
Come See Us @ UCL
University College London (UCL)Gower Street, London
Using a computer instead of a trained specialist in the medical sector could potentially be life-threatening for patients. That is why this technology is only a helping hand for medical staff. Yet, the advantages are undeniable and include an increase in quality, accuracy, and predictability. Saving diagnosis time and early detection of certain diseases are also important, alongside the reduction of costs. While diagnosis relying on human experience can vary greatly, the accuracy provided by algorithms is superior and easily replicable over similar data sets. Cameras and GPUs are never tired and if the underlying model is executed correctly, they can pick-up details which are easily missed by the naked eye. [1]
Although there are no systems currently designed that a have the same functionalities as our project, using computer vision in medicine has fast become a topic of interest for many. Keeping this in mind, we decided to look into the different uses of computer vision in the industry.
Computer vision techniques have shown great application in surgery and therapy of some diseases. Recently, three-dimensional (3D) modelling and rapid prototyping technologies have driven the development of medical imaging modalities, such as CT and MRI. Medical professionals in Iceland are currently trying to combine CT and MRI images with DTI tractography and use image segmentation protocols to 3D model the skull base, tumour, and five eloquent fibre tracts which provide a great potential therapy approach for advanced neurosurgical preparation. [2]
Another way of using computer vision in Medicine is to perform the analysis, visualization, and optimization of surgical workflows by formally describing the surgical activities in the OR. An example of this is to understand and optimize the usage of imaging modalities during a neurological procedure. This model has been shown to be useful for preoperative planning. In a more recent work, a model is proposed of the surgical process for different kinds of laparoscopic procedures such as and pancreatic resection. [3]
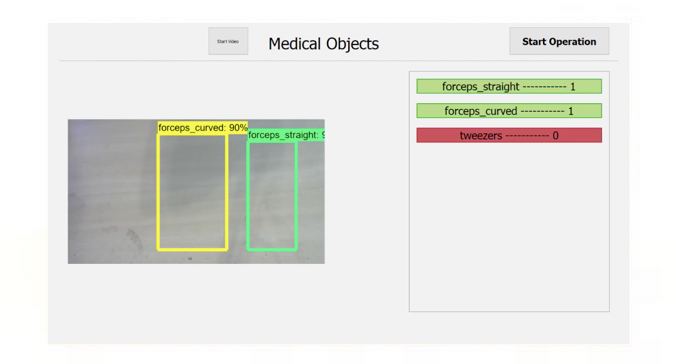
For our project we needed a way to detect objects from a video feed. Two immediate solutions which popped up were object detection and object tracking: OpenCV object tracking [4] and Google’s TensorFlow object detection API. The main difference between the 2 are the way in which they track objects in a video stream.
Object tracking uses tracking algorithms alongside object detection to predict the path of objects. This means that it is faster than detection as you are tracking an object from the previous frame. Therefore, in the next frame you can predict the location of the object using information such as speed and trajectory from the previous frame. It also means that if objects get obscured, the tracker will still be able to detect the object where an object detection system may fail to identify the object.
Object detection APIs on the other hand uses a series of detections on images to locate each object and therefore ‘track’ them frame by frame.
In the end we decided on using object detection algorithms. This is because although it may be slower, most of the objects will be remaining stationary so the tracking algorithms won’t help much. Furthermore, a lot of the objects will look quite similar, so we need a solution that can identify between the different instruments accurately.
Next, we needed to look at the range of object detection APIs available to us. Over the past few years, deep learning algorithms for object detection have become more popular and powerful making older more traditional methods redundant [5].
[6][7]Upon researching different different models, we decided on using the Google TensorFlow API which offers a few models including faster r-cnn which we are particularly interested in. This model has a high level of detection accuracy but cuts back on detection speed. However, it is still sufficient for a video stream as we intend to perform the detection using a GPU on Azure. We chose this model to start of with as we need our software to be able to detect objects quickly but mainly accurately as possible as the system is used during operations where risks need to be minimized.
If the model does not meet our needs we can also look at the YOLOv3 mode using the DarkNet framework which has similar accuracies on some datasets but is faster.
As mentioned above we intend to use Microsoft Azure services to handle the ‘detection’ of objects. To do this we need to upload a video stream to the cloud service. This separates the system into 2 parts, which we have broken down what tasks need to be done for each component.