Project Background
We are working with the Alliance of NGOs and CSOs for South-South Cooperation (ANCSSC) to assist in their efforts to improve and assist NGOs within their remit. The ANCSSC's mission is to "enhance civil society’s understanding of the value of South-South Cooperation in developmental, humanitarian and related spheres." They achieve this particularly through their focus on their Sustainable Development Goals (SDGs).

Broadly, this project aims to start on a process of creating a way in which the ANCSSC can review and compare the effectiveness and sustainability of NGOs and their projects. We have been working on building the tools required to construct a dataset of useful information, on top of which modeling, most likely through some form of synthetic data generation, can find patterns and useful analytics in the data we collect.
Requirement gathering
The requirement gathering for this project been quite a complex journey. The original problem statement was left deliberately vague to allow movement in what particular direction we took. After a lot of back-and-forth between ourselves and multiple different sources including our clients, machine learning specialists, and members of the Computer Science Department, notably Dean Mohamedally, we managed to draw some reasonable requirements. Originally our project was going to be more focused on the creation of a Generative Neural Network in order to build a dataset that can be used to model the success of the NGO members of the ANCSSC. As we have continued to gather and understand our requirements, we and our clients realised that the major obstacle for us to overcome is in fact the data gathering from the NGOs. In particular, this involves extracting relevant information form annual reports of NGOs working under the ANCSSC, as well as building a corresponding database structure.
We have found it a challenge to truly nail down our requirements in term 1, and they continued to shift during term 2 as we continued to talk to our clients as well as experts in machine learning, such as Dr Pontus Stenetorp, who gave us great insight into different machine learning mechanisms we could use for our PDF extraction tool, including the BERT algorithm.
Sources of requirement gathering such as the use of surveys are not possible in our case. The user-base of our software is incredibly niche, consisting of ANCSSC employees.
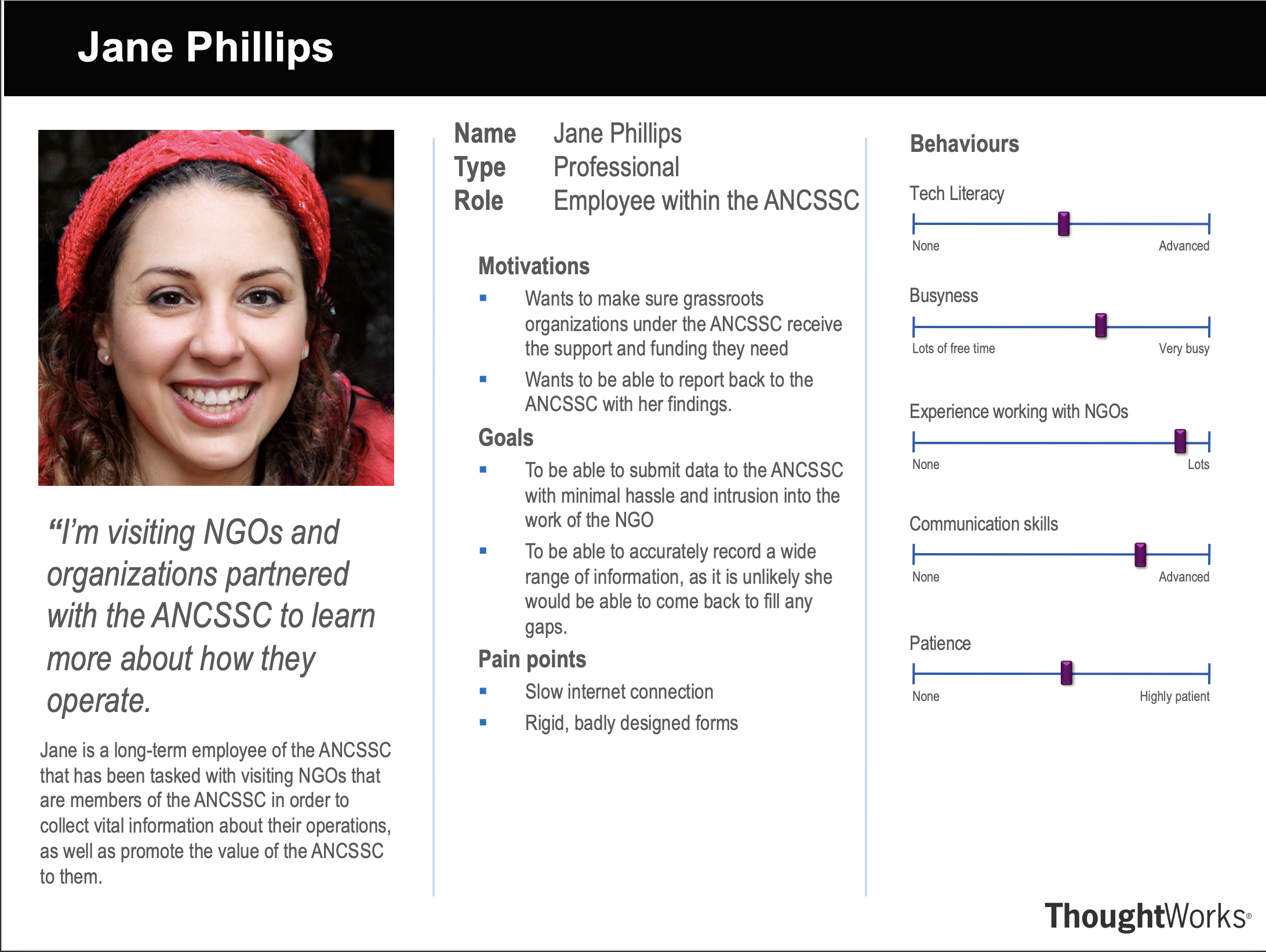
Persona

Project Goals
Initially the goal of this project was focused around building this Generative Adversarial Network (GAN) in order to create a decision-making tool for the UN. Although we would love to attempt this, after long consultations with our clients and members of staff at UCL, we have scaled back our ambitions to focus on building the dataset. Fundamentally, we want to be able to collect and store as much data from these PDF records as possible, and assist the development of a web app for the ANCSSC through the creation of a database, as well as a few other supplementary requirements.
Therefore in overview, we will build two database structures, one to contain data collected via a form submitted by NGOs, and the second to contain data scraped from NGO reports, which is essentially a collection and synthesis task from unstructured data. We will also build the PDF extraction tool to scrape this data from the NGO reports.
MoSCoW List (Iteration 2)
| ID | Requirements | Priority |
|---|---|---|
| 1 |
Database 1 -ANCSSC database for web app (used by Team 37 and Masters team)
|
MUST |
| 2 |
PDF data extraction tool
|
MUST |
| 3 |
Database 2 (UN "Knowledge-base")
|
MUST |
| 4 |
Quality documentation for PDF extraction tool
|
SHOULD |
| 5 | Statistical analysis tool
|
COULD |
| 6 | Front end access to database 2
|
COULD |
| 7 | Build generative adversarial network (GAN)
|
WOULD LIKE |
| 8 | Machine Learning based recommendation algorithm
|
WOULD LIKE |
| 9 | Link database 1 & 2 into a single coherent structure | WOULD LIKE |
Reasoning behind MoSCoW requirement changes
The MoSCoW requirements list seen above is different to the one found on the prototype 1 website. This is due to numerous developments and consultations made with our clients, other members of the ANCSSC, and other UCL teams
A link to the prototype 1 website can be found on the home page
Data-Collection form removed
This requirement was removed for two main reasons. Firstly, we originally wanted to collect financial information we could use for analysis, however Dr Husna Ahmad, the steering committee coordinator for the ANCSSC, explained that most NGOs do not want to give up such information, or don't have access to it in the first place.
Secondly, we realised after consultation with the Masters team that everything our forms were going to do was handled by them, thus making the forms not a priority
Front end for Database 1 removed
We were originally going to build a way to access Database 1, however this will be entirely handled by the Masters team
Server unit for PDF extractor removed
This requirement was removed due to budgetary constraints. The cost of resources required to run our extraction tool on a cloud service such as Azure was simply beyond the scope of the ANCSSC's budget. As such, our tools will be run from the ANCSSC's computers.
Statistical analysis tool moved to could
This tool is something we originally wanted to build as part of our project, however simply due to time constraints along with prioritisation, this was deemed not as essential as the continued work on the extraction algorithm.
Front end access to db 2 moved to could
Along with the analysis tool, this was deemed to be less essential than other aspects of our project. Data within the database can still be viewed from free database clients such as DBeaver.
GAN, machine learning model, and linking of two databases moved to would like
These requirements were always going to be long-shots and most likely unobtainable in the time-frame that we had, thus are more fitting as "would-like" requirements.
Use cases
Due to the nature of our project, it is difficult to provide concrete use cases for our current work. It is inherently research based and will hopefully go on to be used by future teams. Our system architecture diagram demonstrates the main use-case for our system.