For each new iteration and new feature we implemented subsequently meant we had to test that it was performing correctly, this is known as a test-driven development approach. TDD and the agile development process we had in place worked well together in carrying out continuous iterations.
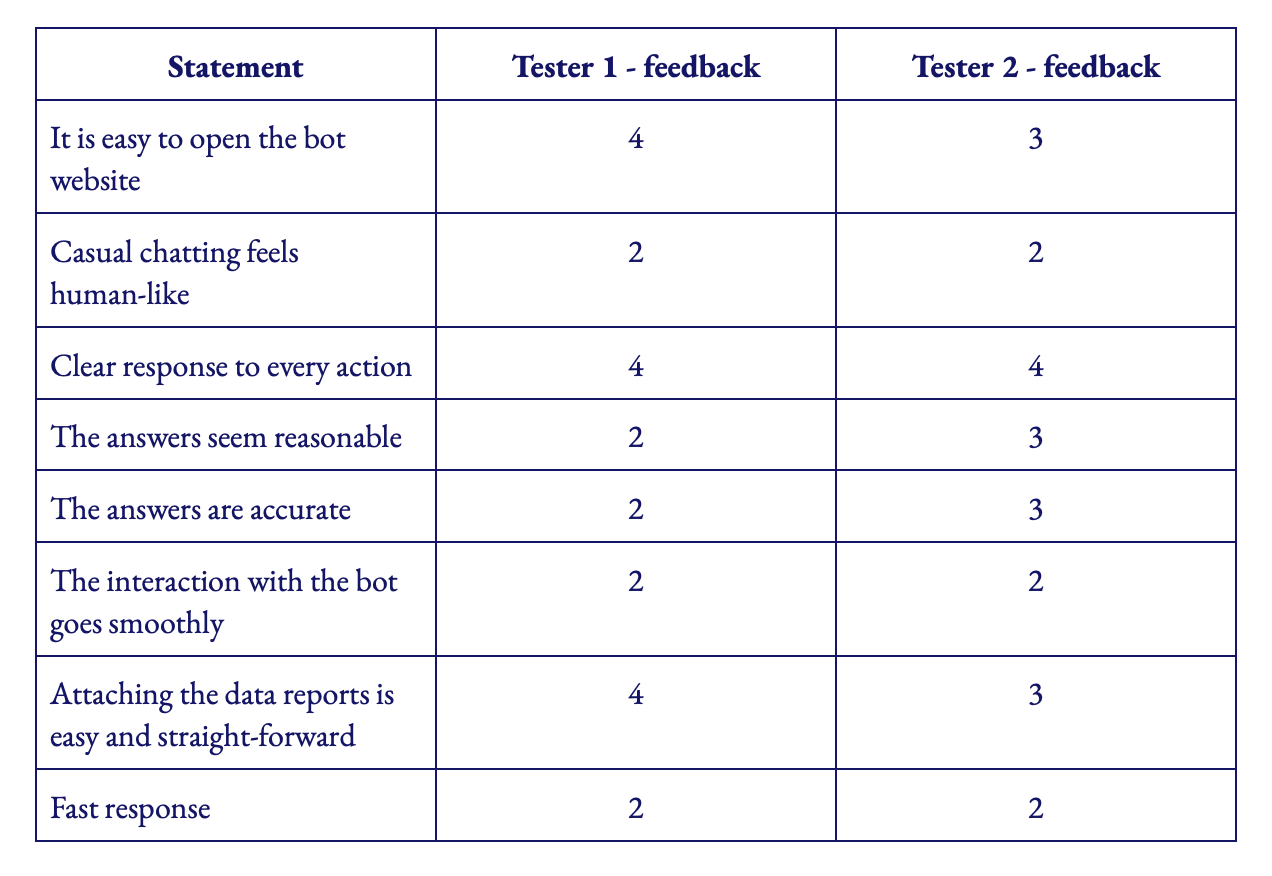
Agile software development advocates frequent short development cycles. In this first cycle we generated unit tests and our aim was to evaluate the accuracy of our fine-tuned TaPas model, the testing approach was not to pass every test. Instead, we would calculate the ratio between successful and failed tests, then constantly fine-tune the TaPas model to bring the success rate up through further iterations. It showed us where our model was working well and where we could improve and focus on.
Our second major implementation saw the completion of the bot pipeline and user interface. Following this completion we generated a file to validate and test dialogues end-to-end by running through test stories. This helps us evaluate that the bot behaves as expected. Testing TaPas on test stories is the best way to have confidence in how the assistant will act in certain situations.
Even though we used open source packages, we are also required to create some self-defined modules to link the functionalities and extend some features.
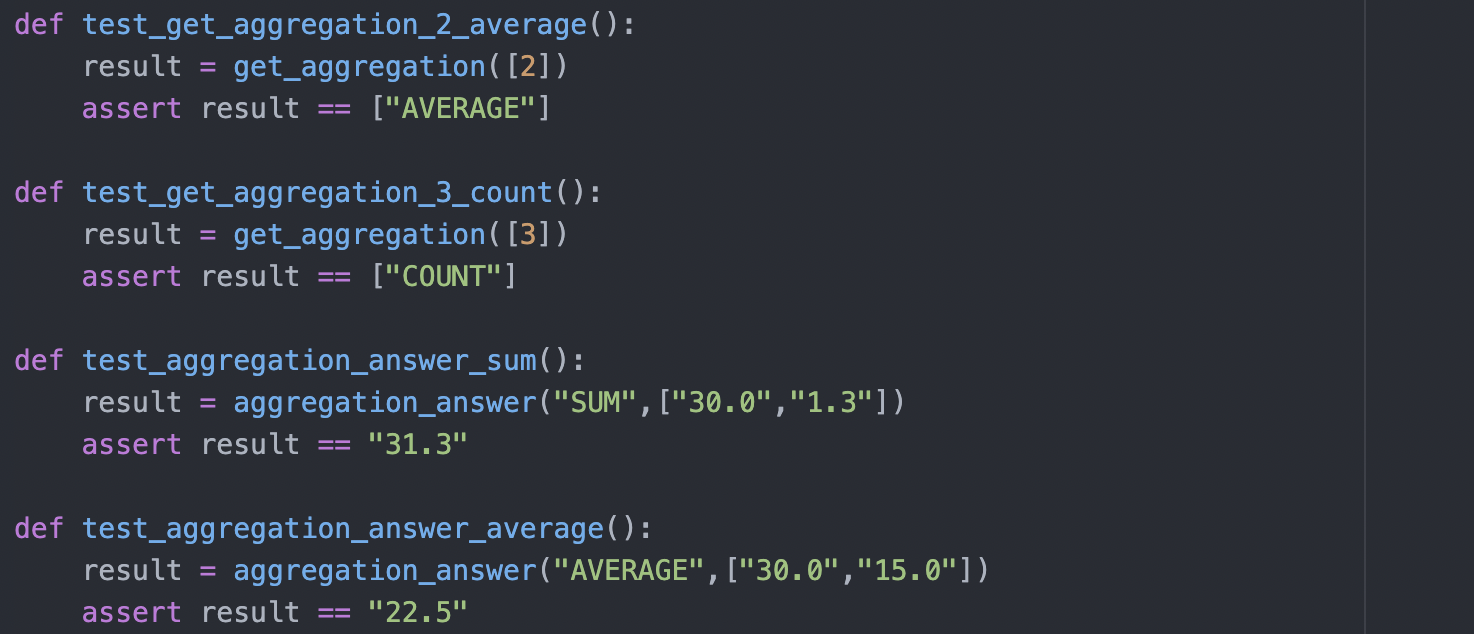
To process the logits or coordinates returned from TaPas model prediction, auxiliary functions are required. They are written as per needs with some references to tutorials or guide sources [1]. Tests are required to ensure that they work as expected and will not break the system or return false answers.
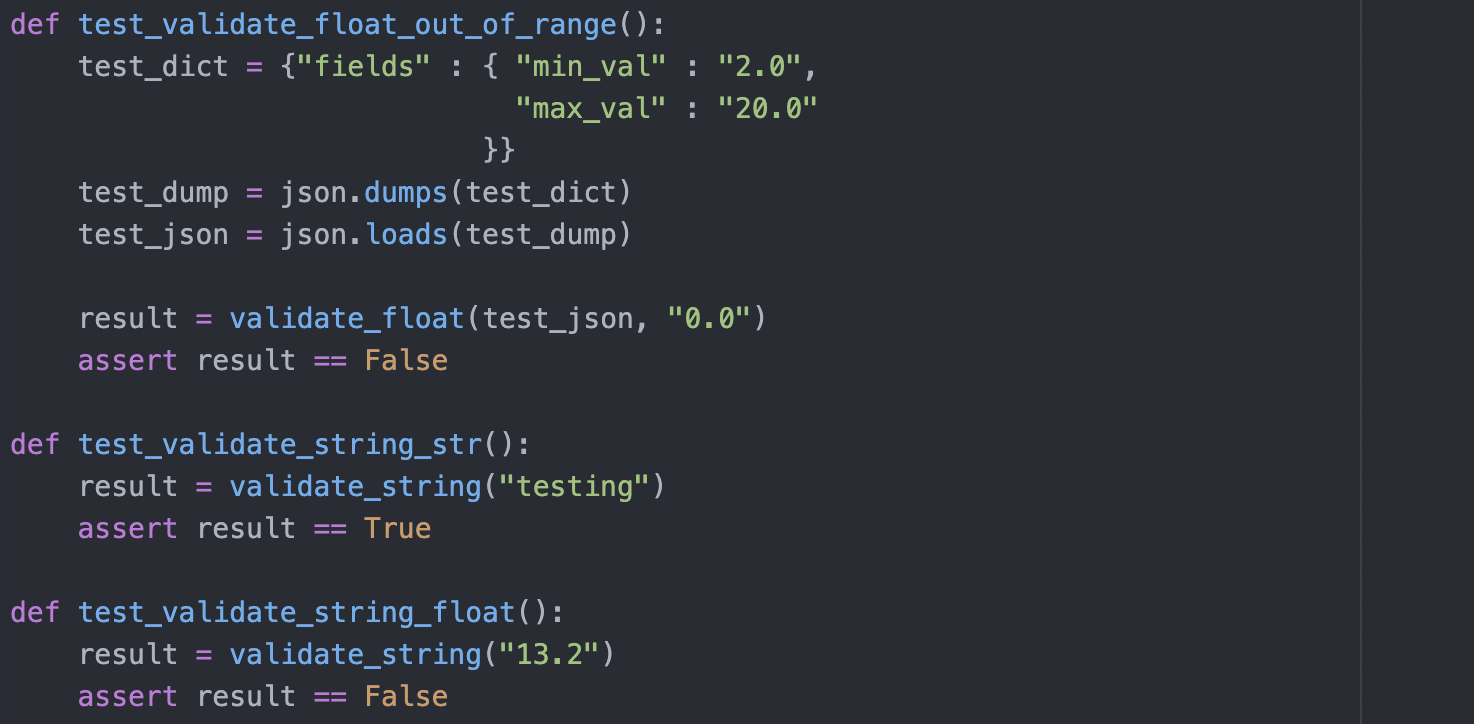
Where applicable and allowed, post processing and validation functions are tested to check if they return the expected processed answers. The functions that involve requesting an endpoint could not be tested as a running server is required. However, we extracted validation functions to be their own, and therefore could be tested where relevant. As for endpoint related functions, they have their own tests in the Django database. Thus, the working of the functionalities are ensured.

Tests for both self-defined modules are ensured to pass to avoid any possible errors or bugs.
Reference: [1] Hugging Face TAPAS - Usage: Inference [Online] Available at: https://huggingface.co/docs/transformers/model_doc/tapas#usage-inference [Accessed: 3 March 2022]
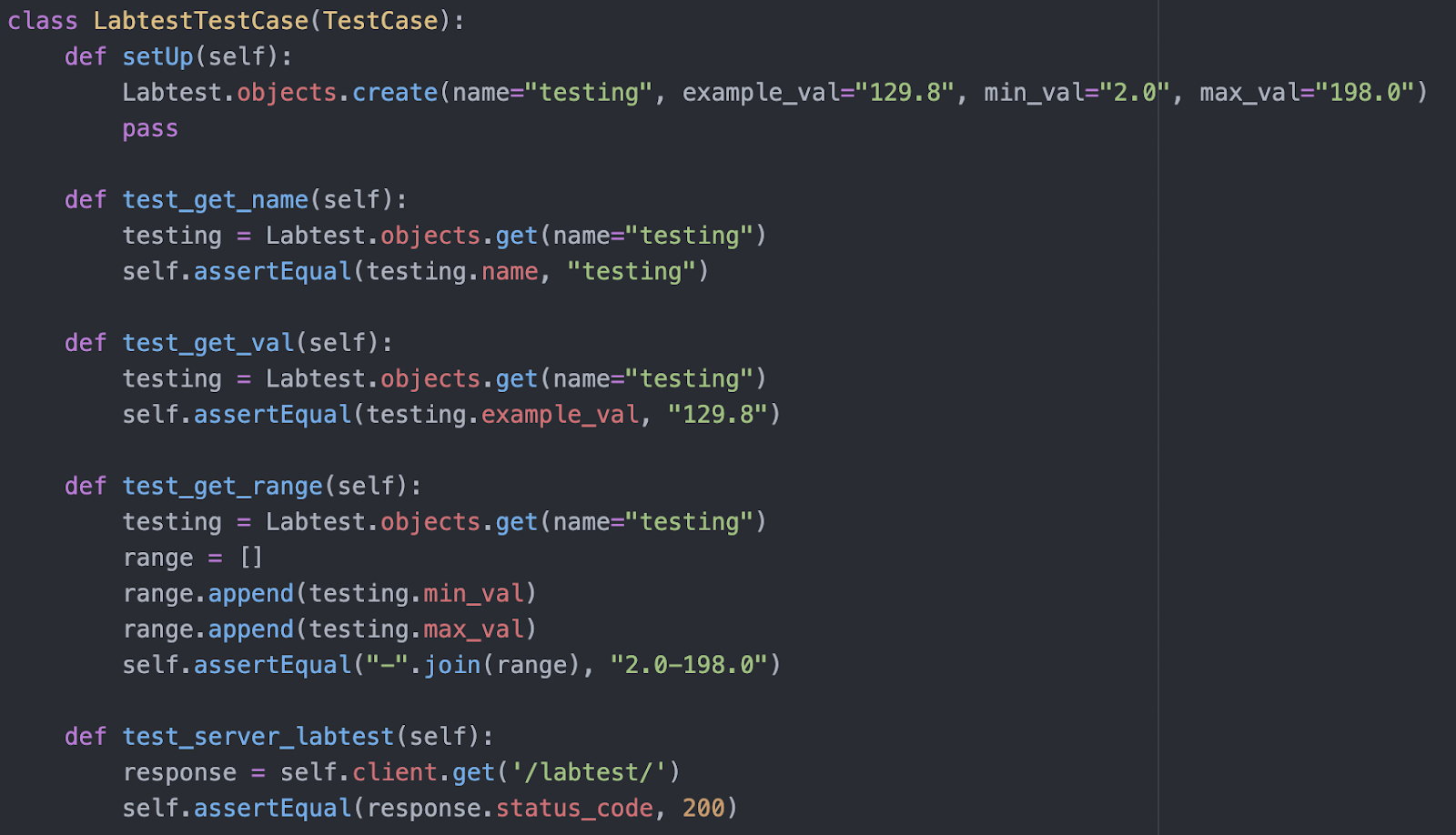
We utilised the Django built-in testing functionality to ensure that whenever an object with the stated entity value is requested, the correct entry is returned. Apart from that, the server endpoint is simulated and tested to ensure that the server works well and returns a success response whenever a request is sent. As our database model is very small, the tests which can be carried out are limited and therefore, the test number is small as well.
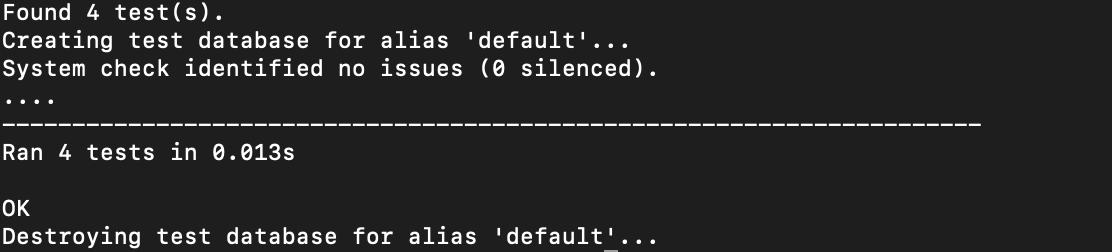
The results are shown in the photo. The database’s functionality is tested and all tests are expected to pass. If any failures occur, iterations are carried out to fix the bug as soon as possible.
To ensure that the system is working and all parts are coordinating well, we carried out integration testing with the chatbot. This is to ensure that the dialogue flow is working and actions are triggered correctly according to the user’s intents.
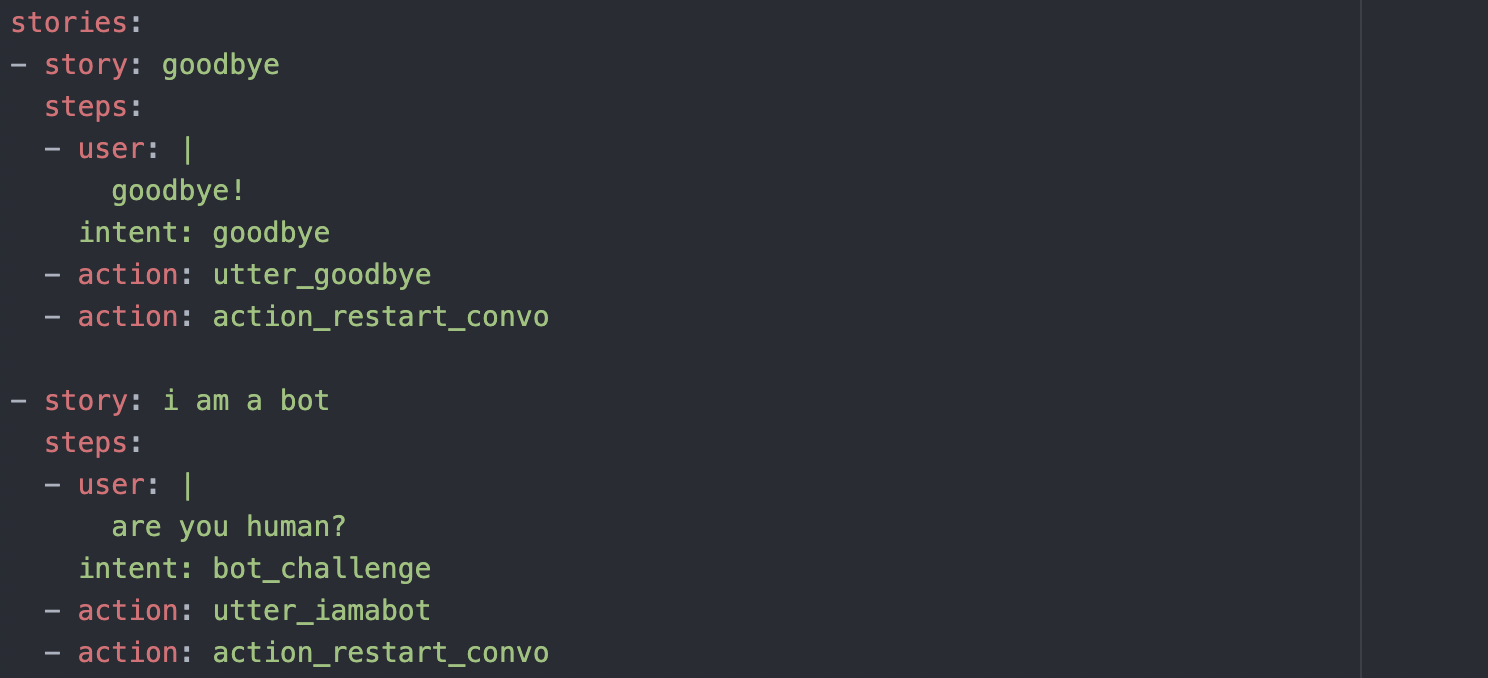
To ensure that the bot correctly identifies the intent of the user and the next action to take, tests are written in the form of stories to check the correctness of the dialogue flow. As shown in the photo, the user's input is simulated through the “user” field and the bot’s decision has to match the indicated intents and actions.
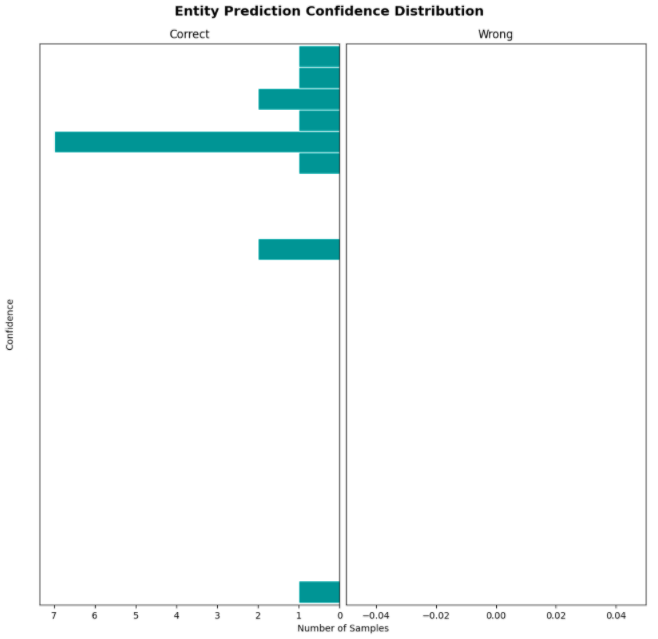
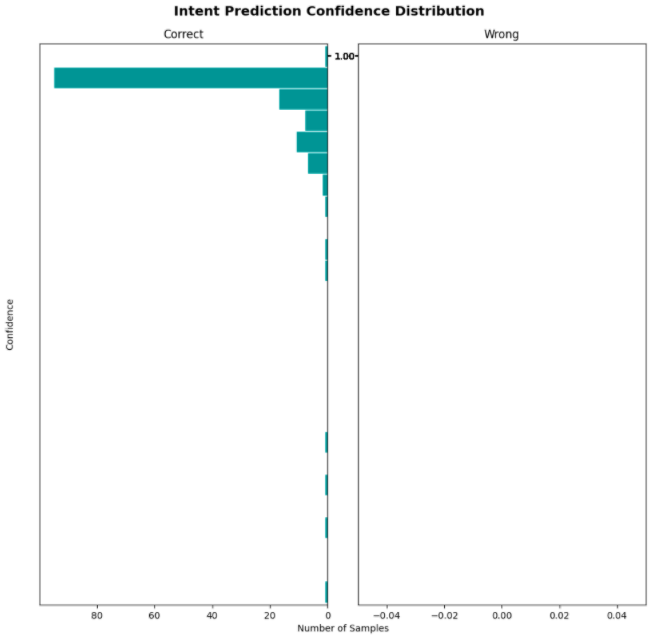

By doing so, we are able to test if the system works smoothly and the respective modules or functions associated with the actions are triggered when appropriate.
To check how well our bot performs in the eyes of possible users we decided to expose our bot to 2 testers. These users have different backgrounds, different intentions, and skills. They both have no specialised technological knowledge, but are able to perform basic computer tasks, such as opening a browser, searching through files stored on the computer.
These users reflect people who are most likely to be using the bot in the future and receiving feedback from these users is crucial for further development and adjustment of the project.
When testing the deployed bot, the users were asked to give feedback regarding different stages of interacting with the chat bot. They were asked to rate a few objectives. The possible answers are in the range 0-4 where 0 states the lowest score and 4 the highest.
There are different statements that users rated, these can be found in the table below: