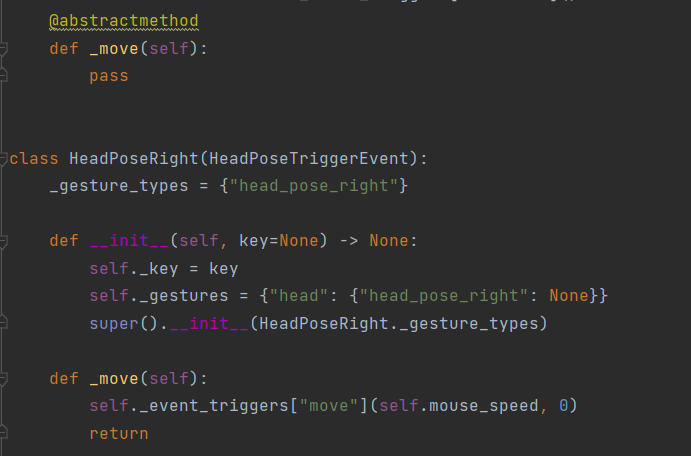
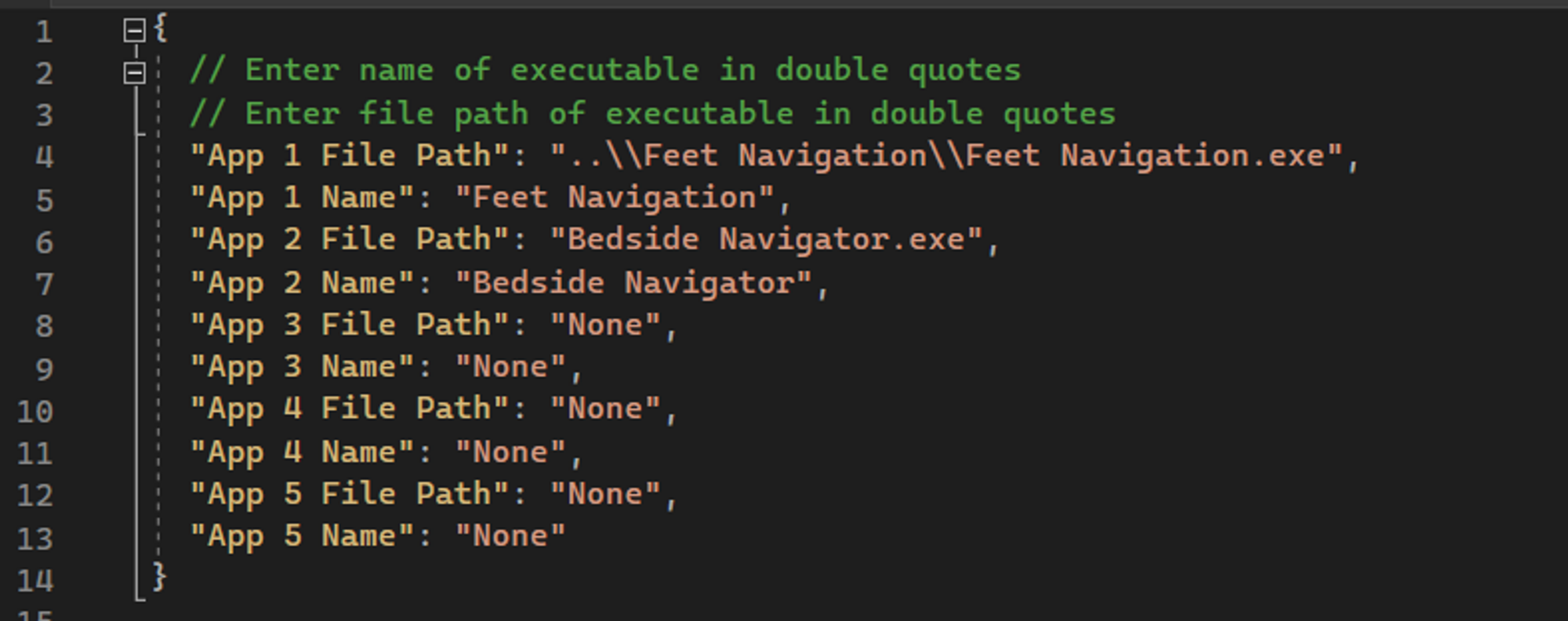
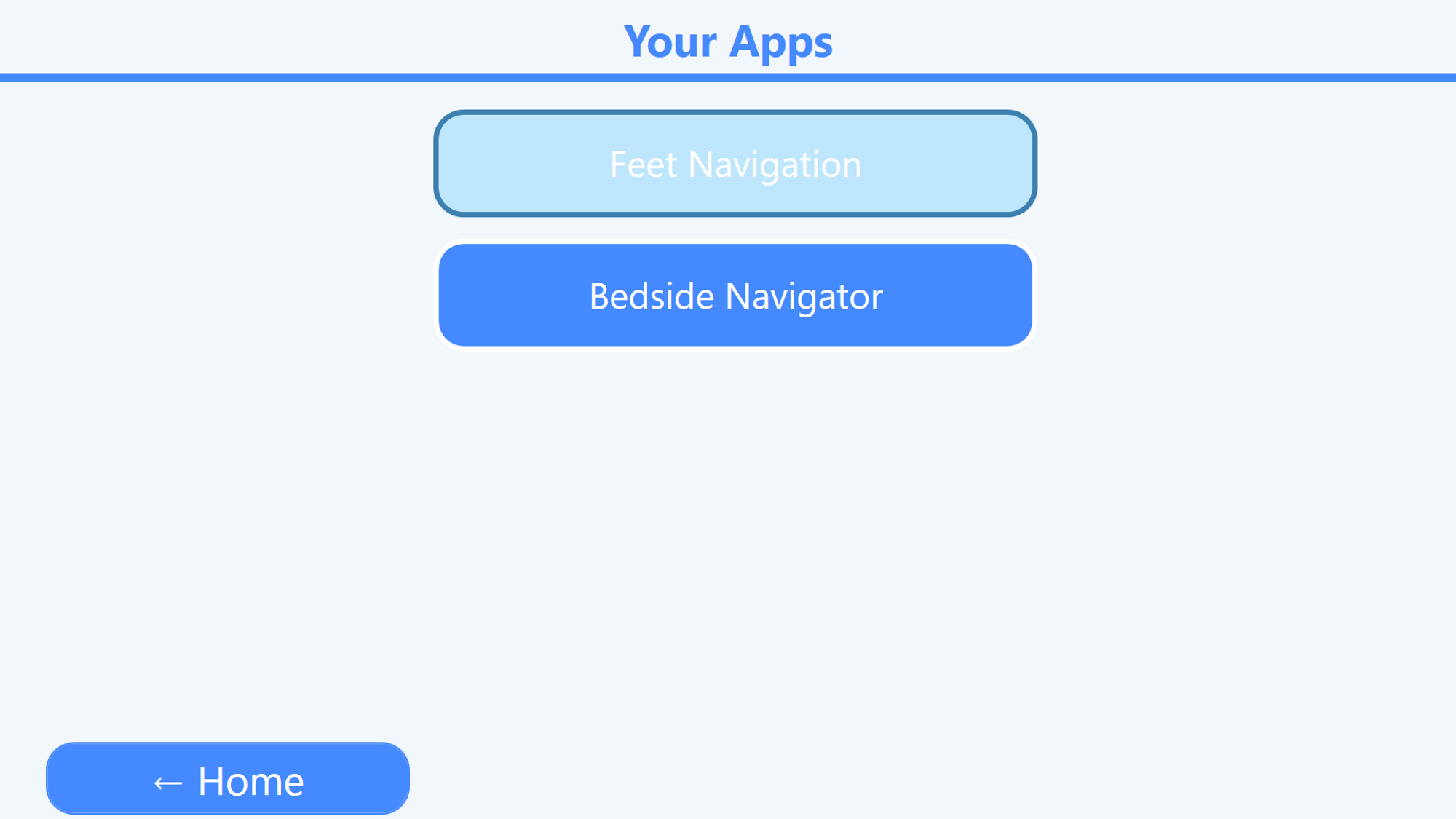
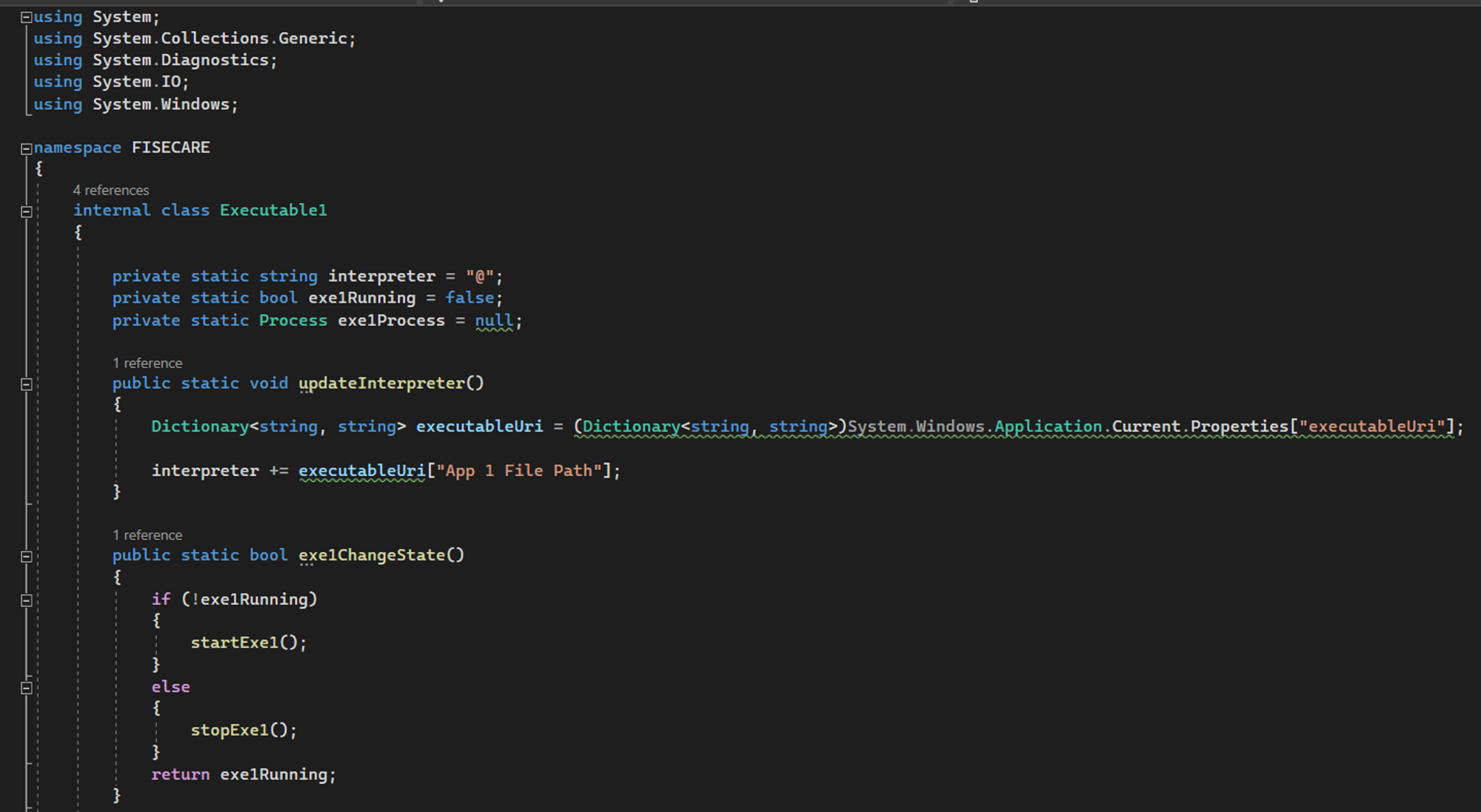
This section introduces a unique addition to the MotionInput architecture in the form of hand and head modes. This documentation outlines the core workflow for the navigation modes, as well as a detailed breakdown of the purpose and functionality of each component.
- bedside_nav_right_touch: navigate using the right hand at an angle, with hand gestures and speech commands.
- bedside_nav_left_touch: navigate using the left hand at an angle, with hand gestures and speech commands.
- bedside_nav_face_speech: navigate using nose tracking and use speech commands for interaction with the system.
- bedside_nav_face_gestures: navigate using nose tracking and use facial gestures for interaction with the system.
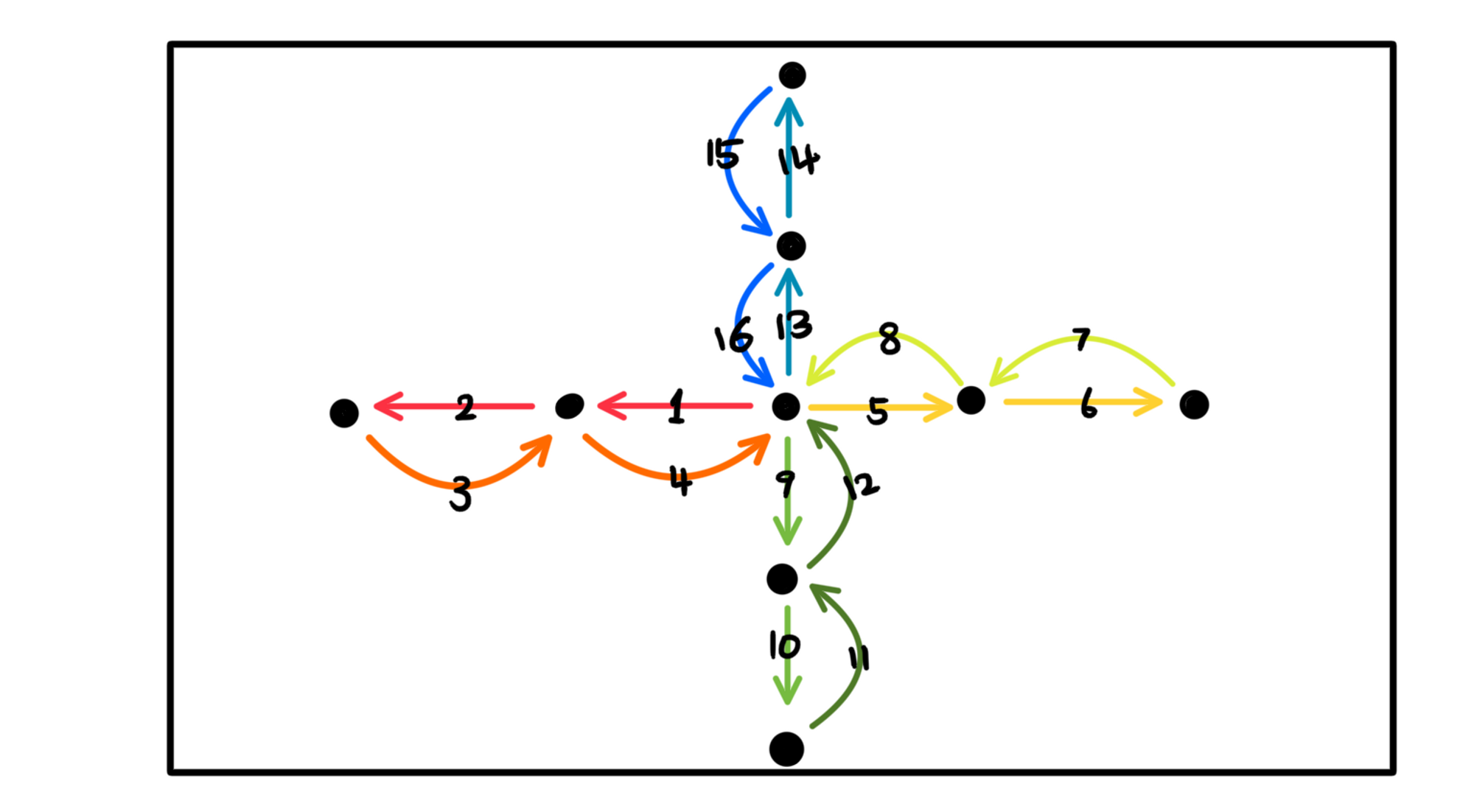
- bedside_nav_face_joystick_cursor_speech: navigate the cursor with head pose like a 4-way joystick, and interact with the system with speech commands.
- bedside_nav_face_joystick_cursor_gesture: navigate the cursor with head pose like a 4-way joystick, and interact with the system with facial gestures.
In mode_controller.json, all our navigation modes can be found, including: