MotionInput System Architecture
The MotionInput app consists of the frontend, written in C# and the Python backend. In the backend we have the app specific communicator class that uses the MotionInputAPI to control the entire system.In our project we worked on creating the MotionInputAPI that can be used not only by the main MotionInput app, but also by various use case specific apps, with different technologies used in the front end and with different connections.
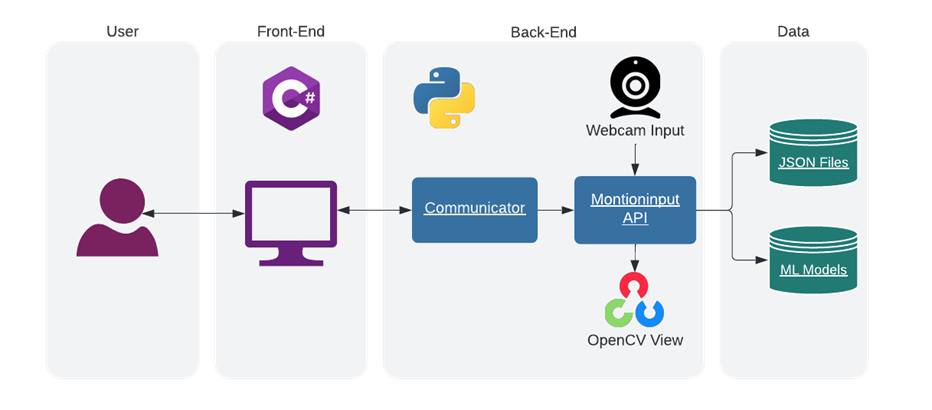
Backend (Code) Architecture
After designing the overall architecture of MotionInput V3, we delved into how we would design the implementation for the backend code.
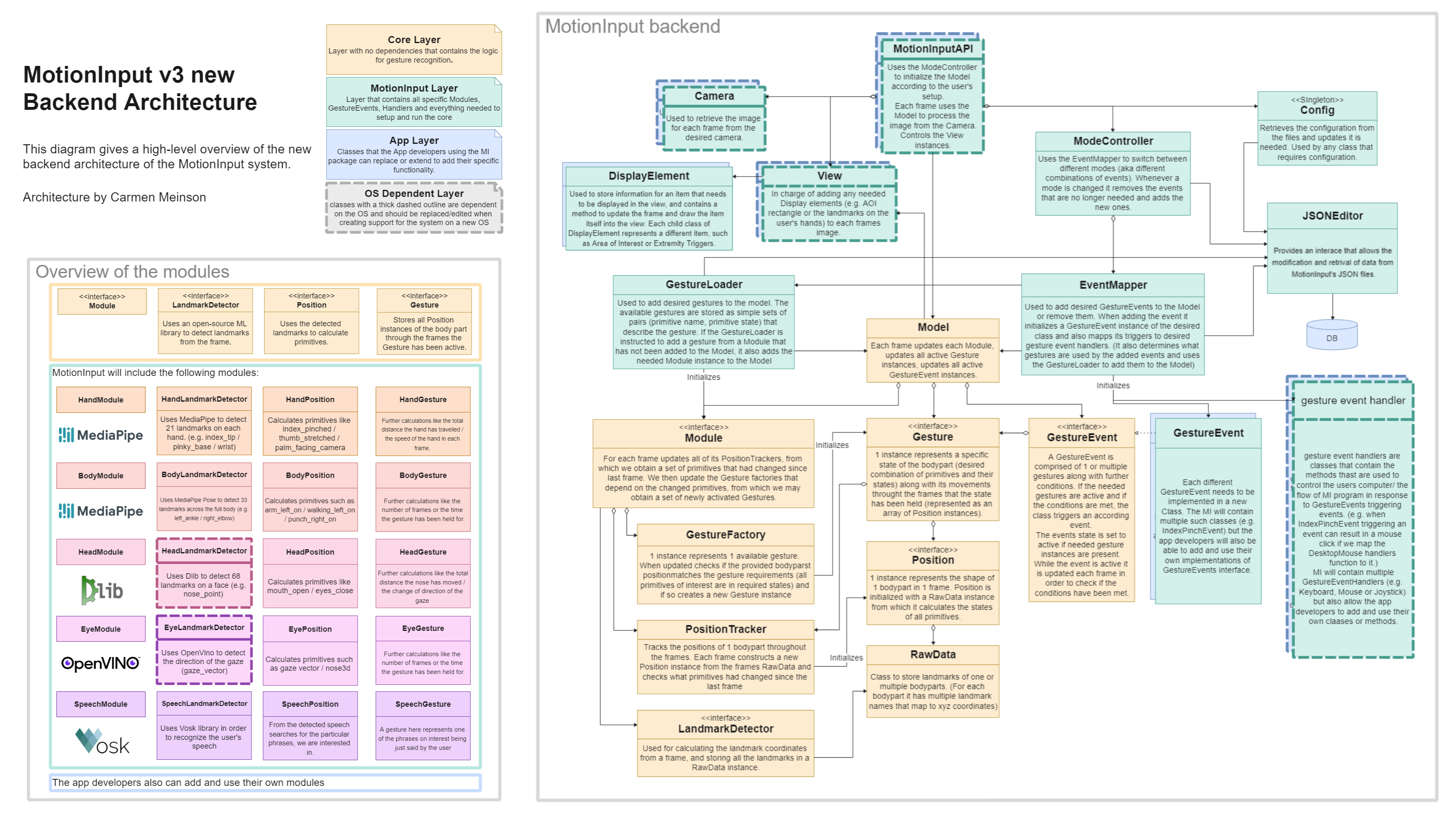
To start off, in order to take the Object-Oriented approach we needed to break down the gestures and the recognition process into smaller parts. We firstly have a Core layer of classes, where we created the ideas of landmarks (contained in RawData class instances), Positions, Gestures and GestureEvents shown in the diagram and expanded on above. Most of these terms were inspired by V2 and have a similar meaning as we wanted to make the migration to the V3 codebase easy for developers who had experience with V2. Those objects and the process of recognising and creating them is what the Core layer was created for. We define the classes outside of the Core layer to be the MotionInput layer, and their implementation allows to initialise the core classes with our desired functionality, or control and support it during the frame-by-frame image processing. These classes can be grouped into 4 types:
-
The gesture event handlersThese are the classes that contain all the logic of interacting with the computer, like moving the mouse or performing the key presses. Hence also why some of them are OS-dependent. The methods of those classes are called whenever the core detects some gestures we are interested in.
-
The classes used for handling the JSON filesThe code contains a JSONEditor class and multiple child classes for simplifying the handling of the JSON files for classes across the system.
-
The classes used to control the functionality of the coreAs the core itself has no hard coded gestures or events, all the desired functionality is loaded into the core by the GestureLoader, EventMapper and ModeController classes from the JSON files.
-
The MotionInputAPI classUsed alongside the View and Camera classes that take care of starting up the system and keeping the MI running frame by frame - retrieving the image from a camera, processing it and displaying it on the OpenCV window.
Now we move on to describing the outline of the classes that we will use to implement our backend architecture. This is split into the Core layer classes, and the Motioniput layer classes.
Core Layer
-
RawData
Firstly let's give a quick definition: Landmark is used to refer to a specific point on a body part like the left knee, the right corner of the mouth or the tip of the pinky finger. A Landmark in the code is a pair consisting of the name of the landmark together with its coordinates. The RawData class is where we store all the data that is produced by the ML models from one camera frame. As we use each ML model (such as MediaPipe Hand/Pose, OpenVino or Dlib) to detect the locations of landmarks on a specific body part, we store this data in the RawData accordingly. The data is split into multiple body parts (such as the head or the right hand), based on the module they were generated by, and then in those body parts, we store all the modules landmarks.
-
Position
A single Position instance is what describes the shape of a single body part in one frame. Every Position instance is generated from the raw data of one body part. From the landmarks in said raw data the Position class calculates all the needed primitives. Primitives are essentially a collection of boolean values that we use to define and detect gestures. Some examples of primitives are “thumb_folded”, “index_pinched”, “smiling” or “punch_left”.
-
Gesture
A Gesture instance represents a specific state of a body part along with the movement of the said body part through the frames the state has been active. The state of the gesture is determined by a combination of primitives. So for example a “peace” HandGesture is defined by the following primitives: {"thumb_folded": true, "index_stretched": true, "middle_stretched": true, "ring_folded": true, "pinky_folded": true }. Thus an instance of a “peace” HandGesture would be created once all the primitives of a HandPosition are in needed states and would contain the HandPosition of every frame while that “peace” gesture is held. This allows us to now have an object that contains all the data about a body part through the time it has been in some specific gesture, so we can not only react to simple gestures being made in one frame but also the path the gesture has travelled and the speed at which it has moved. As previously mentioned, the core does not contain any hard coded gestures - all gestures are loaded in from a JSON file where they are stored in the same format as the “peace” example above. This allows for new gestures to be added or removed without having to recompile any code.
-
LandmarkDetector
Each module's LandmarkDetector is where we use the ML libraries such as MediaPipe, OpenVino or Dlib to analyse a frame and detect our landmarks. Hence, this is the class that populates the RawData for each frame.
-
PositionTracker
A PositionTracker instance is used to track a single body part through all the frames. The trackers are contained in modules, and a single module may have either one or multiple trackers, such as the HandModule having a tracker for both the right and the left hand. Each frame the tracker is given a RawData instance from which it creates a Position instance that describes the state of the specific body part it is tracking. It then compares the created Position to the Position instance from the previous frame and determines all the primitives that have changed since the last frame.
-
GestureFactory
Whilst a Gesture instance represents a single active gesture, the GestureFactory instance represents an available gesture. (In every module we have a factory instance for every gesture we are interested in detecting) The GestureFactories are used to check if a body parts primitives are in the desired states and in case they are the GestureFactory then creates a new Gesture instance representing the newly active gesture. We update a GestureFactory only if one of the primitives its gesture depends on is determined to have changed by the PositionTracker. This ensures that we create the Gesture instance only once - when that gesture is first activated.
-
Module
The modules control the whole process of generating needed Gesture instances from each frame and also hide all this logic from the rest of the system. A module is described by a LandmarkDetector, a Position and a Gesture class. In our system, we have a module corresponding to each ML library we are using.
Module ML Technology HandModule MediaPipe Hands BodyModule MediaPipe Pose HeadModule Dlib EyeModule OpenVino SpeechModule Vosk When designing the frame by frame processing, we realised that unlike in the MI v2, there is no need to check all of the gestures. Instead, we have decided to use the observer design pattern - keeping track of any primitives that change between frames and then checking only those gestures that use said primitives. Each frame the Module updates its PositionTrackers, from which it obtains the set of all primitives that had changed since the last frame. It then updates every GestureFactory that uses any of the changed primitives. As every GestureFactory creates a new Gesture instance if the gesture it contains has just become activated, the Module obtains the set of all the Gesture instances that have been activated by the current frame.
-
GestureEvent
A GestureEvent consists of one or multiple gestures along with possible further conditions (e.g. only one of 2 gestures being active, time held or distance moved since last frame).The GestureEvents are the layer where all the Gesture instances from the core are being used to decide when and what handler functions to trigger (e.g. moving the mouse, pressing a keyboard key or switching to a different mode of interaction). The event classes analyse the Gestures and extract any values we need from them to pass on to the handlers - the gestures themselves however remain in the core and are untouched by the other classes in order to avoid any interference. Whenever any of the gestures used by an event class either activates or deactivates the event is checked to see if it has become active. Whether the event is active or not is up for itself to decide. While the event maintains the active state it is going to be updated every frame. During those updates is where the event checks its conditions (e.g. if the “scroll” gesture has been active for the needed amount of frames) and may trigger a handler function (e.g. function that actually makes the mouse scroll with the speed reflecting the position of the fingers). The GestureEvent classes don't actually contain specific handler methods - the methods are mapped to the events on initialization, based on the events.json file. This allows for configurability as an event that was used to press a key can easily be switched to change the interaction mode by just editing a JSON file and without having to recompile any code. By creating new classes of the GestureEvent interface is where the developers have the most power to create new functionality in the MotionInput system.
-
Model
Model is the class that we use to abstract all the gesture detection and event triggering logic from the rest of the system. Whenever the MI backend is started or whenever the mode of interaction is changed, the needed modules, gestures, and events are loaded into the model. Afterwards, for each frame we pass the image into the model, process it, get all the newly activated Gestures, update all active GestureEvents, where we trigger all the necessary handler methods, thus delegating the responding to the events to the outer layer. For the frame processing we leverage the real-time nature of MI and the fact that between most pairs of consecutive frames, the gestures do not actually change. Whenever a Gesture is created by the Modules or deactivated we update only the GestureEvents that use said gestures.
MotionInput Layer
-
JSON Editors
JSONEditor and its child classes are used to abstract all the JSON file handling from the rest of the system. They provide an interface to add, modify and delete entries in the JSON files.
-
Config (Singleton)
To avoid either passing all the configuration as arguments (as widely done in v2) to the classes or rereading the file each time we want to get a setting, we created the Config singleton. It allows any class through the code (e.g. HandPosition, Camera, or handlers) to easily access the configurations, which are retrieved from the file only upon the first use.
-
GestureLoader
The GestureLoader is used to add the needed gestures and modules to the model. For this the GestureLoader simply needs the set of the desired gesture names. The GestureEditor (child class of the JSONEditor) is then used to get the set of primitives for each desired gesture along with the gestures module. The gesture is then added to the model and if the gesture belongs to a module that has not been previously added, the GestureLoader also adds the appropriate Module child class. Note that there is no need for the GestureLoader to remove gestures as this is done by the model automatically whenever the gesture is not used by any GestureEvents.
-
EventMapper
EventMapper is used to add or remove any events to or from the model. Then adding events, it initialises the GestureEvents, maps their triggers to handler methods and afterwards adds the events to the model. Whenever a GestureEvent is added, the event is queried for the names of all the gestures it uses, and then the GestureLoader is used to add those gestures to the model. To add or remove any events using the EventMapper simply the names of the events need to be provided - the specifics of the event will be retrieved from the JSON file using the EventEditor class (child class of the JSONEditor).
-
ModeController
The ModeControler is used to switch between the modes of interaction, thus switching the sets of events in the model. The events that make up each mode are retrieved from JSON using the ModeEditor (child class of the JSONEditor).
-
DisplayElement
DisplayElement is a class that allows for the storing of attributes relating to a particular item/graphic that needs to be displayed in the view, as well as a method that actually updates the view to display the graphic using the information stored by the DisplayElement’s attributes. These attributes can be updated by parameters that are passed from a gesture event handler. The graphic is drawn to the view by taking an image object (the frame), and updating it by drawing to the cv2 image. DisplayElement itself is a parent class, with child classes having different attributes to keep track of, and its own implementation of how to update the attributes and what to draw onto the view.
-
View
In V2 each module and event handled its own graphics and added them while processing the frame. We however decided to remove that from the model and combine all of that into the View and the DisplayElement classes. The View class is used to handle the window that displays the live web camera image and all the graphics that need to be added to it. (e.g. the extremity triggers or the area of interest). Items/Graphics are drawn to the view via the use of DisplayElement classes. Since DisplayElements contain attributes that determine what is to be displayed, it needs a way for these attributes to be updated, which is done via information being passed from a gesture event handler. A gesture event handler will have a reference to the view, and the view will allow information that needs to be sent to a particular display element to be passed through the view, and the view will call the corresponding DisplayElement instance, and update its attributes using what was passed from the gesture event handler. With every frame passed to the view, the view will call each DisplayElement and pass the frame, allowing each DisplayElement to take the image and draw what it needs to into the view, which is then displayed.
-
Camera
The Camera class is used to read the image from the camera each frame.
-
MotionInputAPI
The MotionInputAPI class serves as a facade for the entire system, combining all the methods that the app built on the backend needs into one class. It is meant to be used by the Communicator and thus the GUI and ensures that the front end does not use any classes or methods that it is not supposed to - thus ensures that MotionInput backend functions as intended.
Capabilities:
- Methods for starting or stopping the MotionInput processing.
- Methods to access the JSON editors to configure the functionality.
- Methods to hide or show the view window. If the view is hidden before the MotionInput is started, then upon running the MI the view window never appears.
Capabilities: Only before running MotionInput:
- Methods to pre-initialize modules - thus initialising the modules ML models before the MI is run. Thus allowing for the most time consuming part of starting the system, to be done while the user is still interacting with the GUI and setup.
- Methods to calibrate modules. We allow for the modules to be calibrated from the GUI before running the system as this removes the need to calibrate them each time over when the mode is started (as was done in v2 head module) and also allows the modules to assume that whenever the system is running everything is calibrated.
Capabilities: Only while running MotionInput:
- Method to change the mode of interaction.
Design Goals
Our main consideration for developing our new system architectures and design were the following improvements:
Efficiency
The MI system was optimised and thus the frame rate improved in the following ways:
- New frame by frame processing logic that uses the Observer design pattern.
- Used multithreading for reading the Camera on a separate thread and thus removing the bottleneck between the processing of frames.
- Used multithreading to optimise the use of multiple modules simultaneously.
Extendability and Modularity
The system will be developer friendly for them to extend the functionality of MotionInput with ease:
- New GestureEvents can be easily added by just creating a new class in the gesture_event directory. The GestureEvents do not interfere with each other.
- Used multithreading for reading the Camera on a separate thread and thus removing the bottleneck between the processing of frames.
- All the functionality of interacting with the computer is contained in the handler classes (in the gesture_event_handlers directory) and thus adapting the MI to work on a different OS, would only require changing some of the handlers and possibly then the other classes that are marked in the diagram as OS-dependant (Camera, View).
Single Responsibility Principle
- We split the motion detection process into the following classes - GestureEvent, Gesture, Position and RawData - so that each class would be used for one step in the gesture detection process. This also allowed us to provide a clear interface for the GestureEvent classes to use - gestures that are composed of positions that contain the primitives and the landmarks.
- There is a clear cut between the core and the handlers. This removes any OS dependency from the core and also allows us to contain all the interaction with the system in one directory thus making it easier to edit.
- We extracted all the view code from the modules and gesture detection (as it was there in v2) to better follow the MVC design.
Abstraction
- Through the ModeController, the EventMapper and GestureLoader classes provide that abstraction for adding all the GestureEvents, Gestures and Modules to the Model - only the names of the events in the events.json are required and the EventMapper and GestureLoader will automatically initialise and add everything that is needed into the Model.
- There is a clear split in modules when it comes to image processing and detecting gestures but once the Gestures are created they can be used almost interchangeably by the GestureEvents - removing the separation of modules.
- The MotionInputAPI class serves as the abstraction for the whole backend to be used by the front end.
Configurability
- The system's functionality is highly configurable through the JSON files. No gestures or events are hardcoded into the system making it easy to edit functionality beyond just pre-set use cases.
Consistency
- We widely used abstract classes and interfaces in order to maintain the consistency despite the vast number of developers working on this iteration and to also to keep that same consistency for future iterations.



