MotionInput V2
MotionInput v2 was a final-year MSc Computer Science industry project completed in the summer of 2021. They were tasked with redeveloping and expanding on the functionality of MotionInput v1, creating 4 modules of interaction: hand, eye, head and full body gesturing. At the end of the project, they produced a fully functional, compiled proof-of-concept demonstrating their hard work and development. In order to ensure that our development of MotionInput v3 is a vastly improved version over the last generation, it was crucial that we studied the old version’s implementation as in-depth as possible. We focused on finding the criticisms and areas of improvement, and created potential solutions for any problems found to form our final requirements, ensuring that MotionInput v3 would be better in the most crucial areas, and to set a high standard for any future development onwards with MotionInput.
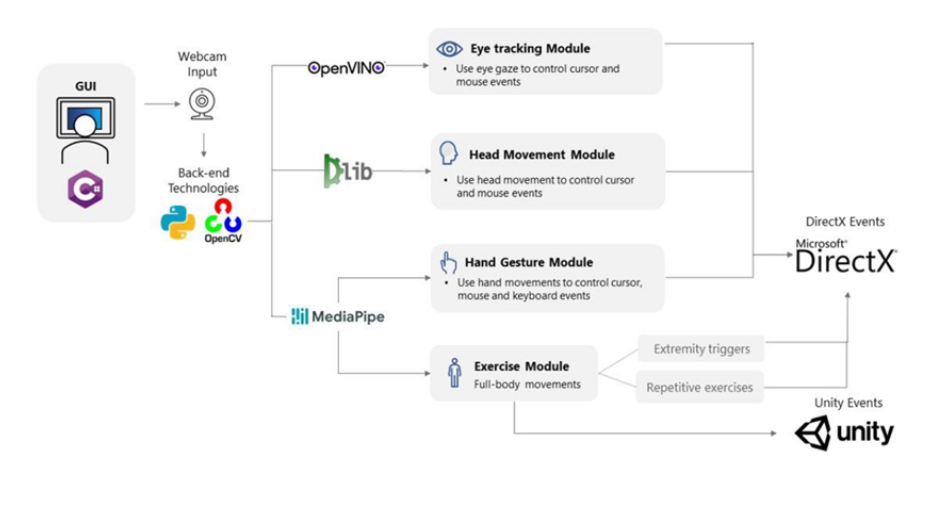
The 2 main sources of information for MotionInput v2 was the development source code repository, allowing us to directly see the implementation of everything underneath, and also the MSc Computer Science dissertation papers of the final year students that authored MotionInput v2, which should compliment the code that each student wrote. Firstly, each student’s project was wholly about implementing a particular functionality for MotionInput. For example, one dissertation is titled “Exercises Module with Extremity Triggers and Repetitious Exercises using Computer Vision” [2], whilst another is titled “Webcam-based Hand Gestures to Control Existing User Interfaces and Its Value in a Clinical Environment” [3]. Since each student mainly focused on their work for their dissertation, they would code only for their own functionality. This resulted in very different coding styles and file structure found in the base code.
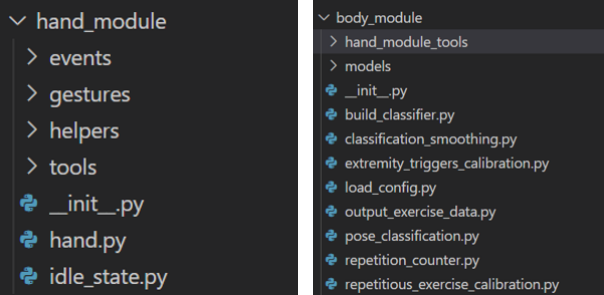
As shown above, we can compare the file structures for the hand module and the body module, both worked on by different students. The concept of an ‘event’ class and ‘gesture’ class is defined in the hand module, but not in the body module or in any other module. The lack of consistency makes it very difficult for a developer to extend functionality for one module and then attempt to extend functionality for another because they are so different in implementation. Likewise, each of the final year students came from undergraduate disciplines that were not Computer science-oriented, and as a result had little coding experience prior to starting the MSc Computer Science course. They only had about 2 months of coding training before starting the project. As a result, the code quality is further affected by the lack of experience and familiarity with high quality coding conventions and methods. Examples include inconsistent variable and method naming:
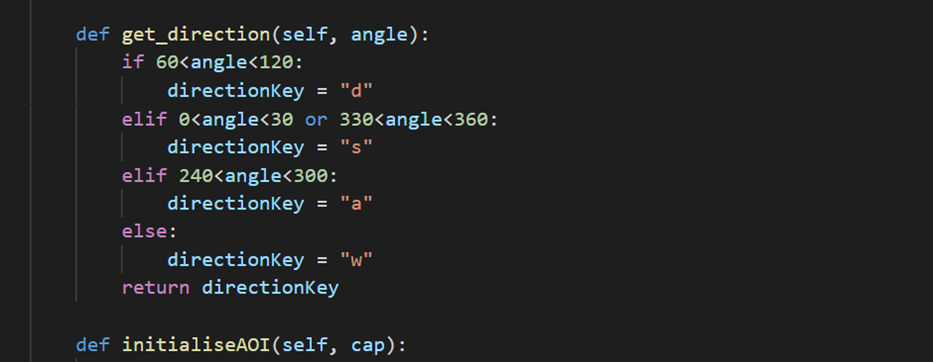
get_direction is in snake case, but another method name,
initaliseAOI is in camel caseThe architecture of MotionInput v2 is also limited in that it did not allow for the use multiple modules at once. For example, you cannot exactly select “Hand Gesturing” with “Full Body Gestures”.

Strangely, however, there is a mode within “Full Body Gestures” that has full body tracking with some hand gestures allowing for controlling the cursor with the hand. However, instead of the code allowing for part of the hand module being activated alongside the body module, instead code from the Hands module is just copied over to the Body module’s file structure. This is an unnecessary repetition of code, breaking the DRY rule (Don’t Repeat Yourself).
Coded methods and classes are generally not cohesive and verbose, with some main classes having a huge number of input arguments, making them very hard to decipher.
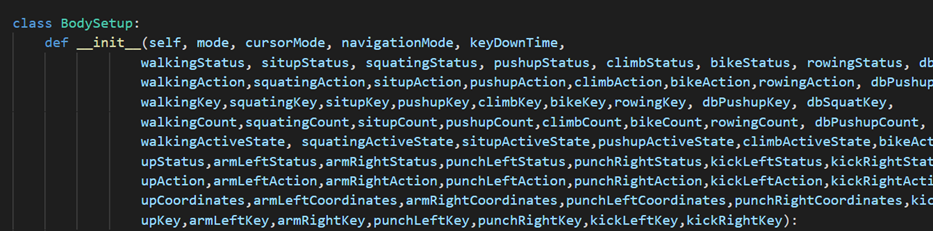
__init__ signature with a large number of arguments
Likewise, for all of the modules, the main body of code is located in each module’s __init__.py file, which is not the intended purpose
of __init__ files and since the files are extremely long, they are difficult to understand. For example, the __init__
file for the head module consists of one class, but the class in total is over 1000 lines long, with a method to process a
frame that is over 800 lines long

It is also mentioned in some dissertations that the Model-View-Controller (MVC) pattern is used in some areas of the codebase [3]. However, this is a misinterpretation of the design pattern as the software as a whole should use the MVC pattern rather than selectively. We can also see the attempts to use MVC are also not entirely correct. There is no model, view, or controller classes or files explicitly defined in the codebase, and there are many times where actions that should be performed separately by a model, view or controller are combined in a single class or method. An example of this is in the processFrame method for a module, which acts as all 3. It receives an image (model), validates and processes it (controller), and draws to the screen (View). There are also a lot of “magic numbers”, or hard coded values that are repeated multiple times in a method.

0.5) rather than variables or attributesWhilst sometimes it is necessary to have hard coded values, the example above may be a value that a developer may want to configure and change, rather than leave as is. If they wanted to change the value, they would need to manually go through code and change each occurrence every time. There is no centralised storage or file containing configurable parameters such as this one. Finally, With regards to documentation, there is a severe lack of it, with the only documentation for developers being a compilation guide, and some system manuals that are placed in some of the MSc dissertation papers’ appendices [3]. This documentation is not very detailed, mainly outlining a few areas of code rather than extensively going through each file and classes. Since they are all found in different places, it is also difficult to keep them all organised. This means that the documentation for V2 doesn’t compliment the code well, and does not help with maintainability or future developers to get up to speed with understanding the codebase.
ML Technologies
MotionInput, as webcam-based system, requires a number of Computer Vision Machine Learning solutions to work. Currently, MotionInput V2 uses a number of open-source gesture recognition technologies [1], and their decisions for each solution has been thoroughly discussed in a number of literature reviews, for where we primarily conducted our research into why we are continuing MotionInput V3 with the selected technologies.
MediaPipe Hands
For detecting hand gestures MotionInput utilises MediaPipe Hands, which an ML model that is capable of detecting 21 3D landmarks on one or multiple hands from just a single frame. The decision to use Google’s MediaPipe in MotionInput was made by the developers of previous versions and was determined to be a suitable choice for a few reasons. Firstly, as hand detection is rather complex, instead MediaPipe uses palm detection, and only after hand landmark detection to pinpoint precise landmarks around the palm. This provides not only great efficiency but also precision benefit, which is critical for smooth real-time hand gesture control [4]. Secondly, as after detecting the palm location the same location can often be used in the subsequent frames, we achieve even better frame-by-frame performance as for most of the frames MediaPipe runs only the landmark detection. Lastly, MediaPipe is open-source and its licence allows for free research and commercial use. [3]
MediaPipe Pose
For detecting full body movement, and in particular for the classifying of repetitive exercises, MotionInput utilises MediaPipe Pose. MediaPipe Pose provides us with a Pose Landmark ML Model that features 33 3D coordinates across the body, whose locations can be detected and then the body’s “pose” can be estimated. We can then classify the pose created by the landmarks against a k-NN algorithm that is trained by custom sample sets of exercise poses stored in .csv files [5]. Similar to MediaPipe Hands, MediaPipe Pose was chosen as the solution for full body detection by the previous developers. Originally there were 2 possible choices for full body detection, which were MediaPipe Pose or MediaPipe Holistic. Since Pose’s landmarks are spread across the body, it only provided 4 landmarks for the hand, reducing the accuracy of hand detection, in the case that full body + hand functionality would be required. Conversely, MediaPipe Holistic would provide the 21 landmark from MediaPipe Hands, alongside the 33 landmarks from Pose, as well as 468 landmarks from MediaPipe Face Mesh (for face detection), which in total means that 543 3D landmarks would be detected simultaneously. Whilst this would provide highly accurate tracking, the developers discovered that not only were the face landmarks redundant, but this significantly increased the latency of landmark detection and classification [2]. Since they also concluded that hand motion did not make much difference in classifying a full body pose, MediaPipe Pose was still the correct solution to use.
Dlib Library
For detecting head gestures, MotionInput makes use of Dlib library, in order to estimate facial landmarks in each frame. Dlib is trained to recognise 68 landmarks on a face, as shown in the image [6]. Each of the landmarks are represented as (x, y) coordinates. The decision to choose Dlib over other libraries with similar purposes, such as OpenCV and MediaPipe, was made by the previous developers of the project. Dlib was preferred over OpevCV due to its list of pre-trained detectors for both faces and landmarks. Multi-Task Cascaded Convolutional Networks (MTCNN), a framework for face detection and alignment was also not considered for MotionInput because of its lower precision, outputting only 5 landmarks, instead of 68. On the other hand, Google’s MediaPipe Face Mesh was avoided for using 468 face landmarks, causing lower processing speed, but also making it more difficult to process a large number of coordinates in order to obtain recognition of the facial gestures [7]. Similar to the decision for MediaPipe Pose for full body detection, Face Mesh therefore has a number of redundant landmarks (hands and full body) if we only need to consider the face with high accuracy.
Solution Decisions
For our analysis of the MotionInput V2 codebase, it’s clear that MotionInput V3 needs to consist of a new system architecture which allows for a high level of configurability and extendability. Configurability could come from a way of storing alterable parameters in a file system (e.g. JSON) that allows developers to easily edit and add them without having to manipulate any source code manually. To promote extendibility, we need to ensure that the codebase is consistent. This perhaps could mean making extensive use of class templates, such as gesture classes, event classes that start off the same, but can then be adapted for each module. This would allow for more functionality to be created and added in the same manner for developers. On top of this, we could also generalise modules as a template. This simplifies development for those that want to add functionality to multiple existing modules, allow for multiple modules to be used at once, and even allow developers to create and add their own modules. We should ensure that our architecture also properly follows design patterns. In particular to the MVC pattern, we should ensure the separation of logic and processing, data controlling and displaying to separate classes to maintain the pattern. The code written also needs to be clean and make use of good programming practices such as short, cohesive functions, avoid repetition, and be consistent and highly readable with the addition of docstrings and comments. This ensures that developers reduce the time it takes to understand existing code, so that they can develop on top of the codebase quickly and with ease, as well as keeping the existing code maintainable. We need to also make sure that we have extensive documentation that compliments the codebase, thoroughly explaining the use of every class and method and its technical aspects (parameters, return values, types etc), as well as other parts of the development cycle like compilation. This also includes well produced architecture diagrams to back up any written documentation. The documentation should all be in one place, preferably a website allowing for easy and structured access to any piece of information required. In terms of technical decisions, we will retain the Machine Learning technologies used in MotionInput V2, as they were determined to be the best suited solutions for their respective functionalities in a number of literature reviews performed by the students. This means using MediaPipe Hands for hand gesturing, MediaPipe Pose for full body interaction, and DLib for facial recognition.
References
- [1] University College London (UCL), "MotionInput v2.0 supporting DirectX: A modular library of open-source gesture-based machine learning and computer vision methods for interacting and controlling existing software with a webcam." [online], 2021. Available:
- [2] Q. Lu, "Exercises Module with Extremity Triggers and Repetitious Exercises using Computer Vision.", 2021.
- [3] A. Kummen, "Webcam-based Hand Gestures to Control Existing User Interfaces and Its Value in a Clinical Environment", 2021.
- [4] "Hands", mediapipe, 2022. [Online]. Available: https://google.github.io/mediapipe/solutions/hands.html. [Accessed: 27- Mar- 2022].
- [5] "Pose Classification", mediapipe, 2022. [Online]. Available: https://google.github.io/mediapipe/solutions/pose_classification.html#overview. [Accessed: 27- Mar- 2022].
- [6] A. Rosebrock, "Facial landmarks with dlib, OpenCV, and Python - PyImageSearch" [online], PyImageSearch, 2021. Available: https://pyimagesearch.com/2017/04/03/facial-landmarks-dlib-opencv-python/ [Accessed 27- Mar- 2022].
- [7] T. Ganeva, "Head tracking and facial expressions features for Music creation and direction software enabling virtual instrument playing for accessibility", 2021.



