Algorithms
Being primarily LLM-based, this project did not have many algorithms that the group specifically implemented - the granular details were mostly abstracted by the pre-trained models. The group did, however, employ an embeddings model to generate the Confusion (Semantic Similarities) Matrix. The group also found it good practice and useful to learn more about the specific algorithms that powered LLMs.
First, a high-level overview of how an LLM algorithm works is detailed. In the second section, the group members delve deeper into the embeddings model and how the confusion matrix was generated.
1. Large Language Models
Since the crux of the project is the theory of Large Language Models (LLMs), the underlying algorithm and structure behind them are essential. In this section, the concept of transformer models will be briefly explored, before the relationship between transformer models and LLMs are elicited.
1.1 Transformer Models
A transformer model is a type of deep learning model that is popular in conducting Natural Language Processing (NLP) tasks. It is effective due to its ability to capture long-range dependencies in sequences of data; that is, the model can understand how distant parts of a sentence or sequence relate to each other to make sense of the whole string of information.
1.2 Overview of Transformer Architecture
Transformer models are unique in that they do not rely on convolutional neural or recurrent neural networks (CNN, RNN). [2] The result of this is that transformer models require less training time than other CNN or RNN based neural networks. These speeds are achieved by two new primary features of Transformer Models: Positional Encoding and Self-Attention.
1.2.1 Positional Encoding
Positional Encoding allows the model to assign unique numbers (embeddings) to each word instead of sequentially looking through the text. This allows for the correlation of words within sentence structures instead of in a word-by-word context.
1.2.2 Self-Attention
Self-Attention is a mechanism in which a model calculates scores (weights) for every word in a sentence in relation to every other word in the sentence. This allows the model to predict words which are likely to be used in sequence. In this way, the model can learn human syntax and grammar through analysing large amounts of text.
1.2.3 Encoder-Decoder architecture
The transformer encoder-decoder architecture is a variant of the original transformer model which is specifically used for text summarisation and conversational modelling. It broadly comes in two components: the Encoder and the Decoder.
The Encoder is responsible for processing the input sequence and extracting its representations, whilst the Decoder takes the generated representations and creates the output sequence. Both the encoder and decoder contain multiple layers, each of which contain self-attention and feedforward neural network sub-layers. [3]
During training, the encoder-decoder model is trained using various techniques to minimise the difference between the predicted output sequence and the target sequence.
1.3 How an LLM works [1]
With the help of the transformer model as well as a large number of hyperparameters, LLMs can become extremely good at understanding and generating accurate responses quickly. But before they can be utilised, they must be trained on petabytes of data - this training process usually takes multiple steps. During this training process, the model begins to derive relationships between different words and concepts; it also begins to label data to identify different concepts more accurately.
Then, the LLM undergoes deep learning as it goes through the transformer neural network process. [4] Here, the LLM begins to utilise the self-attention mechanism to connect words and concepts together. Weights are assigned to each token to determine the relationship between it and every other token.
When the training process is finished, the LLM can be fine-tuned to become even better at a certain task (such as translation).
1.4 Parameter Tuning
Both LLMs used in this project (GPT-3.5-turbo and Llama2-13b-chat) are pre-tuned LLM models specifically excelling in chat functionalities. The group considered it beyond the scope of the project to train an LLM model from scratch, as there was not enough reliable hazard data to do so. In addition to this, training an LLM would require an infeasible amount of resources that the group did not have access to. It would also contradict a main functionality of the tool, which was to not have any need for a separate server - an in-house LLM would require the IFRC to have dedicated servers to run the tool.
With that said, however, the group did have some leverage over the generative capabilities of the LLM. By changing the parameters, the group was able to make the LLM behave as closely as desired as possible.
1.4.1 GPT-3.5 Parameters
temperature: 0,
max_tokens: 1300,
During testing, it was found that changing other parameters for GPT, such as top_p , frequency_penalty, or presence_penalty actually made the model perform worse: the hazards generated became more erratic and less relevant to the report or it simply did not find hazards that it had correctly found with default values. As the performance was satisfactory with default parameters, it was decided that only the max_tokens would be changed for balanced efficiency and accuracy of generation - 1300 tokens was enough to fully generate all the entire JSON structure but also small enough to make the generation time reasonable.
1.4.2 Llama2-13b-chat Parameters
llm = AutoModelForCausalLM.from_pretrained(
model_path_or_repo_id="./models/13B-chat-GGUF-q5_K_M.gguf",
model_file="13B-chat-GGUF-q5_K_M.gguf",
model_type="llama",
max_new_tokens=75,
repetition_penalty=1.2,
temperature=0.25,
top_p=0.95,
top_k=150,
threads=22,
batch_size=40,
gpu_layers=50,
)
Llama2 (for the Association Matrix) required more of an experimental approach to determine the optimal parameters - aside from the generative parameters, such as temperature or repetition_penalty, the group also had to worry about the hardware parameters for maximised performance. The group conducted a small experiment to determine the best parameters.
The hardware optimisation was performed first. This included determining the threads , batch_size , and gpu_layers parameters.
threads: Controls the number of CPU threads used during generationbatch_size: Controls the number of input examples processed during generation. A larger batch size could potentially lead to faster processing due to more efficient GPU utilisation. However, increasing the batch size requires more GPU memory.gpu_layers: Controls the number of layers to offload to GPU during generation.
Thorough research into these parameters revealed that the best way to find out the best values was through experimentation. The group made an educated guess into the number of threads to use: since the computer they were using had a total of 24 threads, [5] so they chose to use 22 threads to leave 2 threads for background processes. Next, they experimentally determined the latter two parameters: the time taken to generate a 5x5 matrix was measured. When each parameter was being measured, the others were set to an arbitrary value to maintain uniformity and to only have one dependent variable.
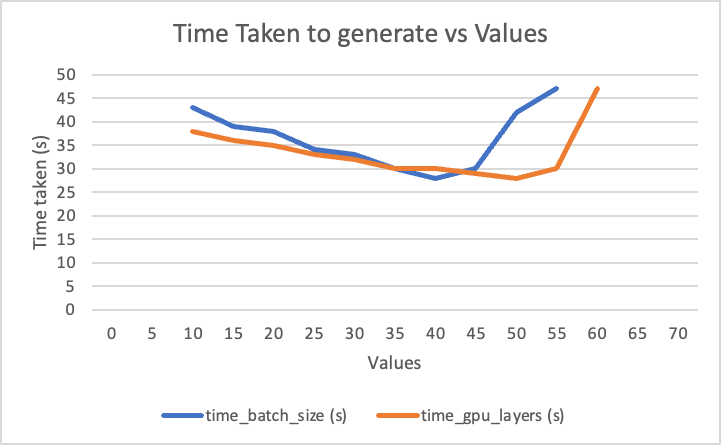
Figure 1.4.2b: The time taken to generate the matrix according to different values of batch_size and gpu_layers.
N.B. threads value was set to 22 for the duration of this experiment.
As shown by this graph, the experimentally found optimal batch_size and gpu_layers were about 40 and 50, respectively. As such, these were the values used as parameters when the association matrix was generated.
The values for top_p , top_k , and temperature were not extensively tested due to time constraints. The values used for the generation were values found online for which other testers were satisfied with the LLM’s responses. Upon basic testing, the LLM generated respectable answers for the association matrix; as thus, these values were left as such.
2. Confusion Matrix algorithms
For another deliverable, the group focused on leveraging text embeddings to generate a Confusion (Semantic Similarities) Matrix. This effort was aimed at understanding and quantifying how likely hazards are to be confused with one another.
2.1 Text Embeddings
Text embeddings are a sophisticated method of converting text into numerical vectors, allowing machines to understand and process natural language more effectively. This technique involves mapping words, sentences, or even entire documents to vectors of real numbers. The primary advantage of text embeddings is their ability to capture the semantic meanings of the text, including nuances and context, rather than merely its syntactical structure.
2.1.1 Embeddings Generation
The generation of embeddings was a critical step in our project. We utilized a pre-trained embeddings model, which had already learned to encapsulate semantic meanings from a vast corpus of text data. By inputting our hazard definitions into this model, we obtained high-dimensional vectors representing the semantic content of each hazard. These vectors served as the foundational elements for our subsequent analysis.
2.1.2 Vector Space Model
The high-dimensional vectors generated by the embeddings model exist in a vector space, where the distance and direction between vectors are indicative of the semantic similarity between the texts they represent. By operating in this vector space, we could apply mathematical and geometric operations to analyze and compare the semantic content of our texts.
2.2 Generating the Confusion Matrix
The Confusion (Semantic Similarities) Matrix was used for visualizing and quantifying the semantic similarities between any two hazards. This matrix was constructed by calculating the distances between every pair of text embeddings in our dataset.
2.2.1 Distance Metrics
To measure the semantic similarity between two text embeddings, we employed the distance metric cosine similarity. Cosine similarity calculates the cosine of the angle between two vectors, providing a measure sensitive to the vectors' orientation in the vector space rather than their magnitude. This metric is particularly suitable for text embeddings, as it effectively captures the degree of semantic similarity between texts.
2.2.2 Matrix Construction
With the distance metrics defined, we calculated the similarity scores between all pairs of hazards in our dataset. These scores were then arranged in a matrix format, where each cell represented the similarity score between each pair of hazards. The resulting Confusion Matrix provided a comprehensive overview of how similar the definitions of each pair of hazards are. As the likelihood of two hazards being confused is directly related to how similar their definitions are, we can assume that their similarity is a good indicator of how likely the hazards are to be confused.
3. References
[1] What is a large language model?: A comprehensive llms guide. Elastic. (n.d.). https://www.elastic.co/what-is/large-language-models
[2] What is a transformer model?. IBM. (n.d.). https://www.ibm.com/topics/transformer-model
[3] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2023, August 2). Attention is all you need. arXiv.org. https://arxiv.org/abs/1706.03762
[4] Kerner, S. M. (2023, September 13). What are large language models?: Definition from TechTarget. WhatIs. https://www.techtarget.com/whatis/definition/large-language-model-LLM
[5] Intel® CoreTM I9-12900K processor (30m cache, up to 5.20 GHz) product specifications. Intel Core i912900K Processor 30M Cache up to 5.20 GHz Product Specifications. (n.d.). https://ark.intel.com/content/www/us/en/ark/products/134599/intel-core-i9-12900k-processor-30m-cache-up-to-5-20-ghz.html