Algorithms
Comparison Process
This page is for the comparison of the models we narrowed down in the research page. We already concluded what libraries or models to use for some parts of the project in the research section. The following comparison structure is strictly for distractor generators and falsifying statement models.
For each algorithm class we followed the same structure:
1. Describe all the algorithms.
2. Explain our experiment setup and the datasets we used for testing.
3. Discuss which algorithm to choose and finalise our decision.
Distractor Generators
After some research we narrowed it down to two libraries. Sense2vec and WordNet.
Description
The following are the brief descriptions of both methods and a bit of background information on their use cases.
Sense2vec
Sense2vec has the ability to capture complex semantic and syntactic relationships amongst the words. It can also encode the context of the word by generating contextually-keyed word vectors [1]. So it creates a vector for each sense of the word. For example, the word apple gets two vectors. When it is used as the name of the fruit and when it is used as the name of the company. Sense2vec has a pre-trained model implemented in Python as a library that we can use.
Sense2vec is particularly useful because it accepts open compound words as input as well. So, it doesn't have to be a standalone word. For example, it can take open compound words such as machine learning or ice cream and find similar words to it.
WordNet
WordNet is a lexical database of semantic relations between words [2]. It can be seen as a huge dictionary but with connections between words. WordNet categorises and links words into semantic relations including synonyms, hyponyms and meronyms. The synonyms are grouped into synsets with short definitions and usage examples. The way WordNet creates synsets can prove to be quite useful in distractor generation.
WordNet is a relatively smaller library and it doesn't cover open compound words. So, when the input of machine learning is given it considers the word machine separately from learning. This is definitely something to take into account when comparing WordNet with Sense2vec.
Experiment Setup and Data
To measure which one is better for generating distractors we used 200 completely random words and tested the same words in both libraries. Then, we decreased the number of words in each set by 20 until we got a batch of 20 random words just to check if it affects the outcome. We are looking for the distractors to not be synonyms and still be similar to each other. The best way to measure this is to use simlarity checking between the initial word and the generated distractors from both systems. We would check the first 3 words since that is the maximum number of options our system aims to generate not including the answer. We get the data into a comparable format by taking the average similarity score for all three distractors. We take into account possible generated synonyms by halving the similarity score of a distractor that is also a synonym of the initial word. We can check if it is a synonym by using the nltk library so that we can deduct from the score accordingly. After taking into account the synonyms and calculating the average similarity score we do it for the other rest of the words and take the average similarity score for all of them. Then we can use that data to compare between both systems since we now have the overall average similarity score for both systems. The similarity scores are out of 1.0 when it is 1.0, it means the words are identical and 0 being completely unrelated. All the data can be found below:
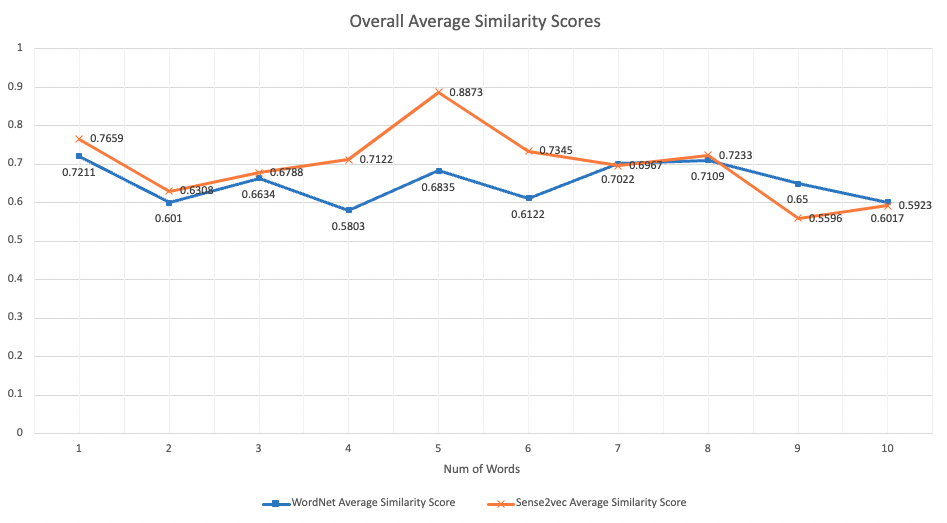
Discussion and Conclusion
From the data above there isn't a clear difference between the performances of two libraries even though Sense2vec sligthly out performs WordNet in most number of words. Number 1 to 10 on the horizontal axis represents the number of words from the batch size of 200 to 20 in increments of 20. The vertical axis represents the average similarity score and it is ranged from 0 to 1. The randomly generated words are all standalone words so this data is without taking into account the open compound words. We did this to provide an even testing environment for both libraries since we know that Sense2vec has no problems with open compound words but WordNet can't use them.
When comparing these two libraries we also checked how long it took them to generate the distractors and WordNet took about 1.7 seconds to generate distractors for the batch size 100. For Sense2vec it took almost 4 times longer (6.3 seconds) to generate distractors from the same batch. There is a clear performance difference between these two libraries in terms of speed and WordNet is the quicker one.
Even though the data shows that there isn't a significant difference between the similarity scores of the distractors generate from both libraries there is a very significant difference in terms of the speed of generating these distractors. On paper, these factors put WordNet in the lead for us. One key factor which is not reflected in the data is the distractor generation from open compound words. Since we do want our system to be able to pick phrases as answers, not just standalone words Sense2vec is the better option for our use case. Also, in terms of the average similarity scores, Sense2vec beats WordNet in most batch sizes. That is why we decided to use a pre-trained version of Sense2vec for distractor generation.
Falsifying Statement Model
After some research we narrowed it down to two models. GPT-2 and T5. We are considering the pre-trained versions of these models in our experiements.
Description
GPT-2
Even though the first method is not only using GPT-2 to falsify a statement, GPT-2 is doing the main work. To describe GPT-2 briefly it is an open-source artificial intelligence created by OpenAI [3]. GPT-2 translates text, answers questions, summarises passages and generates text output on a high level such that it can be hard to distinguish it from humans. It does have a tendency to create very long passages which can get a bit out of context sometimes. It is considered to be a general-purpose learner and it is not specifically trained to do any falsifying statement tasks. We will be using a pre-trained version so that GPT-2 can falsify a statement pretty accurately. In our experiment, we will be using a pre-trained version for sentence completion so that when we input a sentence with a missing end it can complete it for us..
T5
For this method, all the work will be done by the T5 model. Just in case you missed the research page here is a quick description of the T5 model. T5 is an encoder-decoder model pre-trained on a multi-task mixture of unsupervised and supervised tasks and each task is converted into a text-to-text format. T5 works well on a variety of tasks out-of-the-box by prepending a different prefix to the input corresponding to each task [4]. For example, for translation tasks, it will take the prefix "translation" and for summarization tasks, it will take the prefix "summarize". So, T5 is a model that can learn from a dataset and apply what is learnt to a new input. The T5 model we will be using is pre-trained on the boolq dataset [5]. The boolq dataset has 15942 yes/no questions that are naturally occurring. So, these examples are generated in unprompted and unconstrained settings. Each example in the dataset has a question, passage and answer. A pre-trained T5 model on the boolq dataset can generate a statement from a text passage which can be converted into a true or false question format.
Experiment Setup and Data
We found out that the best way to have a way of measuring the quality of the true or false questions is by using user acceptance testing. We will have 100 different sentences and generate true or false questions out of those sentences using both models. As a result, we will have 200 true or false questions. As the people who are conducting the test, we will present the random unbiased users the true or false question generated from both models side by side but they would not know which question was generated by which model. The users will be shown the text passage used to generate the questions. Then, the user will be asked to pick the better question out of the two. We are not setting any criteria to assess the question's quality. The user is given complete freedom on how they determine the question quality. This way it is more intuitive and natural for them to make their decision. For each user, we will use 10 generated true or false questions from each model and the users will be only comparing questions that are generated from the same text passage. That way we can have 10 different people pick the one they prefer. If they think both questions are equally good they can pick both of them. That's why we will use percentages for each user and take the average of it overall. This way we can pick the better true or false question generator out of the two and have supporting data to justify it. The data we collected is shown in a bar chart down below. Where the horizontal axis represents the users and the vertical axis is the number of times the question generated by a certain model was picked.
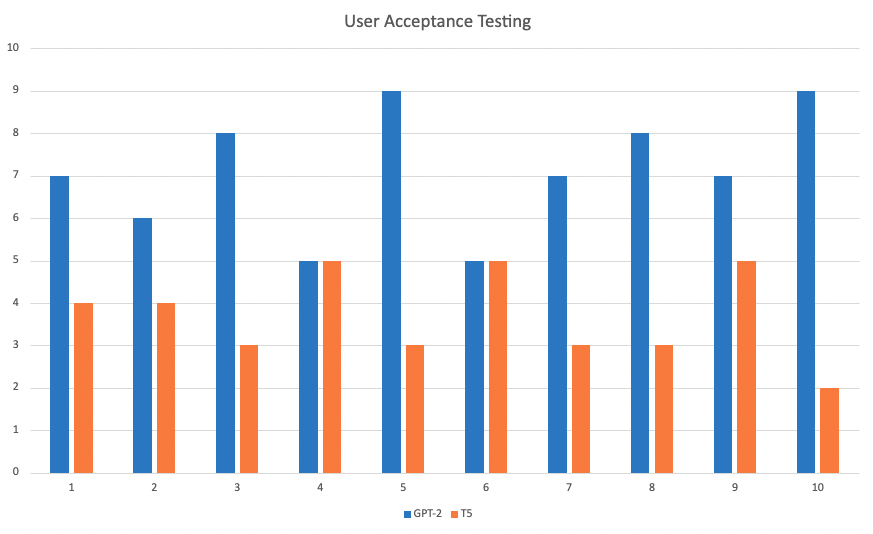
Discussion and Conclusion
From the data, we can extract a few things. Firstly, for GPT-2 out of 100 questions, 71 questions have been picked to be the better or equivalent quality to the compared question. So, that means GPT-2 generated true or false questions are prefered 71% of the time by 10 different users. For the T5 model, only 37 questions out of 100 have been deemed to be better or equivalent quality to the questions generated by GPT-2. This data is pretty significant and the difference between the likelihood of GPT-2 questions getting picked over T5 is definitely something to consider. Also, all the users were students which are a part of our target audience but they don't have any prior knowledge of the project they are working on so it is safe to say that their judgement was not interfered with. To sum up the results, it is fair to say that the users preferred the true or false questions generated by GPT-2 over T5. The difference in the results was very clear and that is why we chose to go with GPT-2 model in our system for the best results.
Final Technical Decisions
After our experiments we finalised our decisions and here is the final technical decisions table. The justifications of our reasonings can be found on both algorithms and the research page.
| Tech | Decision |
|---|---|
| API Framework | Flask |
| Language | Python |
| Database | PostgreSQL |
| Website | React JavaScript, HTML, CSS |
| Distractor Generator | Sense2Vec |
| QG Model | T5 |
| Falsifying Statement | GPT-2 |
References:
- 1. Guide to Sense2vec – Contextually Keyed Word Vectors for NLP Available at: https://analyticsindiamag.com/guide-to-sense2vec-contextually-keyed-word-vectors-for-nlp/ [Accessed 16th March 2022]
- 2. Wordnet Available at: https://en.wikipedia.org/wiki/WordNet#:~:text=WordNet%20links%20words%20into%20semantic,of%20a%20dictionary%20and%20thesaurus [Accessed 10th March 2022]
- 3. GPT-2 Available at: https://en.wikipedia.org/wiki/GPT-2 [Accessed 10th March 2022]
- 4. T5 Available at: https://huggingface.co/docs/transformers/model_doc/t5 [Accessed 12th March 2022]
- 5. boolean-questions Available at: https://github.com/google-research-datasets/boolean-questions [Acessed 12th March 2022]