Implementation
Base Web Application Implementation
Tools & Dependencies

The Python Flask micro web framework is used for the back-end of the application.

ElephantSQL manages the PostgreSQL database used to store information about users and questions.

Jinja is used for fast, expressive and extensible templates to serve the front end of the application.
Implementation Overview
1. Create a database with the required tables
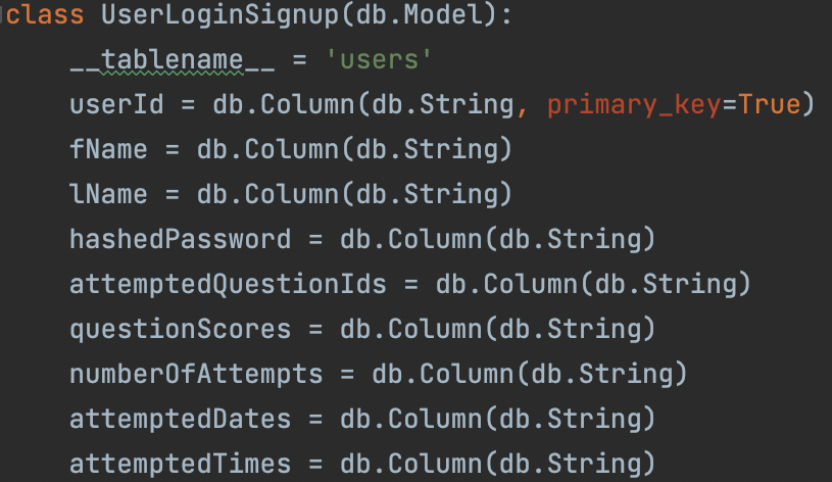
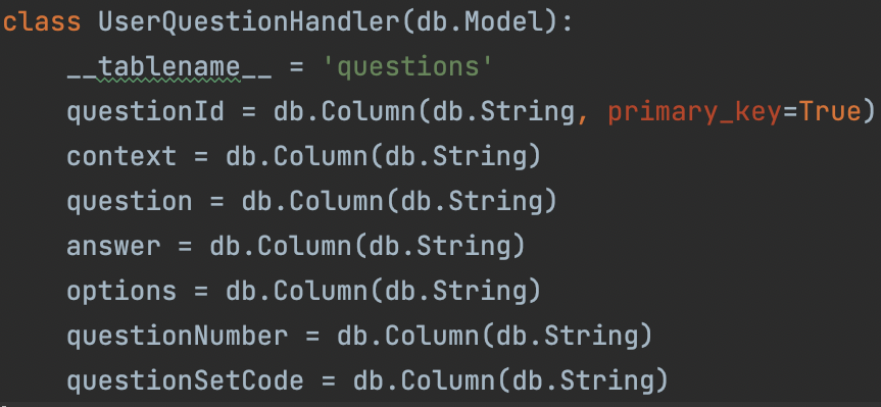
The first stage was to create a Postgres database using SQL. The required tables were created and columns were defined. Two tables were created: users and questions. The users table was instantiated with the following columns: userId, fName, lName, hashedPassword, attemptedQuestionIds, questionScores, numberOfAttempts, attemptedDates and attemptedTimes. The questions table was instantiated with the following columns: questionId, context, question, answer, options, questionNumber and questionSetCode.


2. Define project structure
We decided to use the MVC design pattern so that models can be replaced during further development without breaking the system. We also decided to use flask blueprints in order to encapsulate functionality, such as views, templates and other resources.
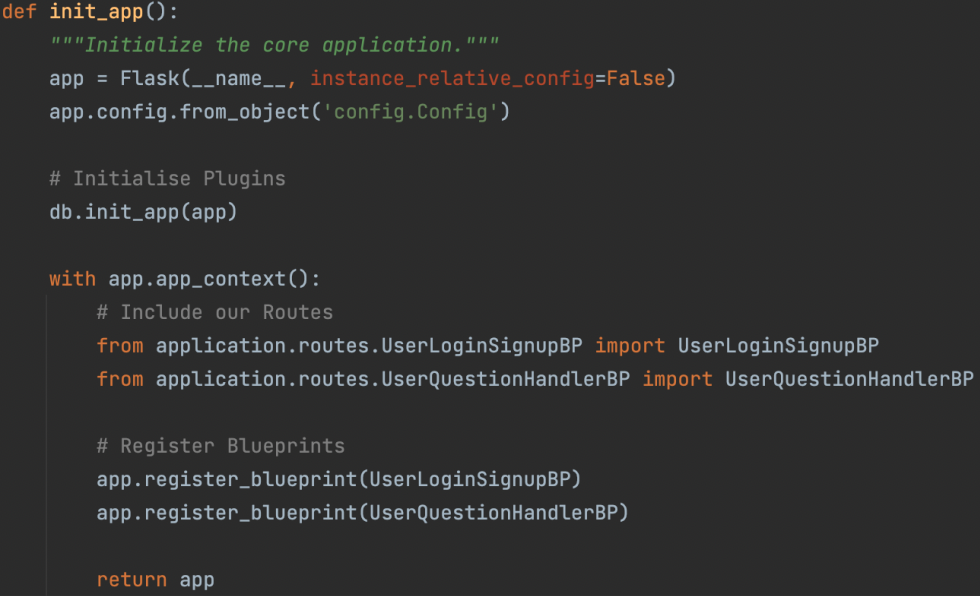
3. Set up base flask application and define configuration values
An application factory was set up in __init__.py in the core application folder. This instantiates the application with a selected configuration environment. The blueprints associated with the specific instance of the application were also registered here. Finally the database toolkit SQLAlchemy was also initialised to link the database to the flask application.The configuration environments required to set up the flask application were defined in config.py, this included the database url. A final file wsgi.py was written and this runs the flask app on the localhost (during development).
True or False Question Generator Implementation
Tools & Dependencies

Allennlp was used to develop a state-of-the-art deep learning model to generate a Penn treebank for a sentence

spaCy is an open-source software library for advanced natural language processing.

BERT is a transformer-based machine learning technique for natural language processing (NLP).

GPT-2 generates synthetic text samples in response to the model being primed with an arbitrary input.

TensorFlow is an end-to-end open source platform for machine learning.
Implementation Overview
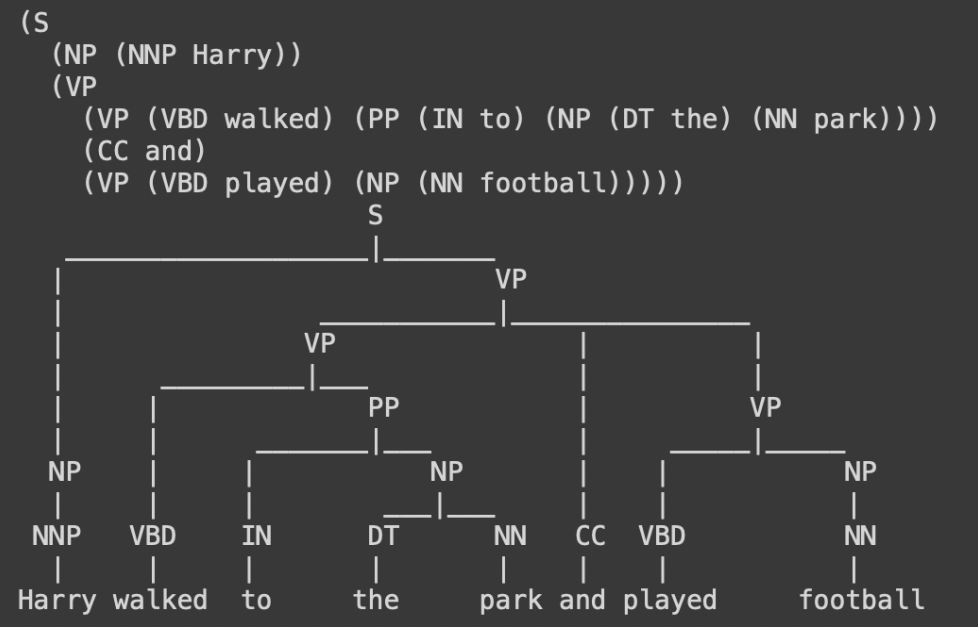
1. Create an incomplete statement from a given sentence
The first stage was to remove punctuation and correct the spaces for a given sentence. After this preprocessing was complete, we used Allennlp to annotate a sentence and mark verb phrases and noun phrases. A tree was created from the annotated sentence and the longest noun and verb phrases were identified. These were then later removed from the sentence to create an incomplete statement.

2. Generate alternate endings to a split statement using GPT-2
The next stage was to use a GPT-2 tokeniser to encode the incomplete statements and produce input_ids to be passed to the GPT-2 model. Next, we activated top p and top k sampling to generate sample outputs from our encoded incomplete statements. These sample outputs were then decoded and 10 statements with alternate endings were created.
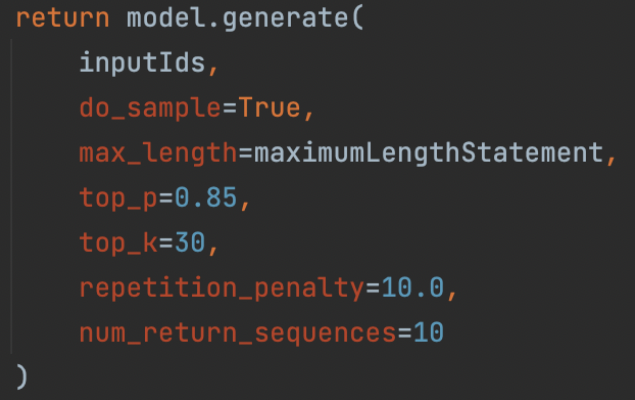
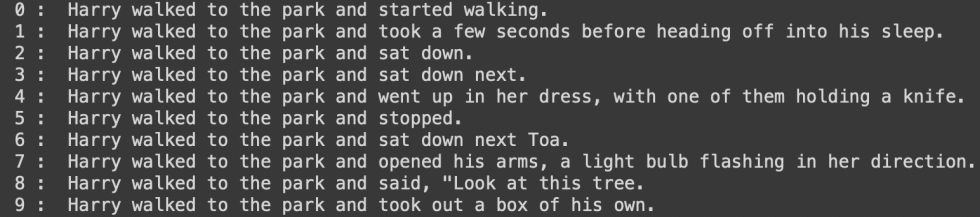
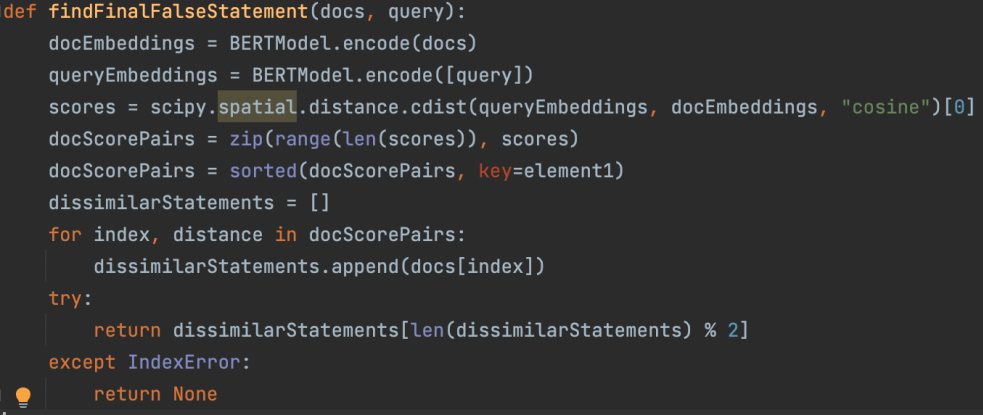
3. Filter the sentences with BERT
The final stage is to calculate the spatial cosine distance between the original sentence and the new one with the alternate endings. These are then ranked in order of dissimilarity in which we choose the sentence with the greatest dissimilarity to present to the user.

Multiple Choice Question Generator Implementation
Tools & Dependencies

Nltk is suite of suite of libraries for statistical natural language processing of English.

SQuAD is a reading comprehension dataset, consisting of questions posed by crowd workers on a set of wikipedia articles.

T5 is an extremely large new neural network model that is trained on a mixture of unlabelled text.
GPT-2 generates synthetic text samples in response to the model being primed with an arbitrary input.

Sense2vec is a neural network model that generates vector space representations of words from large corpora.
Implementation Overview
1. Select an answer from a given sentence
The first stage was to remove punctuation and correct the spaces for a given sentence. After this preprocessing was complete, we used averaged_perceptron_tagger to tag the given sentence with their parts of speech (POS). The last noun of the given sentence was selected to be the answer to the question that will be produced later on.
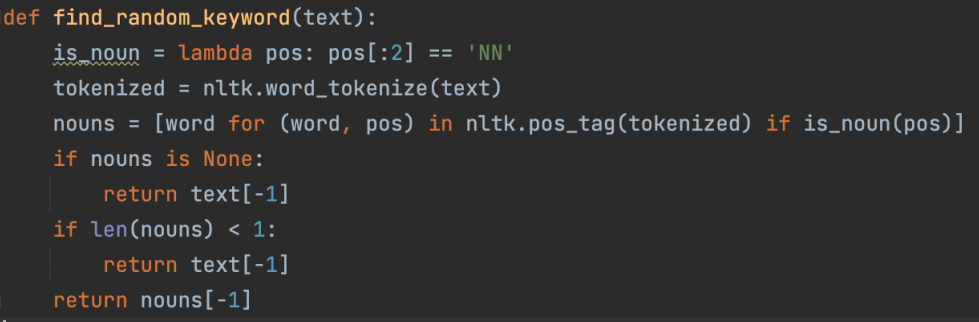
2. Generate distractors for the selected answer
The first part of generating distractors is to get the sense of the word that we have selected as the answer. Next, the most similar 20 words to the obtained sense of the answer are added to a list.
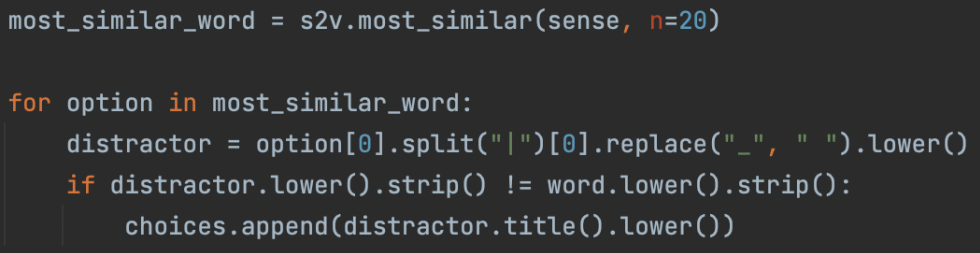
3. Generate misspellings for the selected answer
If there are not enough similar words to the answer then misspellings of the noun are created. This is a fail-safe way of ensuring any selected answer always has possible distractors. This is done by selecting a letter in the answer at random and performing a single edit on it such as altering, removing or adding a letter.

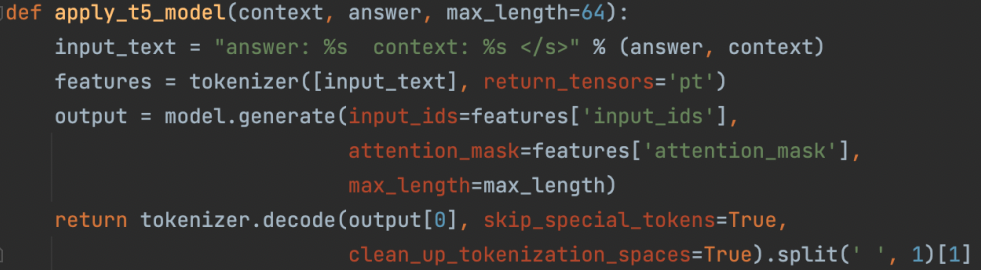
4. Generate question from sentence and answer
Now that we have generated distractors for the selected answer in a sentence, we use the T5 model that has been fine-tuned on a question and answering dataset to generate questions. This is done by encoding the sentence and answer and then using the T5 model to generate questions. The output tensors are decoded using the T5 tokeniser before the question, answer and distractors are served to the user.
Serving Questions and API Implementation
Tools & Dependencies

SQLAlchemy is an open-source SQL toolkit and object-relational mapper for the Python programming.

bcrypt is a password-hashing function designed by Niels Provos and David Mazières, based on the Blowfish cipher

Html, css, javascript and ajax were used to assist the flask application in serving the web applications front end.
Implementation Overview
1. Assign blueprints for flask application
The first stage was to create routes and blueprints for the required pages of our web application. There are two blueprints and each one is assigned to its own controller. The UserLoginSignupBP works with the UserLoginSignupController to serve the user with functionality such as logging in, signing up, logging out, saving users question answering results and all other user-related requests. The UserQuestionHandlerBP works with the UserQuestionHandlerController to serve the user with functionality such as creating multiple-choice questions, true or false questions, accessing the question generation api’s, saving questions and their attributes and all other question-related requests.
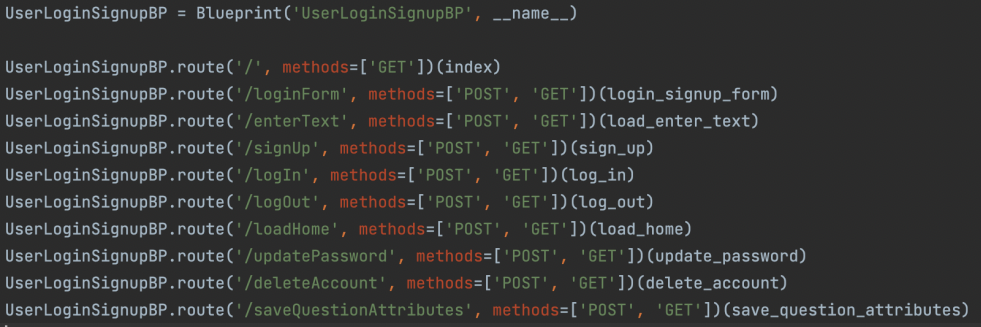
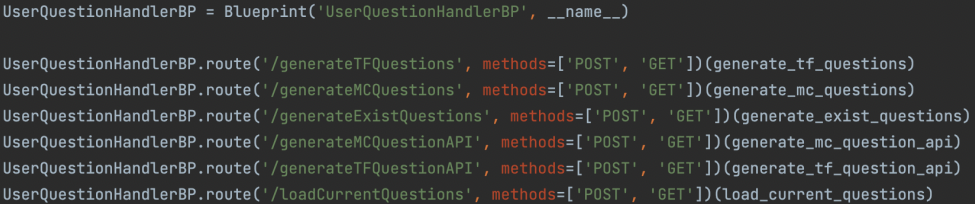
2. Create models for objects and tables for each model
Two individual models were created and each was assigned to its own controllers. These controllers can safely access the models and their static methods. The UserLoginSignup model stores information about the user and the passwords for their accounts. Bcrypt was used to hash the passwords. The UserQuestionHandler model stores information about the questions generated by users. Bcrypt was again used to hash the questions and create a question id which was assigned to be the primary key of the questions table.
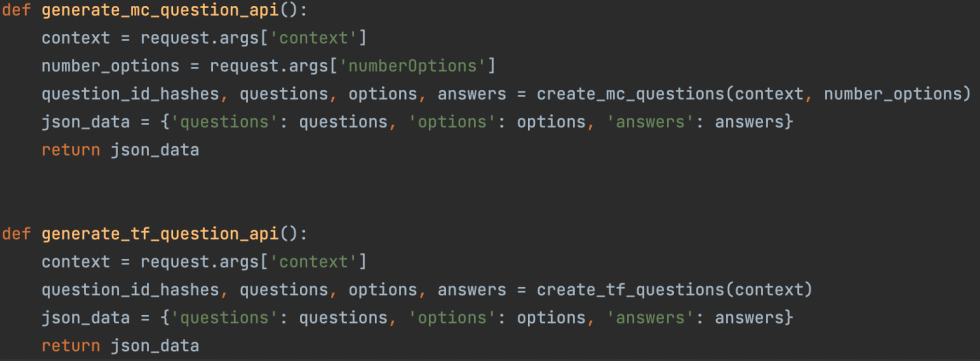
3. Create API endpoints
A separate controller handles the API endpoints of our web application. The information is retrieved from the query string in a POST request to the API. Questions are generated and the questions, answers and options are returned to the user in json format. This was tested using POSTMAN which we describe in our testing phase.