Algorithms
String Matching Algorithms
A core aspect of the log viewer web-app is the responsiveness in fetching substring matches. For all records, if it contains the target substring, then it needs to be returned for appropriate highlighting. To do this, there are 3 main algorithms discussed below.
Naive Substring Search
This is a brute force approach of substring matching. For each record, it goes through all the substrings of length k (k being the length of the target substring), and checks if it matches with the target
Click to expand code snippet
export function naiveSubstringSearch(text, pattern) {
const results = [];
const textLength = text.length;
const patternLength = pattern.length;
// Loop over each possible start position in the text
for (let i = 0; i <= textLength - patternLength; i++) {
let match = true;
// Compare character-by-character
for (let j = 0; j < patternLength; j++) {
if (text[i + j] !== pattern[j]) {
match = false;
break;
}
}
// If all characters matched, record the start index
if (match) {
results.push(i);
}
}
return results;
}The naive search has time complexity O(N * K) where N is the number of characters in the record, and K is the number of characters of the target.
KMP Algorithm
The KMP (Knuth-Morris-Pratt) algorithm improves pattern matching by avoiding redundant comparisons. It first preprocesses the pattern to create an LPS (Longest Prefix Suffix) array, where each entry LPS[i] represents the length of the longest proper prefix which is also a suffix for the substring ending at index i. During the search, if a mismatch occurs after some matches, KMP uses the LPS array to shift the pattern efficiently without rechecking characters that are known to match, resulting in a linear-time search.
Click to expand code snippet
// JavaScript program to search the pattern in given text
// using KMP Algorithm
function constructLps(pat, lps) {
// len stores the length of longest prefix which
// is also a suffix for the previous index
let len = 0;
// lps[0] is always 0
lps[0] = 0;
let i = 1;
while (i < pat.length) {
// If characters match, increment the size of lps
if (pat[i] === pat[len]) {
len++;
lps[i] = len;
i++;
}
// If there is a mismatch
else {
if (len !== 0) {
// Update len to the previous lps value
// to avoid redundant comparisons
len = lps[len - 1];
} else {
// If no matching prefix found, set lps[i] to 0
lps[i] = 0;
i++;
}
}
}
}
export function search(pat, txt) {
const n = txt.length;
const m = pat.length;
const lps = new Array(m);
const res = [];
constructLps(pat, lps);
// Pointers i and j, for traversing
// the text and pattern
let i = 0;
let j = 0;
while (i < n) {
// If characters match, move both pointers forward
if (txt[i] === pat[j]) {
i++;
j++;
// If the entire pattern is matched
// store the start index in result
if (j === m) {
res.push(i - j);
// Use LPS of previous index to
// skip unnecessary comparisons
j = lps[j - 1];
}
}
// If there is a mismatch
else {
// Use lps value of previous index
// to avoid redundant comparisons
if (j !== 0)
j = lps[j - 1];
else
i++;
}
}
return res;
}The search algorithm works by doing a letter by letter comparison between the source and target string. However, if there is a character mismatch, instead of restarting from the beginning of the target string, the algorithm jumps back to the last matched prefix. By doing so, redundant comparisons are not performed.
The KMP algorithm is an improvement from Naive Search, with guaranteed time complexity O(N + K). O(N) for preprocessing, and O(K) for searching.
Boyer-Moore Algorithm
Boyer–Moore is a classic algorithm for finding a substring within a larger string. It’s known for being very efficient in practice, especially on typical English text or other natural-language data, because it uses information gained from mismatches to skip large sections of the text.
Instead of checking the pattern from left to right (like the naive approach), Boyer–Moore compares characters starting from the rightmost end of the pattern. When there is a mismatch, it uses precomputed rules (the bad character rule and the good suffix rule) to decide how far to shift the pattern before trying to match again.
Click to expand code snippet
/**
* Boyer–Moore Substring Search
*
* Returns an array of all starting indices where `pattern` is found in `text`.
* The implementation uses both the Bad Character rule and the Good Suffix rule.
*
* @param {string} text - The text in which to search.
* @param {string} pattern - The pattern to search for.
* @returns {number[]} An array of start indices of matches.
*/
export function boyerMooreSearch(text, pattern) {
const n = text.length;
const m = pattern.length;
// Edge case: if pattern is empty, match at every position by convention or return empty
if (m === 0) {
return [...Array(n + 1).keys()]; // or simply return []
}
// 1. Build the "bad character" table.
// badChar[c] will store the rightmost index of character c in `pattern`.
// If c does not appear in `pattern`, it remains -1.
const badChar = buildBadCharTable(pattern);
// 2. Build the "good suffix" table.
// goodSuffix[i] indicates how far to shift if a mismatch happens at position i in the pattern.
const goodSuffix = buildGoodSuffixTable(pattern);
const matches = [];
let s = 0; // s is the shift of the pattern with respect to text
while (s <= n - m) {
let j = m - 1;
// Move backwards through pattern comparing to text
while (j >= 0 && pattern[j] === text[s + j]) {
j--;
}
if (j < 0) {
matches.push(s);
s += goodSuffix[0];
} else {
const charCode = text.charCodeAt(s + j);
const badCharShift = j - (badChar[charCode] ?? -1);
const goodSuffixShift = goodSuffix[j];
s += Math.max(badCharShift, goodSuffixShift, 1);
}
}
return matches;
}
/**
* Builds the bad character table for Boyer–Moore.
* For simplicity, we’ll assume an extended ASCII set (0-255).
*
* @param {string} pattern
* @returns {number[]} badChar - The last (rightmost) position of each character in pattern.
*/
function buildBadCharTable(pattern) {
const tableSize = 256; // For extended ASCII
const badChar = new Array(tableSize).fill(-1);
for (let i = 0; i < pattern.length; i++) {
badChar[pattern.charCodeAt(i)] = i;
}
return badChar;
}
/**
* Builds the good suffix table for Boyer–Moore using the standard suffix-based approach.
* goodSuffix[i] tells how far to shift the pattern if a mismatch occurs at pattern[i].
*
* @param {string} pattern
* @returns {number[]} goodSuffix - Shift distances by pattern index on mismatch.
*/
function buildGoodSuffixTable(pattern) {
const m = pattern.length;
const goodSuffix = new Array(m).fill(m);
const suffix = new Array(m).fill(0);
// Step 1: Build the `suffix` array
// suffix[i] = the length of the longest suffix of pattern[i..m-1] which is also a prefix of pattern.
// We fill this from right to left.
suffix[m - 1] = m;
let g = m - 1; // boundary for suffix that matches prefix
let f = m - 1; // backup pointer
for (let i = m - 2; i >= 0; i--) {
if (i > g && suffix[i + (m - 1 - f)] < i - g) {
suffix[i] = suffix[i + (m - 1 - f)];
} else {
if (i < g) {
g = i;
}
f = i;
while (g >= 0 && pattern[g] === pattern[g + (m - 1 - f)]) {
g--;
}
suffix[i] = f - g;
}
}
// Step 2: Build the goodSuffix array
// Initialize all shifts to m by default.
// Then compute the actual shift values based on the suffix array.
// A partial match of length suffix[i] implies a certain shift.
for (let i = 0; i < m; i++) {
goodSuffix[i] = m;
}
// Case 1: When suffix[i] = i + 1, the entire substring from i to end is a prefix
// We fill the leftmost positions in goodSuffix
let j = 0;
for (let i = m - 1; i >= 0; i--) {
if (suffix[i] === i + 1) {
for (; j < m - 1 - i; j++) {
if (goodSuffix[j] === m) {
goodSuffix[j] = m - 1 - i;
}
}
}
}
// Case 2: Other cases based on suffix lengths
for (let i = 0; i < m - 1; i++) {
goodSuffix[m - 1 - suffix[i]] = m - 1 - i;
}
return goodSuffix;
}Boyer-Moore algorithm has time complexity of O(N * K) in the worst case, where the target string and the source string share most/all characters, for example source = “aaaaaaaaaaaaaaa”, and target = “aaaaab”. In this case, large jumps cannot be made, and so the time complexity is poor. However, in practice, this is not realistic, and Boyer-Moore runs much faster than simpler string matching algorithms like Naive Search and KMP, with time complexity O(N / K) due to large jumps.
Comparison
To determine which algorithm to use moving forward, we ran detailed performance analysis of the 3 on varying input sizes. The test case works by randomly generating a string of length n, while keeping the target string constant across tests. For each length, we ran each algorithm 3 times. and took the mean average to plot.
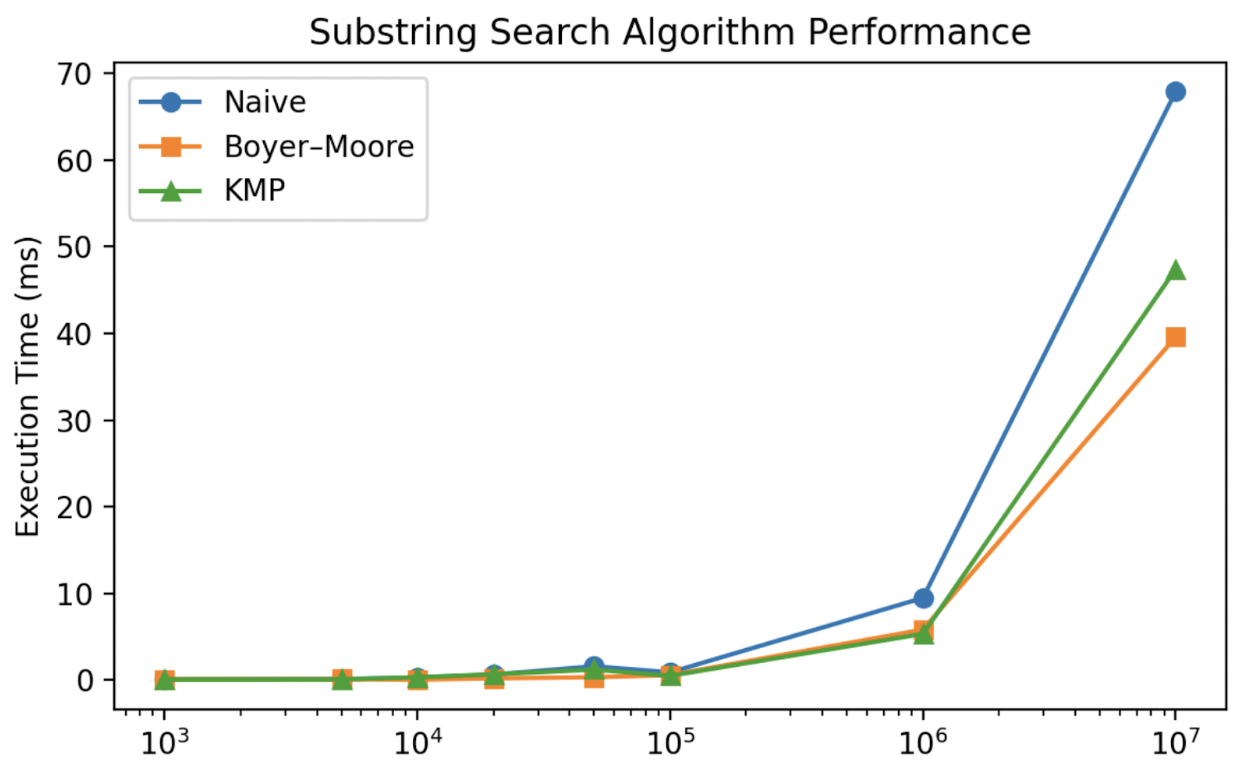
From the graph above, it can be seen that for small strings, the performance difference between the algorithms is negligible, but as the size grows beyond 106, the Boyer-Moore algorithm performs the best. It has been established by talking with our clients that the datasets have around 107 records. Therefore, we decided to use the .includes() method for substring search, which utilises the Boyer-Moore algorithm, instead of creating our own version.
Regex Caching
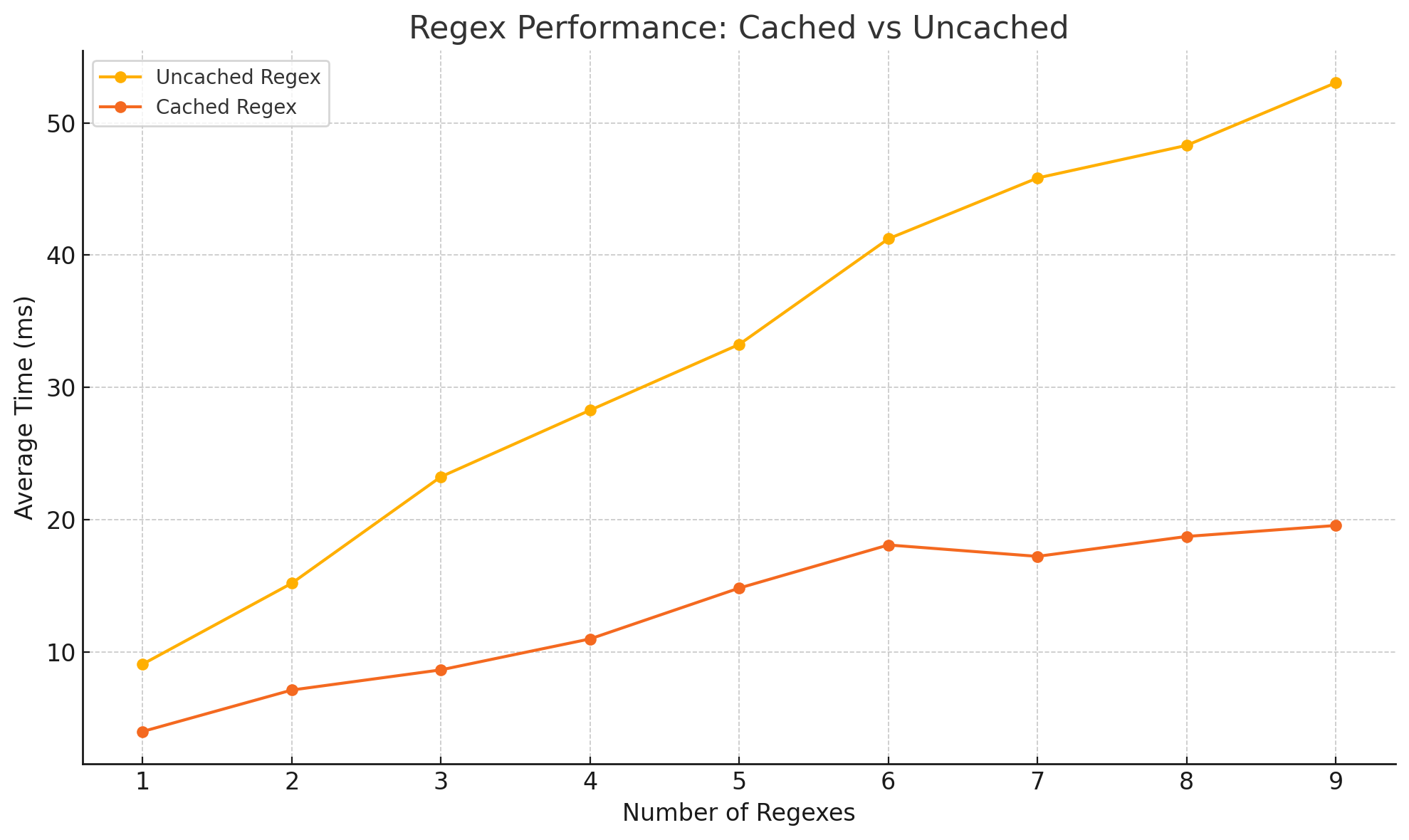
Whilst exploring Cisco's current filtering functionality, we noticed some places where there's unnecessary computations and where performance can be Improved. Specifically, RegExp patterns were being compiled again and again on each log record iteration, which is extremely wasteful. Hence, we've changed the code to instead cache RegExp patterns as soon as they are created and only recompiling them if they are updated. This lead to the following improvements for regex filtering time:
Click to expand code snippet
/**
* Filter logs by searching inside `message` field and keeping logs which match specific keywords.
* Runs the filter 100 times to get an average runtime.
*
* @param {Keyword[]} filterKeywords - An array of keywords to filter by.
*/
function filterItemsByFilterGroups(filterKeywords) {
console.log(filterKeywords);
const runs = 100;
let totalTime = 0;
for (let run = 0; run < runs; run++) {
// Deep copy to reset filtered_items for each run (just for safety)
let items = [...filtered_items];
const start = performance.now();
if (filterKeywords.length !== 0) {
const new_items = [];
const filterLimit = max_page_size;
for (let i = 0; i < items.length; i++) {
const log = items[i];
if (filterKeywords.some(keyword => {
const caseSensitive = keyword.caseSensitive !== undefined ? keyword.caseSensitive : true;
if (keyword.regex) {
const pattern = keyword.pattern;
return pattern.test(log.message);
} else {
return caseSensitive
? log.message.includes(keyword.text)
: log.message.toLowerCase().includes(keyword.text.toLowerCase());
}
})) {
new_items.push(log);
}
}
items = new_items;
}
const end = performance.now();
totalTime += (end - start);
}
const average = totalTime / runs;
console.log(`Average filter time over ${runs} runs: ${average.toFixed(3)} ms`);
}Explanation of Algorithm & Results
This function filters a list of log items (filtered_items) by checking if their message field matches any of the provided filter keywords (with support for regex, case sensitivity, etc.). It repeats the filtering 100 times to measure and log the average runtime.
As the number of regexes increases, average time for uncached regexes grows sharply — from ~9 ms (1 regex) to ~54 ms (9 regexes).
- This is because compiling regex patterns is expensive.
- Creating new regex objects in every iteration leads to repeated overhead.
With cached regexes, performance is consistently better — only ~20 ms even at 9 regexes.
- The compiled patterns are reused, so there's no need to rebuild them every time.
- This keeps filtering efficient, especially as more patterns are added.
Overall, this algorithm introduced a 2.7x performance boost in in filtering speeds involving regexes
Prefix Matching
One feature that we were keen to implement was a search bar that filters all records containing a search string or search regex pattern. Since these regex patterns and filters can get quite large, they become tedious to repeatedly type, and so we wanted to implement a way to save previous searches, and use prefix matching algorithms to provide the user with search prompts based on their history.
To do this, we implemented a 3-way trie data structure. The data held in the trie should persist across page refreshes and updates; therefore, the contents of the trie are held in the browser’s localStorage. Regarding the trie, there are 2 core functionalities needed:
- A new word should be inserted into the trie
- All the words matching a prefix string should be retrieved
Here is a brief explanation of 3-way tries:
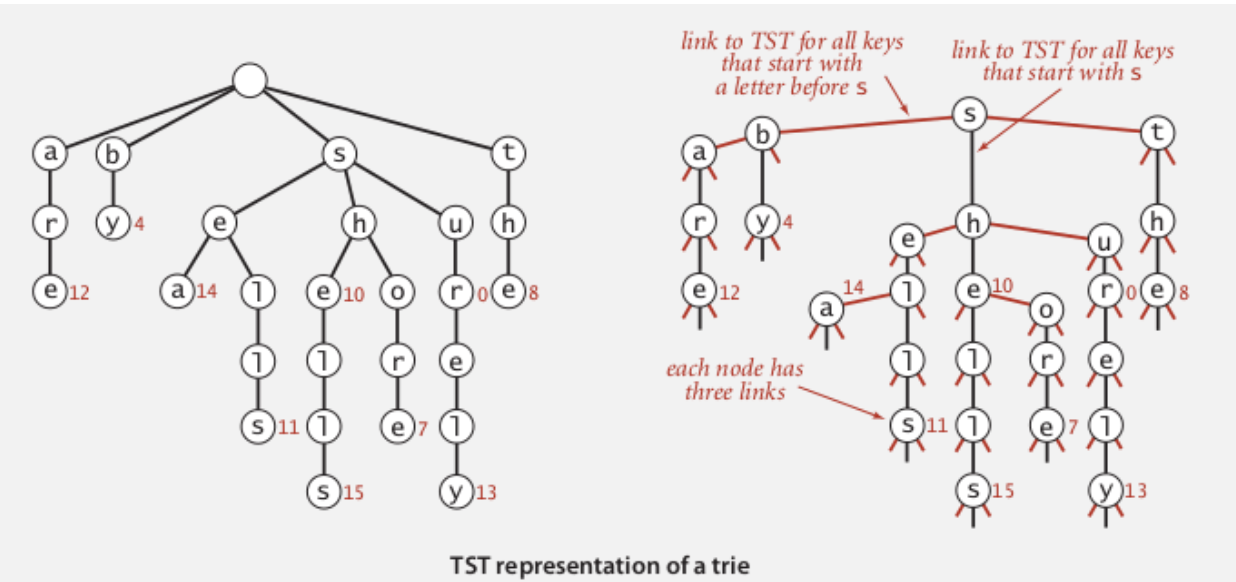
The diagram shows how each character is represented as a node in the trie, and the last character in a word has an associated value, which is essential in word collection from a prefix. In our case, the value of a node for the final character in a string is the number of times that word is chosen (frequency of word). The value of the intermediary nodes is set to 0. A key aspect of the trie is that it is ordered. For a given node N, the node on its left is a character of a word lexicographically smaller than the current word, the node in its middle is the next character of the current word, and the node on the right is part of a word lexicographically larger than the current word.
Word Insertion
Click to expand code snippet
_insertWord(currNode, s, idx) {
if (currNode == null) {
currNode = new Node();
currNode.character = s[idx];
}
if (s[idx] > currNode.character) {
currNode.right = this._insertWord(currNode.right, s, idx);
} else if (s[idx] < currNode.character) {
currNode.left = this._insertWord(currNode.left, s, idx);
} else if (idx < s.length - 1) {
currNode.middle = this._insertWord(currNode.middle, s, idx + 1);
} else if (idx == s.length - 1){
currNode.freq++;
}
return currNode;
}Explanation of Algorithm
- The string s typed into the search bar is passed into the function
- Starting at the root node, you match the largest prefix p§ossible through in-order tree traversal
- If that word already exists in the trie, the increment the frequency of the node corresponding to the last character of the string
- If it does not, keep creating new nodes till you reach the last character of the string
Word Collection
Click to expand code snippet
collect(prefix, numberOfMatches) {
let matches = [];
if (prefix == "") {
return matches;
// this._collect(this.root, "", matches);
} else {
var currNode = this.getStartNode(prefix);
if (currNode == null) {
return matches;
}
if (currNode != null && currNode.freq > 0) {
matches.push(new Pair(prefix, currNode.freq));
}
this._collect(currNode.middle, prefix, matches);
}
const pq = new PriorityQueue(numberOfMatches);
matches.forEach((pair) => {
console.log(pair.word + " " + pair.freq);
pq.insert(pair);
})
const result = pq.getTopResults();
return result;
}
_collect(currNode, word, matches) {
if (currNode == null) {
return;
}
if (currNode.freq > 0) {
matches.push(new Pair(word + currNode.character, currNode.freq));
}
this._collect(currNode.left, word, matches);
this._collect(currNode.middle, word + currNode.character, matches);
this._collect(currNode.right, word, matches);
}
_printMatches(matches) {
matches.forEach((e) => {console.log(e.word + " " + e.freq)});
}Explanation of Algorithm
- Find the node corresponding to the last character of the current prefix. This is the start node of the collection algorithm
- From this node run a tree traversal exploring the left, middle and right nodes of the current node
- If a node with a non-zero frequency is encountered, it means it is a word with a shared prefix, so add it to the matches list
- From this list, the words with the top 5 frequencies are chosen using a custom priority queue.
Another key aspect is how the trie is stored in localStorage. In localStorage, data has to be stored as a string, and so the trie cannot be stored in its natural state. For this area of prefix matching, the 2 core stages are:
Building the JSON from a trie
Click to expand code snippet
export const trieToJSON = () => {
let trieJSON = buildTrieJSON(suggestionTrie.root, {});
return trieJSON;
}
const buildTrieJSON = (node, trieJSON) => {
if (node == null) {
return null;
}
trieJSON['character'] = node.character;
trieJSON['freq'] = node.freq;
if (!trieJSON['left']) {
trieJSON['left'] = {};
}
trieJSON['left'] = buildTrieJSON(node.left, trieJSON['left']);
if (!trieJSON['middle']) {
trieJSON['middle'] = {};
}
trieJSON['middle'] = buildTrieJSON(node.middle, trieJSON['middle']);
if (!trieJSON['right']) {
trieJSON['right'] = {};
}
trieJSON['right'] = buildTrieJSON(node.right, trieJSON['right']);
return trieJSON;
}Explanation of Algorithm
- The JSON should be built like:
- The algorithm checks if an object exists for left, middle, right, and creates them if they don’t.
- Then recurse on the left, middle and right.
- Finally, stringify the JSON before pushing the k-v pair to localStorage as follows.
window.localStorage.setItem('suggestionTrie', JSON.stringify(trieJSON));Building Trie from JSON
Click to expand code snippet
export const trieFromJSON = (trieJSON) => {
let newTrie = new Trie();
newTrie.root = buildTrie(newTrie.root, trieJSON);
return newTrie;
}
const buildTrie = (node, trieJSON) => {
if (trieJSON == null) {
return null;
}
if (node == null) {
node = new Node();
}
node.character = trieJSON['character'];
node.freq = trieJSON['freq'];
node.left = buildTrie(node.left, trieJSON['left']);
node.right = buildTrie(node.right, trieJSON['right']);
node.middle = buildTrie(node.middle, trieJSON['middle']);
return node;
}Explanation of Algorithm
- If the current object is not null, the create a node with the character and frequency specified in the object
- Traverse down the left, middle and right to recursively build the trie
Select top K
In the search functionality, only the k most frequently used words should be displayed. The naive approach would be to collect all the words, and sort them in descending order, from which the first k can be selected, but in an environment where performance and responsiveness of the application is crucial, we decided to explore more optimised data structures & algorithms. For this purpose, we built a custom priority queue with an underlying binary min-heap.
Explanation of a binary min-heap:
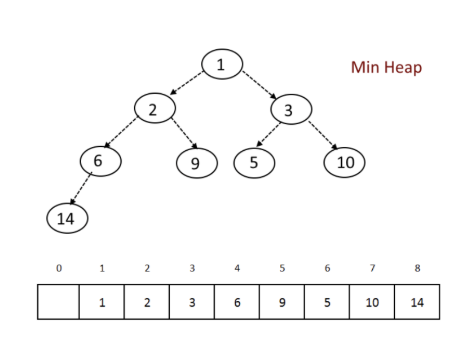
A binary min-heap is stored as a 1 indexed array where the parent of a node is stored at index idx // 2, the left child of a node is at index 2 * idx, and the right child at index 2 * idx + 1. The property of a min heap is that the parent has a value less than its left child and right child. In our case, a parent node would have a lower frequency than its 2 children. Another crucial property is that before and after each operation, the tree will be a complete binary tree.
The main algorithms are as follows:
Insertion
Click to expand code snippet
insert(pair) {
this.heap[++this.n] = pair;
this._swim(this.n);
if (this.n > this.maxSize) {
this._deleteMin();
}
}
_swim(k) {
while (k > 1 && this._greater(this.heap[Math.floor(k / 2)], this.heap[k])) {
this._swap(Math.floor(k / 2), k);
k = Math.floor(k / 2);
}
}Explanation of Algorithm
-
When a
- It is repeatedly swapped with its parent node while its frequency is less than its parent’s frequency
- If the number of nodes in the heap is greater than k, the min element is removed to ensure that only the k most frequent words remain.
Deletion
Click to expand code snippet
_deleteMin() {
this._swap(1, this.n--);
this._sink(1);
this.heap[this.n + 1] = new Pair("", 0);
}
_sink(k) {
while (2 * k <= this.n) {
let j = 2 * k;
if (j < this.n && this._greater(this.heap[j], this.heap[j + 1])) {
j++;
}
if (!this._greater(this.heap[k], this.heap[j])) {
break;
}
this._swap(k, j);
k = j;
}
}Explanation of Algorithm
- The first element in the heap array is the minimum. This is replaced with the largest element in the heap which is the last element of the array.
- The new top element is then sunk back to restore the heap properties by comparing its frequency to max(left child.freq, right child.freq) and swapping if necessary.