System Design
Desigining & engineering a system that can effectively cover our requirements.
🔧 System Architecture Overview
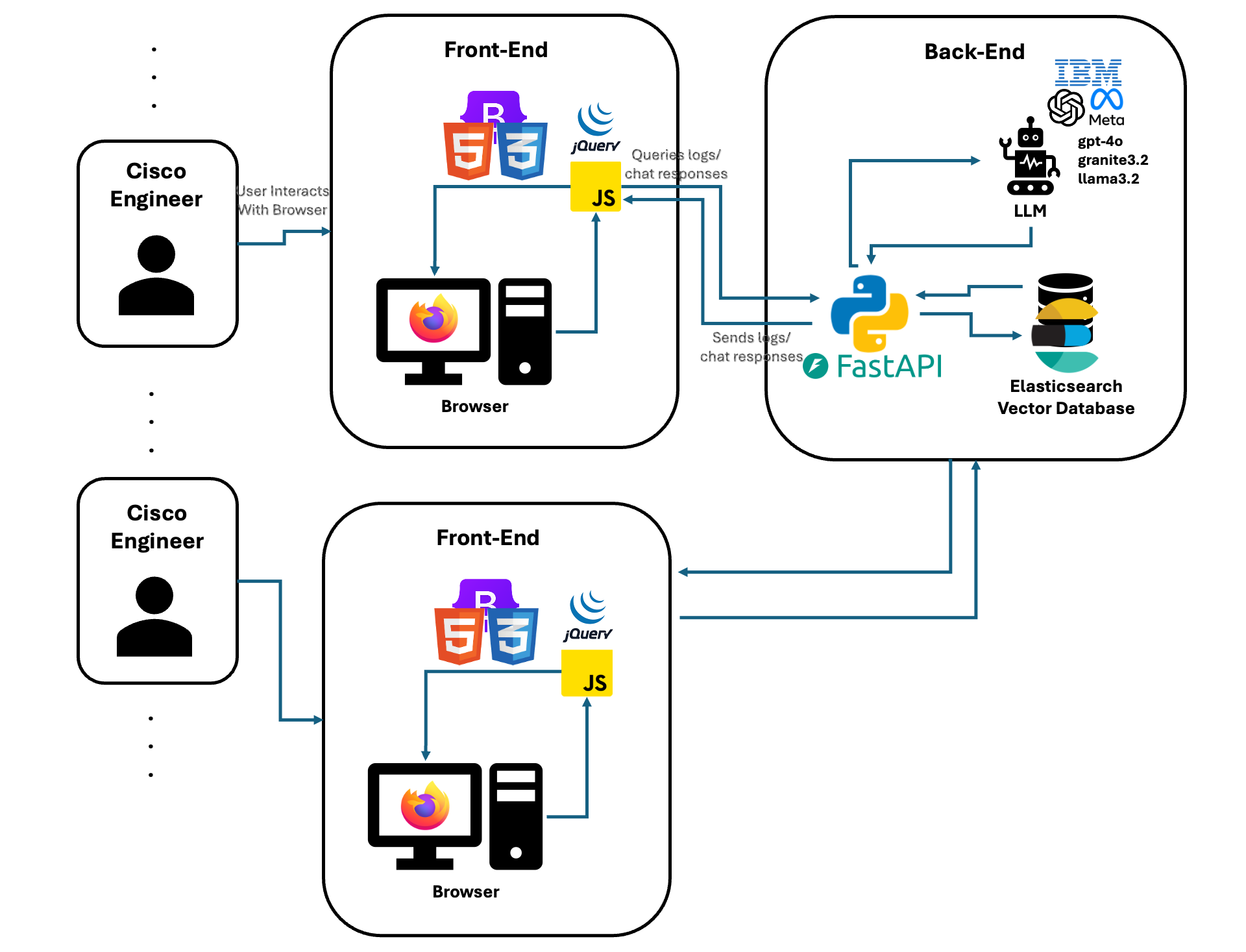
The Log Viewer System is composed of several interrelated components that allow Cisco engineers to seamlessly interact with logs, perform intelligent searches, and receive real-time insights. The system can operate fully offline and is modular by design.
More details about the major components can be found in the respective sections below.
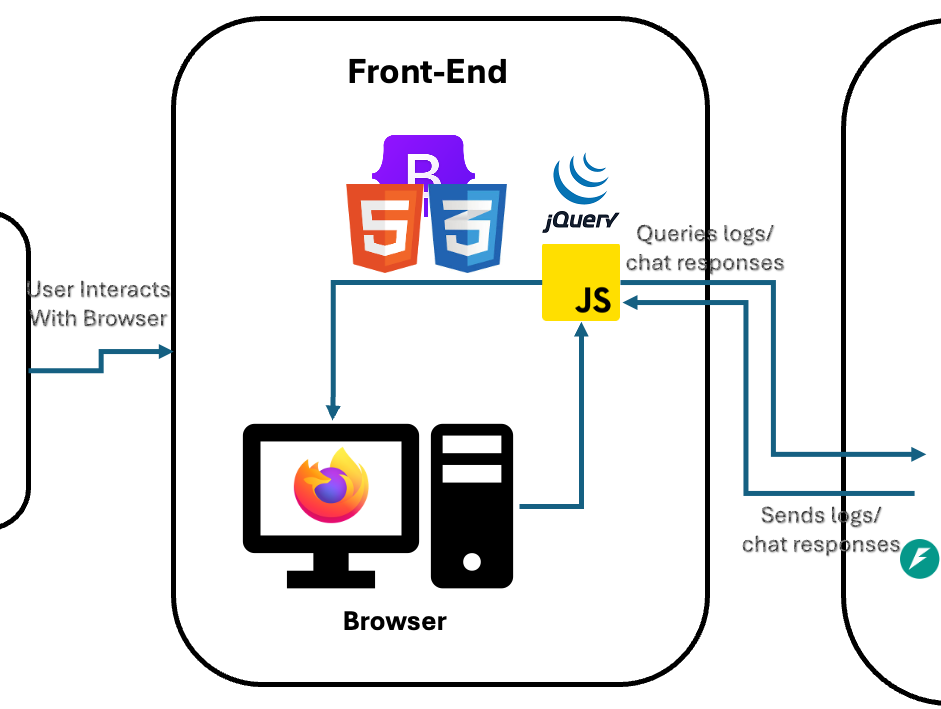
🌐 Front-End Architecture
- Handles user interactions like:
- Uploading log files.
- Querying logs or requesting AI assistance.
- Uses Server-Sent Events (SSE) to receive real-time updates from the backend once asynchronous tasks complete.
- Sends user inputs (log search queries or AI prompts) to the backend via HTTP requests.
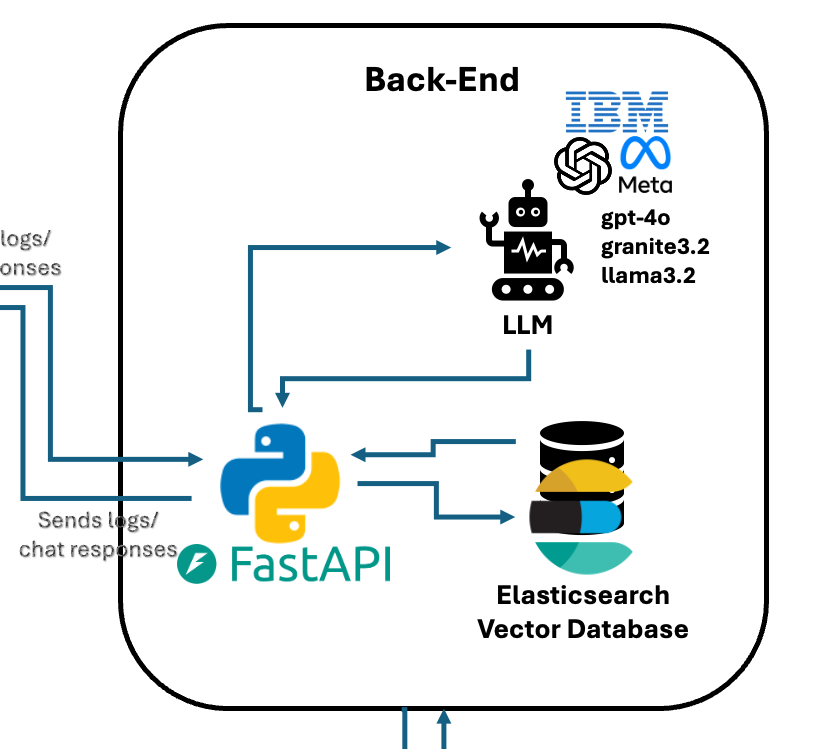
🧠 Back-End Architecture
- Implemented using Python’s FastAPI, this component handles:
- Log queries and responses (from/to the database).
- AI-agent powered queries using a Retrieval-Augmented Generation (RAG) structure.
- The backend is capable of operating fully offline, and users can deploy their own local instances.
More details about the database and RAG AI in following sections
🤖 RAG-Enhanced AI-Driven Log Analysis Component
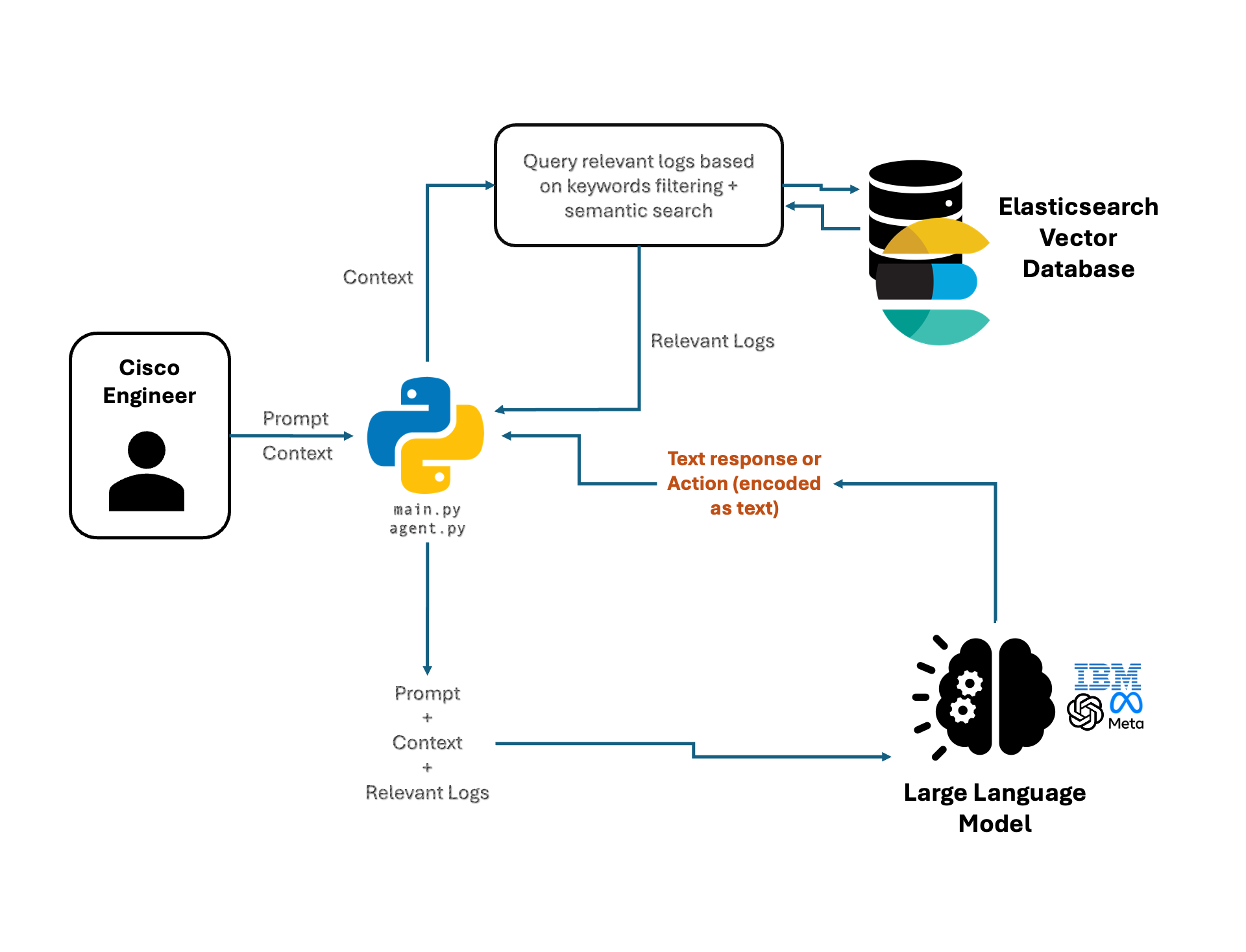
Our system employs a Retrieval-Augmented Generation (RAG) framework to deliver intelligent log analysis. The core functionality is driven by robust keyword and regex matching, which is augmented by semantic search when precomputed embeddings are available. This design ensures that even if semantic embeddings are not yet ready, the system continues to operate using the proven matching methods, guaranteeing uninterrupted service. Moreover, as soon as any asynchronous action completes, its result is instantly transmitted to the front end, ensuring a fluid and responsive user experience.
Component Architecture & Workflow:
Endpoint & Asynchronous Streaming:
-
The AI functionality is exposed via a RESTful endpoint (
/chat_stream) built with FastAPI. Responses are streamed back using Server-Sent Events (SSE), which means:- As each asynchronous action (e.g., summary generation, issue evaluation, filter creation) completes, its result is immediately sent to the front end.
- This real-time streaming ensures that users receive incremental updates, keeping the interaction seamless and responsive.
Chat Agent Orchestration:
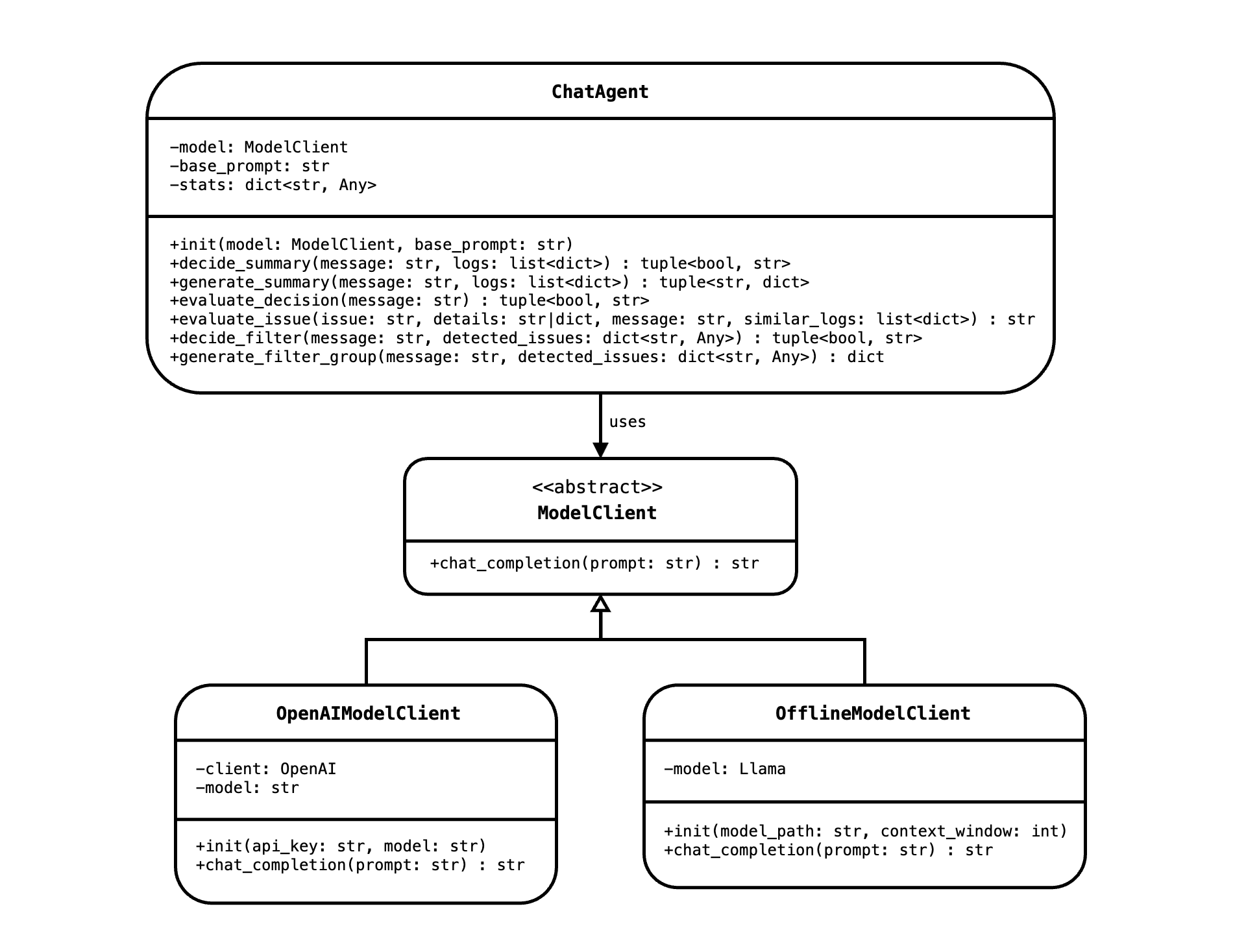
As shown in the UML diagram, the ChatAgent class orchestrates multiple asynchronous steps to process user queries:
Summary Decision & Generation:
-
decide_summary: Analyzes log statistics (via functions like
get_log_level_countsandcompute_stats) to decide if a summary should be generated. - generate_summary: If needed, generates a natural language summary of the log statistics using the RAG approach, which blends retrieved log data with generated insights.
Known Issue Evaluation:
- evaluate_decision: Determines whether the user query necessitates checking for known issues.
- evaluate_issue: Uses robust keyword/regex matching to extract relevant log segments. When semantic embeddings are available, it further enriches this data with contextually similar log entries, ensuring high detection accuracy.
Filter Decision & Generation:
- decide_filter: Evaluates the user query and any detected issues to decide if additional filtering is required.
- generate_filter_group: Generates a JSON-formatted filter group detailing keywords or regex patterns, case-sensitivity, and suggested highlight colors.
Hybrid Matching Approach:
- Core Keyword/Regex Matching: This method forms the backbone of the log analysis, delivering high-quality, robust pattern recognition.
- Semantic Search Augmentation: When available, precomputed embeddings allow the system to perform semantic search, adding a layer of contextual understanding. This additional information is integrated seamlessly without delaying the core functionality.
Design Principles & Patterns:
- RAG Framework: The combination of retrieval (via keyword/regex and semantic search) with generative capabilities forms the basis of the RAG approach. This design empowers the system to produce nuanced summaries and detect issues with a high degree of contextual awareness.
- Asynchronous & Event-Driven Architecture: Leveraging asynchronous programming alongside SSE, the system processes tasks concurrently and streams each result immediately upon completion. This ensures that users experience minimal latency and continuous feedback throughout their interaction.
-
Modularity & Decoupling: As illustrated in the UML diagram, the
ChatAgentclass depends on an abstractModelClientinterface, rather than a concrete implementation. This separation means that the ChatAgent remains independent of the underlying model details, promoting maintainability, testability, and straightforward swapping of different model backends when needed. Each function—from summary generation to filter creation—is encapsulated within dedicated methods, further isolating components and enabling independent updates or enhancements. - Flexible Algorithmic Strategy: The modular decision-making logic allows for independent modifications to summarization, issue evaluation, or filtering processes. The hybrid matching approach ensures robustness regardless of the state of semantic embeddings, supporting both immediate keyword/regex matching and enhanced semantic searches when embeddings become available.
Integration with the Overall System:
The AI module interacts directly with the Elasticsearch-based log storage, utilizing real-time log statistics along with background-generated metadata. The outputs (log summaries, flagged issues, and dynamic filters) are seamlessly integrated into the log viewer web-app, ensuring that engineers have immediate access to actionable insights. This RAG-enhanced design, coupled with immediate asynchronous event streaming to the front end, guarantees that the AI-driven log analysis component remains both responsive and robust, providing a high-quality user experience at all times.
🗃️ Database Design & Vector Search
Scale & Performance Considerations
From discussions with our clients, we estimate that each log file contains approximately 107 data records. Assuming each record is about 1 kB in size, a single log file requires roughly 10 GB of storage. Our tool supports loading multiple files for faster access; if up to 5 files are loaded concurrently, this amounts to a maximum storage requirement of around 50 GB. Furthermore, the tool is used by a small team at Cisco (around 10 people). Due to the modest storage needs and low traffic volume, we did not implement big data solutions such as load balancers or geographical partitioning. Instead, our focus is on ensuring fast retrieval times to deliver rapid search and filtering capabilities for engineers.
As mentioned in Research, we chose an Elasticsearch database for this application. A key feature of Elasticsearch is its scroll feature: large datasets, such as log files, are automatically paged, and Elasticsearch scrolls through all pages to fetch results in batches.
Since Elasticsearch is a document-based database rather than a SQL database, it does not have a
fixed schema.
Instead, the structure of the documents is determined by the data passed into it.
In our case, a JSON object with the format
{ "logs": [...], "title": "<Title>", "description": "<Description>" }
is sent to the upload_file endpoint.
Each object in the logs array becomes a new document in the Elasticsearch index, taking
full advantage of its schema-flexible nature.
Example Record from a Log File
{
"timestamp": "2025-01-16T14:18:52.024Z",
"level": "Debug",
"thread ID": "[0xd1ba62]",
"messages": [
"[]MediaApplication.cpp:318 startLogger::Started media logger. LogFile = ********/Library/Logs/SparkMacDesktop/media/calls/1737037131593_0e6b4dfa-ca34-4422-8f4a-9e260cad346c.log"
]
}
Document in Elasticsearch
{
"_index": "your_index_name",
"_id": "0",
"_source": {
"timestamp": "2025-01-16T14:18:52.024Z",
"level": "Debug",
"thread ID": "[0xd1ba62]",
"messages": [
"[]MediaApplication.cpp:318 startLogger::Started media logger. LogFile = ********/Library/Logs/SparkMacDesktop/media/calls/1737037131593_0e6b4dfa-ca34-4422-8f4a-9e260cad346c.log"
]
}
}
When queries are performed on the database, they are referenced by their index name and document ID.
Vector Database & Semantic Search
In addition to its document-based storage, our Elasticsearch instance is used as a vector database.
We generate embeddings in the background for the log data using a local
msmarco-MiniLM-L12-cos-v5
sentence transformer (running on GPU if available). Later, these embeddings are leveraged by the LLM
to perform semantic search—enabling retrieval of contextually similar log entries.
Embedding Schema & Similarity Index
The following Python snippet shows how we create an Elasticsearch index with a mapping designed for
similarity search.
Notice how the embedding field is defined as a dense vector (with 384 dimensions) and
configured to use cosine similarity.
def create_similarity_index(es: Elasticsearch, index_name: str, title: str, description: str):
"""
Creates an Elasticsearch index with a mapping for similarity search.
"""
mapping = {
"mappings": {
"_meta": {"title": title, "description": description},
"properties": {
"message": {"type": "text"},
"embedding": {
"type": "dense_vector",
"dims": 384,
"index": True,
"similarity": "cosine",
},
},
}
}
if not es.indices.exists(index=index_name):
es.indices.create(index=index_name, body=mapping)
else:
print(f"Index '{index_name}' already exists.")
This mapping not only stores the log messages but also the generated embeddings. By doing so, we enable efficient semantic searches on the log data, combining traditional keyword queries with vector-based similarity matching.
📡 API Design & Packages
Our backend is built using FastAPI for asynchronous RESTful endpoints and is served via Uvicorn. The API is designed to handle tasks such as log ingestion, real-time streaming of analysis results, and semantic search through Elasticsearch.
The API supports various endpoints to manage logs and enable chat-driven analysis. Key endpoints include:
Key Endpoints
-
GET /table/{id}: Retrieves logs from a specific Elasticsearch index (log file) and removes theembeddingfield for output. -
POST /table/{id}: Accepts a JSON payload of logs (with title and description) and uploads them to Elasticsearch. This endpoint also schedules background tasks for computing embeddings. -
DELETE /table/{id}: Deletes a specified Elasticsearch index. -
GET /table: Lists all log indices along with their metadata. -
POST /chat_stream: Streams real-time responses for log analysis via Server-Sent Events (SSE). This endpoint coordinates tasks like summary generation, known issue evaluation, and filter group creation.
Dependencies & Packages
Our Front-End utilizes the following key packages:
- Vite: A modern build tool that significantly speeds up the development process.
- jQuery: Used for DOM manipulation.
- Bootstrap: For responsive design and UI components.
- Marked.js: For rendering markdown content for the AI agent responses.
- Split.js: For resizable split views in the log viewer (e.g., between the log tables)
- CORS: For handling cross-origin requests.
The API leverages several essential libraries and services:
- FastAPI & Uvicorn: For building and serving the asynchronous REST API.
- pydantic: For request validation and data modeling.
- Elasticsearch: Used for document storage and advanced search capabilities, including vector-based semantic search.
-
Sentence Transformers: The
msmarco-MiniLM-L12-cos-v5model is used (on GPU if available) for generating embeddings from log messages. -
LLM Clients: The system supports multiple LLM backends:
- OpenAI: For GPT-4-based queries (configured via environment variables).
- llama.cpp and granite3.2 instruct models: For offline model deployments (as seen in the commented code sections), allowing flexibility for environments with restricted internet access.
- dotenv: Loads environment variables for configuration.
- Other utilities and helper packages are used for logging, JSON processing, and managing background tasks.
Example API Route
Below is a simplified example of the POST /table/{id} endpoint, which uploads log data
to Elasticsearch and schedules background embedding computation:
@app.post("/table/{id}")
async def upload_file(id: str, request: Request, background_tasks: BackgroundTasks):
data = await request.json()
const_logs = data.get("logs")
if not const_logs or not isinstance(const_logs, list):
raise HTTPException(status_code=400, detail="Expected 'logs' to be a JSON array")
title = data.get("title", str(id))
description = data.get("description", "")
# Push logs to Elasticsearch and schedule embedding computation
response = push_to_elastic_search(const_logs, id, title, description)
background_tasks.add_task(update_embeddings_for_logs, id)
return response
This modular design ensures that our API is robust, scalable, and optimized for real-time log analysis, leveraging both online and offline LLM capabilities.