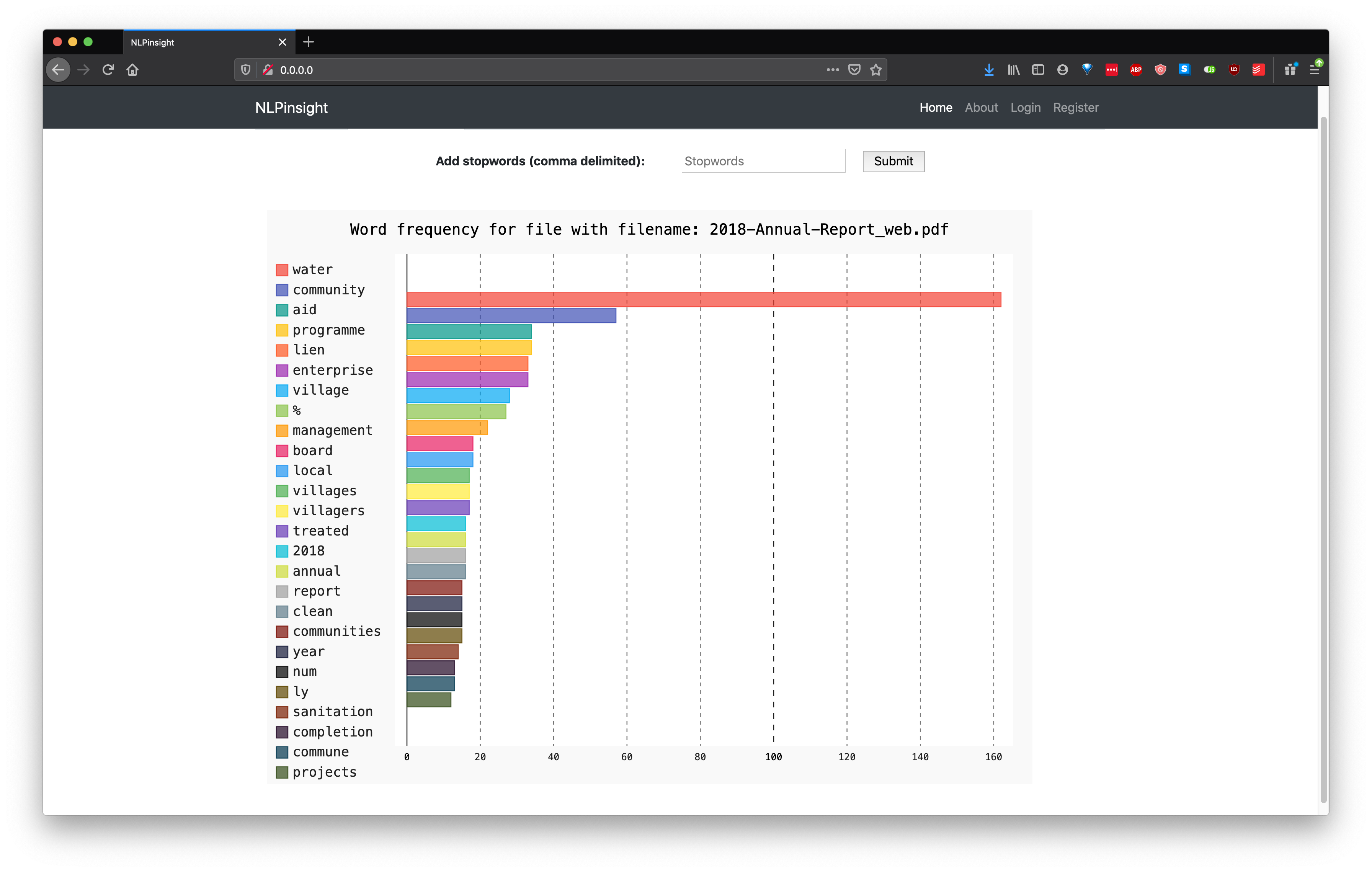
Eventually we decided to move away from these algorithms, believing them to be overkill for our situation, especially due to the fact that the example we had from David Rudolph was effectively a "Black Box" which we were struggling to make sense of.
Yansong in particular read a lot of documents relating to using machine learning to analyse and extract text including:
- Teach Machine to Comprehend Text and Answer Question with Tensorflow
- Machine Learning — Text Processing
- Mining Text Data
- Building a Machine Learning Based Text Understanding System
Azure Cognitive Services (ACS)
After moving away from LDA and t-SNE, we began looking at services that could perform the tasks we needed, after looking at tools such as Google's OCR service, we came across Azure's Cognitive Services. This service can be queried via an API and seems to contain many of the features we are looking for, such as the Ink Recogniser and Text Analytics tools.
These services allow the best text extraction from PDFs that we've found. We can send an image of each PDF page to the ACS server and receive a json of the text within for us to analyse.
Table extraction using Azure Cognitive Services (ACS)
Right at the end of term 1, we discovered that Azure had recently released a beta feature for form extraction on ACS [8], we were quite excited by this, and requested access to the feature. However, after receiving access and trialing the feature, we discovered we had not quite understood the full details of the product, and the feature was only suitable for working with large datasets of the same table, which we do not have, as tables in every document are completely different. As such, ACS table extraction was abandoned.
Table extraction using "tabula"
As part of continued research into table extraction techniques, we looked into a tool called Tabula [9], a Java-based tool for "liberating data tables locked inside PDF files". Github user chezou built a wrapper for this tool for use in Python [10]. This work was interesting, but presented a huge problem. The dataset it produced was very messy, with lots of formatting inconsistencies and garbage data. Some tables were better than others, but creating an algorithm that could distinguish the two and produce any meaningful output was simply too big of a project for us, given time contraints were were under.
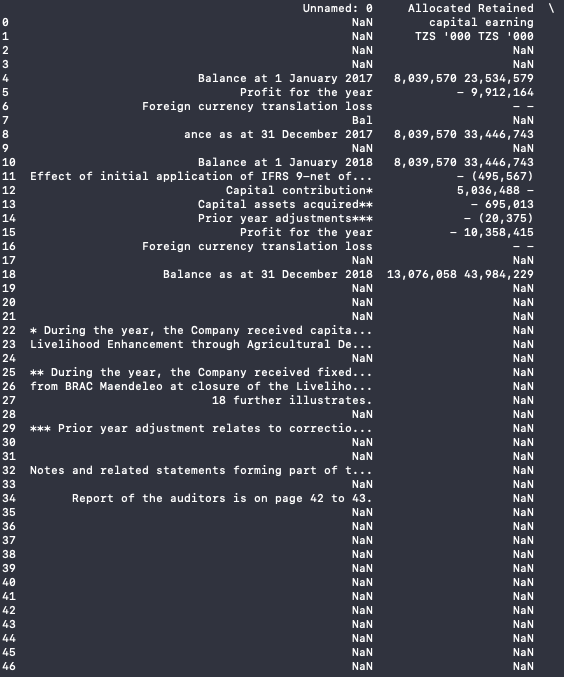
This table contains a lot of garbage data, making it difficult to ascertain what the values are for
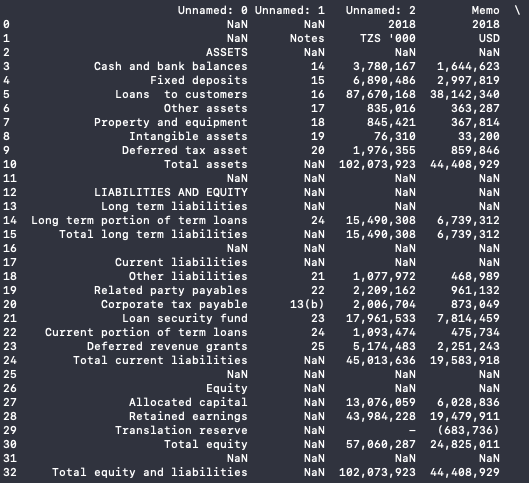
This table is structured a lot better, but the values for the column headings are missing, again making it very difficult to relate the data to any meaningful output.
Chuking
As part of research, I used NLTK software available online to construct an abstract syntax tree for a passage with corresponding labels. Each word is tokenized and labelled corresponding to a dictionary of labels relating to the word type. This was an alternative brute-force method, as proposed by our NLP expert Dr. Pontus Stenetorp, to replace our machine learning solution. The main purpose of the chunking method was to extract numeric information because they had separate labels (NP) to the surrounding information. The aim was to extract financial information. When a passage was passed into the NLTK software for chunking, a subtree was created, with labels for each word in the passage. This subtree could be traversed to search for numeric data. I decided not to pursue this algorithm because we found that the machine learning solution, BERT, was much more powerful.
The BERT Algorithm
BERT - what is it? [11]
BERT stands for Bidirectional Encoder Representations from Transformers.
Essentially BERT uses large amounts of existing text, as well as reading comprehension style questions and answers, to pretrain a model’s parameters using self-supervision. This requires no data annotation – the model learns itself. Self-supervised training techniques are more beneficial as they have less reliance on time and resource-intensive data labelling. This avoids the need for developers like us to train a machine learning model for natural language processing from scratch and instead one can start from a model with knowledge of the language.
BERT is a contextual model and so each word representation is based on the words in the sentence. BERT represents a word based on the words both before and after it (hence bidirectional). Bidirectional implementations are difficult to implement which is why the technology is very new. Bidirectional models cannot be trained by conditioning each word on its previous and next words – this would allow the word being predicted to “see itself” in a multi-layer neural network. This is why some words in the input are masked and each word in the sentence is conditioned bidirectionally to predict the masked words. BERT can also model relationships between sentences, added to the model’s ability to understand context.
On the SQuAD dataset, BERT achieves a 93.2% F1 score (F1 is a measure of accuracy) compared to a human-level score of 91.2%.
Why is there a need for BERT?
One of the biggest challenges in NLP is lack of training data. This is because training data tends to be task specific and so little training data is available for these distinct tasks. To close this data gap, researchers have developed a variety of techniques for training general purpose language representation models using the huge amount of unannotated text on the web (pre-training). The pre-trained model can be fine-tuned on small-data NLP tasks like question answering and sentiment analysis, resulting in substantial accuracy improvements compared to training on these datasets from scratch. With BERT, anyone can train their own state-of-art question answering system.
RoBERTa [12][13]
A Robustly Optimized BERT Pretraining Approach
A research group at Facebook AI conducted a replication study of BERT and showed that hyperparameter choices have a significant impact on the final results. They produced a research paper which carefully measures the impact of many key hyperparameters and training data size. RoBERTa, the new version of BERT, has improved design choices.
RoBERTa builds on BERT’s language masking strategy, where the system learns to predict intentionally hidden sections within unannotated examples. RoBERTa, implemented in PyTorch unlike BERT and ALBERT, modifies key hyperparameters in BERT. This includes removing BERT’s next-sentence pretraining objective and instead training with larger batches. This improves on masked language modelling compared to BERT and leads to better performance. This was a previously unexplored design choices.
ALBERT [14]
This is a very new algorithm, coming from a Google AI blog dated 20/12/2019 (reference above).
ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
This is an upgrade to BERT (from a year ago) and advances state-of-art performance on 12 NLP tasks, including the Stanford Question Answering Dataset (SQuAD v2.0). It has been released by Google as an open-source implementation built on top of TensorFlow and includes multiple ALBERT pre-trained language representation models. Google AI improved on BERT, a new approach to NLP, by furthering their understanding of what is contributing to language-understanding performance. There are multiple factors such as network’s height (number of layers in neural network), its width (size of hidden layer representation), learning criteria for self-supervision. The ALBERT model manages to optimize performance by allocating the model’s capacity more efficiently. Input-level embeddings (words, sub-tokens) need to learn context-independent representations, whereas hidden layer embeddings refine that into context-dependant representations. For example, the word “bank” can be in the context of finance or rivers. Another critical design difference for ALBERT is that it eliminates redundancy by parameter sharing across the layers (the same layer is applied on top of each other). Other Transformer-based neural network architectures, such as BERT and RoBERTa, rely on independent layers stacked on top of each other. However, Google AI observed that the network performed similar operations at various layers, using different parameters of the network.
Google have shown that accuracy of models based on BERT depends on developing robust, high-capacity contextual representations. The context, modelled in the hidden-layer embeddings, captures the meaning of the words, which in turn drives the overall understanding, as directly measured by model performance on standard benchmarks.
We chose ALBERT because when it is trained on the same larger dataset as RoBERTa, it outperforms all models to date with a score of 89.4.
Fine-tuning
As part of our research, we decided to fine-tune different models on the SQuAD dataset multiple times, in order to choose the model and number of times resulting in the highest accuracy. This process was extremely time-consuming and resource-intensive, requiring machines running overnight and powerful GPUs for processing. Due to many file permission issues, we dedicated almost 2 weeks to this fine-tuning process.
Ultimately, due to time-constraints, we decided the small improvement in accuracy did not justify the time being spent on it and decided not to pursue fine-tuning. Instead, we implemented an ALBERT model which had been trained once, as this had the highest accuracy of according to the SQuAD rankings [15].
Testing BERT versions
There are several different types of BERT algorithm. As part of our research we wanted to compare different versions and methods to find the one with the highest accuracy. There are two accuracy metrics to compare. The "exact" accuracy, that is, BERT returns exactly the right answer, and "hasAns" (has answer) accuracy, where BERT returns a sentence that contains the answer we are looking for. From the testing we did, we found that the hasAns accuracy was much higher than the exact accuracy.
We were also changing two different variables. First the particular version of BERT, including ALBERT - a more lightweight version of BERT, as well as how the number of "passes" would affect the accuracy result. This refers to how many times we run the algorithm over the data, and generally more passes means a higher accuracy, at the cost of time taken to run. Due to time constraints and technical problems we were not able to run that many tests, but our results are shown below.
| Type | Accuracy | ||
|---|---|---|---|
| Model | Passes | Exact | hasAns |
| BERT | 2 | 43% | 90% |
| BERT | 3 | 46% | 93% |
| ALBERT | 3 | 44% | 94% |
Alternative APIs, libraries, etc
The open source components for the project consist of ALBERT and the Hugging Face Transformers library. The Hugging Face python wrapper for ALBERT is released under an Apache licence, which means the software can be distributed or modified for any purpose. The paid services which we are using include Azure’s Cognitive Services Computer Vision OCR API to convert pdf files into text and Azure cloud services to host our database. Whilst there are open source OCR tools available, after researching and comparing different tools, our team thought the price justified the increase in accuracy which is essential for our project.
Summary of final decisions
Given the research above, our final decision was to use an ALBERT based algorithm using a single pass to produce our reportQuery solutions. This utilises Azure's Cognitive Services API. Our databases are hosted on Azure's MySQL database hosting service.Similar Projects
Daniel Lahlafi's work
Throughout the Systems Engineering module Daniel Lahlafi came up with a few interesting ideas and techniques regarding NLP and BERT that presented useful comparisons to our project.
Daniel had initially developed a version of the TF-IDF (term frequency - inverse document frequency) algorithm. This algorithm is able to rank words by their importance. "The importance increases proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus." [16]. We thought such an algorithm could be useful for the extraction of important information from our NGO reports, however this algorithm is not really designed for accurate retrieval of small items of data from such a large and varied dataset as our reports. It became clear that a more complex solution would be necessary, this complex solution became BERT in later weeks.
After our conversation with Dr Pontus Stenetorp and our discovery of the BERT algorithm. We explained to Daniel how it works, and in parallel to the development of our ALBERT solution he utilised a different Hugging Face Tranformers BERT model to build a web api for question and answering, found here. This presented an interesting comparison to our own work. The model he used was much more lightweight than ours, which presented a few trade offs. His model was able to process text faster, but had a limited number of characters of data you could include in the requests. Our model was larger and took longer to run, but can run on any length of text (vital for working on NGO reports) and was arguably slightly more accurate.
Lack of similar PDF extraction projects
In all of our research, we could not find similar projects that involved the kind of PDF extraction we had set out to do. We are not sure as to the reason behind this, maybe before BERT such large-scale extraction was difficult or impossible. As far as we can see, such a project as ours, especially including a cutting-edge machine learning algorithm like BERT, has never been done before.
Use of BERT at Google
Google has poured a lot of research into BERT, having specifically developed their own pre-trained models using TensorFlow [17]. They use it as part of their Search systems, allowing them to better understand "longer, more conversational queries", used in about 1 in 10 queries in the US [18]. Although their use of BERT is based on a different dataset to ours, I think this speaks volumes as to the power of BERT to find valuable information from unstructured text.
Citations
[1] “MongoDB vs MySQL Comparison: Which Database is Better?,” Eugeniya. [Online]. Available: https://hackernoon.com/mongodb-vs-mysql-comparison-which-database-is-better-e714b699c38b. [Accessed: 25-Mar-2020].[2] “Pricing - Azure SQL Database Managed Instance: Microsoft Azure,” Pricing - Azure SQL Database Managed Instance | Microsoft Azure. [Online]. Available: https://azure.microsoft.com/en-us/pricing/details/sql-database/managed/. [Accessed: 25-Mar-2020].
[3] M. T. S. E. Team, “SQL vs. MySQL - What is the Difference?,” MyThemeShop, 31-Aug-2019. [Online]. Available: https://mythemeshop.com/blog/sql-vs-mysql-difference/#d. [Accessed: 25-Mar-2020].
[4] Jan-Eng, “Pricing tiers - Azure Database for MySQL,” Pricing tiers - Azure Database for MySQL | Microsoft Docs. [Online]. Available: https://docs.microsoft.com/en-gb/azure/mysql/concepts-pricing-tiers. [Accessed: 27-Mar-2020].
[5] T. Doll, “LDA Topic Modeling,” Medium, 11-Mar-2019. [Online]. Available: https://towardsdatascience.com/lda-topic-modeling-an-explanation-e184c90aadcd. [Accessed: 27-Mar-2020].
[6] L. van der Maaten, “t-SNE,” t-SNE. [Online]. Available: https://lvdmaaten.github.io/tsne/. [Accessed: 27-Mar-2020].
[7] dr1012, “dr1012/NLPinsight,” GitHub repository. [Online]. Available: https://github.com/dr1012/NLPinsight. [Accessed: 27-Mar-2020].
[8] “Form Recognizer – AI document extraction service: Microsoft Azure,” Form Recognizer – AI document extraction service | Microsoft Azure. [Online]. Available: https://azure.microsoft.com/en-gb/services/cognitive-services/form-recognizer/. [Accessed: 27-Mar-2020].
[9] “Tabula is a tool for liberating data tables locked inside PDF files.,” Tabula, 04-Jun-2018. [Online]. Available: https://tabula.technology/. [Accessed: 27-Mar-2020].
[10] Chezou, “chezou/tabula-py,” GitHub repository, 08-Mar-2020. [Online]. Available: https://github.com/chezou/tabula-py. [Accessed: 27-Mar-2020].
[11] “Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing,” Google AI Blog, 02-Nov-2018. [Online]. Available: https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html. [Accessed: 31-Mar-2020].
[12] Liu, Yinhan, Ott, Goyal, Naman, Joshi, Chen, Danqi, Levy, Omer, Lewis, Mike, Zettlemoyer, Luke, Stoyanov, and Veselin, “RoBERTa: A Robustly Optimized BERT Pretraining Approach,” arXiv.org, 26-Jul-2019. [Online]. Available: https://arxiv.org/abs/1907.11692. [Accessed: 31-Mar-2020].
[13] “RoBERTa: An optimized method for pretraining self-supervised NLP systems,” Facebook AI Blog. [Online]. Available: https://ai.facebook.com/blog/roberta-an-optimized-method-for-pretraining-self-supervised-nlp-systems/. [Accessed: 31-Mar-2020].
[14] “ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations,” Google AI Blog, 20-Dec-2019. [Online]. Available: https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html. [Accessed: 31-Mar-2020].
[15] “SQuAD2.0,” The Stanford Question Answering Dataset. [Online]. Available: https://rajpurkar.github.io/SQuAD-explorer/. [Accessed: 31-Mar-2020].
[16] “idf :: A Single-Page Tutorial - Information Retrieval and Text Mining,” Tf. [Online]. Available: http://www.tfidf.com/. [Accessed: 31-Mar-2020].
[17] Google-Research, “google-research/bert,” GitHub repository, 11-Mar-2020. [Online]. Available: https://github.com/google-research/bert. [Accessed: 31-Mar-2020].
[18] P. Nayak, “Understanding searches better than ever before,” Google, 25-Oct-2019. [Online]. Available: https://www.blog.google/products/search/search-language-understanding-bert/. [Accessed: 31-Mar-2020].