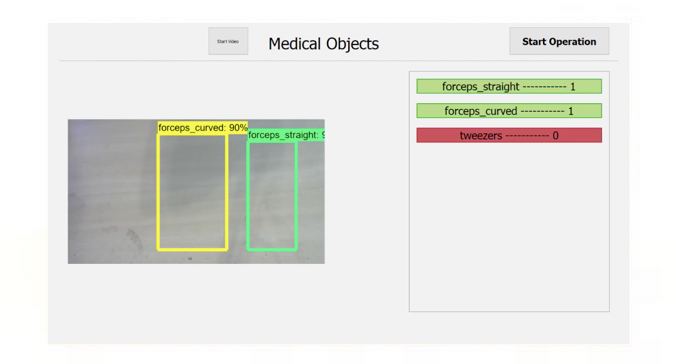
summary of ACHIEVEMENTS
Achievements Table
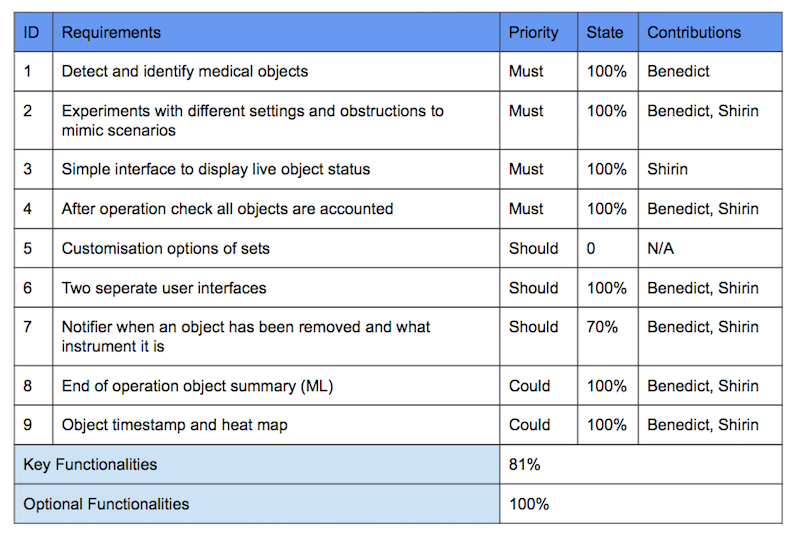
Known Bugs

Individual Contribution Table
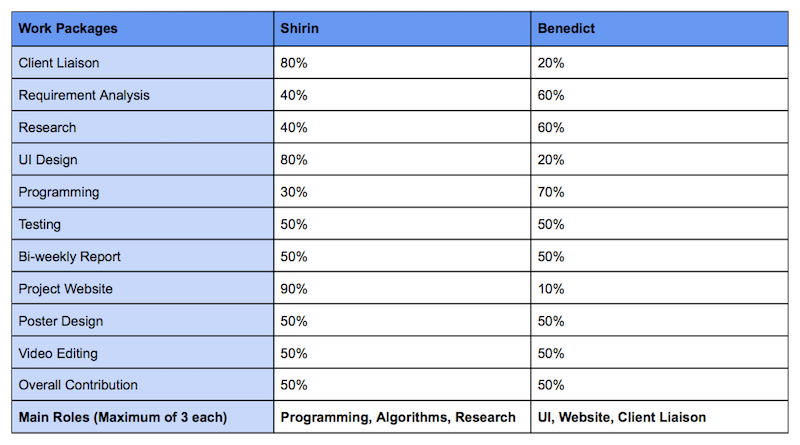
critical evaluation of project
The interface was created with simplicity in mind as the system was being used in stressful locations where complexity would not be beneficial. For this reason we focused on convenience and naturalness of interaction.
As the user interface is an integral part of the system we wanted to make sure it looked as clear and simple which is why we started off by trying to write the interface in AngularJS and Electron. While this gave us an intuitive and elegant interface processing with the python backend became difficult and time consuming slowing down the speed of the system. For this reason we decided on using PyQt5 instead as there would no longer be a need for communicating between the back and front end using JavaScript as everything was written in Python itself.
Our main source of input regarding the user interface came from user testing which was done in two rounds in order to find improvements that needed to be made. Getting these external views helped the team decided to update the user interface completely in order to make it more intuitive and elegant.
The difference between the interfaces can be see below:
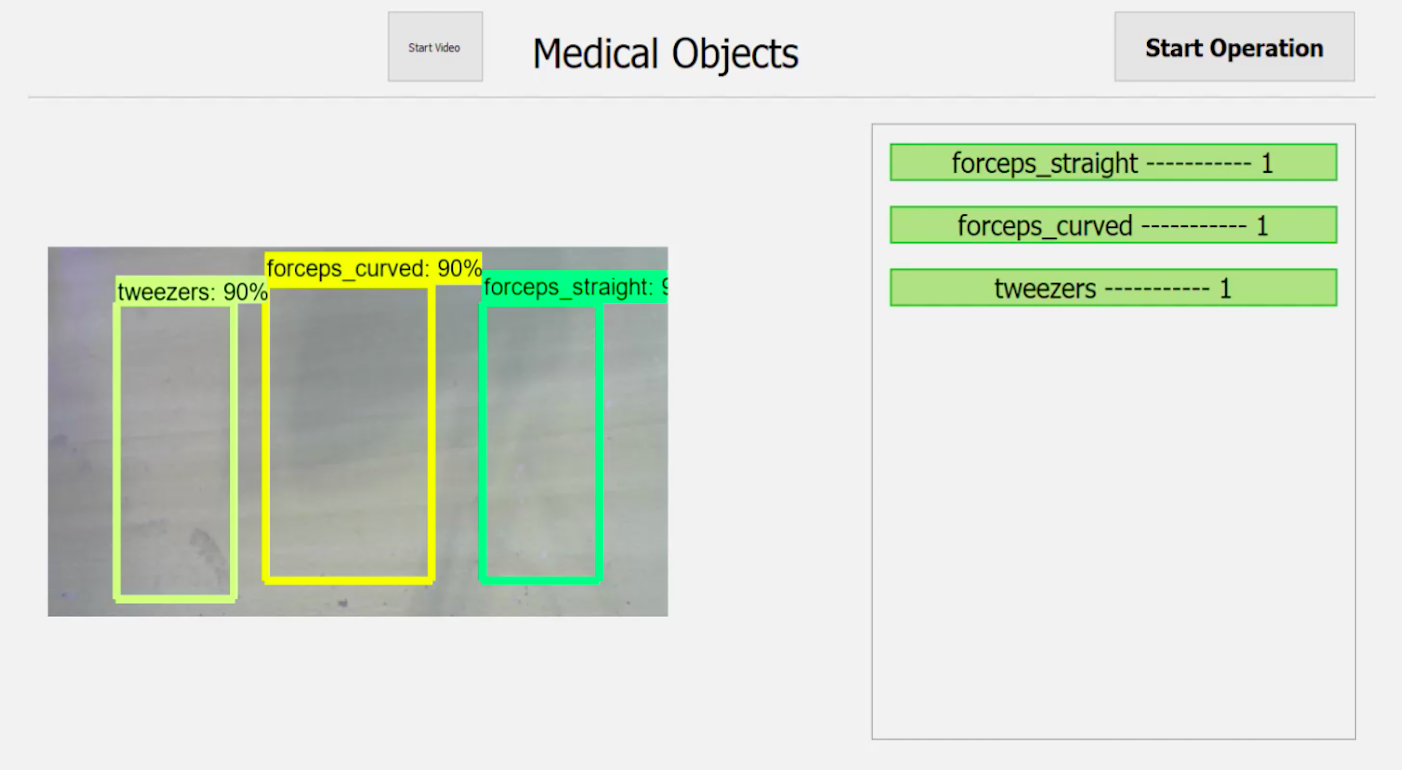
Old Interface
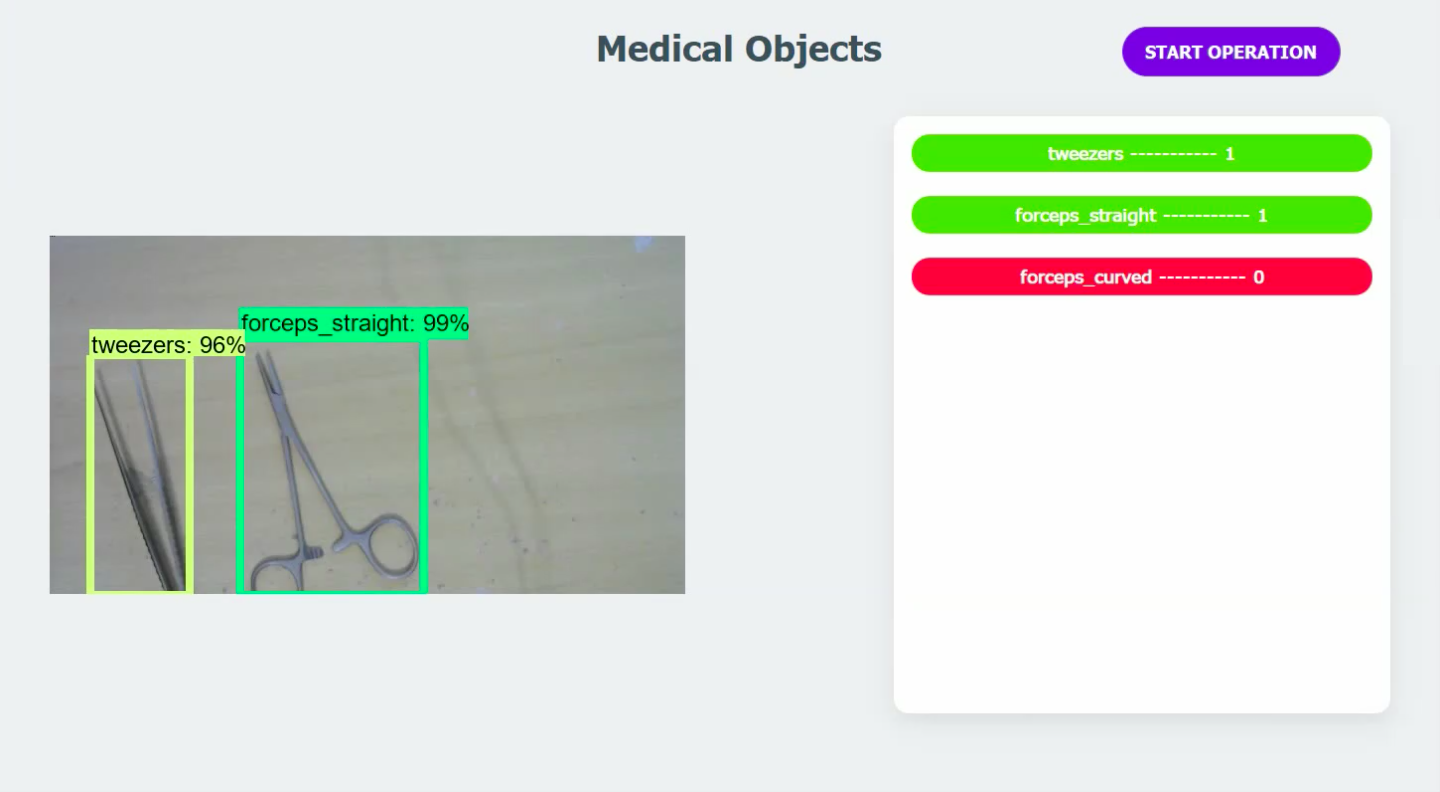
New Interface
As you can see from our requirements, the application we set out to create has a wide range of functionality. As you can see have implemented the functionality we thought was feasible in the timeframe of the project and some after the research phase. We decided not to implement the customisable sets feature. This is because our model would not be extensive enough for us to create sets of instruments for different types of operations. The client also suggested, sets which were tailored to the user depending on their past operations which added another level of ML complexity. We did however, implement all the statistics functions that were in our project plan.
After creating our application, we had to test how it performed so we could constantly improve on it. The main brunt of the work in our project project involves running inference on the images from the input. Therefore to increase the stability of the application, we moved that process to a web API which the application interacts with. This web API can then be scaled up or down to accommodate the number of client applications running at the same time.
To increase the efficiency of our application, we seperated the application into different concurrent processes and ran them on different threads. By doing so we increased the speed of the application. However, as the Python interpreter only runs on 1 thread, this means the multithreading is just context switching. Therefore if we made our application in a different language such as Java or C++ it would be much faster. At the moment, the limiting factors in the speed of our application is the ‘multithreading’ and the speed of communication to the web API. In the future works section we discuss how we could improve this. At the moment, the inference on the images take about 0.25 seconds for each image, limiting our application to 4 frames per second on the current model.
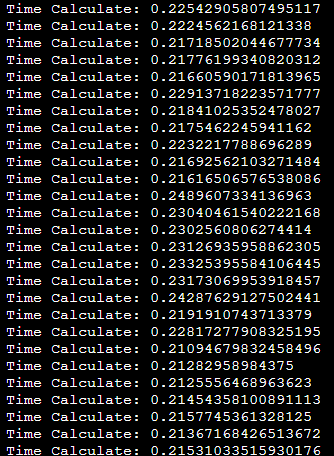
Time for Inference
When designing the application we kept the maintainability of it in mind. We separated the application into different objects allowing the logic to be seperated and therefore taken out and put into another application. We also wanted our application to be compatible with any type of database so we created an adapter. This allows the database connection to be modified without changing the main core code of the application.
As our team only consisted of 2 people, the management was very simple. We set weekly tasks for each member with some being optional/from the week after allowing for flexibility while keeping our project delivery on time. We also set specific deadlines for larger sections using Trello, with contingency time in between to allow for unexpected errors or underestimation of time.
future work
Having only been given around 6 months for our project, the end product is still very much a proof of concept and could be improved much further. If we were given 6 more months we would continue to improve by trying out different detection models, adding more instruments and testing them thoroughly. This would allow us to improve our system by finding a better and stronger model and a better conclusion in creating your own. We could also create a notification system so that a notification is shown every time a instrument is added or removed from the tray. We can also improve the system by adding more statistics options. By talking to medical professionals that would use the system we would be able to see what other statistics would be beneficial to them.
The main thing we would work on given more time would be to increase the efficiency of our application. At the moment, the web API is a singular synchronous websocket application that can handle multiple connections. In the following months we would modify the web API into a Flask-websockets application. By doing so we could run the web API using Gunicorn and Nginx which acts as a load balancer and means it can run and automatically restarts multiple workers for our API. This makes our system much more scalable as the number of clients increase. On the client application side, we could also have multiple connections to the web API, allowing for multiple images to be processed at a time instead of processing 1 frame at a time however, this would make the application more strenuous on the system.
If we could do the project again, and with unlimited resources there are still a few changes we would make. Even if we did the above modifications to the application, it would still be limited by the fact the Python interpreter runs on 1 thread. Therefore, I would have prefered to write the client application in a different language that supports actual multithreading such as Java or C++.
Another important functionality we would hope to add is having the option of custom sets. Custom sets given the system a specific set of tools that must be used during the operation and accounted for afterwards which would be helpful for operation technicians as they would know what instruments would be needed and at what time.
The last change we would make would be to the training of the model used in our project. Due to limited resources, we only trained the model using 1 instrument for each category. This meant that it could not distinguish the same categories for other instruments which were not used for training. Ideally, the model would be trained on a wide variety of different models of the the same instrument. This would allowing for the model to detect any set of instruments used in operations around the world.