Research
Project Research
General Research
The automatic question generation topic has many different published papers on different question generation models and their performances. There are many different models and libraries we can implement and test. We started by looking into more basic models to implement and test as a starting point. The first step was to decide on what type of question to generate, we did research on what type of question has the most resources and literature written about it. We read through many research papers and found out that objective-type multiple-choice questions are the question type that has the most amount of resources online [1]. Also, because of the use case of our system, we decided to generate domain-unspecific questions.
We researched the structure of multiple-choice questions and what do we need to generate them. There were many different ways to generate them but one common thing we noticed is that the question itself and the options of the questions are generated separately [2]. So, we split our research on multiple-choice question generation into two parts. The first is the question and the second part is the options to the question. The options are also called distractors in literature where the whole goal of the distractor generators is to generate options very similar to the answer of the question. Ideally, to be able to know which model and distractor generator to use we would like to test it by comparing the quality of the generated questions by crowdsourcing it [3]. Since we do not have the resources or the time to do that we decided to create some criteria to test the quality of the generated questions. We were inspired by Alsubait's review [4] when picking the criteria. Those criteria being:
If the question is well formed and easy to understand.
Where it is clear what the question is asking for.
The distractors should not have synonyms of eachother and should be still related.
Related Project Review
We started researching apps with similar functionalities that can automatically generate objective-type domain-unspecified multiple-choice questions from educational text. The most capable app we came across is called Quillionz[5]. Quillionz is able to generate questions from educational text by making the user pick the keywords they want to generate questions based on. Even though this may result in better quality generated questions, we believe it is not fully automated, therefore, we decided to generate questions without making the user pick the keywords. According to Quillionz's website, they are using AI and machine learning algorithms but they haven't stated which question generation models and datasets they are using. Also, they state that they are able to generate various different types of questions and not just multiple-choice.
We also came across a very similar project to Quillionz, it is an automatic question generator built by Arcadia Software Country [21]. Their question generator has the same structure as Quillionz. So, it requests the user to enter a text passage and then it requests users to pick the keywords they want the questions to be generated on. Then, it gives the option to pick how many of each type of question to be generated and then generate the questions. The questions can be exported into word or pdf format but they can't be directly shared on the platform. Also, their software supports multiple languages.
To compare the two question generation softwares:
| Quillionz | Arcadia |
|---|---|
| Aimed at teachers or students | Aimed at teachers or students |
| Generate Wh- type questions | Generate Wh- type questions |
| Only supports English | Supports multiple languages |
| Generates multiple types of questions | Generates multiple types of questions |
| No sharing on the platform | No sharing on the platform |
| Can't pick the number of options for questions | Can't pick the number of options for questions |
We analysed the pros and cons of both projects and decided to implement some of them. So, our software will be fully automated, so the user will not be picking the keywords to generate questions. We also decided to implement different types of questions such as multiple-choice and true or false questions. Our system will also provide a way to users to track their progress which neither Quillionz nor Arcadia provides.
Technology Review
Algorithms
Considering our requirements we wanted to create two types of questions. So, we did our algorithms research mainly based on algorithms for multiple-choice questions and true or false questions. We split multiple-choice question generation into two parts: question generation and distractor generation. For true or false questions we only needed to find a way to create a false or a true statement from the context we receive. Since our project is heavily based on natural language processing and most of our question generation methods and algorithms are going to require the use of many libraries. It would be not possible to just choose one algorithm based on our research, it is only right if we test and optimize the algorithms ourselves. That's why we decided to narrow down our options with research but not conclude on one algorithm. We followed this method for researching distractor generation and falsifying statements. We will present all the pros and cons of each algorithm for each category and conclude on which algorithms we ended up using in the algorithms page
Multiple-Choice Question Generation Models
Multiple-choice question generation is the most important part of our system. In this section, we explained all the methods we found for question generation and why we think they are viable.
T5 Model
One of the ways we can generate a question is by using a text-to-text transformer. Transformers can be used in many different ways such as language translation, question answering and classification. The T5 is a text-to-text transformer created by Google and it is used on Natural language processing tasks mainly. The method we found uses the T5 model and fine-tunes it on a SQuAD v1.1 dataset for question generation [18]. SQuAD [19] data set is short for Stanford Question Answering Dataset and version 1.1, which is the version we looked into, contains 100,000+ question-answer pairs on 500+ articles. When the T5 model is trained on the SQuAD dataset it allows it to take a sentence and an answer as the input and create a question out of it. This model seemed very elegant and advanced. We also managed to find a pre-trained T5 model we can use [18] which saved us from spending time and resources on training the model ourselves. As we researched this method more, we found out that is more commonly used and is backed by many different implementations when it comes to question answering [20]. That's why using the T5 model for question generation seems very promising.
BERT and Keyword Extraction model
This method is slightly different from what we initially thought of as multiple-choice question generation. This model creates multiple-choice questions in the format of fill in the blank questions [2]. It generates questions by extractive summarizing the whole of the text input and then using a keyword extractor to remove all the nouns in the summary. After removing all the nouns, it matches it with the sentence it was removed from. This way it has a blank in the sentence and we also have the answer to the questions which can be used to generate the other options in the multiple-choice questions. It summarises the text input by using BERT [13] model which stands for Bidirectional Encoder Representations from Transformers. BERT works by learning the contextual relations between words in a text and this allows it to be able to summarise the text. For the keyword extraction, this method uses a library called pke where you can pick for the extractor to choose which type of words to choose. To match the keywords with the sentences we don't need any extra libraries it can be done by a simple searching algorithm. This question generation method is quite clever and it doesn't require long processing times since it requires very little NLP work. Even though, this method technically generates multiple-choice questions it is in the fill in the blank format which is not exactly what we had in mind. We will still consider this method but might choose to implement it slightly differently or possibly optimise it.
Conclusion
After looking through both the T5 model and the BERT model it was clear to us just by research which one was the better option for our use case. T5 model can achieve exactly what we are looking for when trained with the SQuAD v1.1 dataset and we can have access to the pre-trained models. Meanwhile, BERT doesn't give us the multiple-choice question format we are asking for and we could not come up with a way to transform it. That is why we chose to go with the T5 model and we did not need testing to prove that. Since the produced question type is not the same, it wouldn't be a fair comparison. This situation automatically eliminated the BERT model and we decided to go with the T5 model.
Distractor Generator Research
The initial idea we had for the distractor generation was to use the answer to the generated question to generate the other distractors. We researched different libraries we can use to generate distractors. We were looking for libraries that contain every English word with a heuristic to measure the familiarity between words. We came across resources such as WordNet [16] and Sense2Vec [17].
WordNet
Out of the two popular options we came across, WordNet seemed very easy to implement and integrate. WordNet is a large lexical database of English words. So, very similar to a thesaurus but it captures even broader relationships between words. Upon further research, we found a website that shows us all the related words to the word we input. We tried a bunch of different words and it seemed to have good enough connections with other words to be able to generate distractors. One major weakness we found was the lack of managing phrases with multiple words. For example, when we input the phrase "machine learning" the WordNet library finds connections to the word machine and learning separately. Then, combines the two words which create a non-sensical distractor. Even then it is a good library to consider because of how simple it is to implement.
Sense2vec
Sense2vec seemed like a good option to consider because of how each word and phrase is connected to each other. The connections are more semantically formed compared to WordNet which is better because the generated distractors can not be the synonym of the answer and we can eliminate those distractors by checking semantic relationships between the phrases. This feature can potentially give us good quality distractors. Also, Sense2vec covers phrases like "machine learning" which is a major advantage over WordNet. To give an example of how the library works we can try to generate distractors for the word "King". The process is shown below.
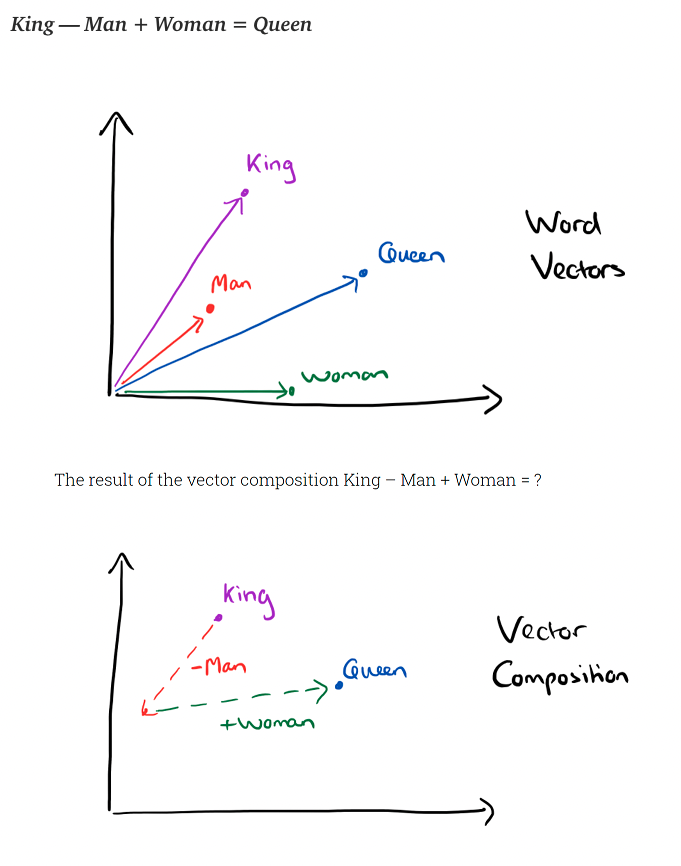
That is mainly why we are considering using sense2vec for our distractor generator and you can read which library or libraries we ended up choosing on the algorithms page.
Falsifying Statement Research
Falsifying statement method is used to generate true or false questions. At the start, we didn't know how to create true or false questions because the question itself needs to state a fact rather than asking a question unlike in multiple-choice questions. Our client suggested that we can start by looking into models that can change a sentence to be false. That way it is possible to create a true or false question from a sentence. So, we started looking into a few models and methods to see if they can change the sentence in a way where we can falsify it.
First Method (GPT2)
The first method we came across required us to use different libraries and the main idea was to use a pre-trained text transformer to complete a sentence. Initially, we used the allenNLP library [10] to get the sentence we want to falsify and create a Penn treebank [11] to classify every word. A treebank is a parsed text corpus that annotates syntactic or semantic sentence structure [11]. After creating the bank tree we use it to create a parse tree and that parse tree allows us to see all the nouns, verbs etc. From there, we pick the longest noun or verb phrase and remove it. We do this because the longest noun or verb phrase is usually the phrase we can change to have an effect on the context of the whole sentence. After, removing the phrase from the rest of the sentence we pass the modified sentence into a trained generative text-to-text transformer. This transformer is called GPT2 [12] and it stands for generative pre-trained transformer. The fact that GPT2 is pre-trained was one of the reasons we liked this method because that meant we didn't have to spend resources and time on training the model ourselves. GPT2 was trained on a dataset for true or false questions. So, when we passed on the sentence with the missing phrase it can complete it for us. Even though, it was possible to get the exact same sentence as the original sentence the probability of that happening was very slim. According to our research, GPT2's output usually falsified the original statement very well but there were some limitations to this method. The first one is that the falsified question could become non-sensical and go out of context. The second possible problem was the possibility of getting the exact same sentence as the original. We believe we can optimize the algorithm to prevent or minimise these problems. One of the ways we found to minimise the problems was to use a similarity checking method between the original and the final sentence. This would allow us to check how similar the sentences are and measure the performance of the first method that way. The evident advantage of this method is that both alenNLP and GPT2 are open sources and GPT2 is pre-trained which saves us a lot of time.
Second Method (T5)
Another algorithm we came across had a more straightforward approach to falsifying statements. It involved training a text to text transformer called T5 [14]. It used a dataset called boolq. This dataset has a bunch of sentences and their falsified versions. When the T5 model is fine-tuned with this data set it takes our sentence and falsifies it. This method seemed quite simple and effective but since we did not have the resources to train the T5 model, we had to find a pre-trained one. We found one pre-trained T5 model but from the research, we have done this model does not seem to work the way we want it to. Most of the sentences it generates do not make sense and are semantically incorrect. We will still implement it and see if we can optimize the model or even fine-tune it on boolq dataset once more. The best part of this method is how most work is done by a single component.
Languages
Python
Python is a very popular programming language especially when it comes to natural language processing (NLP) which is required for automatic question generation. Python has many natural language processing libraries such as Spacy, CoreNLP and NLTK [6] and it is very easy to deploy applications on. Also, our client has the most experience with Python and their existing infrastructure is in Python. Even though the computational speed of Python is relatively slower than other languages the pros outweigh the cons. That's why we decided to use Python for our API. Most of our question generation functionality is achieved by functions written in Python and the help of the NLTK and allenNLP library.
React JS
React JS is great for building smooth and simple user interfaces. It allows us to create reusable UI components which accelerate the process of building a frontend for our web application. The whole purpose of the web application is to give the users an interactive platform to make the most of the API's functionalities. React's easy to learn structure and extensive JavaScript libraries are one of the many reasons why we chose React JS for the front-end.
Framework
Flask
After deciding on the backend programming language, we had to decide on a framework for the web application and the API. Python has two dominant frameworks for web development and those are Flask and Django [7]. We compared the two frameworks as such:
| Flask | Django |
|---|---|
| Built for rapid development | Built for more simple web applications |
| API support | No API support |
| Allows multiple types of databases | Does not allow multiple types of databases |
| Lightweight codebase | Robust Documentation |
| More flexible | Follows standrad practices strictly |
| Free to use any plug-ins and libraries | More limited access to libraries |
After the head-to-head comparison between Flask and Django, Flask seemed to be the more suitable framework for our needs. Flask gave us more freedom on how to write our code and allowed us to import many different libraries, which, are required for natural language processing. On top of that, Flask's API support is crucial for us since we are trying to create our API and connect to it. Even though Django has very robust documentation and a great community behind it, Flask is more suitable for our needs [8].
Technical Decisions
For the distractor generator and the falsifying statement rows, there are two models/algorithms written because we decided to compare them by testing. Therefore, our final technical decision for those two rows can be found here.
| Tech | Decision |
|---|---|
| API Framework | Flask |
| Language | Python |
| Database | PostgreSQL |
| Website | React JavaScript, HTML, CSS |
| Distractor Generator | Sense2Vec, WordNet |
| QG Model | T5 |
| Falsifying Statement | GPT2, T5 |
References:
- 1. Automatic Question Generation and answer assesment: a survey Available at: https://telrp.springeropen.com/articles/10.1186/s41039-021-00151-1 [Accessed 6th March 2022]
- 2. Practical AI: Automatically Generate Multiple Choice Questions (MCQ) from any content with BERT Summarizer, Wordnet and Conceptnet Available at: https://towardsdatascience.com/practical-ai-automatically-generate-multiple-choice-questions-mcqs-from-any-content-with-bert-2140d53a9bf5 [Accessed 7th March 2022]
- 3. Crowdsourcing evaluation of the quality of automatically generated questions for supporting computer-assisted language teaching Available at: https://www.cambridge.org/core/journals/recall/article/crowdsourcing-evaluation-of-the-quality-of-automatically-generated-questions-for-supporting-computerassisted-language-teaching/4C54D575DA560524F205F8A7FC93FAC3 [Accessed 6th March 2022]
- 4. A Systematic Review of Automatic Question Generation for Educational Purposes Available at: https://link.springer.com/content/pdf/10.1007/s40593-019-00186-y.pdf [Accessed 8th March 2022]
- 5. Quillionz Available at: https://www.quillionz.com/ [Acessed 6th March 2022]
- 6. Python Libraries for Natural Language Processing Available at: https://towardsdatascience.com/python-libraries-for-natural-language-processing-be0e5a35dd64 [Accessed 9th March 2022]
- 7. lask vs Django: What’s the Difference Between Flask & Django? Available at: https://www.guru99.com/flask-vs-django.html#:~:text=KEY%20DIFFERENCES%3A,for%20easy%20and%20simple%20projects [Accessed 11th March]
- 8. Flask vs Django in 2022: Which Framework to Choose? Available at: https://hackr.io/blog/flask-vs-django [Accessed 10th March 2022]
- 9. Everything you need to know about MVC architecture Available at: https://towardsdatascience.com/everything-you-need-to-know-about-mvc-architecture-3c827930b4c1 [Accessed 11th March]
- 10. AllenNLP Available at: https://allenai.org/allennlp/software/allennlp-library [Accessed at: 13th March 2022]
- 11. Treebank Available at: https://en.wikipedia.org/wiki/Treebank [Accessed 12th March]
- 12. gpt2 Available at: https://huggingface.co/gpt2 [Accessed 12th March 2022]
- 13. BERT Explained: State of the art language model for NLP Available at: https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270 [Accessed 14th March 2022]
- 14. t5-base Available at: https://huggingface.co/t5-base [Accessed 14th March 2022]
- 15. Pennbank tree strcuture
- 16. Wordnet Available at: https://wordnet.princeton.edu/ [Accessed 14th March 2022]
- 17. spaCY sense2vec Available at: https://spacy.io/universe/project/sense2vec [Accessed 14th March 2022]
- 18. t5-base-finetuned-question-generation-ap Available at: https://huggingface.co/mrm8488/t5-base-finetuned-question-generation-ap [Accessed 15ht March 2022]
- 19. SQuAD explorer Available at: https://rajpurkar.github.io/SQuAD-explorer/ [Accessed 15th March 2022]
- 20. Question Answering on SQuAD1.1 dev Available at: https://paperswithcode.com/sota/question-answering-on-squad11-dev [Accessed 16th March 2022]
- 21. SoftwareCountry Automatic Question Generator Available at: https://softwarecountry.com/our-products/automatic-question-generator/ [Accessed 15th March 2022]