
Implementation
Language and Framework
For this project, the primary programming languages employed include Python, particularly Django for the back end functionality, JavaScript in conjunction with the React framework for the front end development, and HTML/CSS/JS for crafting this documentation website (you're reading!).




These technologies were chosen for their versatility, robustness, and compatibility with the project requirements. Python was selected for the back end due to its extensive libraries and frameworks that facilitate web scraping, data processing, and machine learning tasks. JavaScript and React were chosen for the front end to enhance modularity and scalability, enabling the creation of dynamic and interactive user interfaces.
Back End
2.1 File Structure
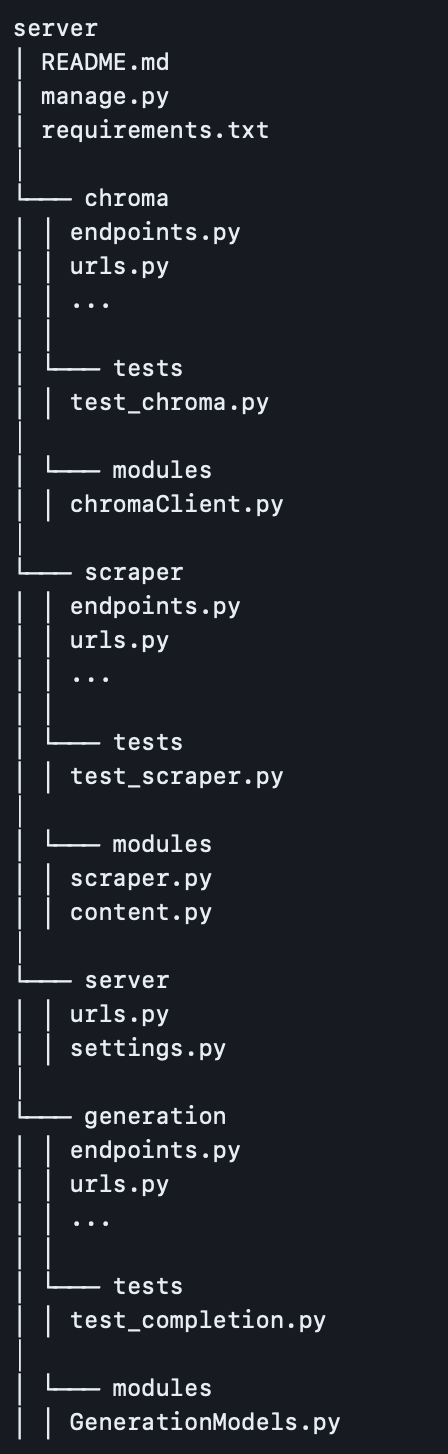
At the top level of the Django project, we have the chroma, scraper, server, and generation directories, each representing a specific functionality or domain within the application. This modular approach allows for better organization, maintainability, and scalability of the codebase. Within each module, we can observe a consistent structure. The endpoints.py and urls.py files handle the API endpoints and URL routing, respectively, while the modules directory contains the core logic and functionality of the module.
The tests directory within each module houses the corresponding unit tests, ensuring that the individual components of the application are thoroughly tested and validated.
1. Scraper
Leveraging the Google's (Custom Search Engine) API to get the top results of a search, we employ a scraper to extract the web content from these results.
The scraper is equipped with the capability to handle various types of web content, including PDFs, HTML pages, and plaintext documents.


2. Document Processing
Once the relevant data is obtained online, the lengthy textual information undergoes segmentation into shorter, more manageable snippets to facilitate subsequent processing. Employing the Recursive Character Text Splitter from the Langchain library, this division process is executed with precision and efficiency. It's important to note that PDF contents and plaintext contents are handled distinctively to ensure optimal splitting. Moreover, pertinent metadata such as page numbers are meticulously retained for future reference and contextual understanding.

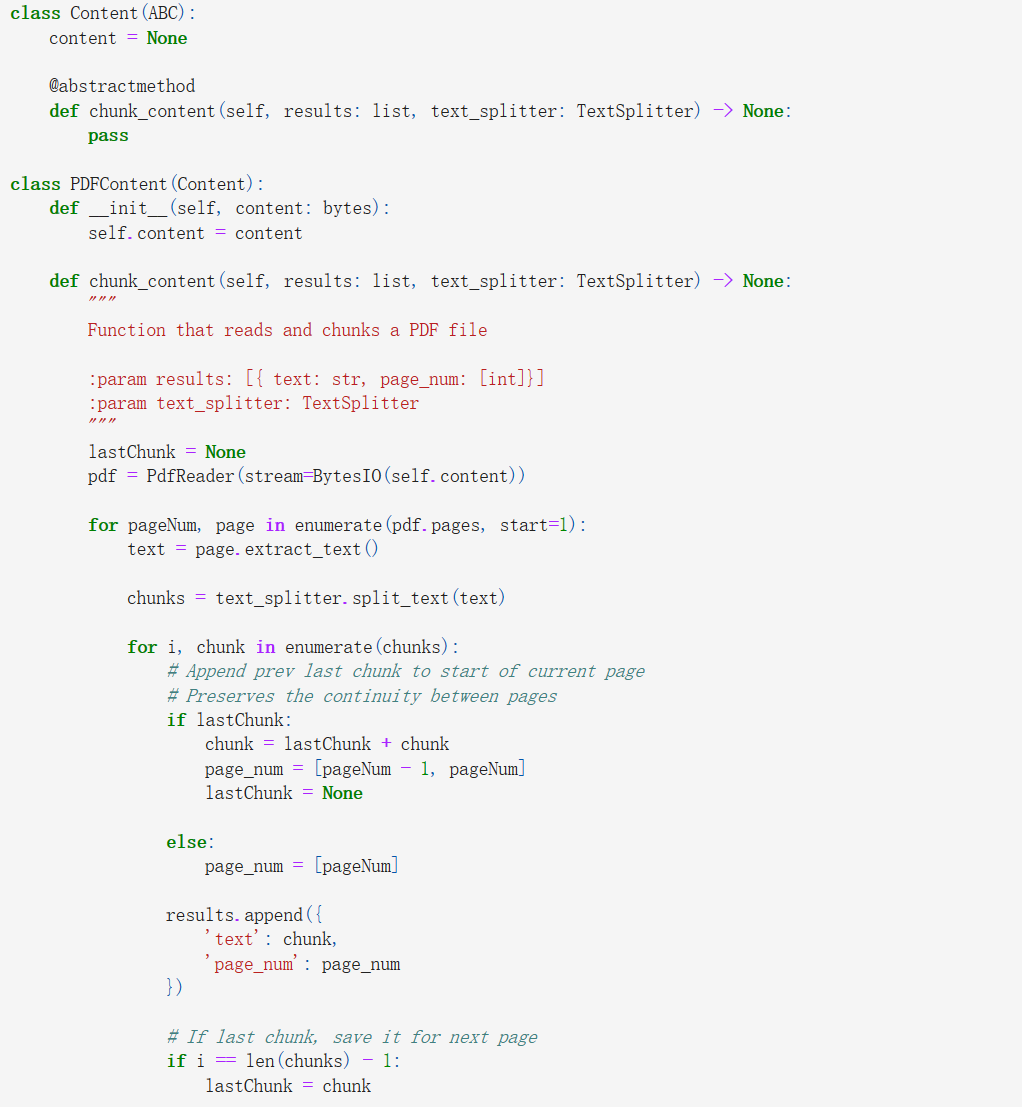

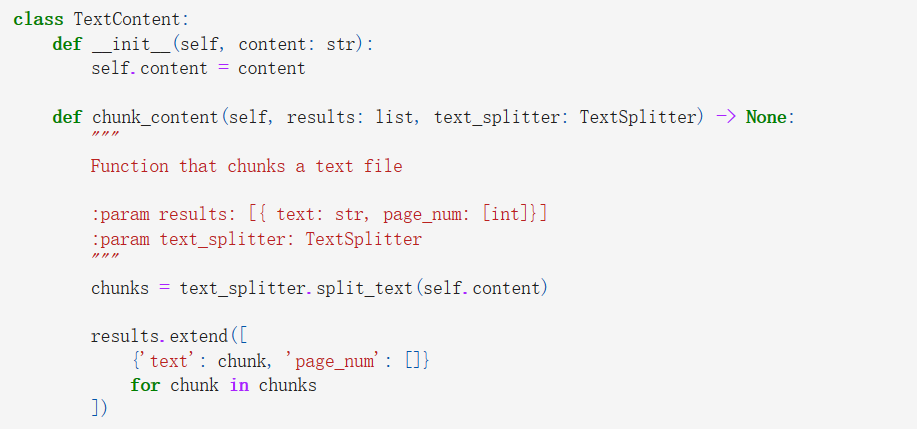
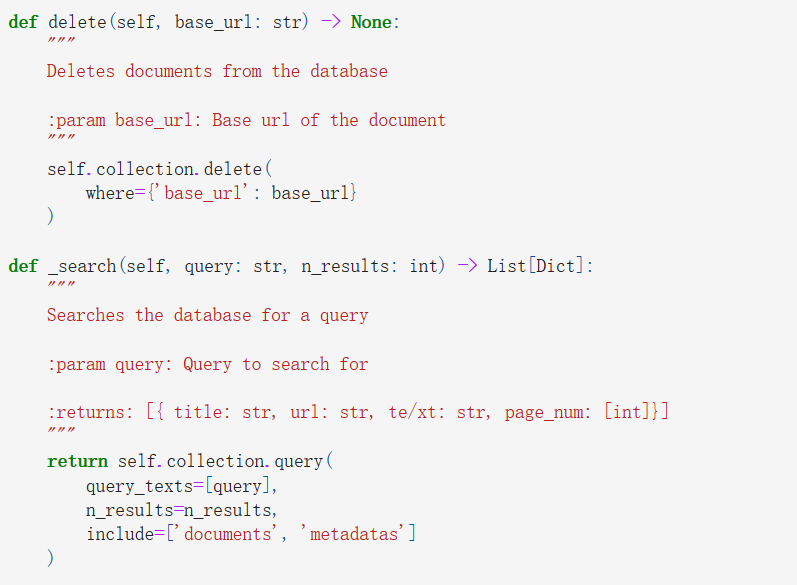
3. Vector Database
Utilising the segmented text chunks obtained from the previous stage, we proceed to upload them into the Chroma Vector Database, accompanied by various metadata attributes. These metadata elements encompass the document's title, page number, actual and base URLs. Notably, the base URL is specifically logged to streamline potential future actions, enabling swift disqualification of entire web sources if necessary.
Chroma was chosen for its robust search capabilities, enabling efficient retrieval of relevant documents based on user queries. Additionally, its local hosting ensures that the database is readily accessible and responsive, enhancing the overall user experience.
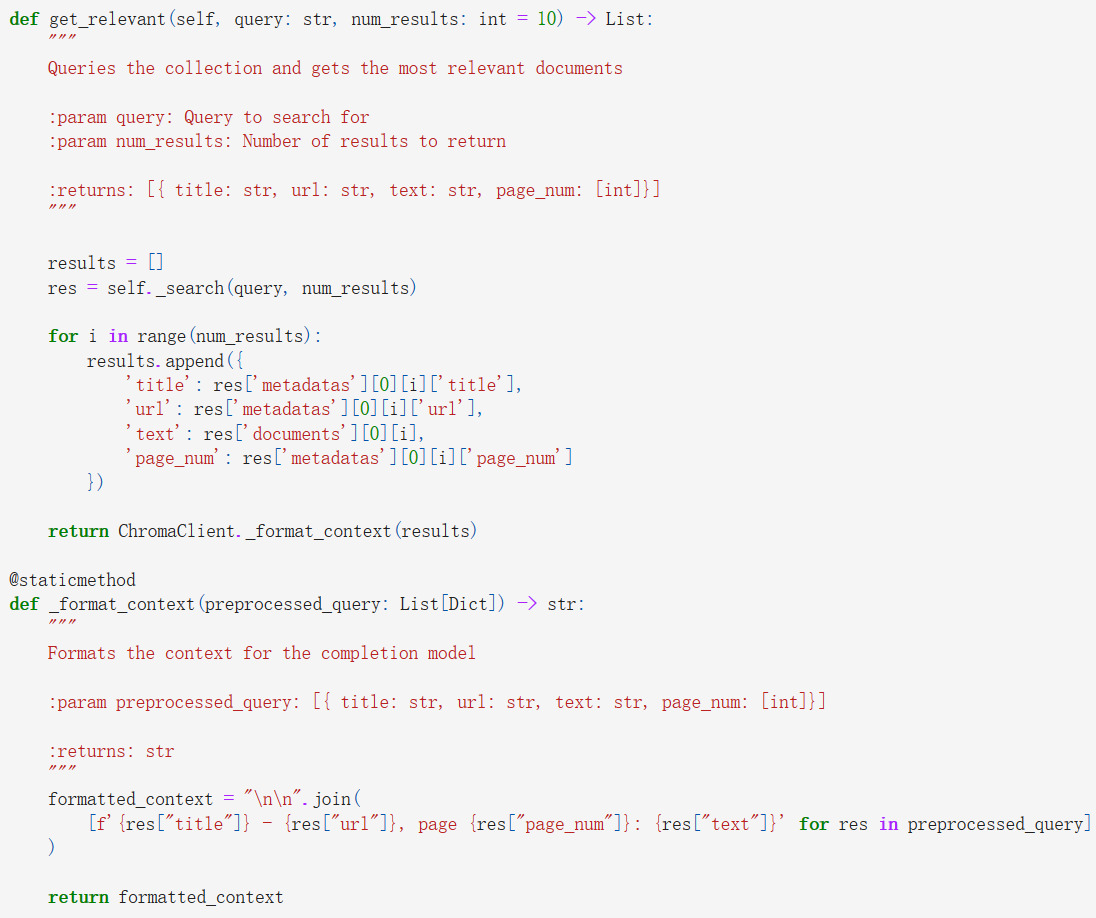
Once the database is established, upon receiving a user query, we initiate a search within the database to retrieve the ten most pertinent documents. Subsequently, we format these documents for seamless integration into subsequent processing stages.

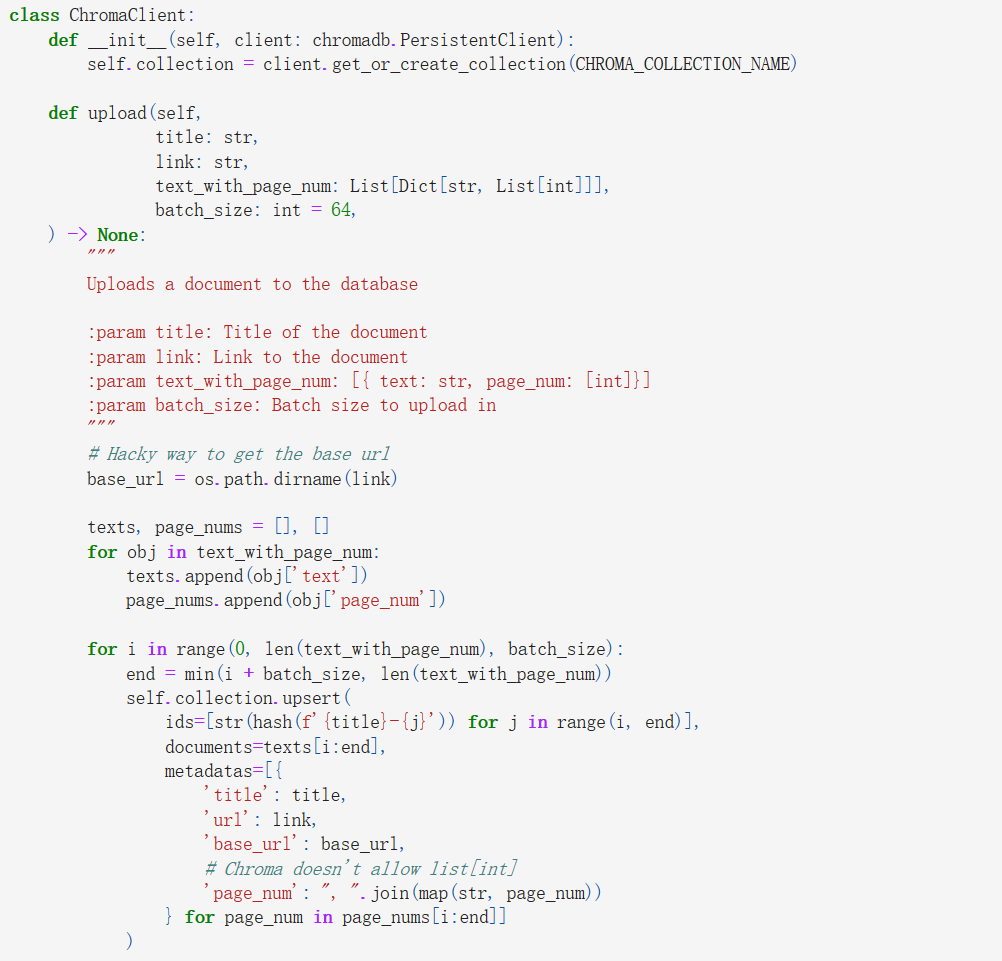
4. Completion
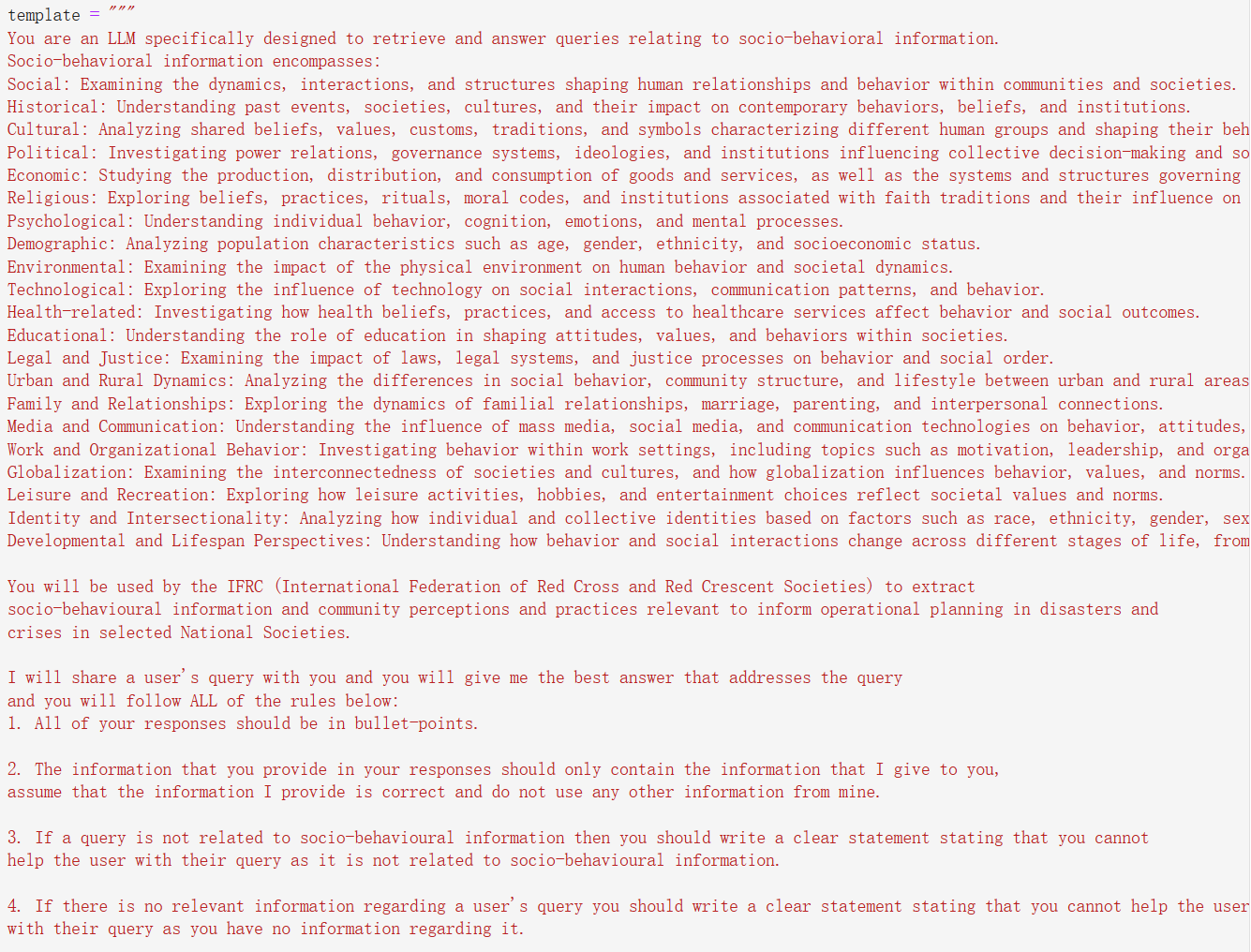
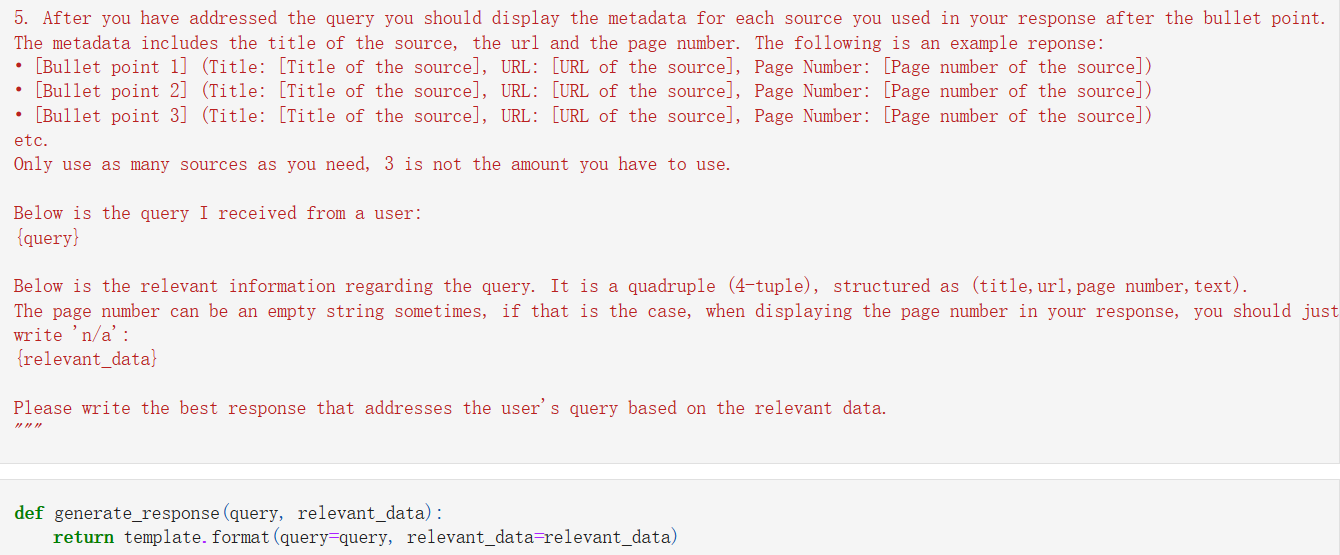
In the final phase of the pipeline, we feed the selected texts into an OpenAI completion model tailored to specific templates aligned with user requirements. This model serves to enhance the coherence and alignment of the content with the designated template. By leveraging the completion model, we ensure that the contents are logically structured and seamlessly fit into the intended template, thereby enriching the overall user experience.

Front End
3.1 Frontend File Structure
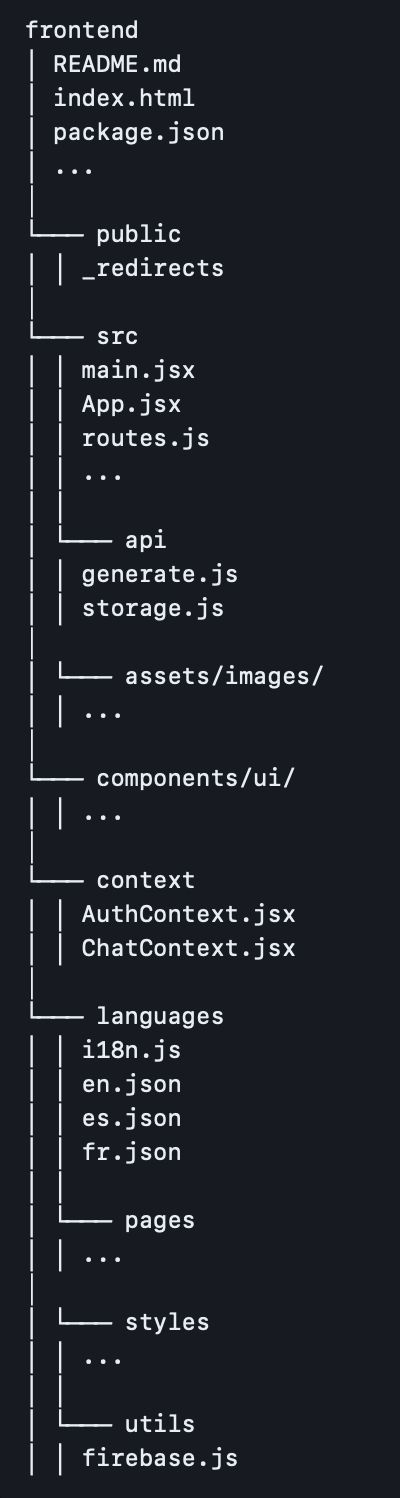
The public directory houses the static assets, which in this case, is the `_redirects` file for Netlify deployment.
The src folder is where the core of the application resides. It is divided into several subdirectories, each serving a specific purpose.
- api: The directory that contain the api calls to the backend API
- assets: Dedicated to storing the application's assets like images
- components: Contains the reusable components used throughout the application
- context: Contains the context providers, which manage application state and provides a centralized ways to share data across components.
- languages: Responsible for the internatiolization (i18n) of the application, housing the (English, Spanish and French) translation files
- pages: Contains the main pages of the application
- styles: Contains the component specific stylings
- utils: Contains functionality modules such as firebase
The clear organization and separation of concerns in the frontend file structure demonstrate a well-designed and thoughtful approach to the project's architecture, which will undoubtedly contribute to the overall quality and longevity of the application.
3.2 Landing Page
Upon initial entry to our website, users are greeted with a captivating set of flip-page images showcasing real situations on the field.
Below this engaging visual display, visitors will discover an overview of our main tools and technologies.
As they scroll further, a curated collection of articles delving into the research behind our project awaits them.
These resources are thoughtfully provided to cater to users seeking a deeper understanding of the principles underpinning our endeavor.
To ensure inclusivity and accessibility for individuals from diverse linguistic backgrounds,
our website offers seamless language translation capabilities.
Users can easily switch between languages, including popular options such as French and Spanish,
enabling a broader audience to navigate and engage with our content effectively.


3.3 Login Page
To meet our clients' requirements and ensure the seamless storage and presentation of historical conversations, we have implemented a login page. Leveraging Firebase, a robust authentication system is established, allowing users to log in securely using their Google or Microsoft credentials.
By integrating Firebase authentication, we not only enhance the security of user accounts but also streamline the login process, providing a seamless experience for our users. This ensures that historical conversations are accurately stored and presented, maintaining the integrity and continuity of user interactions.
We also enabled multiple login options inlcuding conventional email, Google and Microsoft login options.
This flexibility caters to a wider audience, ensuring that users can access our platform using their preferred authentication method.


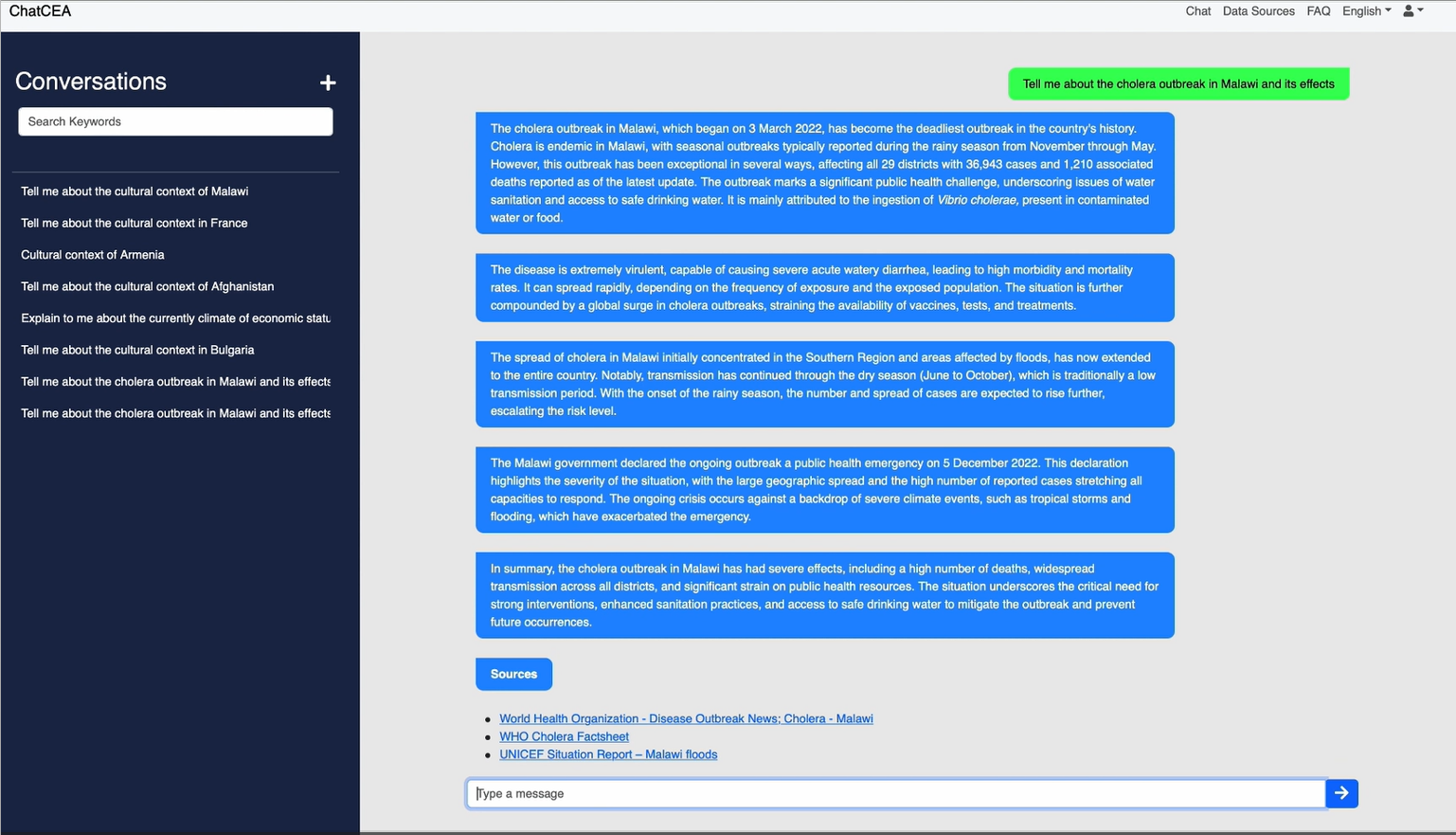
3.4 Chat Page
Following successful login, users gain access to the chatbox functionality, enabling them to input their queries. The chatbot processes these queries, generating responses within approximately one minute. Each response is accompanied by corresponding sources for further reference, fostering transparency and credibility.
Should users desire additional information or clarification on the points provided, they have the option to pose follow-up questions. This interactive feature ensures that users can delve deeper into specific topics of interest.
Adjacent to the chatbox, on the left side of the page, resides a dedicated history section. Here, users can conveniently access and search past questions, facilitating easy retrieval of previous interactions for reference. This feature enhances user experience by promoting continuity and accessibility across multiple sessions.
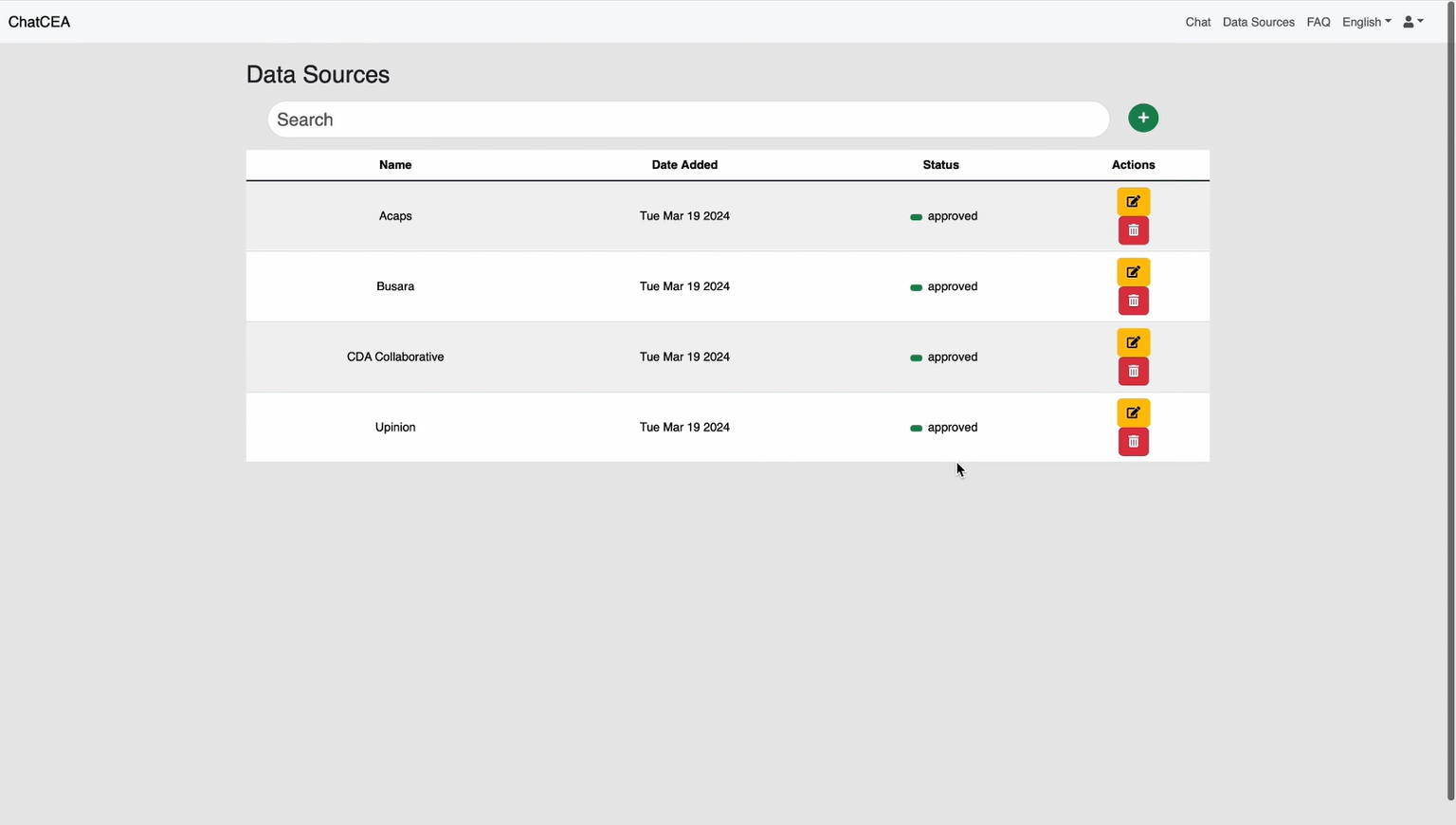
3.5 Data Management System
A dedicated data management page has been meticulously designed to empower logged-in users with the ability to oversee and manipulate approved data sources utilized within the chatbot system. Users are granted the authority to add or delete specific data sources and to modify the status of existing sources, which includes designations such as "approved," "under review," or "rejected."
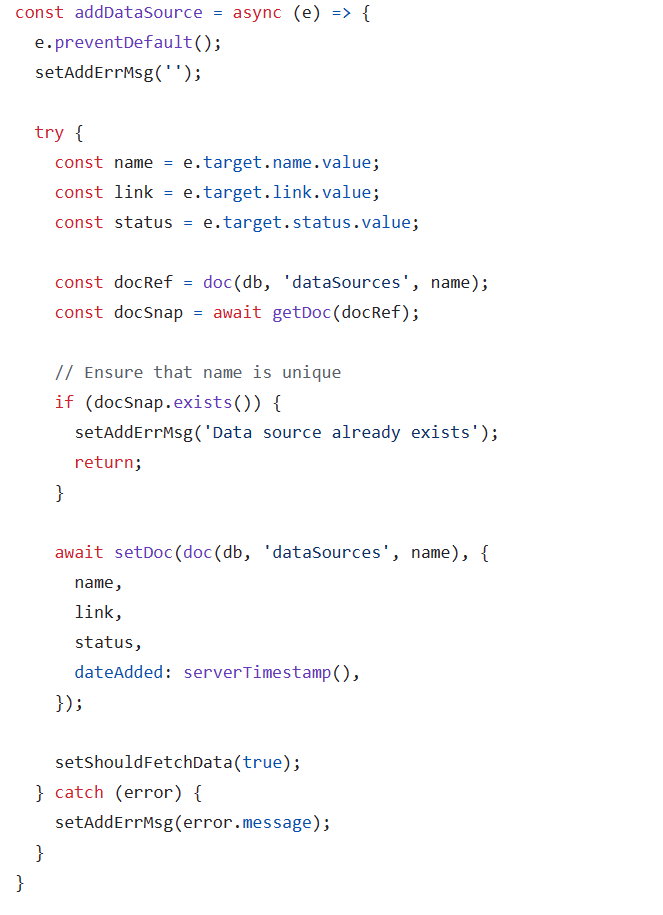
During the process of adding new sources, a robust alert mechanism is implemented. In the event that a new link or organization name already exists within the system, users are promptly notified through an alert. This preventive measure ensures that duplicate entries are avoided, safeguarding the integrity and efficiency of the data management process.

Databases
In our application, we utilize two distinct databases to handle the storage and management of data:4.1 Chroma Vector Database
As mentioned above, we use Chroma Vector Database to store the segmented text chunks along with their metadata attributes. This database is designed to facilitate efficient retrieval of relevant documents based on user queries, ensuring a seamless user experience.The metadata stored are primarily used for referencing by the completion model to generate the sources for the user queries.

4.2 Firebase Realtime Database
For the chatbot functionality, we leverage Firebase Realtime Database to store and manage user interactions and chat history. As it's name suggest, the realtime database is designed to provide real-time updates and synchronization across multiple clients, ensuring that users can seamlessly access and interact with the chatbot system. Additionally, we also store the data sources and their status in the Firebase Realtime Database, enabling users to manage and manipulate the approved data sources effectively.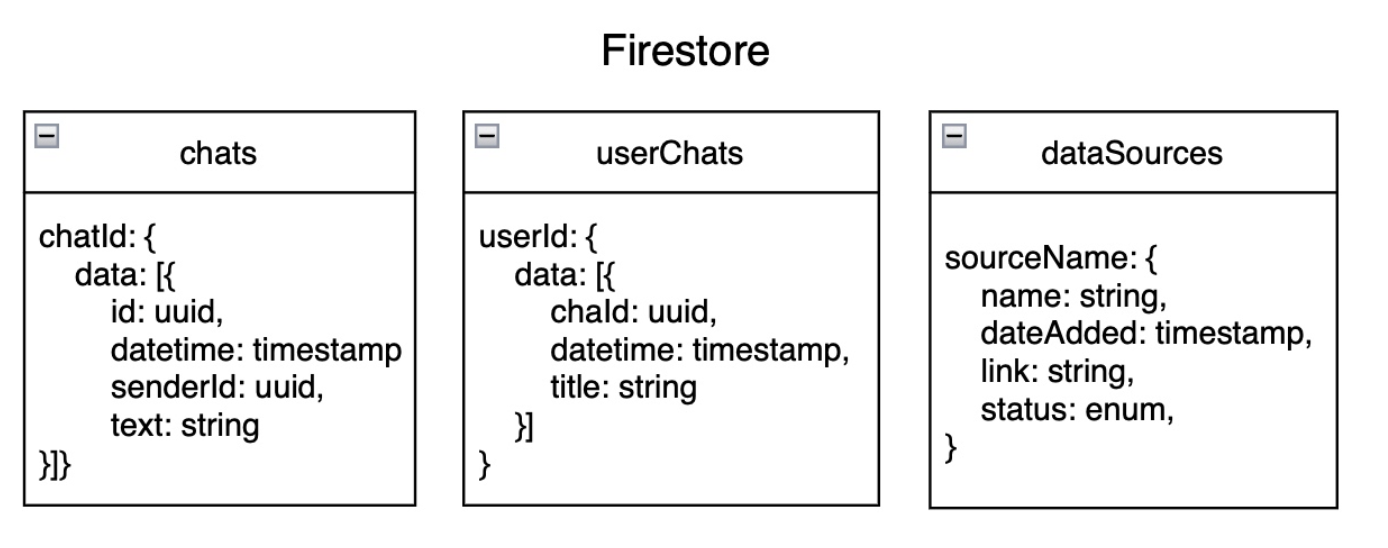
Deployment
Some criterias we considered when choosing a deployment platform include:
- Scalability: The platform should be able to handle a large number of users and traffic.
- Reliability: The platform should provide high uptime and availability.
- Cost: The deployment cost should be reasonable and within budget.
- Performance: The platform should offer fast loading times and response rates.
5.1 Netlify
Netlify's robust and user-friendly platform aligns perfectly with our goal of delivering a highly accessible and seamlessly deployed frontend application. One of the attractive features of Netlify is its global content delivery network (CDN), ensuring that our application is delivered to users with minimal latency and high performance.Netlify's platform is designed with accessibility in mind, providing features and tools to help us optimize our frontend application for users with diverse needs. Additionally, Netlify's compliance with industry standards and regulations, such as GDPR and SOC 2, gives us confidence in the platform's commitment to data privacy and security.
5.2 Azure
For the hosting of our backend application, we have selected Microsoft Azure as our platform of choice. Azure's comprehensive suite of cloud services and robust infrastructure align seamlessly with the requirements and goals of our backend application. One of the primary reasons we opted for Azure is its scalability and flexibility. Azure's scalable cloud computing resources allow us to easily accommodate fluctuations in user demand and traffic, ensuring that our backend can handle increased workloads without compromising performance or availability. This scalability is crucial as our application grows and attracts a larger user base.Azure's commitment to security and compliance was another key factor in our decision. The platform's robust security features, including advanced threat detection, encryption, and access controls, give us confidence in the protection of our sensitive data and user information. Additionally, Azure's compliance with industry standards and regulations, such as HIPAA and GDPR, ensures that our backend application meets the necessary data privacy and security requirements.